







书生·浦语(InternLM),作为上海人工智能实验室发布的语言大模型系列,近期在阿里的魔搭社区全球首发开源了其200亿参数的版本(InternLM-20B和InternLM-Chat-20B),这一更新距离上次开源的70亿参数版本(InternLM-7B)仅过去两个月。此次更新不仅体现在模型参数的增加上,更在数据集、预训练、微调和部署,以及评测和应用的开源工具链上实现了全线升级。
其中,OpenCompass作为新升级工具链中的大模型评测工具,在50多个数据集和30多万道题目的严格评测下,展示了书生·浦语InternLM-20B的综合学习能力,使其成为了最接近GPT-3.5的大模型之一。这一成就不仅体现了书生·浦语在语言理解和生成能力上的显著提升,也标志着国产大模型在技术研发和应用方面取得了重要进展。
此外,上海人工智能实验室还开发了针对Llama2的多模态大模型工具链Accessory,为国产多模态大模型的开发做出了显著贡献,进一步展示了其在人工智能领域的创新能力和技术实力。
笔者通过参与训练营,预计将体会,从基础使用,到构建RAG应用、使用Xtuner微调、Opencompass评测、Lmdeploy部署等,像打怪升级一样的大模型知识进阶之路。
在第一期课程中,最有意思的部分,莫过于打通大模型全栈链路的 OpenCompass 了。在本期笔记中,将会详细分享 OpenCompass 的特点和应用前景。
此外,InterLM2 优异的表现,在其技术报告中进行了翔实的实验验证和系统性总结。笔者也会对该报告进行梳理,并总结自己的想法。
课程链接:https://www.bilibili.com/video/BV1Vx421X72D/?vd_source=e4bd6a61d5545c40ca2fa4bd29444b66
OpenCompass
要想了解 OpenCompass, 首先需要了解大模型在工业界的应用流程。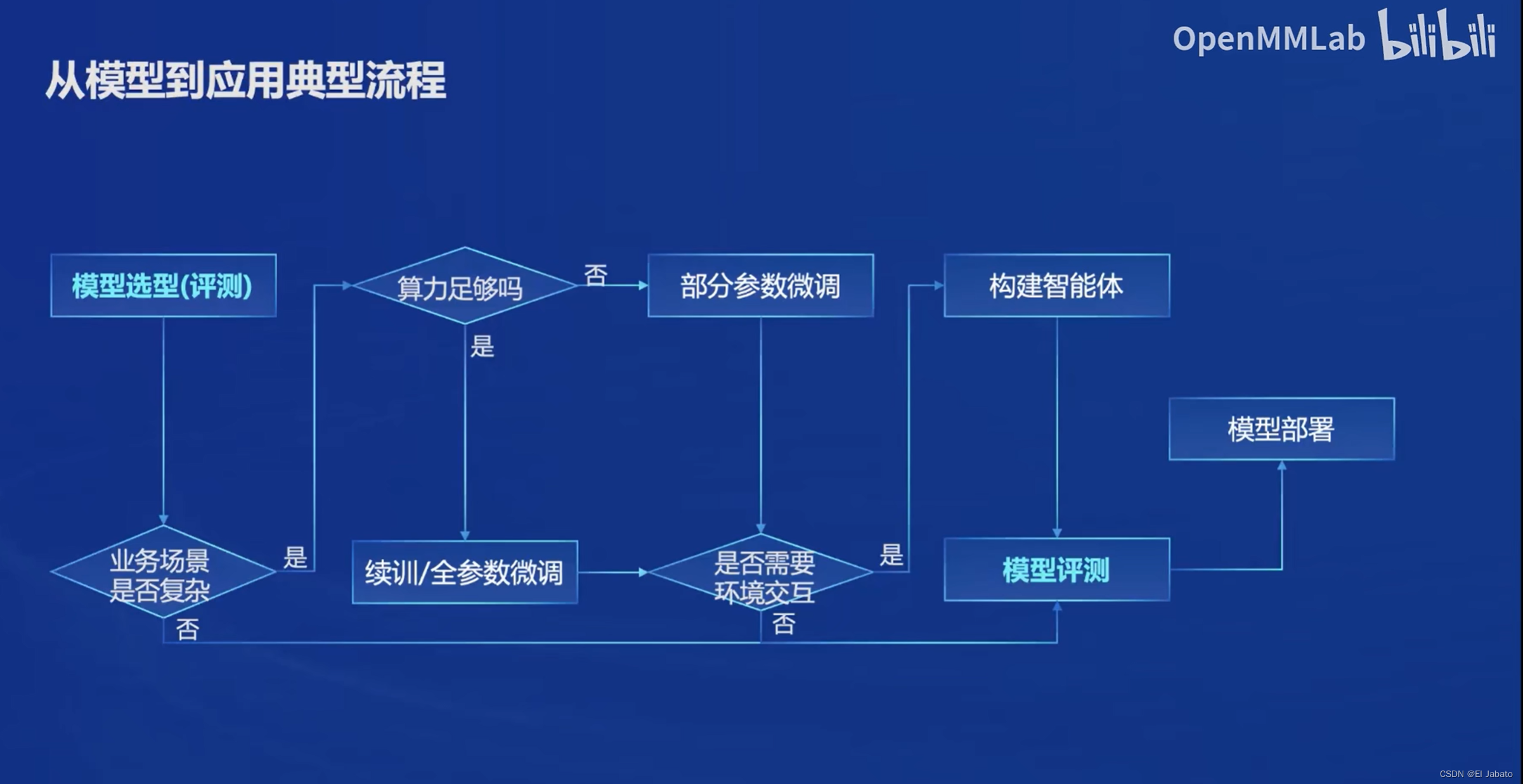
我们可以看到,在应用过程中,有三方面需要注意:
- 下游任务的复杂性和数据
- 大模型微调
- Agent 和环境交互问题
OpenCompass 能够全链路式打通各个模块,方便大模型落地过程中各个环节的调整和验证。
OpenCompass 是如何打通上下游的
openCompass评测工具是由书生大模型(internLM)研发团队开源的,它属于市面上稀有的代码级开源评测项目。此工具旨在提供一个完整的评测生命周期,涵盖数据集处理、模型加载与生成、结果评测与指标计算等流程。openCompass的显著特点之一是它集成了大量的数据集和相应的预处理脚本,极大地减轻了用户开发预处理脚本的工作量。
openCompass基于MMEngine框架构建,通过Partitioner模块将评测任务拆分为多个最小粒度的task元素,并由Runner模块有序执行这些task。此外,openCompass还依赖于上海AI Lab的openICL项目,特别是其中的icl_inference和icl_retriever模块,用于通过In-context-learning方式从数据集中选择样本并“做题”。
icl_retriever模块提供了多种样本选择方式,如基于BM25、KNN的检索方式,以及zeroshot方式,帮助大模型更好地理解当前数据样本。而icl_inference模块则支持两种生成方式——ppl和gen,分别针对base版模型和chat版模型,以适应不同形态的大模型评测需求。
openCompass的这套评测流程和工具链为大模型的开发和评测提供了极大的便利,特别是对于那些需要处理大量数据集和进行复杂评测任务的场景。
InternLM2 技术报告阅读
InternLM2作为一个开源的大型语言模型(LLM),在多个维度和基准测试中展示了超越前辈模型的性能。
InternLM2的模型结构是基于LLaMA架构进行改进的,以提高训练效率和性能;同时,它能够利用 InternEvo 进行预训练、监督微调(SFT)和基于人类反馈的强化学习(RLHF)。
由于报告内容非常多,笔者将对技术报告中的部分进行思考总结。感兴趣的同学建议阅读原文 https://arxiv.org/abs/2403.17297
背景知识:Transformer 和 LLaMa
Transformer架构因其出色的并行化能力而广泛应用于大型语言模型(LLMs)中。像LLaMA、Falcon、Qwen、Baichuan和Mistral等模型利用Transformer骨干来提高训练效率和性能。
这些模型通过用RMSNorm替换LayerNorm,并采用如SwiGLU等激活函数,优化了GPU在并行处理中的利用率。Transformer的优势在于它能够充分利用GPU的力量,加速LLMs的训练,并在数千个GPU之间实现高效扩展性能。这一结构设计原则已成为LLMs开发的标准,推动了自然语言处理领域的进步。
LLaMA模型采用了一种基于Transformer的架构,这是一种由多个自注意力机制和前馈神经网络组成的深度神经网络结构。
相比标准的Transformer,LLaMA在模型结构上进行了改进,包括前置层归一化+RMSNorm归一化函数、门控线性单元和SwiGLU激活函数以及旋转位置编码RoPE等。
GQA:加速和节省算力
分组查询注意力(GQA)通过使InternLM2系列模型能够高效地处理非常长的上下文信息,从而有助于这些模型实现高速度和低GPU内存使用。
通过使用GQA,模型能够快速有效地处理信息,同时利用极少的GPU内存,使它们在处理大量数据时表现出高效率,并在规模上保持性能。
那么, GQA 具体是如何工作的呢?
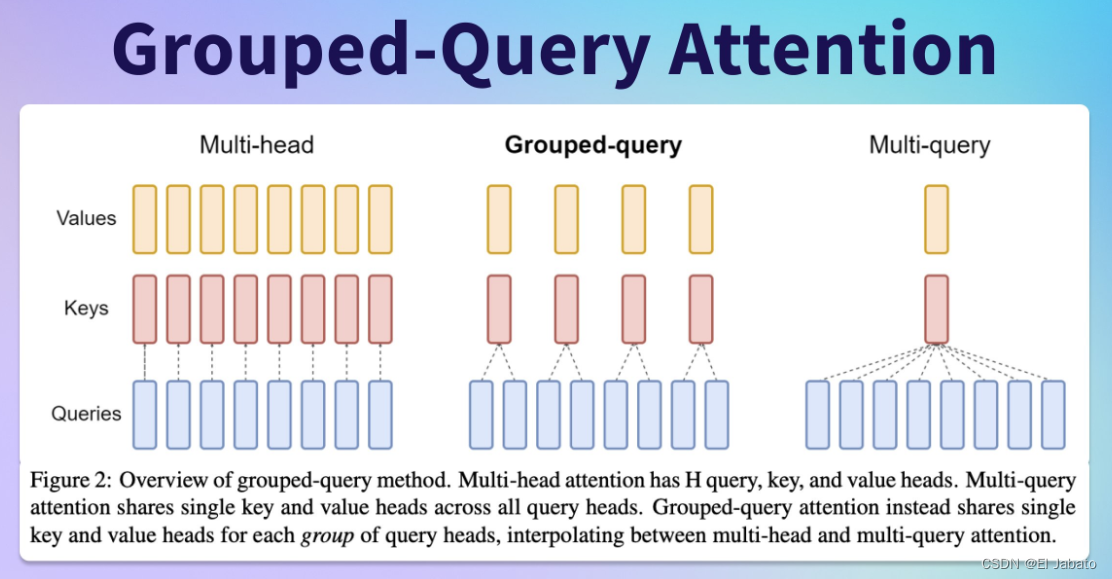
首先,GQA将标准多头注意力(MHA)的查询头(Query Heads)分成多个组(Groups)。在标准的MHA中,每个头都有自己独立的查询、键(Key)和值(Value)。而在GQA中,每个组内的查询头共享同一份键和值。
由于GQA允许查询头共享键和值,它显著减少了计算量和GPU内存的使用。传统的MHA中,每个头都需要与所有的键和值进行点积操作,这会导致计算复杂度和内存需求的增加。而GQA通过将查询头分组并共享键和值,减少了这种冗余的计算和内存占用。
由于计算量和内存使用的减少,GQA使得模型能够更快速地处理输入数据,从而提高了推理速度。这对于处理长上下文信息或大规模数据集的任务尤为重要。
同时,GQA被设计为在保持多查询注意力(MQA)速度的同时实现多头注意力(MHA)的质量。这意味着GQA试图在速度和精度之间找到一个平衡点,以满足不同应用场景的需求。
在实现上,GQA将查询头按照某种策略分成若干组,并为每组分配一个共享的键和值。然后,模型对每个组内的查询头进行标准的自注意力计算,并将结果拼接起来得到最终的输出。这个过程可以通过PyTorch等深度学习框架进行高效的实现。
对齐阶段InternLM2的数据分析能力
通过在监督微调(SFT)和基于人类反馈的强化学习(RLHF)中利用长上下文预训练数据,可以保持 InterML 2 的长上下文能力,这项技术也是 InterML2 两点之一 。
那么,什么是长上下文预训练数据,它有什么作用呢?
长上下文预训练数据是指在训练深度学习模型之前,已经经过一定程度处理和标注的、包含较长上下文信息的数据。这些数据通常来源于大规模的语料库,涵盖了丰富的词汇、语法和语义信息。
长上下文预训练数据的作用主要体现在以下几个方面:
提高模型性能:长上下文预训练数据可以帮助模型在训练过程中更快地收敛,提高模型的性能。通过在大规模语料库上进行预训练,模型可以学习到文本的上下文信息,包括词汇的语义信息、句子的语法结构信息、文本的篇章结构信息等,从而提高模型对于自然语言的理解和处理能力。
增强模型泛化能力:长上下文预训练数据可以使模型在实际应用中具有更好的泛化能力。由于预训练数据已经包含了丰富的上下文信息,模型可以更好地处理未见过的数据,降低对大量标注数据的依赖,减轻数据标注的工作量。
支持复杂任务:对于需要处理复杂上下文信息的任务,如文本分类、文本相似度计算、机器翻译、问答系统等,长上下文预训练数据可以提供必要的背景信息和上下文支持,使模型能够更准确地理解文本的含义,从而提高任务完成的准确性和效率。
除此以外,InterML 2 还使用了以下的 alignment 技术:
长上下文预训练数据:该模型通过在监督微调(SFT)和基于人类反馈的强化学习(RLHF)中利用长上下文预训练数据,来保持其长上下文能力。
代码仓库选择:InternLM2使用诸如Pandas、Numpy、Tensorflow、Scipy、Scikit-learn、PyTorch和Matplotlib等核心代码仓库来增强其代码分析能力。这些仓库的选择基于其相关性和流行度。
数据清洗和过滤:对GitHub上拥有超过10,000颗星的仓库的原始数据进行清洗和过滤,以确保分析时使用的是高质量且相关的数据。
提示生成:为文件内容生成简短描述作为提示,以便于代码数据的分析。这有助于有效组织和处理数据。
处理数据的拼接:将处理后的数据按顺序拼接,直到达到32k的长度,以提高模型的长上下文和代码分析能力。
这些策略旨在优化数据分析过程,并在对齐阶段提高InternLM2在代码相关任务中的性能。
InternLM2 在 AlignBench 和 AlpacaEval 数据集上的表现
InternLM2在AlignBench和AlpacaEval数据集上的表现证明了它与人类偏好的出色对齐。在AlignBench数据集中,InternLM2在7B和20B版本上都取得了SOTA(当前最佳)分数,超越了GPT-3.5。
此外,经过RLHF(基于人类反馈的强化学习)增强后,在问答和角色扮演等任务中显示了显著的性能提升。在AlpacaEval数据集中,InternLM2-20B在比较模型中获得了最高的胜率,再次展示了其卓越的对齐性能。InternLM2中的RLHF策略证明在增强模型与人类偏好的对齐方面是有效的。
这些结果表明,InternLM2在各种任务和领域中都表现出色,是那些需要强大的语言理解和广泛知识的现实世界应用的可靠选择。
此外,InternLM2的卓越性能不仅体现在与人类偏好的高度对齐上,也体现在其广泛的适用性和灵活性上。该模型能够在不同场景和领域中进行有效应用,从简单的文本生成到复杂的对话系统,再到高级的知识问答,都能展现出其出色的表现。
重要的是,InternLM2的成功并非偶然,它背后是先进的技术和大量的研发努力。通过不断地优化模型架构、训练方法和数据预处理技术,研究人员成功地提高了模型的语言理解和生成能力,使其能够更准确地理解人类的语言和意图,并生成更符合人类期望的响应。
随着人工智能技术的不断发展,我们期待看到更多像InternLM2这样的高性能模型出现,它们将在各个领域中发挥越来越重要的作用,推动人工智能技术的进一步发展和应用。同时,我们也需要关注这些模型可能带来的伦理和社会问题,确保它们的使用能够符合人类的价值观和道德标准。















 1313
1313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









