








ERNIE 3.0:大规模知识强化的语言理解和生成训练
Yu Sun ∗ Shuohuan Wang ∗ Shikun Feng ∗ Siyu Ding Chao Pang Junyuan Shang Jiaxiang Liu Xuyi Chen Yanbin Zhao Yuxiang Lu Weixin Liu Zhihua Wu Weibao Gong Jianzhong Liang Zhizhou Shang Peng Sun Wei Liu Xuan Ouyang Dianhai Yu Hao Tian Hua Wu Haifeng Wang Baidu Inc. { sunyu02, wangshuohuan, fengshikun01 } @baidu.com
摘要
经过预训练的模型在各种自然语言处理(NLP)任务中取得了最先进的结果。T5[1]和GPT-3[2]等最近的研究表明,扩大预先训练的语言模型可以提高它们的泛化能力。特别是,具有1750亿个参数的GPT-3模型展示了其强大的与任务无关的零样本/少样本学习能力。尽管取得了成功,但这些大型模型都是在纯文本上训练的,没有引入语言知识和世界知识等知识。此外,大多数大型模型都是以自回归的方式进行训练的。因此,这种传统的微调方法在解决下游语言理解任务时表现出相对较弱的性能。为了解决上述问题,我们提出了一个统一的框架ERNIE 3.0,用于大规模知识增强模型的预训练。它融合了自回归网络和自编码网络,使得训练后的模型可以方便地适应自然语言理解和生成任务,并具有零镜头学习、少量镜头学习或微调功能。我们在由纯文本和大规模知识图组成的4TB语料库上用100亿个参数训练了模型。实证结果表明,模型在54项中文NLP任务上的表现优于最先进的模型,其英文版在SuperGLUE[3]基准(2021年7月3日)上取得了第一名,超过了人类绩效+0.8%(90.6%对89.8%)。
1引言
经过预训练的语言模型(如ELMo[4]、GPT[5]、BERT[6]和ERNIE[7])已被证明能够有效提高各种自然语言处理任务的性能,包括情感分类[8]、自然语言推理[9]、文本摘要[10]、命名实体识别[11]等。一般来说,预先训练的语言模型是以自我监督的方式在大量文本数据上学习的,然后对下游任务进行微调,或者通过零/少数镜头学习直接部署,而无需特定于任务的微调。这种预先训练好的语言模型已经成为自然语言处理任务的新范例。
在过去一两年中,预训练语言模型的一个重要趋势是其模型的大小不断增大,这导致预训练中的困惑程度降低,在后续任务中表现更好。威震天LM【12】,有10亿个参数,是为语言理解而提出的,使用一种简单但高效的层内模型并行方法,在多个数据集上实现了最先进的结果。T5【1】探索了具有100亿个参数的预训练模型的局限性,但很快,具有1750亿个参数的GPT-3模型打破了这一记录,该模型在少数镜头甚至零镜头设置下具有良好的性能。不久之后,开关变压器(Switch Transformer)被提议作为世界上第一个万亿参数预训练语言模型。
然而,这些具有数千亿参数的大规模预训练语言模型是在纯文本上训练的。例如,1750亿个参数的GPT-3是在一个语料库上训练的,语料库中有570GB来自普通爬网的过滤文本。这些原始文本缺乏语言知识和世界知识等知识的明确表达。此外,大多数大型模型都是以自回归的方式进行训练的,但[6]表明,在适应下游语言理解任务时,此类模型在传统微调的情况下表现出较差的性能。
在这项工作中,为了解决单一自回归框架带来的问题,并探索具有大规模参数的知识增强预训练模型的性能,我们提出了一个称为ERNIE 3.0的统一框架,通过融合自回归网络和自动编码网络,在由纯文本和大规模知识图组成的4TB语料库上训练大规模知识增强模型。提出的ERNIE 3.0可以通过零镜头学习、少量镜头学习或微调来处理自然语言理解任务和自然语言生成任务。此外,拟议的框架支持随时引言。这些任务共享相同的编码网络,并通过多任务学习进行训练。这种方法使得在不同的任务中对词汇、句法和语义信息进行编码成为可能。此外,当赋予新任务时,我们的框架可以基于以前的训练参数对分布式表示进行增量训练,而无需从头开始训练。
综上所述,我们的贡献如下:•我们提出了一个统一的框架ERNIE 3.0,该框架将自回归网络和自动编码网络相结合,使经过训练的模型可以通过零镜头学习、少量镜头学习或微调来处理自然语言理解和生成任务。
•我们预先训练了具有100亿个参数的大规模知识增强模型,并通过一系列自然语言理解和自然语言生成任务的实验对其进行评估。实验结果表明,ERNIE 3.0在54个基准测试中始终优于最先进的模型,并在SuperGLUE(3)基准测试中获得第一名。
2.相关工作
2.1大规模预训练模型
自BERT[6]被提出作为一种强大的自然语言理解语言模型以来,预训练语言模型受到了越来越多的关注,成为自然语言处理的新范式。其中一个研究趋势是增加模型的大小,从而降低困惑度,提高性能【14】。因此,在过去两年中,许多大规模的预训练模型被提出。T5模型[1]旨在提高110亿个参数的自然语言理解和自然语言生成任务的性能。T5模型通过统一的框架将所有基于文本的语言任务转换为文本到文本的格式,并充分探讨了预训练目标、体系结构、未标记数据集、传输方法和其他因素的有效性。在T5模型之后,GPT-3[2]包括1750亿个参数,建议在少量放炮和零放炮设置下,在广泛的任务中实现惊人的性能。具体而言,GPT-3是一种自回归语言模型,比其前身GPT-2(由[15]提出)多10倍。然而,GPT-3在测试中缺乏常识,存在偏见和隐私问题[16]。【13】提出了一个名为Switch Transformer的1万亿参数模型,简化了MoE【17,18】路由算法,以较少的通信和计算成本改进模型,并且【13】还提出了一个大规模分布式训练解决方案,以解决训练的复杂性、通信成本和训练的不稳定性问题。
除上述模型外,最近还提出了更多的非英语大型模型。[19]发布了一个26亿参数的中文预训练语言模型(CPM),该模型在大规模中文训练数据上进行生成性预训练,模型结构受到了[2]的启发。【20】发布了110亿参数的模型CPM-2。为了加速基于现有PLM而不是从头开始的训练模型的预训练,引入了知识继承技术,在微调阶段,需要进行快速调整,以便更好地利用预训练模型中的知识。[21]提出了一种称为M6(多模态到多模态多任务巨型变压器)的跨模态预训练方法,包括1000亿个参数,用于对多模态数据进行统一预训练。【22】提出了一个名为PangGu-α的2000亿参数自回归语言模型,该模型在2048个Ascend 910 AI处理器集群上进行训练,采用分布式训练技术,包括数据并行、op级模型并行、管道模型并行、优化器模型并行和重物化。除了中国的大型模型外,还提出了一个名为HyperCLOVA(23)的韩国2040亿参数语言模型,其韩语机器学习数据量是GPT-3的6500倍。通过以上讨论,观察结果表明,大规模预训练模型已经吸引了越来越多的工业界和学术界的注意力。
2.2知识增强型模型
预先训练的语言模型从大规模语料库中获取句法和语义知识,但缺乏世界知识。最近,有几项工作试图将世界知识融入预先训练的语言模型中。
世界知识的典型形式是知识图。许多著作([24,25,26])将知识图中的实体和关系嵌入到预先训练好的语言模型中。WKLM【27】将原始文件中提及的实体替换为相同类型的其他实体的名称,并训练模型,以区分正确的实体提及和随机选择的实体提及。开普勒(KEPLER)[28]通过知识嵌入和屏蔽语言模型目标优化模型,以将世界知识和语言表示对齐到相同的语义空间中。
CoLAKE【29】将语言语境和知识语境整合到单词知识图中,并结合扩展的掩码语言模型目标学习语言和知识的语境化表示。
另一种现存的世界知识形式是对大规模数据的额外注释。ERNIE 1.0[7]引入了短语掩蔽和命名实体掩蔽,并预测整个掩蔽短语和命名实体,以帮助模型学习本地上下文和全局上下文中的依赖信息。CALM[30]教授模型通过两种自我监督的预训练任务来检测和修改概念顺序不正确的损坏句子,并区分真实句子和不太可信的句子。K-Adapter[31]利用在不同的知识源上训练的适配器,通过附加注释来区分知识的来源。
3 ERNIE 3.0
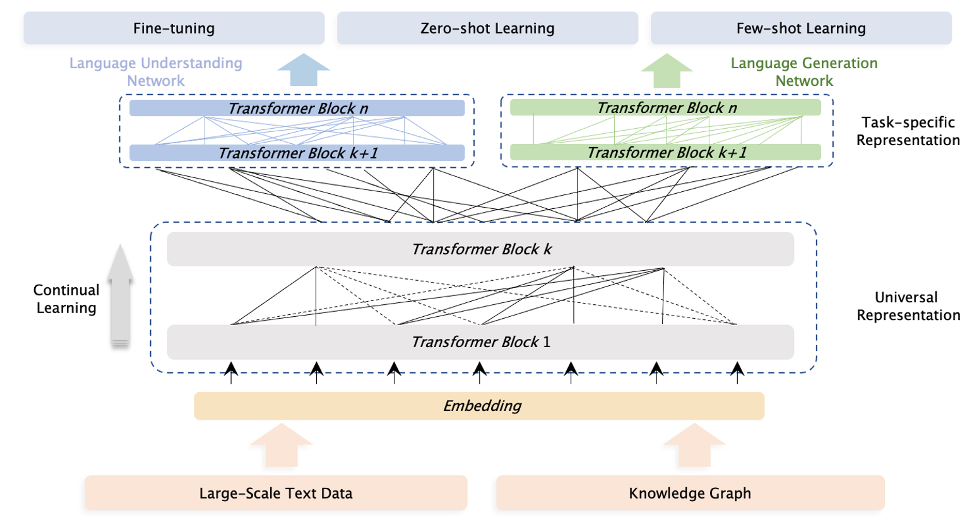
图1:ERNIE 3.0的框架。
对于具有基本或大模型尺寸的知识增强预训练模型,如ERNIE、ERNIE 2.0和SpanBERT[32],在各种自然语言处理任务上取得了显著改进,其中基本/大模型尺寸分别代表12/24层。为了探索知识增强的大规模预训练模型的有效性,我们提出了ERNIE 3.0框架,在包括纯文本和知识图在内的大规模无监督语料库上对模型进行预训练。此外,我们采用各种类型的预训练任务,使模型能够更有效地学习由有价值的词汇、句法和语义信息组成的不同层次的知识,其中预训练任务传播了三种任务范式,即自然语言理解、自然语言生成和知识提取。因此,ERNIE 3.0创新性地设计了一个持续的多范式统一的预训练框架,以实现多任务范式之间的协同预训练。下面几节将解释ERNIE 3.0的明确引言。
3.1 ERNIE 3.0框架概述
图1显示了ERNIE 3.0的框架,该框架可广泛用于预训练、微调和零/少镜头学习。与流行的统一预训练策略不同,ERNIE 3.0设计了一个新的连续多范式统一预训练框架,该策略使用共享的Transformer网络来完成不同的精心设计的完形填空任务,并使用特定的自我注意面具来控制预测条件的上下文。我们认为,自然语言处理的不同任务范式始终依赖于相同的底层摘要特征,如词汇信息和句法信息,但顶层具体特征的要求是不兼容的,其中,自然语言理解任务具有学习语义连贯的倾向,而自然语言生成任务期望获得更多的语境信息。因此,受到多任务学习的经典模型体系结构的启发,在该体系结构中,底层在所有任务中共享,而顶层是特定于任务的,我们提出了ERNIE 3.0,以使不同的任务范式能够共享在共享网络中学习到的底层摘要特征,并分别利用在各自的任务特定网络中学习到的任务特定顶层具体特征。此外,为了帮助模型有效地学习词汇、句法和语义表示,ERNIE 3.0利用了ERNIE 2.0中引入的连续多任务学习框架【33】。对于不同类型下游任务的应用,我们将首先针对不同的任务范式,结合预先训练的共享网络和相应的任务特定网络的参数,初始化ERNIE 3.0,然后使用特定任务的数据执行相应的后续过程。
我们将骨干共享网络和任务特定网络称为ERNIE 3.0中的通用表示模块和任务特定表示模块。具体而言,通用表示网络扮演着通用语义特征提取器的角色(例如,它可以是多层Transformer),其中参数在各种任务范式中共享,包括自然语言理解、自然语言生成等。任务特定表征网络承担着提取任务特定语义特征的功能,其中参数由任务特定目标学习。ERNIE 3.0不仅使模型能够区分不同任务范式之间的特定于任务的语义信息,而且还缓解了大规模预训练模型难以在有限的时间和硬件资源下实现的困境,其中ERNIE 3.0允许模型在微调阶段仅更新特定于任务的表示网络的参数。具体而言,ERNIE 3.0采用了通用表示模块和两个任务特定表示模块的协作架构,即自然语言理解(NLU)特定表示模块和自然语言生成(NLG)特定表示模块。
3.1.1通用表示模块
ERNIE 3.0使用多层Transformer XL【34】作为主干网络,就像其他经过预训练的模型一样,如XLNet【35】、Segatron【36】和ERNIE文档【37】,其中Transformer XL与Transformer类似,但引入了辅助递归存储模块,以帮助对更长的文本进行建模。我们将主干称为通用表示模块,它在所有任务范例中共享。众所周知,Transformer可以通过自我注意捕获序列中每个标记的上下文信息,并生成上下文嵌入序列。显然,Transformer模型的规模越大,其捕获和存储不同层次的各种语义信息的能力就越强。因此,ERNIE 3.0将通用表示模块设置为更大的尺寸,以使模型能够通过学习不同范式的各种训练前任务,有效地从训练数据中捕获通用词汇和语法信息。需要特别注意的是,记忆模块仅对自然语言生成任务有效,同时控制注意力掩码矩阵。
3.1.2任务特定表示模块
与基本共享表示模块类似,任务特定表示模块也是一个多层Transformer XL,用于捕获不同任务范例的顶级语义表示。ERNIE 3.0将特定于任务的表示模块设置为一个可管理的大小,即基础模型大小,而不是多任务学习中常用的多层感知器或浅层Transformer,这将产生三个明显的好处,一是基础网络比多层感知器和浅层Transformer捕获语义信息的能力更强;第二,具有基本模型大小的任务特定网络使ERNIE 3.0能够区分不同任务范式之间的顶级语义信息,而不会显著增加大规模模型的参数;最后,与共享网络相比,任务特定网络的模型尺寸更小,这将导致在仅微调任务特定表示模块的情况下,大规模预训练模型的可实现实际应用。ERNIE 3.0构建了两个任务特定的表示模块,即NLU特定的表示模块和NLG特定的表示模块,其中前者是双向建模网络,后者是单向建模网络。
3.2预训练任务
我们为各种任务范式构建了多个任务,以捕获训练语料库中信息的不同方面,并使预训练的模型具备理解、生成和推理的能力。
3.2.1单词意识预训练任务
知识蒙面语言建模ERNIE 1.0[7]提出了一种通过知识集成增强表示的有效策略,即知识集成蒙面语言建模任务。它引入短语掩蔽和命名实体掩蔽,预测整个被掩蔽的短语和命名实体,以帮助模型在局部上下文和全局上下文中学习依赖信息。
文档语言建模生成性预训练模型通常使用传统的语言模型(如GPT[5]、GPT-2[15])或序列到序列语言模型(如BART[38]、T5[1]、ERNIE-GEN[39])作为预训练任务,后者使用辅助解码器结构在网络上进行训练。ERNIE 3.0选择传统语言模型作为预训练任务,以降低网络复杂性,提高统一预训练的有效性。此外,为了使ERNIE 3.0的NLG网络能够对更长的文本进行模型,我们引入了ERNIE文档[37]中提出的增强递归存储机制,通过将一层向下递归转换为同一层递归,该机制可以模型比传统递归Transformer更大的有效上下文长度。
3.2.2了解结构的预训练任务
ERNIE 2.0(29)中引入的句子重新排序任务旨在通过重新组织排列的片段来训练模型,以学习句子之间的关系。最后,在预训练期间,将给定段落随机分成1个tom段,所有组合按随机排列顺序进行洗牌。
然后,要求预训练的模型重新组织这些排列的片段,建模为k类分类问题,其中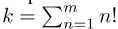 。
。
句子距离-句子距离任务是传统下一句预测(NSP)任务的扩展,广泛应用于各种预训练模型中,以增强它们学习句子级信息的能力,可以将其建模为一个三级分类问题。这三个类别表示两个句子相邻、不相邻,但在同一个文档中,并且分别来自两个不同的文档。
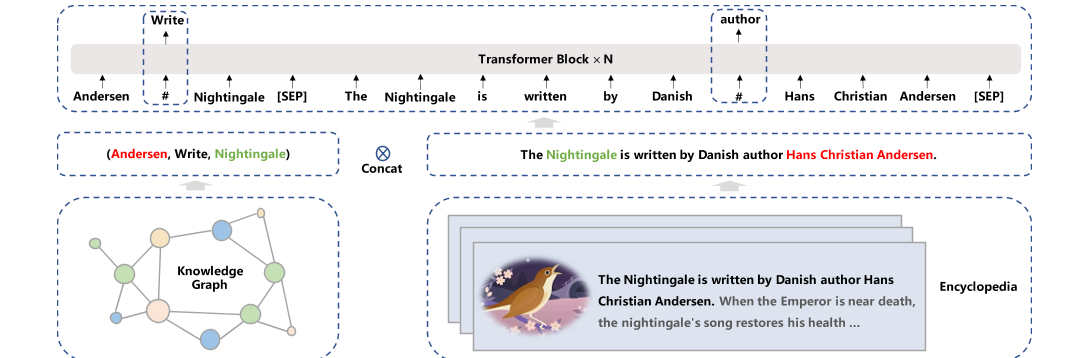
图2:通用知识文本预测。

表1:预训练数据集统计。
3.2.3有知识意识的预训练任务
通用知识文本预测为了将知识整合到一个预先训练好的语言模型中,我们引入了通用知识文本预测(UKTP)任务,它是知识掩蔽语言模型的扩展。
知识掩蔽语言建模只需要非结构化文本,而通用知识文本预测任务需要非结构化文本和知识图。通用知识文本预测任务如图2所示。给定知识图中的一对三元组和百科全书中相应的句子,我们随机将关系隐藏在三元组或句子中的单词中。为了预测三元组中的关系,模型需要检测头实体和尾实体的提及,并确定它们在相应句子中的语义关系。
这个过程的本质与远程监控算法[40]在提取任务方面类似。远程监控算法假设,如果两个实体参与一个关系,任何包含这两个实体的句子都可能表达该关系。同时,为了预测相应句子中的单词,该模型不仅考虑了句子中的依赖信息,还考虑了三元组中的逻辑关系。具体来说,获取三元组和相应句子对的过程如下:给定百科全书中的一个文档,我们首先在知识图中找到候选三元组,其中提到的头实体或尾实体是文档的标题,然后从候选三元组中选择三元组,这些候选三元组在文档中的同一句话中提到了头实体和尾实体。
ERNIE 3.0通过知识掩蔽语言建模训练NLU网络,提高词汇信息的捕获能力,训练句子重排任务和句子距离辨别任务,增强句法信息的捕获能力,最后利用通用知识文本预测任务对模型进行优化,以提高知识的记忆和推理能力。同时,ERNIE 3.0使用文档语言建模任务训练NLG网络,以支持各种生成样式。
3.3预训练流程
3.3.1预训练算法
渐进式训练最初是为了提高稳定性而提出的,它从一个高效的小型模型开始,并逐渐增加容量[41]。最近的研究利用这种范式来加速模型训练。随着大规模的预训练不断推进最先进的技术([6],[5]),他们巨大的计算消耗成为进一步开发更强大模型的主要负担([15])。已在Transformer训练前初步应用渐进式训练。BERT([6])设计了一个两阶段的训练,在前90%的更新中减少了序列长度。[15]还将批量从较小值线性增加到最大值。[42]还请注意,改变正则化因子(例如[43]、[44])相对于输入大小的阶段性变化可以加快训练网络的速度。为了进一步提高训练过程的收敛速度,我们建议通过逐步同时增加包括输入序列长度、批量大小、学习率和退出率在内的训练因子,以更全面和平滑的方式调整训练正则化因子。事实上,Transformer模型通常采用学习率预热策略来提高训练的稳定性,我们改进的渐进式学习策略与现有策略兼容。
3.3.2预训练数据
为了确保ERNIE 3.0预训的成功,我们构建了一个规模大、种类广、质量高的中文文本语料库,存储容量达4TB,分为11个不同类别。据我们所知,与CLUECorpus2020[45](100GB)、中国多模式预训练数据[21](300GB)、Wdaocorpus2相比,这是目前最大的中国预训练语料库。0由CPM-2[20](2.3TB中文数据和300GB英文数据)和盘古语料库[22](1.1TB)使用。
具体而言,我们在ERNIE 2.0(包括百科、维基百科、feed等)、百度搜索(包括白嘉浩、知道、贴吧、体验)、网络文本、QA long、QA short、诗歌2和对联3、医疗、法律和金融领域的特定领域数据以及超过5000万事实的百度知识图的基础上,构建了厄尼3.0的语料库。
为了提高数据质量,我们采用了以下预处理策略:•重复数据消除在不同粒度上进行,包括字符级、段落级和文档级。在字符级别,我们用一个字符替换连续的相同字符(即空格、制表符、感叹号、问号等)。一是在段落层面,我们将两个相同的连续段落(由N个句子组成)替换为一个段落,其中0<N<100。上述两种重复数据消除策略对于ERNIE 3.0生成非重复内容至关重要。最后,我们采用消息摘要算法MD5(Message Digest Algorithm5)通过比较每个文档中前三个最长句子的MD5之和来过滤重复文档。
•过滤少于10个单词的句子,因为它们可能是有问题或不完整的句子,其中包含有限的语义信息,用于模型预训练。
•我们进一步使用正则表达式进行句子切分,并基于百度的分词工具进行分词。这有助于ERNIE 3.0在训练前更好地学习句子边界和命名实体知识。
然后,在为NLU网络预训练截断数据后,将每个数据集乘以用户定义的乘数以增加数据多样性。
3.3.3预训练设置
ERNIE 3.0的通用表示模块和任务特定表示模块都使用Transformer XL[34]结构作为主干。对于通用表示模块,我们采用了48层、4096个隐藏单元和64个头的结构。对于任务特定的表示模块,我们采用了12层、768个隐藏单元和12个头的结构。通用表示模块和任务特定表示模块的总参数为100亿。使用的激活函数是GeLU[46]。上下文的最大序列长度和语言生成的内存长度分别设置为512和128。所有预训练任务的总批量设置为6144。我们使用Adam[47],学习率为1e-4,β1=0。9 , β 2 = 0 . 999,L2权重衰减为0.01,学习率在前10000步预热,学习率线性衰减。在前10000个步骤中,我们还使用渐进式学习来加速预训练初始阶段的收敛。模型使用384个NVDIA v100 GPU卡进行了总计375亿代币的训练,并在这是老的classifier框架上实现。通过[48,49]中使用的参数切分,我们设法减少了模型的内存使用,并解决了模型的总参数超过单个GPU卡内存的问题。
4 实验
我们通过对自然语言理解任务(第4.2.1节)和自然语言生成任务(第4.2.2节)以及零镜头学习(第4.3节)5进行微调,将ERNIE 3.0的性能与最先进的4种预训练模型进行比较。
4.1评估任务
我们在54个NLP任务上进行了大量实验,以评估模型的微调和零炮学习性能。
4.1.1自然语言理解任务
在我们的实验中,使用了14种自然语言理解任务的45个数据集,如下所示:•情绪分析:NLPCC2014-SC 6,SE-ABSA16_PHNS 7,SE-ABSA16_come,BDCI2019 8。
•意见提取:COTE-BD[50],COTE-DP[50],COTE-MFW[50]。
•自然语言推理:XNLI[51],OCNLI[45],CMNLI[45]。
•Winograd Schema Challenge Cluews220[45]。
•关系提取:FinRE[52],SanWen[53]。
•事件提取:CCKS2020 9。
•语义相似性:AFQMC[45],LCQMC[54],CSL[45],PAWS-X[55],BQ语料库[56]。
•中文新闻分类:TNEWS 10、科大讯飞[57]、THUCNEWS 11、CNSE[58]、CNSS[58]。
•闭卷问答:NLPCC-DBQA 12,CHIP2019,cMedQA[59],cMedQA2[60],ckbqa 13,WebQA[61]。
•命名实体识别:CLUENER[45]、微博[62]、OnNotes[63]、CCKS2019 14。
•机器阅读理解:CMRC 2018[64]、CMRC2019[65]、DRCD[66]、DuReader[67]、DuReader robust[68]、DuReader检查表、DuReader yesno 15、C 3[69]、CHID[70]。
•法律文件分析:CAIL2018-Task1【71】,CAIL2018-Task2【71】。
•无法理解:狗哨局内人,狗哨局外人[72]。
•文件检索:搜狗日志[73]。
4.1.2自然语言生成任务
实验中使用了9个数据集,分别属于7种自然语言生成任务,如下所示:•文本摘要:LCSTS[10]•问题生成:KBQG 16,DuReader QG[67],DuReader robust-QG[68]。
•闭卷问答:MATINF-QA[74]。
•数学:Math23K[75]。
•广告生成:AdGen[76]。
•翻译:WMT20 Ensh[77]。
•对话生成:KdConv[78]。
4.2微调任务的实验
4.2.1自然语言理解任务的微调
自然语言理解任务的结果如表2所示。
情绪分析。情绪分析是一项分类任务,旨在确定句子是积极的、消极的还是中性的。我们考虑来自不同领域的4个数据集,包括购物(NLPCC2014-SC)、电子学(SE-ABSA16-PHNS、SE-ABSA161CAM)和金融(BDCI2019)。ERNIE 3.0在所有四个数据集上都取得了实质性的改进。
意见提取。与情感分析任务类似,意见提取需要模型挖掘句子的意见。我们使用了中国客户评论(COTE)的三个子数据集。实验结果表明,ERNIE 3.0的性能也大大优于目前的SoTA系统。
自然语言推理。自然语言推理的任务是确定一个给定前提在语义上是否包含另一个假设。我们使用OCNLI和XNLI数据集。结果表明,ERNIE 3.0在两个数据集上分别实现了3.9和0.7的精度提高。XNLI数据集的改进非常有限,这可能是因为XNLI数据集是从英文翻译过来的,所以数据集的质量很差。
Winograd模式挑战。WSC2020是一项回指消解任务,要求模型确定句子中的代词和名词是否共同引用,ERNIE 3.0取得了25.7分的显著改进。
关系抽取。关系抽取的任务是识别不同实体之间的关系,如个人和组织。我们认为FrRe和SanWen分别是财经新闻和中国文学的两个关系抽取数据集。ERNIE 3.0的表现比之前的索塔模型平均高出2.46个百分点。
事件提取。与关系提取类似,事件提取任务旨在识别事件实体并将其分类为不同的类别。我们选择了CCKS2020——一个金融领域的文本级事件主题提取数据集。
ERNIE 3.0在测试集上有3点改进。
语义相似性。语义相似性是一个经典的NLP任务,它决定了单词、句子、文档等不同术语之间的相似性。在这项工作中,我们关注句子级的相似性任务。我们在包括AFQMC、LCQMC、CSL、PAWS-X和BQ在内的不同领域的多个数据集上测试了ERNIE 3.0。实验结果表明,ERNIE 3.0的性能显著优于基线模型。特别是,在可比较的参数数量下,ERNIE 3.0在LCQMC数据集上以1.2分超过CPM-2。
中文新闻分类。我们还评估了ERNIE 3.0对中国新闻分类的影响。我们考虑6个数据集,包括新闻标题(TeNews),APP描述(IFLTETEK),和新闻故事(TuxNews,CNSE,CNSS)。在不同类型的分类任务下,ERNIE 3.0可以持续获得更好的准确性,平均提高2.8分。
闭卷问答。闭卷问答旨在直接回答问题,无需任何额外的参考文献或知识。我们选择了一个通用QA数据集NLPCC-DBQA和三个医疗现场数据集CHIP2019、cMedQA和cMedQA2来测试ERNIE 3.0的能力。实验结果表明,ERNIE 3.0在所有QA任务上都表现得更好,我们相信知识增强的预训练方法确实会给闭卷QA任务带来好处。
我无法理解。Cant,也称为doublespeak,是人类的一种高级语言用法。然而,机器很难理解这种语言。我们在DogWhistle上测试了ERNIE 3.0的超能力,这是一个基于Decrypto游戏的数据集。要求模型在相应铁路超高的指导下选择正确答案。ERNIE 3.0获得了最好的结果,并显示了它在理解更难的语言方面的潜力。
命名实体识别。命名实体识别是一项经典的自然语言处理任务,用于对文本中的实体进行提取和分类。我们选择了广泛使用的OnNotes、CLUENER、Weibo和特定领域的数据集CCKS2019。从结果来看,ERNIE 3.0在所有数据集上的表现都优于基线模型。
机器阅读理解。我们综合评估了ERNIE 3.0在不同方面的机器阅读理解能力,包括广度预测阅读理解(CMRC2018,DuReader,DRCD,DuReader检查表)、多项选择阅读理解(C3,DuReader yesno)、完形填空(CHID,CMRC2019)和稳健性测试(DuReader robust)。在知识增强型预训练的帮助下,ERNIE 3.0超越了基线模型,在所有类型的任务上都有显著的增强。更具体地说,ERNIE 3.0在5个跨度预测任务上实现了至少1.0分的EM改进,在多项选择任务上平均实现了0.89分的准确性改进。此外,在可比较的参数数量下,ERNIE 3.0在C3数据集上的得分为0.6,优于CPM-2。对于稳健性测试,ERNIE 3.0在具有过灵敏度和过稳定性样本的测试集上也表现最好。
法律文件分析。接下来,我们测试了ERNIE 3.0的文档分析能力,我们选择了两个特定领域的法律任务。CAIL2018的这两个数据集都是多标签文档分类任务。ERNIE 3.0的表现优于ERNIE 2.0,增幅显著。
文献检索。文档检索旨在匹配给定查询的文档。我们评估了ERNIE 3.0在搜狗日志上的检索能力。在之前的工作[20]之后,我们报告NDCG@1在测试相同测试集上的性能以及在测试原始测试集和ERNIE 3.0上的MRR性能优于CPM-2。
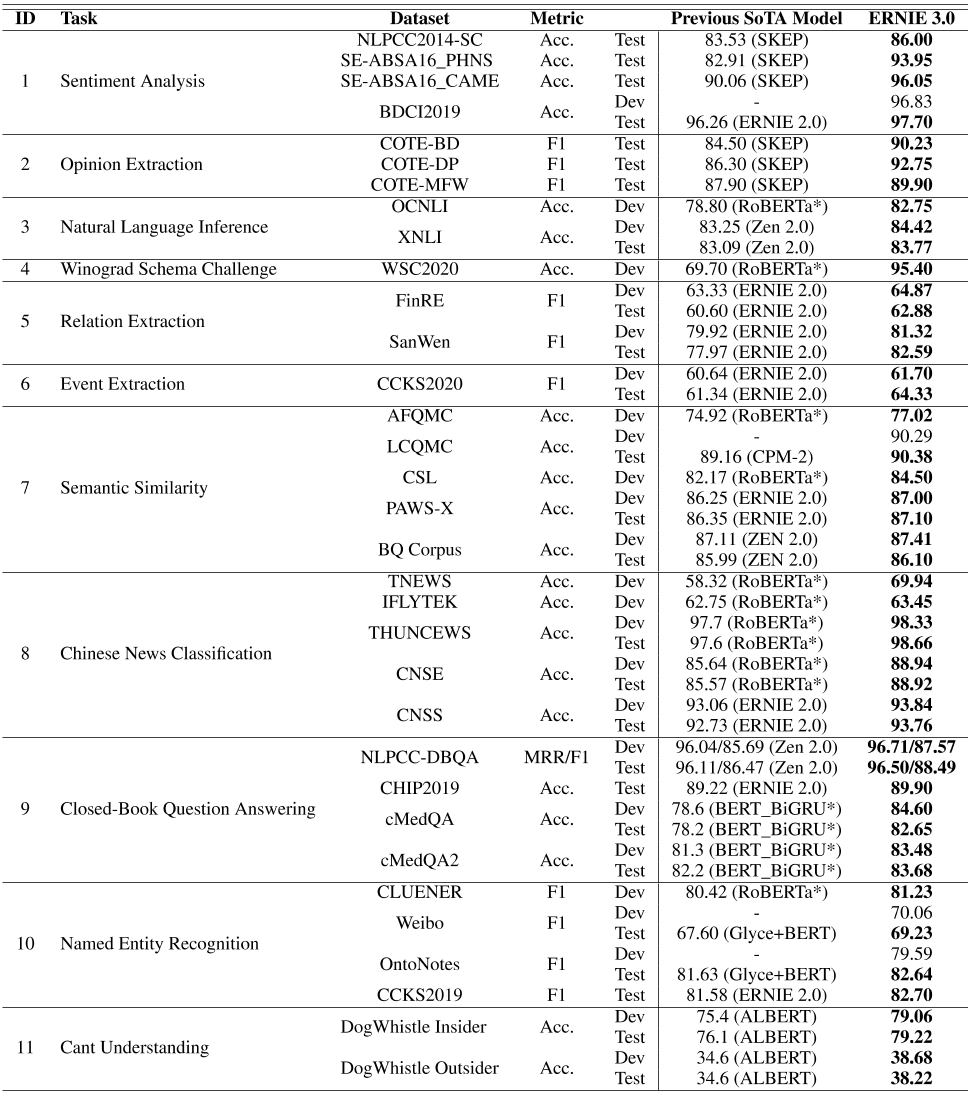
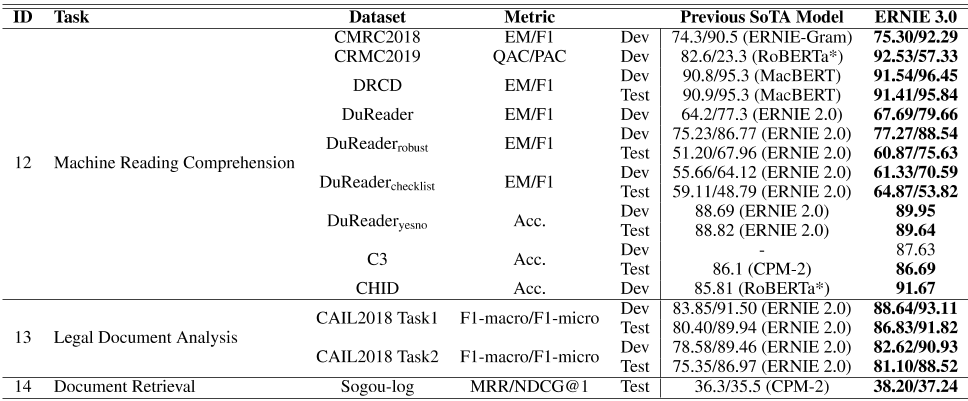
表2:自然语言理解任务的结果。我们将ERNIE 3.0与之前的10条SoTA基线进行了比较,包括CPM-2【20】、ERNIE 2.0【33】、ERNIE Gram【79】、SKEP【80】、RoBERTa wwm ext large【81】(标记为RoBERTa*)、ALBERT【82】、MacBERT【83】、Zen 2.0【84】、Glyce【85】和crossed BERT siamese BiGRU【86】(标记为BERT\\u BiGRU*)。
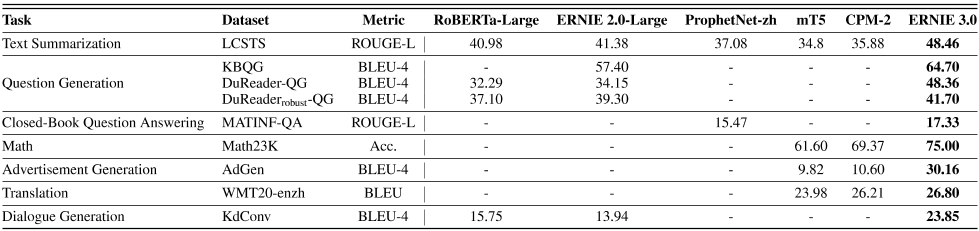
表3:自然语言生成任务的结果。我们在测试集上报告了结果。
4.2.2自然语言生成任务的微调
自然语言生成任务的结果如表3所示。
文本摘要。我们考虑一个大规模的中文短文本摘要(LCSTS)数据集,该数据集需要一个模型来理解文本并提炼关键信息,以生成连贯的、信息丰富的摘要。LCSTS是一个经典的中文文本摘要数据集,由200万条真实中文短文本和新浪微博的短摘要组成。ERNIE 3.0获得了48.46%的Rouge-L分数,在可比较的参数数量(11B)和当前的SoTA ProphetNet zh下,该分数优于CPM-2。
问题生成。问题生成是机器阅读理解(MRC)的反向任务,它要求模型理解文档并根据给定的简短答案生成合理的问题。我们使用了一套三个数据集,包括知识库问题生成(KBQG)、两个名为Dureader和Dureader robust的MRC数据集。与基线相比,ERNIE 3.0在这三个数据集上表现最好。
数学为了测试ERNIE 3.0执行简单算术运算的能力,我们考虑了Math23K数据集,该数据集包含23161个小学生的真实数学单词问题,包括问题描述、结构化方程和答案。对ERNIE 3.0进行了微调,以生成给定问题描述的结构化方程的后缀表达式,然后可以使用Python eval()函数计算最终答案(请注意,“[”和“]”应分别替换为“(”和“)”,并且“%”应替换为“*0.01”,以避免使用Python eval()函数的失败解决方案)。结果表明,ERNIE 3.0是一个很好的数学解算器,与CPM-2 69.37%相比,其精度高达75%。
广告生成。我们考虑ADGEN,包括119K对广告文本和服装规格表从中国电子商务平台。它要求模型生成包含每件衣服的所有给定属性-值对的广告文本。属性值对用冒号连接,几个属性值对根据其段号使用“|”顺序连接。然后,我们将结构属性值对字符串作为ERNIE 3.0的输入。这表明,ERNIE 3.0能够通过从结构输入中提取信息,生成连贯而有趣的长广告文本,与CPM-2相比,BLEU-4的得分提高了19.56%。
翻译对于ERNIE 3.0,我们主要考虑汉语语料库的预训练。为了测试它的多语言能力,我们扩大了词汇量,增加了10K英语子词。在经典的多语言数据集WMT20 enzh上,我们对ERNIE 3.0进行了微调,将英语翻译成汉语。与mT5 xxLarge和CPM-2相比,ERNIE 3.0 17是最好的,表现出优异的多语言能力。
对话一代。接下来,我们评估ERNIE 3.0在对话框生成任务中的作用。我们认为中国的多领域知识驱动的对话数据集,包含4.5K的对话,从三个领域(电影,音乐,旅游)。
我们在上述三个领域的融合数据集上对ERNIE 3.0进行训练和测试,只给出对话历史以生成当前的话语。知识三元组被排除在输入之外,因此可以通过在预训练利用固有知识来测试模型对多回合对话进行模型的能力。与基线相比,ERNIE 3.0将性能提高了8.1个百分点,我们相信知识图大大增强了训练前属性。

表4:雪橇基准测试结果。我们在测试集上报告了结果。
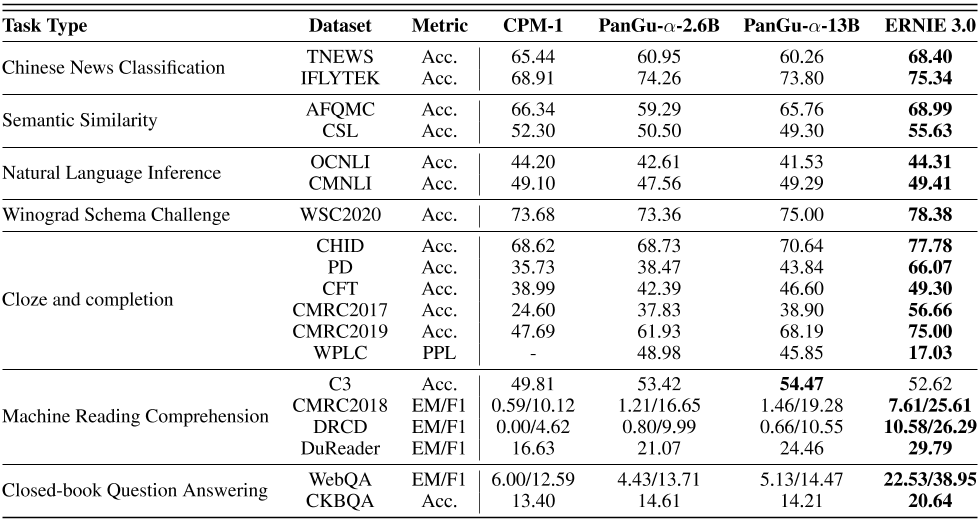
表5:零射击学习任务的结果。
4.2.3 LUGE基准
为了进一步全面方便地评估不同模型的能力,我们在语言理解和生成评估基准(LUGE))18上进行了实验。我们使用LUGE的六个代表性任务(见表4)。ERNIE 3.0比ERNIE 2.0和罗伯塔等领先的预科车型平均提高了5.36%。
4.3Zero-shot学习实验
我们已经证明,ERNIE 3.0在NLU和NLG任务上优于之前的SoTA方法,遵循先训练后微调的范式。在本节中,我们使用零炮设置执行各种类型的任务,其中应用模型时不需要任何梯度更新或微调。与最近提出的大规模语言模型(如CPM-1(2.6B)、盘古-α-2.6B和盘古-α-13B)相比,ERNIE 3.0在大多数下游任务上都取得了很好的性能。最后,我们展示了ERNIE 3.0可以在我们手动收集的450个案例中,在13个不同的任务中生成更连贯、自然和准确的响应。
4.3.1评估
评价方法可分为两类,即基于困惑的方法和基于生成的方法。
•基于困惑的方法。在从CHID和CMRC2017等多个候选中选择一个正确答案的任务中,当将每个答案填充到上下文的空白时,我们比较每个令牌困惑得分19。每个标记的困惑分数较低的将被预测为正确答案。对于需要二进制或多重分类的任务,我们为每个标签分配一个语义上更有意义的名称,并使用提示将上下文和标签形式化为人类可读的文本。然后,这类任务可以被视为多项选择任务。我们使用的提示与CPM-1和PanGu-α中的提示类似。
•基于生成的方法。对于自由形式完成的任务,例如闭卷QA,我们使用波束宽度为8且没有长度惩罚的波束搜索。根据数据集上答案长度的95%百分位点,生成的最大完成长度受到预定义数字的限制。然后使用精确匹配(EM)、F1和胭脂-1等指标。对于限制完成的任务,如提取MRC,我们使用与之前相同的参数进行限制束搜索。为每个样本构造一个Trie树,有效地限制生成空间,只生成给定文本中发生的完成。
4.3.2结果
中文新闻分类。TNEWS和IFLYTEK数据集分别有15和119个类别。我们随机抽取三名候选人作为每个样本的负面标签,并比较这四个选择中的每标记通透性得分。这种抽样策略与CPM-1和PanGu-α相一致,以减少总的计算成本,因为我们需要分别计算每个候选者的每标记通透性分数。ERNIE 3.0在TNEWS上表现良好,甚至与之前最先进的微调方法具有竞争力,在科大讯飞上表现稍好。
语义相似性。我们考虑AFQMC和CSL数据集。ERNIE 3.0的表现大大优于基线。
然而,精度略高于随机猜测模型。这可能部分归因于提示符的次优选择(比如下面两个句子的语义相同/不同:KaTeX parse error: Can't use function '\.' in math mode at position 8: SENT\_A\̲.̲SENT_B.)。
自然语言推理。ERNIE 3.0是在两个NLI数据集上进行评估的,即OCNLI和CMNLI,其中CMNLI通过将英语翻译成汉语,由XNLI和MNLI组成。我们使用提示作为
S
E
N
T
_
A
?
N
否
/
是
E
S
/
M
A
Y
B
E
,
SENT\_A?N否/是ES/M AYBE,
SENT_A?N否/是ES/MAYBE,SENT\\u B。ERNIE 3.0的性能与基线相当,这表明对于零炮NLI任务的预训练模型,仍有很大的改进空间。
Winograd Schema Challenge:我们将WSC2020数据集形式化为一个多选完成任务,其中用每个候选词替换一个代词,以计算样本的每个标记的复杂度。与盘古-α-13B相比,ERNIE 3.0将性能提高了3.38个百分点。
完形填空。在CHID数据集上,我们将每个只包含一个空白单词的句子分割为样本,并将其形式化为多项选择任务。ERNIE 3.0在基线中取得了最好的成绩。对于长上下文中文单词预测(Chinese WPLC),一个样本由一个蒙面文本和一个正确的单词组成。在盘古-α之后,我们用正确的单词替换面具标记,并计算整个句子的困惑分数。与盘古-α相比,ERNIE 3.0的困惑得分要低得多。在CMRC2019数据集上,我们从原始候选样本中为每个空白随机抽取三个阴性候选样本,然后应用beam搜索来计算样本的最佳路径。我们还将PD、CFT和CMRC2017形式化为多个选择任务,其中以空白前的文本为输入,多个选择是整个文本中出现的单词。ERNIE 3.0以巨大的差距超过了基线。
机器阅读理解。我们考虑四个MRC数据集。在C3这一多选机器阅读理解任务中,我们使用提示作为问题:
Q
U
E
S
T
I
O
N
?
回
答
:
Q UESTION?回答:
QUESTION?回答:C选择。答案在以下文件中:KaTeX parse error: Can't use function '\.' in math mode at position 61: …ase方法评估了ERNIE 3\̲.̲0,提示为document:D文档。问题:KaTeX parse error: Can't use function '\.' in math mode at position 22: …ION?答案:。ERNIE 3\̲.̲0在CMRC2018、DRCD…Q UESTION?答案:)。与基线相比,ERNIE 3.0实现了更好的性能。我们在第节中详细分析了CKBQA数据集。5.

表6:在我们收集的450例病例中手动评估零炮生成性能。(我们报告了连贯性、流利性和准确性的平均得分,分别为[0,1,2])
4.3.3案例研究
我们手动收集450个案例,评估当前大规模预训练模型在5种不同类型的13项任务(包括问答、口译、对话、文本生成和摘要)上的零镜头生成能力。在不人道的评估中,注释者被要求在[0,1,2]的范围内对生成质量进行评分。我们在Tab中报告了连贯性、流利性和准确性的平均得分。6,并在Tab中展示了ERNIE 3.0的一些零炮代。与CPM-1、PLUG、PanGu-α20相比,ERNIE 3.0平均可以生成最连贯、流畅和准确的文本。下面列出了三个评分指标的引言,并在选项卡中提供了评分详细信息。8.
•一致性衡量生成是否相关,是否与上下文一致。
•流利度评估生成的文本是自然的还是可读的。一篇流利的文本在生成的文本之间不应该有语义矛盾。
•准确度是评估生成的文本是否与基本事实相同的指标。
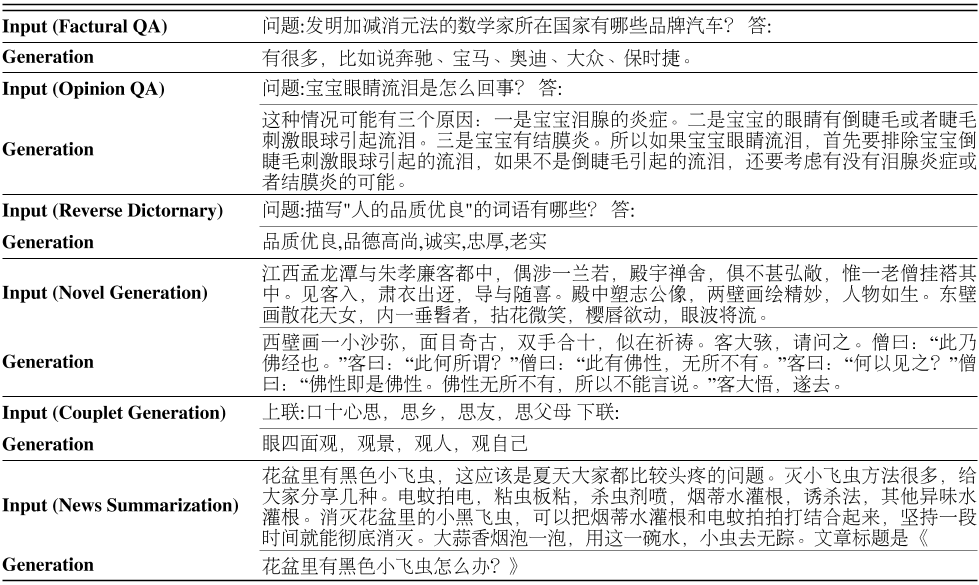
表7:ERNIE 3.0的零炮代示意图。

表8:零投篮生成的得分细节。
4.4关于SuperGLUE的实验

表9:由超级胶水评估服务器评分的超级胶水测试结果(结果记录在2021年7月3日)https://super.gluebenchmark.com/leaderboard).
作为自然语言理解的多任务基准,SuperGLUE[3]通常用于评估预训练模型的性能。我们还测试了ERNIE 3.0在SuperGLUE上的性能,SuperGLUE覆盖了各种NLP数据集,如下所示。
•BoolQ(Boolean Questions,[56])是一项QA任务,其中每个示例包括一篇短文和一个关于该短文的是/否问题。这项任务是用是或否回答问题,这项任务的衡量标准是准确性。
•CB(承诺银行[88])是一个不平衡的自然语言推理任务语料库。使用精度和宏F1对任务进行评估。
•COPA(合理选择[89])是一项基于常识知识的因果推理任务。
这些数据来自博客和与摄影相关的百科全书。在最初的工作之后,我们使用准确性来评估这项任务。
•MultiRC(多句阅读理解[90])是一项QA任务,其中每个示例包括一个上下文段落、一个关于该段落的问题以及一系列可能的答案。系统必须预测哪些答案是正确的,哪些是错误的。评估指标是所有答案选项的F1(F1 a)和每个问题的答案集(EM)的精确匹配。
•记录(使用常识推理数据集[91]进行阅读理解)是一项多项选择QA任务。
它要求模型根据新闻文章的上下文和完形填空式问题选择一个实体来完成答案。这项任务的评估采用最大(所有提及)标记级别F1和精确匹配。
•RTE(识别文本蕴涵[92])数据集来自一系列关于文本蕴涵的年度竞赛。这是一个自然语言推理语料库,评估准确。
•WiC(上下文中的单词[93])是一项词义消歧任务,以准确度作为评估指标,对句子对进行二元分类。
•WSC(Winograd Schema Challenge[94])是一项共指消解任务,其中示例包括一个带有代词的句子,以及一系列作为选项的句子中的名词短语。系统必须从提供的选项中选择正确的代词指代物。这项任务的评估是准确的。
与RoBERTa【95】和DeBERTa【96】中使用的预训练语料库类似,我们为ERNIE 3.0编制了英语预训练语料库,包括英语维基百科、BookCorpus【97】、CC News【98】、OpenWebText【99】、Stories【100】。
如表9所示,ERNIE 3.0超越T5[1]和德贝塔[96],得分90.6,在SuperGLUE Benchmark中排名第一。
5.分析
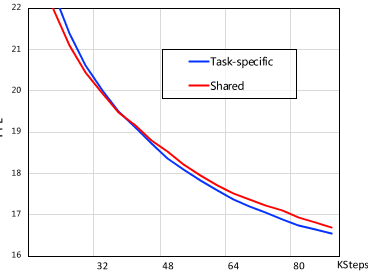
图3:NLG预训练任务相对于训练步骤的困惑变化。
任务特定表征模块的有效性为了验证任务特定网络的有效性,我们将我们提出的结构与在各种训练前任务下共享参数的结构进行了比较。对于消融测试,我们选择理解和生成作为两种不同的训练范式,并利用第3.2节中提到的相应任务。统一网络遵循基本模型设置(12层、768 DIM、12个注意力头),每个任务范式的任务特定网络设置为3层、256 DIM和4个注意力头。对于对比模型,任务特定网络在不同的任务范式中共享。
图3展示了NLG任务在预训练过程中的困惑变化。
如图3所示,模型具有针对不同任务范式的特定于任务的网络,可以达到更高的收敛速度。
此外,随着训练的进展,与具有共享任务特定网络的模型相比,性能差距变得更大。
实验结果表明了所提出的任务特定网络的有效性,并证明了区分不同任务的必要性。
通用知识文本预测进行了一组烧蚀实验,以评估通用知识文本预测任务的性能。关系抽取任务是一个典型的知识驱动任务,旨在预测给定句子中提到的两个实体之间的关系。具体来说,我们添加了四个特殊标记,[HD]、/HD]、[TL]和[/TL]来分别识别前面提到的实体和后面提到的实体,然后对上述四个特殊标记的最终表示的总和进行关系分类。我们在SanWen和FinRE数据集上构建了实验,如表10所示,知识增强策略在关系提取任务上取得了令人印象深刻的实证性能。
此外,基于CKBQA的零镜头生成实验也证实了通用知识文本预测任务的有效性。具体来说,基于知识的问答(KBQA)任务需要一个模型来根据知识图搜索和推理正确的答案。它适用于使用KBQA任务测量预先训练的语言模型的知识学习能力。我们使用“问题:$问题?答案:”作为零镜头学习的提示,然后将我们提出的模型的性能与CKBQA数据集上几个最先进的预训练语言模型进行比较。如表5所示,在CKBQA数据集中,ERNIE 3.0显著优于盘古-α和CPM-1,这表明ERNIE 3.0具有记忆和学习更多知识的能力。
渐进式学习加速收敛我们在两种架构设置(包括ERNIE基地和ERNIE 1)上记录了训练收敛速度。5B,其中ERNIE基地的架构设置遵循[7]和ERNIE 1。5B模型由48层组成,隐藏大小为1536和24个注意力头。如选项卡所示。11,我们记录了模型的损失值收敛到ERNIE 3.0的损失值的时间。对于ERNIE基模型,收敛时间从11小时缩短到4小时,ERNIE 1的收敛时间缩短了65.21%。5B,收敛时间缩短了48%。对于这两种设置,我们在8个NVIDIA Tesla V100 GPU上进行预训练。对于ERNIE Base,我们将批次大小从8增加到2048,序列长度从128增加到512,学习率从0线性增加到1e-4,在渐进预热阶段,辍学率保持为0。ERNIE 1号。5B,我们逐步将批量大小从8增加到8192,学习率从0增加到6e-4,辍学率也保持在0。实验的其余设置与[7]相同。ERNIE 1号。5B,为了在GPU内存约束下实现峰值批量大小,在预训练期间使用梯度累积策略。

表10:通用知识文本预测任务的消融实验。
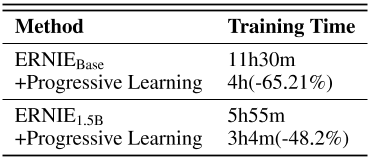
表11:逐步学习以加速训练。
6结论
我们提出了ERNIE 3.0框架,在包含纯文本和知识图的4TB语料库上预训练一个知识增强的100亿参数模型。为了通过零镜头学习、少量镜头学习和微调来处理语言理解和生成任务,ERNIE 3.0设计了一个统一的预训练框架,该框架集成了自动编码器网络和自回归网络。我们对来自不同任务范式和领域的各种数据集进行了广泛的实验,结果表明,与之前最先进的预训练模型相比,ERNIE 3.0是有效的。
参考文献
[1] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. CoRR , abs/1910.10683, 2019.
[2] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems , volume 33, pages 1877–1901. Curran Associates, Inc., 2020.
[3] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. SuperGLUE: A stickier benchmark for general-purpose language understanding systems. arXiv preprint 1905.00537 , 2019.
[4] Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. arXiv preprint arXiv:1802.05365 , 2018.
[5] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. URL https://s3-us-west-2. amazonaws. com/openai-assets/researchcovers/languageunsupervised/language understanding paper. pdf , 2018.
[6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 , 2018.
[7] Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xin Tian, Danxiang Zhu, Hao Tian, and Hua Wu. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223 , 2019.
[8] Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing , pages 1631–1642, 2013.
[9] Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. arXiv preprint arXiv:1508.05326 , 2015.
[10] Baotian Hu, Qingcai Chen, and Fangze Zhu. Lcsts: A large scale chinese short text summarization dataset. arXiv preprint arXiv:1506.05865 , 2015.
[11] Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050 , 2003.
[12] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. CoRR , abs/1909.08053, 2019.
[13] William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. CoRR , abs/2101.03961, 2021.
[14] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 , 2020.
[15] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Blog , 1(8), 2019.
[16] Matthew Hutson. Robo-writers: the rise and risks of language-generating ai. Website, 2021. https://www.na ture.com/articles/d41586-021-00530-0 .
[17] Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts. Neural computation , 3(1):79–87, 1991.
[18] Michael I Jordan and Robert A Jacobs. Hierarchical mixtures of experts and the em algorithm. Neural computation , 6(2):181–214, 1994.
[19] Zhengyan Zhang, Xu Han, Hao Zhou, Pei Ke, Yuxian Gu, Deming Ye, Yujia Qin, Yusheng Su, Haozhe Ji, Jian Guan, et al. Cpm: A large-scale generative chinese pre-trained language model. arXiv preprint arXiv:2012.00413 , 2020.
[20] Zhengyan Zhang, Yuxian Gu, Xu Han, Shengqi Chen, Chaojun Xiao, Zhenbo Sun, Yuan Yao, Fanchao Qi, Jian Guan, Pei Ke, et al. Cpm-2: Large-scale cost-effective pre-trained language models. arXiv preprint arXiv:2106.10715 , 2021.
[21] Junyang Lin, Rui Men, An Yang, Chang Zhou, Ming Ding, Yichang Zhang, Peng Wang, Ang Wang, Le Jiang, Xianyan Jia, et al. M6: A chinese multimodal pretrainer. arXiv preprint arXiv:2103.00823 , 2021.
[22] Wei Zeng, Xiaozhe Ren, Teng Su, Hui Wang, Yi Liao, Zhiwei Wang, Xin Jiang, ZhenZhang Yang, Kaisheng Wang, Xiaoda Zhang, et al. Pangu- alpha : Large-scale autoregressive pretrained chinese language models with auto-parallel computation. arXiv preprint arXiv:2104.12369 , 2021.
[23] Hyperclova from naver. https://medium.com/ai-trend/if-you-look-at-the-direction-of-nave r-ai-you-can-feel-the-potential-of-ai-network-bb129aa9b73a .
[24] Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. Ernie: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129 , 2019.
[25] Matthew E Peters, Mark Neumann, Robert L Logan IV, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A Smith. Knowledge enhanced contextual word representations. arXiv preprint arXiv:1909.04164 , 2019.
[26] Bin He, Di Zhou, Jinghui Xiao, Qun Liu, Nicholas Jing Yuan, Tong Xu, et al. Integrating graph contextualized knowledge into pre-trained language models. arXiv preprint arXiv:1912.00147 , 2019.
[27] Wenhan Xiong, Jingfei Du, William Yang Wang, and Veselin Stoyanov. Pretrained encyclopedia: Weakly supervised knowledge-pretrained language model. arXiv preprint arXiv:1912.09637 , 2019.
[28] Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. Kepler: A unified model for knowledge embedding and pre-trained language representation. Transactions of the Association for Computational Linguistics , 9:176–194, 2021.
[29] Tianxiang Sun, Yunfan Shao, Xipeng Qiu, Qipeng Guo, Yaru Hu, Xuanjing Huang, and Zheng Zhang. Colake: Contextualized language and knowledge embedding. arXiv preprint arXiv:2010.00309 , 2020.
[30] Wangchunshu Zhou, Dong-Ho Lee, Ravi Kiran Selvam, Seyeon Lee, Bill Yuchen Lin, and Xiang Ren. pretraining text-to-text transformers for concept-centric common sense. arXiv preprint arXiv:2011.07956 , 2020.
[31] Ruize Wang, Duyu Tang, Nan Duan, Zhongyu Wei, Xuanjing Huang, Cuihong Cao, Daxin Jiang, Ming Zhou, et al. K-adapter: Infusing knowledge into pre-trained models with adapters. arXiv preprint arXiv:2002.01808 , 2020.
[32] Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S Weld, Luke Zettlemoyer, and Omer Levy. Spanbert: Improving pre-training by representing and predicting spans. Transactions of the Association for Computational Linguistics , 8:64–77, 2020.
[33] Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, and Haifeng Wang. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 34, pages 8968–8975, 2020.
[34] Zihang Dai, Zhilin Yang, Yiming Yang, William W Cohen, Jaime Carbonell, Quoc V Le, and Ruslan salakhutdinov. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860 , 2019.
[35] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V Le. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237 , 2019.
[36] He Bai, Peng Shi, Jimmy Lin, Luchen Tan, Kun Xiong, Wen Gao, and Ming Li. Segabert: Pre-training of segment-aware BERT for language understanding. CoRR , abs/2004.14996, 2020.
[37] Siyu Ding, Junyuan Shang, Shuohuan Wang, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. Ernie-doc: The retrospective long-document modeling transformer. arXiv preprint arXiv:2012.15688 , 2020.
[38] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 7871–7880, 2020.
[39] Dongling Xiao, Han Zhang, Yukun Li, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. Ernie-gen: An enhanced multi-flow pre-training and fine-tuning framework for natural language generation, 2020.
[40] Mike Mintz, Steven Bills, Rion Snow, and Dan Jurafsky. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP , pages 1003–1011, 2009.
[41] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 , 2014.
[42] Mingxing Tan and Quoc V. Le. Efficientnetv2: Smaller models and faster training. CoRR , abs/2104.00298, 2021. [43] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research , 15(1):1929– 1958, 2014.
[44] Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. ICLR , 2018.
[45] Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. Clue: A chinese language understanding evaluation benchmark. arXiv preprint arXiv:2004.05986 , 2020.
[46] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 , 2016.
[47] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014.
[48] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis , pages 1–16. IEEE, 2020.
[49] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. arXiv preprint arXiv:2102.12092 , 2021.
[50] Yanzeng Li, Tingwen Liu, Diying Li, Quangang Li, Jinqiao Shi, and Yanqiu Wang. Character-based bilstm-crf incorporating pos and dictionaries for chinese opinion target extraction. In Asian Conference on Machine Learning , pages 518–533. PMLR, 2018.
[51] Alexis Conneau, Guillaume Lample, Ruty Rinott, Adina Williams, Samuel R Bowman, Holger Schwenk, and Veselin Stoyanov. Xnli: Evaluating cross-lingual sentence representations. arXiv preprint arXiv:1809.05053 , 2018.
[52] Ziran Li, Ning Ding, Zhiyuan Liu, Haitao Zheng, and Ying Shen. Chinese relation extraction with multi-grained information and external linguistic knowledge. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 4377–4386, 2019.
[53] Jingjing Xu, Ji Wen, Xu Sun, and Qi Su. A discourse-level named entity recognition and relation extraction dataset for chinese literature text. arXiv preprint arXiv:1711.07010 , 2017.
[54] Xin Liu, Qingcai Chen, Chong Deng, Huajun Zeng, Jing Chen, Dongfang Li, and Buzhou Tang. Lcqmc: A largescale chinese question matching corpus. In Proceedings of the 27th International Conference on Computational Linguistics , pages 1952–1962, 2018.
[55] Yinfei Yang, Yuan Zhang, Chris Tar, and Jason Baldridge. Paws-x: A cross-lingual adversarial dataset for paraphrase identification. arXiv preprint arXiv:1908.11828 , 2019.
[56] Jing Chen, Qingcai Chen, Xin Liu, Haijun Yang, Daohe Lu, and Buzhou Tang. The bq corpus: A large-scale domain-specific chinese corpus for sentence semantic equivalence identification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 4946–4951, 2018.
[57] LTD IFLYTEK CO. Iflytek: a multiple categories chinese text classifier. competition official website, 2019.
[58] Bang Liu, Di Niu, Haojie Wei, Jinghong Lin, Yancheng He, Kunfeng Lai, and Yu Xu. Matching article pairs with graphical decomposition and convolutions. arXiv preprint arXiv:1802.07459 , 2018.
[59] Sheng Zhang, Xin Zhang, Hui Wang, Jiajun Cheng, Pei Li, and Zhaoyun Ding. Chinese medical question answer matching using end-to-end character-level multi-scale cnns. Applied Sciences , 7(8):767, 2017.
[60] Sheng Zhang, Xin Zhang, Hui Wang, Lixiang Guo, and Shanshan Liu. Multi-scale attentive interaction networks for chinese medical question answer selection. IEEE Access , 6:74061–74071, 2018.
[61] Peng Li, Wei Li, Zhengyan He, Xuguang Wang, Ying Cao, Jie Zhou, and Wei Xu. Dataset and neural recurrent sequence labeling model for open-domain factoid question answering. arXiv preprint arXiv:1607.06275 , 2016. [62] Nanyun Peng and Mark Dredze. Named entity recognition for chinese social media with jointly trained embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing , pages 548–554, 2015.
[63] Ralph Weischedel, Sameer Pradhan, Lance Ramshaw, Martha Palmer, Nianwen Xue, Mitchell Marcus, Ann Taylor, Craig Greenberg, Eduard Hovy, Robert Belvin, et al. Ontonotes release 4.0. LDC2011T03, Philadelphia, Penn.: Linguistic Data Consortium , 2011.
[64] Yiming Cui, Ting Liu, Li Xiao, Zhipeng Chen, Wentao Ma, Wanxiang Che, Shijin Wang, and Guoping Hu. A span-extraction dataset for chinese machine reading comprehension. CoRR , abs/1810.07366, 2018.
[65] Yiming Cui, Ting Liu, Ziqing Yang, Zhipeng Chen, Wentao Ma, Wanxiang Che, Shijin Wang, and Guoping Hu. A sentence cloze dataset for chinese machine reading comprehension. arXiv preprint arXiv:2004.03116 , 2020.
[66] Chih Chieh Shao, Trois Liu, Yuting Lai, Yiying Tseng, and Sam Tsai. Drcd: a chinese machine reading comprehension dataset. arXiv preprint arXiv:1806.00920 , 2018.
[67] Wei He, Kai Liu, Jing Liu, Yajuan Lyu, Shiqi Zhao, Xinyan Xiao, Yuan Liu, Yizhong Wang, Hua Wu, Qiaoqiao She, et al. Dureader: a chinese machine reading comprehension dataset from real-world applications. arXiv preprint arXiv:1711.05073 , 2017.
[68] Hongxuan Tang, Jing Liu, Hongyu Li, Yu Hong, Hua Wu, and Haifeng Wang. Dureaderrobust: A chinese dataset towards evaluating the robustness of machine reading comprehension models. arXiv preprint arXiv:2004.11142 , 2020.
[69] Kai Sun, Dian Yu, Dong Yu, and Claire Cardie. Investigating prior knowledge for challenging chinese machine reading comprehension. Transactions of the Association for Computational Linguistics , 8:141–155, 2020.
[70] Chujie Zheng, Minlie Huang, and Aixin Sun. Chid: A large-scale chinese idiom dataset for cloze test. arXiv preprint arXiv:1906.01265 , 2019.
[71] Chaojun Xiao, Haoxi Zhong, Zhipeng Guo, Cunchao Tu, Zhiyuan Liu, Maosong Sun, Yansong Feng, Xianpei Han, Zhen Hu, Heng Wang, et al. Cail2018: A large-scale legal dataset for judgment prediction. arXiv preprint arXiv:1807.02478 , 2018.
[72] Canwen Xu, Wangchunshu Zhou, Tao Ge, Ke Xu, Julian McAuley, and Furu Wei. Blow the dog whistle: A Chinese dataset for cant understanding with common sense and world knowledge. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 2139–2145, Online, June 2021. Association for Computational Linguistics.
[73] Chenyan Xiong, Zhuyun Dai, Jamie Callan, Zhiyuan Liu, and Russell Power. End-to-end neural ad-hoc ranking with kernel pooling. In Proceedings of the 40th International ACM SIGIR conference on research and development in information retrieval , pages 55–64, 2017.
[74] Canwen Xu, Jiaxin Pei, Hongtao Wu, Yiyu Liu, and Chenliang Li. Matinf: A jointly labeled large-scale dataset for classification, question answering and summarization. arXiv preprint arXiv:2004.12302 , 2020.
[75] Yan Wang, Xiaojiang Liu, and Shuming Shi. Deep neural solver for math word problems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 845–854, 2017.
[76] Zhihong Shao, Minlie Huang, Jiangtao Wen, Wenfei Xu, and Xiaoyan Zhu. Long and diverse text generation with planning-based hierarchical variational model. arXiv preprint arXiv:1908.06605 , 2019.
[77] Loïc Barrault, Magdalena Biesialska, Ondřej Bojar, Marta R Costa-jussà, Christian Federmann, Yvette Graham, Roman Grundkiewicz, Barry Haddow, Matthias Huck, Eric Joanis, et al. Findings of the 2020 conference on machine translation (wmt20). In Proceedings of the Fifth Conference on Machine Translation , pages 1–55, 2020.
[78] Hao Zhou, Chujie Zheng, Kaili Huang, Minlie Huang, and Xiaoyan Zhu. Kdconv: a chinese multi-domain dialogue dataset towards multi-turn knowledge-driven conversation. arXiv preprint arXiv:2004.04100 , 2020.
[79] Dongling Xiao, Yu-Kun Li, Han Zhang, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. Ernie-gram: pretraining with explicitly n-gram masked language modeling for natural language understanding. arXiv preprint arXiv:2010.12148 , 2020.
[80] Hao Tian, Can Gao, Xinyan Xiao, Hao Liu, Bolei He, Hua Wu, Haifeng Wang, and Feng Wu. Skep: Sentiment knowledge enhanced pre-training for sentiment analysis. arXiv preprint arXiv:2005.05635 , 2020.
[81] Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, and Guoping Hu. Pre-training with whole word masking for chinese bert. arXiv preprint arXiv:1906.08101 , 2019.
[82] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942 , 2019.
[83] Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Shijin Wang, and Guoping Hu. Revisiting pre-trained models for chinese natural language processing. arXiv preprint arXiv:2004.13922 , 2020.
[84] Yan Song, Tong Zhang, Yonggang Wang, and Kai-Fu Lee. Zen 2.0: Continue training and adaption for n-gram enhanced text encoders. arXiv preprint arXiv:2105.01279 , 2021.
[85] Yuxian Meng, Wei Wu, Fei Wang, Xiaoya Li, Ping Nie, Fan Yin, Muyu Li, Qinghong Han, Xiaofei Sun, and Jiwei Li. Glyce: Glyph-vectors for chinese character representations. arXiv preprint arXiv:1901.10125 , 2019.
[86] Xiongtao Cui and Jungang Han. Chinese medical question answer matching based on interactive sentence representation learning. arXiv preprint arXiv:2011.13573 , 2020.
[87] Matt Post. A call for clarity in reporting BLEU scores. In Proceedings of the Third Conference on Machine Translation: Research Papers , pages 186–191, Belgium, Brussels, October 2018. Association for Computational Linguistics.
[88] Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. The CommitmentBank: Investigating projection in naturally occurring discourse. 2019. To appear in proceedings of Sinn und Bedeutung 23. Data can be found at https://github.com/mcdm/CommitmentBank/.
[89] Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S. Gordon. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In 2011 AAAI Spring Symposium Series , 2011.
[90] Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages 252–262, 2018.
[91] Sheng Zhang, Xiaodong Liu, Jingjing Liu, Jianfeng Gao, Kevin Duh, and Benjamin Van Durme. ReCoRD: Bridging the gap between human and machine commonsense reading comprehension. arXiv preprint 1810.12885 , 2018.
[92] Ido Dagan, Oren Glickman, and Bernardo Magnini. The PASCAL recognising textual entailment challenge. In Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising tectual entailment , pages 177–190. Springer, 2006.
[93] Mohammad Taher Pilehvar and Jose Camacho-Collados. WiC: The word-in-context dataset for evaluating context-sensitive meaning representations. In Proceedings of NAACL-HLT , 2019.
[94] Hector J Levesque, Ernest Davis, and Leora Morgenstern. The Winograd schema challenge. In AAAI Spring Symposium: Logical Formalizations of Commonsense Reasoning , volume 46, page 47, 2011.
[95] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach, 2019. cite arxiv:1907.11692.
[96] Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. Deberta: Decoding-enhanced bert with disentangled attention, 2020.
[97] Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE international conference on computer vision , pages 19–27, 2015.
[98] Sebastian nagel. 2016. cc-news. http://web.archive.org/save/http://commoncrawl.org/2016/10/ news-dataset-available .
[99] Aaron gokaslan and vanya cohen. 2019. openweb-text corpus. http://web.archive.org/save/http://Sk ylion007.github.io/OpenWebTextCorpus .
[100] Trieu H Trinh and Quoc V Le. A simple method for commonsense reasoning. arXiv preprint arXiv:1806.02847 , 2018.

















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









