






译自:https://wiki.pathmind.com/generative-adversarial-network-gan
你可能认为编码者不是艺术家,但是编程是一个极具创意的职业。它是基于逻辑的创新。-----John Romero
1、生成对抗网络定义(Generative Adversarial Network Definition)
GANs是两个神经网络构成的算法架构,让一个网络与另一个网络竞争(因此称“对抗”(adversarial))来生成新的、合成的看起来像(pass as/for sth.)真实数据的数据实例。广泛应用于图像生成、视频生成和声音生成。
GANs是由Ian Goodfellow和其他包括Yoshua Bengio在内的蒙特利尔大学(University of Montreal)研究人员在2014年提出的(文章:Generative Adversarial Networks)。提及GANs,Facebook的AI研究主管Yann LeCun称对抗训练为“过去10年在机器学习领域最有趣的idea”。
GANs潜在的双刃剑属性相当突出,因为GANs能学习去模仿任何数据的分布。更确切地说,GANs能被引导创造出在图像、音乐、语言和文学等任何领域与我们自己世界诡异相似的世界。从某种意义上讲,GANs是机器人艺术家,而且它们的作品令人印象深刻——甚至深深打动人(poignant even)。但是,它们还能被用来生成虚假的媒体内容,是构成Deepfakes基础的技术。
2、生成与判别算法(Generative vs. Discriminative Algorithms)
为了了解GANs,你应该知道生成算法是如何工作的,为此,将它们与与判别算法相比较是具有启发性的。判别算法试图分类输入数据;那就是,给出一个实例数据的(一些)特征,它们(判别算法)预测一个这个实例数据所属的标签或类别。
例如,给出email中的所有单词(数据实例),一个判别算法能预测出消息是否为"spam"或“not_spam”。"spam(垃圾邮件(尤指广告))"是标签(集)中的一个,收集自email的词袋是组成输入数据的特征(集)。当这个问题用数学化地表示时,标签表示为“y”,特征(集)表示为“x”。那么形如“p(y|x)”就用来表示“给定x时y的概率”,在这个例子中,“p(y|x)”就可以理解为“给定email所包含的词汇后,这个email是垃圾邮件的概率”。
所以判别算法把特征(集)映射到标签(集)。它们(判别算法)仅仅关注这个(映射)关系。一种理解生成算法的方法是——生成算法做的(恰恰)相反。生成算法试图根据给定的标签来预测特征,而不是(跟判别算法一样)根据给定的特征来预测标签。
生成算法试图回答的问题是:假设这封email是“spam”,那么这些特征是怎样的?尽管判别模型关心的是“y”和“x”之间的联系,但生成模型关心的是“你如何得到x”。它们(生成模型)允许你获得“p(x|y)”,给定“y”时候“x”的概率,或者给定一个标签或类别时特征的概率。(这就是说,生成算法还能被用作分类器。碰巧/意外的是(It just so happens that),它们除了分类输入数据外能做更多。)
另一个可考虑的可以用来区分判别与生成的的的方法如下:
• 判别模型学习类别间的边界;
• 生成模型建模每个类别的分布。
3、GANs如何工作(How GANs Work)
一个神经网络,称为生成器,生成新的数据实例,而另一个神经网络,称为判别器,来评估它们的真实性(authenticity);例如,判别器决定它所审查的的每一个数据实例是否属于实际的训练数据集。
例如现在我们要尝试做比模仿蒙娜丽萨更简单的事情——要生成像MNIST数据集中那些收集自真实世界的手写数字。在展示取自真实MNIST数据集的一个实例时,判别器的目标时识别这些数字是可信的。
同时,生成器将创建新的合成图像,然后传递给判别器。这样做是希望它们(images)也能被认为是真实的,即便它们是伪造的。生成器的目标是生成可行的(passable)手写数字:撒谎(伪造)而不被发现。判别器的目标是识别出来自生成器的图像是伪造的。
以下是GAN执行的步骤:
• 生成器获取随机数字,然后返回一幅图像;
• 这个生成的图像与一连串取自真实的ground-truth数据集的图像一起放进判别器;
• 判别器同时获取真实和伪造数据,然后返回一个0~1的概率,其中,1表示预测为真实,0则表示预测为伪造。
因此,这个过程是一个双反馈循环(So you have a double feedback loop):
• 鉴别器与我们已知图像的ground truth处于同一个反馈循环中;
• 生成器与判别器处于同一个反馈循环中。
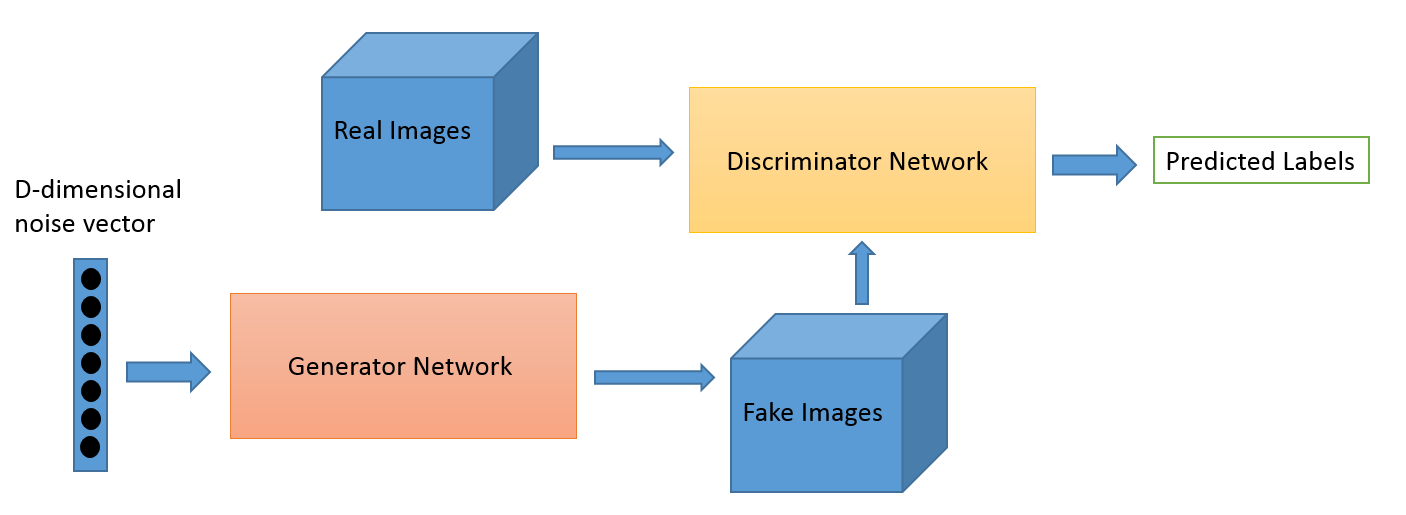
图源: O’Reilly
你可以把GAN当作在猫和老鼠游戏中伪造者和警察的对立,当伪造者要学习通过错误的标注(pass false notes),警察则要学着去检测到它们(false notes)。二者都是动态的,例如,警察一直也在(持续)训练中(为了拓展这个类推(类比,analogy)可能中央银行正在标记那些遗漏的钞票/账单(bills that slipped through)),在不断地升级过程中,每一边都在学习对方的方法。
对于MNIST,判别器网络是一个标准的能分类送入给它的图像的卷积网络,是一个将图像标记为真实或伪造的二项分类器。生成器则是一个相反的卷积网络,从某种意义上讲:当一个标准的卷积分类器获取一幅图像并将其降采样产生一个概率时,生成器则获取一组算随机噪声向量并将其上采样为一幅图像。第一个是通过类似最大池化(maxpolling)的降采样技术来丢弃(throw away)数据,第二个则是生成新的数据。
两个网络都在一个零和游戏中试图优化一个不同且相反的目标函数(或损失函数)。这本质上是一个玩家-评委模型(actor-critic model)。只要判别器改变了它的行为,那么生成器也会做相应的改变,反之亦然(vice versa)。它们的损失对抗着彼此。
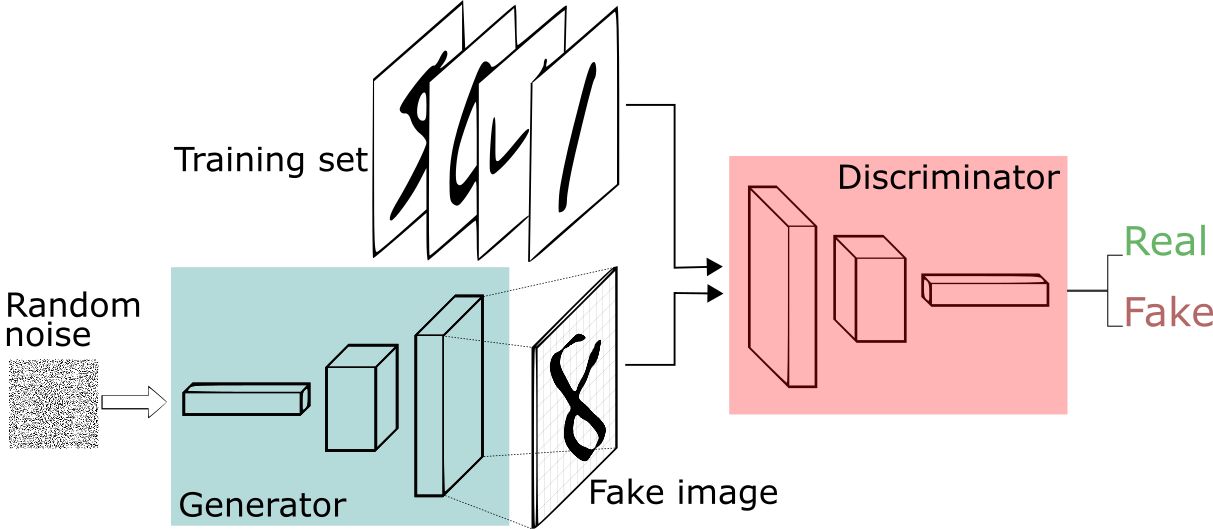
如果你想要学习更多关于生成图像的内容,Brandon Amos 写过一篇非常棒的关于将图像解释为概率分布的样本(interpreting images as samples from a probability distribution)的帖子。
3、GANs,自动编码器和变分自动编码器(Autoencoders and VAEs)
将GAN与其他诸如自动编码器和变分自动编码器等神经网络比较可能是有用的。自动编码器将输入数据编码为向量。它们创建了隐式的或压缩的原始数据的表示方式。这在维度下降(数据降维,dimensionality reduction)中相当有用;这就是,向量作为隐式的表示形式将原始数据压缩成少量(较少数据量)的显著维度。自动编码器能与所谓的(so-called)解码器配对,这个解码器允许你可以基于输入数据的的隐式表示来重建数据,就像你用受限玻尔兹曼机器(restricted Boltzmann machine)一样。
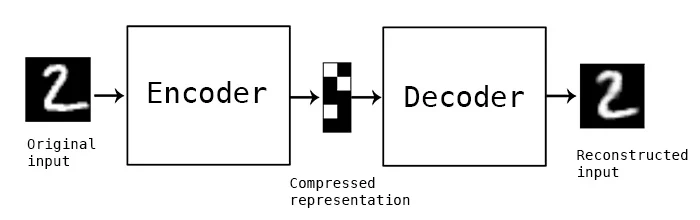
图源:Keras blog
变分自动编码器(VAEs)是生成式算法,增它对编码输入数据增加了一个额外约束,也就是说(namely)这个隐式表示是归一化的。变分自动编码器既能像自动编码器一样压缩数据,也能像GAN一样合成数据。然而,GANs生成的数据足够精细、纹理丰富(in fine, granular detail),但是由变分自动编码器生成的图像则趋于更模糊(blurred)。
你可以将生成算法划分(bucket)为以下三种类型之一:
• 给定一个标签,它们(生成算法)预测相关的特征(朴素贝叶斯,Naive Bayes);
• 给定一个隐式表示,它们预测相关的特征(VAE,GAN);
• 给定一些特征,它们预测剩下的部分(图像修复或污损,inpainting, imputation)。
4、训练GAN的技巧(Tips in Training a GAN)
当你训练判别器时,生成器的参数保持恒定不变;当你训练生成器时,保持判别器很定不变。每个应该训练对抗静态的对手。举例来说,这样能使生成器可以更好地了解到它必须学习的梯度。
在开始训练之前,先针对MNIST对判别器进行预训练,生成器就将建立更清晰的梯度(优化方向)。
GAN的每一方(生成器或判别器)都能战胜另一方。如果判别器太强,它将返回非常接近0或1的值,以至于使生成器难以(struggle to)把握梯度(变化方向)(read the gradient)。而如果生成器太强大,它将持续利用判别器中的弱点,从而导致假负(false negative,FN,被模型预测为负的正样本)。这能通过两个网络各自的学习率来缓解。因此,两个网络必须具有相近的能力水平【1】。
GANs需要花较长时间训练。在单个GPU上训练GAN可能花费数小时,而在单个CPU上训练GAN则要超过一天。虽然难以调整以及因此而难以使用,但是GANs已经激发了大量有趣的研究工作和论文写作。
5、其他生成模型(Other Generative Models)
GANs不仅仅是基于深度学习的生成模型。由微软支持的智库(think tank)OpenAI已经发布了一系列命名为GPT(Generative Pre-trained Transformer)的强大自然语言生成模型。在2020年,他们又发布了GPT-3,且使它能通过API来访问。GPT-3是一个出奇强大的生成语言模型,它能够模拟纯粹的(net,adj. left when there is nothing else to be taken away)新人类语言对提示作出回应。
6、GAN的代码示例(Just Show Me the Code)
代码基于Keras(出处-github: GAN coded in Keras):
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build and compile the generator
self.generator = self.build_generator()
self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
# The generator takes noise as input and generated imgs
z = Input(shape=(100,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The valid takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator) takes
# noise as input => generates images => determines validity
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (100,)
model = Sequential()
model.add(Dense(256, input_shape=noise_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random half batch of images
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (half_batch, 100))
# Generate a half batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, 100))
# The generator wants the discriminator to label the generated samples
# as valid (ones)
valid_y = np.array([1] * batch_size)
# Train the generator
g_loss = self.combined.train_on_batch(noise, valid_y)
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("gan/images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=32, save_interval=200)
7、脚注(Footnotes)
【1】原文脚注类比了进化论,考虑进化的过程,一方面为遗传突变,另一方面为自然选择,在较大较长的范围内是两个相反的算法,存在竞争,但遗传突变需要适配或优胜于自然选择方能适应下来;其次,智人的进化速度快于与之竞争的资源的其他物种,更快更短地解决相同的问题。当前硬件的升级也在加速AI算法的学习速度,算法的学习速度已经快于人类。
8、生成网络的其他资源(Resources for Generative Networks)
- “Generative Learning algorithms” - Andrew Ng’s Stanford notes
- On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes, by Andrew Ng and Michael I. Jordan
- The Math Behind Generative Adversarial Networks
- A Style-Based Generator Architecture for Generative Adversarial Networks, Code – Examples of StyleGAN in action: Faces, Anime, Art – Description of the StyleGAN architecture
- Generating Diverse High-Fidelity Images with VQ-VAE-2
后记:初学入门,翻译不足之处还请指正。















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









