







问题描述
将一个2708行64列的在GPU上的张量z0矩阵保存下来,格式为csv
初步操作
如果 z0 是一个 PyTorch Tensor,你可以使用以下代码将其保存为 CSV 文件:
import torch import pandas as pd
# 假设 z0 是一个 PyTorch Tensor,大小为 (2708, 64)
z0 = torch.randn(2708, 64)#把这部分换成你代码需要保存的张量即可
# 将 PyTorch Tensor 转换为 NumPy 数组,然后使用 pandas 创建 DataFrame
df = pd.DataFrame(z0.numpy()) # 保存 DataFrame 到 CSV 文件 df.to_csv('z0.csv', index=False)这里,z0 是一个大小为 (2708, 64) 的随机张量。通过使用 numpy() 方法,我们将 PyTorch Tensor 转换为 NumPy 数组,然后使用 pandas.DataFrame 创建一个 DataFrame。最后,使用 to_csv 方法将 DataFrame 保存到 "z0.csv" 文件中,index=False 参数表示不保存行索引。
确保你已经安装了 pandas 库,你可以使用以下命令进行安装:
pip install pandas这样,你就会得到一个 CSV 文件 "z0.csv" 包含了 z0 矩阵的数据。
报错了!!!
但是如果你从GPU上的数据进行操作的时候就会出现问题,报错如下
TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.执行上述代码出现了这个错误,怎么解决?
别担心,只需要做下面操作就可以了
#对z0进行操作
z0 = z0.cpu().detach().numpy()解释如下:
这个错误表明你正在尝试将位于 GPU 上的 PyTorch Tensor 直接转换为 NumPy 数组,而 NumPy 不支持 GPU Tensor。为了解决这个问题,你需要将 Tensor 移到 CPU 上,然后再转换为 NumPy 数组。
在你的代码中,如果
z0是一个位于 GPU 上的 Tensor,你可以使用.cpu()方法将其移动到 CPU 上这里,我们使用了
.cpu()方法将 Tensor 移动到 CPU 上,然后使用.detach()方法脱离计算图,最后转换为 NumPy 数组。然后,通过使用pandas.DataFrame创建 DataFrame,并使用to_csv方法保存到 "z0.csv" 文件中。请注意,如果你的数据非常大,将其从 GPU 复制到 CPU 可能会占用大量的内存,因此请谨慎处理。
延伸阅读
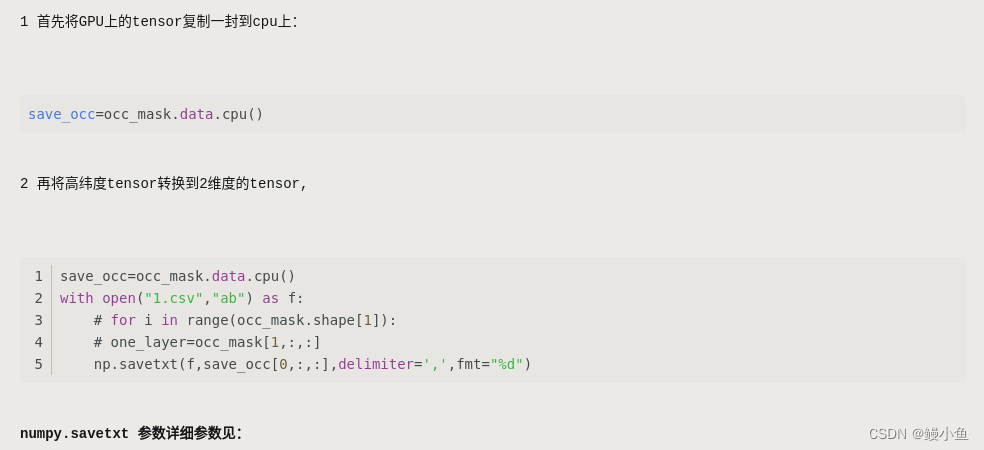
完结撒花
有可能,我们只是忘记了温柔















 1391
1391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









