







Motivition
作者的出发点有几个:
- 尽管BERT这种预训练模型取得了state-of-art的成绩。但是、因为他们没有包含真实世界的实体,所以导致这些模型也很难覆盖真实世界的知识。
没有实体没有知识怎么办呢?Knowledge bases、知识库有。 - 知识库不仅拥有丰富的高质量、人类产生的知识,而且他们包含与原始文本中互补的信息,还能够编码事实性的知识。所以用知识库可以解决因不频繁出现但是常识的mention或者长距离依赖造成的难以学习选择偏好的问题
一些解释
- 实体(Entity):知识库中完整定义的,唯一存在的条目,每一个实体都可以看作是指代它的名词短语或代词构成的集合
例:(巴拉克-奥巴马={美国总统,奥巴马,第44任美国总统,他})。 - 指称(mention):实体在自然语言文本中的别名或另一种指代形式。
例:美国总统(名词词组)、奥巴马(命名实体)、第44任美国总统、他(代词)等。 - 选择偏好(Selectional Preference):动词的倾向性。谓语(Predicate)对其论元(Argument)是有一定选择倾向性的,不是什么词语都可以通过简单排列组合进行搭配的。[百度百科]
KnowBert
KAR
关键思想
关键思想:在输入文本中显式建模实体跨度(Entity spans),并使用实体链接器(Entity Linker)从KB中检测mention、检索相关的实体嵌入(Entity embeddings),以形成知识增强的实体跨度表示形式。然后使用word-to-entity attention将单词的表示重新上下文化,以携带全部的实体信息。
优点
- 不针对特定任务,可以fine-tune
- 轻量,增加了少量的参数和运行时间
- 便于融合其他KB
方法
1、他人工作:从KB中检测mention、检索相关的实体嵌入(Entity embeddings)
输入:文本
输出:候选实体列表 C C C与之对应的先验概率
例: Prince sang Purple Rain, she …
[Prince] sang [Purple [Rain]],[she]…

检测mention的方法是2017年的共指消解文章中提及的方法,这里就不展开介绍了,作者也是拿来直接用。2017年的文章做了这两个事情,1、mention检测。2、共指消解。举个例子,输入文本Prince sang Purple Rain, she …,通过mention检测可以获得[Prince] sang [Purple [Rain]],[she],这几个mention,然而这句话当中,Prince和she共同指代同一个实体,那在传统的embedding方式中这个Prince和she的编码可能不太一致,共指消解的目的就是消除这样的不一致。
至于检索相关的实体,作者使用的是基于规则的方式,也是前人的工作。
Entity embeddings呢,对于不同的数据库作者的做法不完全一致,作者使用三类数据库中的知识,对于图结构的数据库,作者使用了2019年知识图谱embedding的最新工作获得实体嵌入,对于仅有实体元数据的数据库,作者在实验部分介绍到他们使用doc2vec的方式直接从Wikipedia描述中学习Wikipedia页面标题的300维嵌入。两种融合在一起的数据库作者也介绍了他们使用的方法。
总之,在本文中,输入一段文本,作者可以检测其中的mention,检索获得对应的Entity Embedding列表,同时也获得实体对应的先验概率。这些是不参与训练的。
KAR
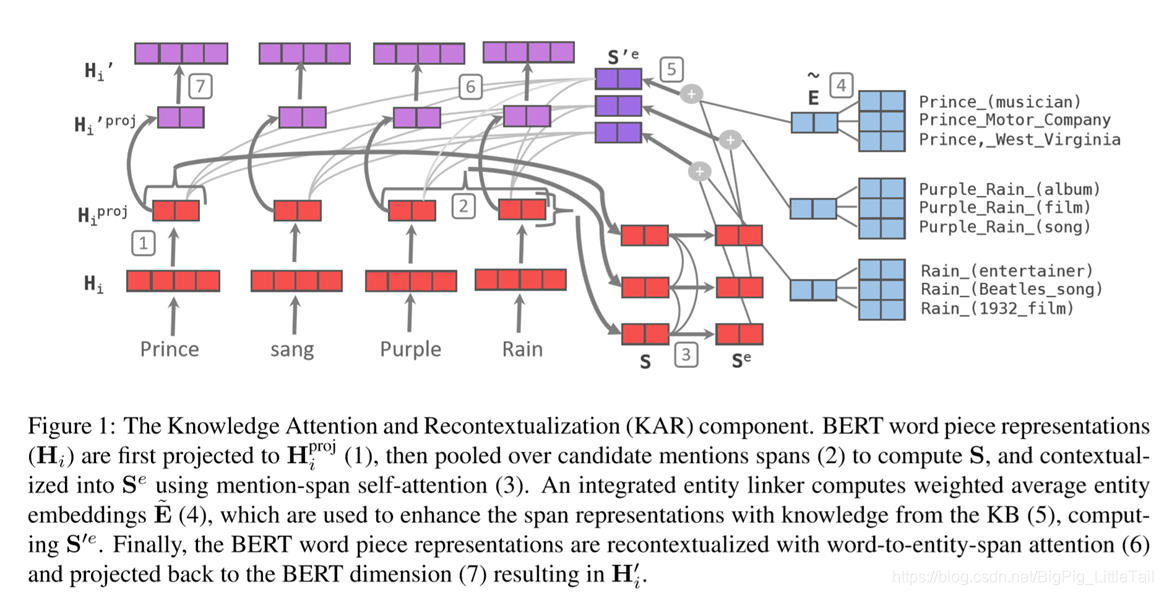
KAR插入在BERT层间, H i H_i Hi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2765
2765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









