






课程链接:InternLM/Tutorial at camp2 (github.com)
课程视频链接:书生·浦语大模型全链路开源体系_哔哩哔哩_bilibili
InternLM2技术报告:arxiv.org/pdf/2403.17297.pdf
一、视频笔记
1. 书生浦语大模型开源体系
-
专用模型:一个模型解决一个问题
-
通用大模型:成为AI发展趋势(一个模型可以解决多种问题)
-
书生浦语大模型:提供不同尺寸和类型模型,支持多语言和多模态任务。
-

2. 模型能力评测
-
综合性能: 达到同量级的开源模型领先水平。
-
计算与分析: 模型内生的计算能力和数据分析功能能够处理复杂任务。
-

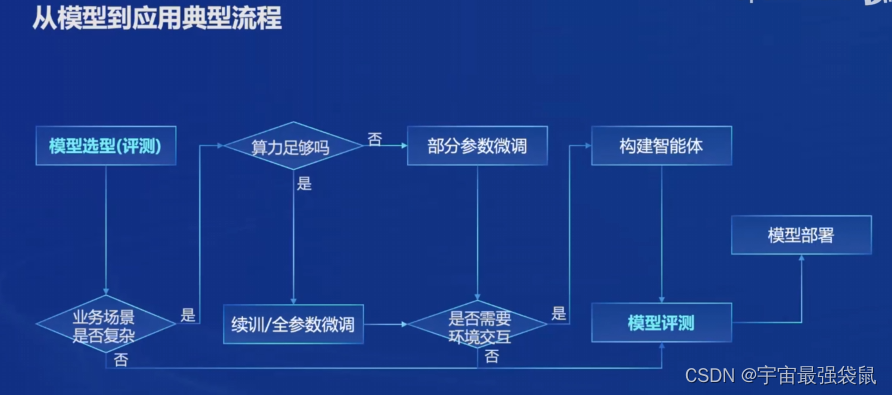
3. 模型选型与应用流程
-
模型选型: 考虑模型复杂度和算力。
-
全链条工具体系: 开源,包括数据、预训练、微调、部署、评测、应用等环节。
-
数据集: 书生万卷cc数据集开源,包含2013年至2023年的互联网公开内容。
-
4. Open Compass 2.0思南大模型评测体系
-
评测框架: 开发和开源,建立评测基准社区。
-
优化: 允许更多精力投入到数据准备和优化。
-
适配: 已适配超过100个评测集,是国内最完善的评测体系之一。
-

4. 高效微调框架 XTuner
适配多种生态
-
多种微调算法: 覆盖各类SFT场景
-
适配多种开源生态:支持Hugging Face、ModelScope模型或数据集
-
自动优化加速: 开发者无需关注复杂的显存优化与计算加速细节
适配多种硬件
-
训练方案覆盖:: NVIDIA20系以上显卡
-
最低只需8GB显存即可微调7B模型
5. 全链条开元开放体系-部署
-
社区发展: 中轻量级模型性能接近商业闭源模型。
-
Mdepot: 提供全链条部署解决方案,支持模型轻量化、推理引擎、服务模块等。
-
智能体框架: Legend支持多种智能体能力,提供多模态AI工具箱AgentLego和多媒体算法功能。
-

-
5. 轻量级智能体框架-Lagent
-
支持多种类型的智能体能力:React、ReWoo、AutoGPT
-
支持多种大语言模型:GPT-3.5/4、Hugging Face、Llama、internLM
-
 二、InternLM2技术报告
二、InternLM2技术报告 -
这份技术报告介绍了开源的大型语言模型InternLM2
InternLM2技术报告摘要:
-
介绍:InternLM2通过创新的预训练和优化技术,在六个维度和30个基准测试中超越了前身模型。
-
预训练过程:详细介绍了包括文本、代码和长文本数据的多样化数据类型的准备工作。
-
模型结构:采用了Transformer架构的变种,优化了训练效率和性能。
-
对齐(Alignment):通过监督式微调(SFT)和人类反馈的强化学习(RLHF),确保模型遵循人类指令并与人类价值观对齐。
-
评估与分析:在多种下游任务上评估了InternLM2的性能,包括语言和知识、推理和数学、编程等。
-
开源:提供了不同大小的模型,包括1.8B、7B和20B参数的版本。
-
长文本窗口:InternLM2设计了200k的上下文窗口,以支持长文本处理。
-
数据准备指导:详细说明了LLMs的预训练数据准备,包括文本、代码和长文本数据。
-
创新的RLHF训练技术:引入了条件在线RLHF(COOL RLHF),以协调不同的偏好,并显著提高了模型在各种主观对话评估中的性能。
- InternEvo:一个高效、轻量级的预训练框架,支持在数千个GPU上扩展模型训练。
-
数据:包括网页、论文、专利和书籍,经过清洗和处理以确保高质量。
-
设置:介绍了令牌化和预训练超参数。
-
阶段:包括4k上下文训练、长上下文训练和特定能力增强训练。
-
SFT:使用高质量指令数据对模型进行微调。
-
COOL RLHF:采用条件奖励模型和多轮在线RLHF策略,以减少奖励黑客攻击。
-
下游任务:在多个NLP任务上评估了模型性能,包括综合考试、语言和知识、推理和数学、编程语言编码等。
-
对齐性能:在多个主观对齐数据集上评估了模型的对齐能力。
结论:
InternLM2作为一个大型语言模型,在多个任务和基准测试中展示了卓越的性能,并通过开源模型和详细的训练过程描述,为社区提供了宝贵的资源。















 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









