







利用Pyhton 爬取图片(定制请求路径,匹配资源)
一. 学习目的:
- 学习python请求根据网站连接定制化
- 学习利用xpath找目标图片的name,路径等等
图片素材链接 (该链接为 站长素材网站下的图片分区的性感美女分区)
https://sc.chinaz.com/tupian/xingganmeinvtupian.html
二.代码部分
首先理清楚代码的整体思路,下载多页的图片资源,首先思路是:
1. 创建定制化请求对象
因为多页的请求链接是不一样的,需要在代码中自动生成下一页的链接,首先观察链接的规律。
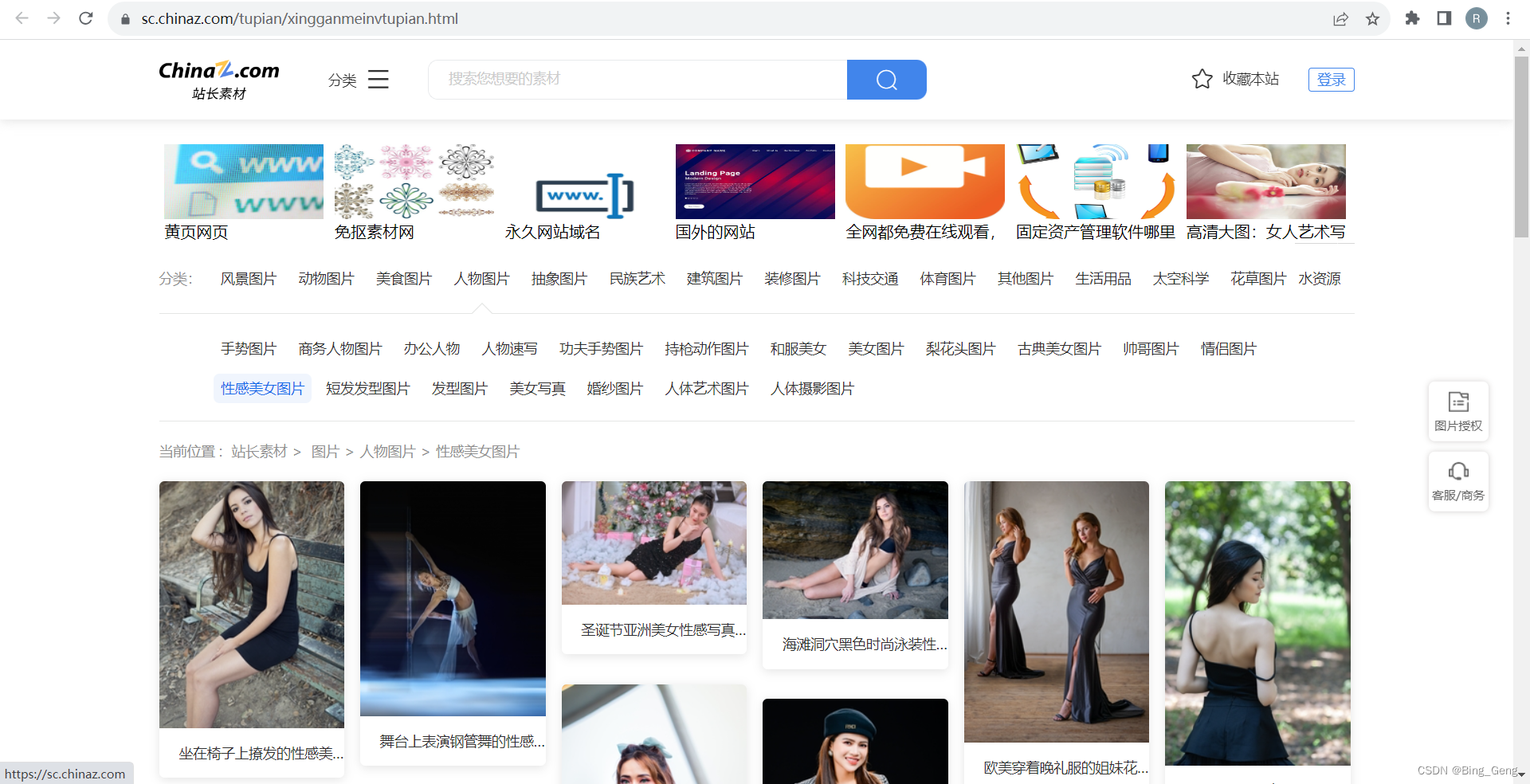
第一页的请求页面(按F12,点击网络查看)
如图所示:第一页请求链接为
https://sc.chinaz.com/tupian/xingganmeinvtupian.html
接下来第二第三页,规律已经发现,第一页为直接是xingganmeninvtupian.html结尾,从第二页开始,第n页后面则加上 **_n** 即可
 ‘
‘

2. 第二步,目标资源的定位。
定制后请求连接后,得到的响应代码要进行解析处理,获取到图片资源的下载垃圾,名字等等。代码中如下:
(浏览器没有xpath插件的读者要先安装在浏览器安装该插件,安装方法可以跳转到其他创作者的,我还没有写)
#定制获取到图片的名字
name_list = tree.xpath('//div[@class="item"]/img/@alt')
print(len(name_list))
# 定制路径获取到图片的资源路径
src_list = tree.xpath('//div[@class="item"]/img/@data-original')
print(len(src_list))
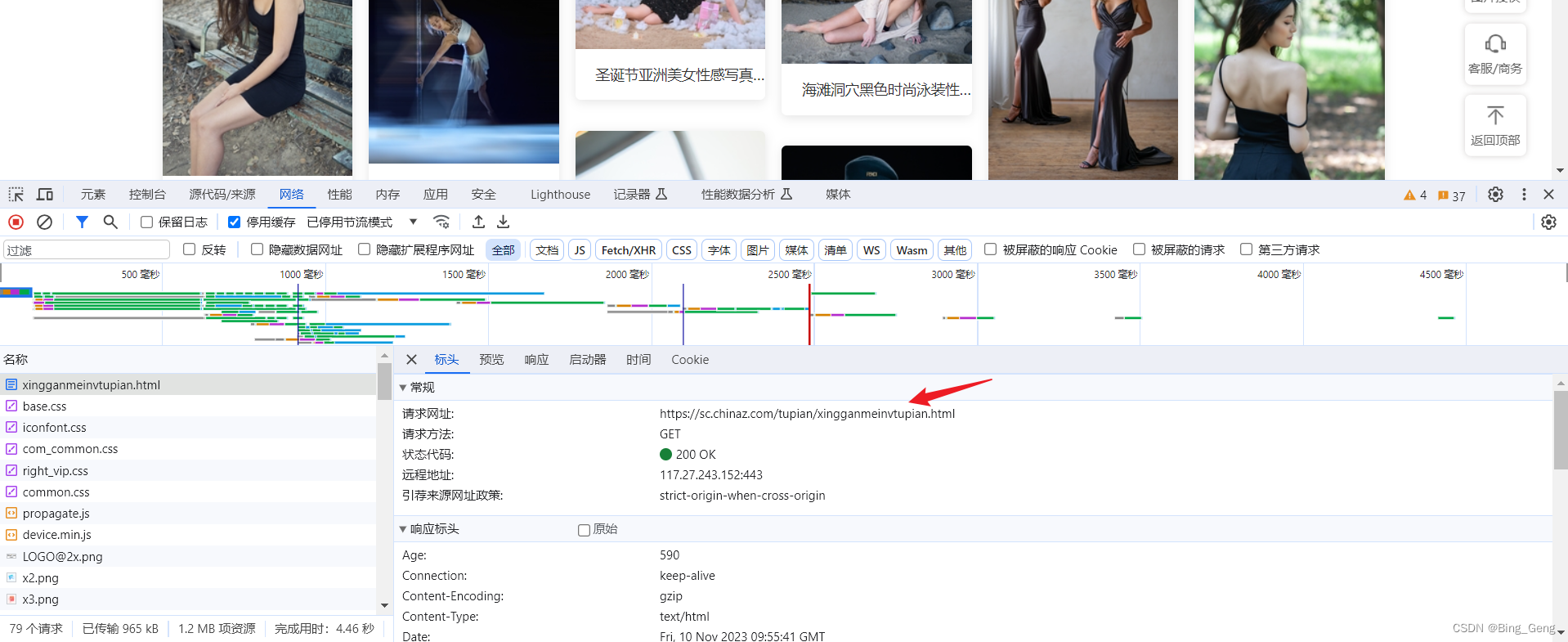
通常刚刚学习的伙伴们会觉得写xpath路径很难,其实看借助xpath helper这个浏览器插件,就可以帮你轻松定位到目标资源,来提示你是否写得正确。下面来进行演示
在网络中,点击响应,查看返回的数据,拉到下面,将看到返回图片的一个一个实体,div标签里面保着img标签,img标签里面有alt属性和data-original属性,这两个属性经过观察,这两个就是名字和图片资源路径,所以我们要获得的就是这两个值。
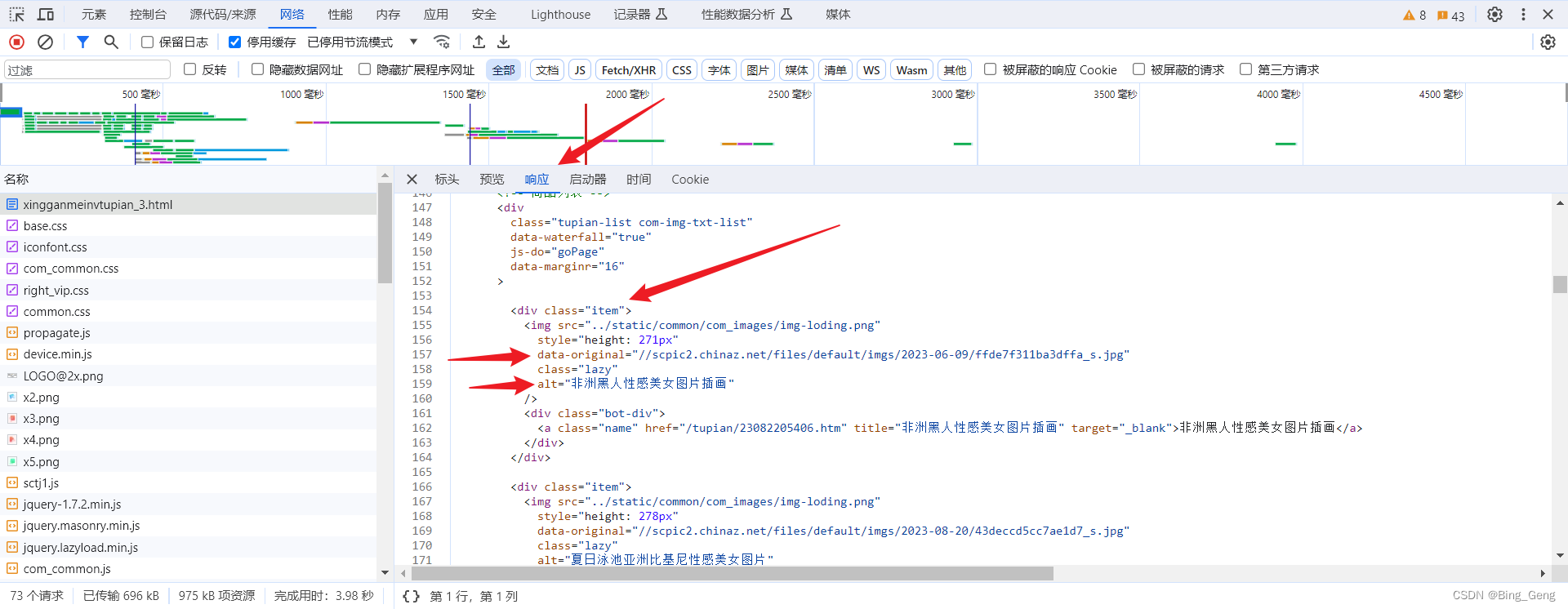
打开xpath(快捷键 ctrl+shift+x),,如果快捷键打不开xpath,可能是输入法现在是中文,转为英文输入即可,或者刷新一下页面,也可以直接点右上角手动打开(手动比较稳定能打开)

现在则在右边输入匹配字符串,来匹配到对应资源,我们刚刚说过,是div标签里面保着img标签,img标签里面有alt属性和data-original属性。所以 来啦
//div 表示选中所有div, 显示出现了124个结果

但经过我们的观察,我们要的带有图片的div里面,class是item,所以我们可以对div进行筛选,只要class为item


然后我们要的是div里面带有一个子标签是img的,所以后面要加一个 /img,代表匹配所有div带着有一个img子标签的,一共有40个结果

然后我们需要img里面的alt和data-original属性,属性的话用 /@ 来获取

这样子的匹配字符串的完整意思就是 获取 class 为 itm 的 div,然后获取该div下的img子标签的alt属性,另一个属性data-original同理

三. 编写代码
在请求路径和资源匹配都解决后,则开始写代码,这里不详细一一讲解,可以结合注释学习,或者在评论区评论
一个功能写一个函数是精细化管理的体现,符合开发规范,维护方便
import urllib.request
from lxml import etree
def create_request(page):
# 这个if else 是定制请求路径,如果是第一页,不需要在后面添加
if(page == 1):
url = 'https://sc.chinaz.com/tupian/xingganmeinvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/xingganmeinvtupian.html_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
}
request = urllib.request.Request(url = url, headers = headers)
return request
# 获取响应内容
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 下载图片
def down_load(content):
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
# print(content)
name_list = tree.xpath('//div[@class="item"]/img/@alt')
print(len(name_list))
# 一般设计图片的网站都会进行懒加载
src_list = tree.xpath('//div[@class="item"]/img/@data-original')
print(len(src_list))
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
print(url)
urllib.request.urlretrieve(url=url,filename='./beautiful/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)
四. 总结内容与不足
- 该文章内容是python如何获取多页数据的图片,里面内容包含了如何定制请求链接,编写xpath路径这两个核心内容
- 该文章没有面对零基础的读者进行详细讲解,零基础的读者可以关注该专栏较早的文章
- 其实在教学xpath部分,是有问题的,xpath输入框输入后,高亮显示的是在控制台的第一个选项卡的元素那里高亮,而图片响应的代码文件却是在网络这个选项卡里面的响应这个地方,所以读者这里可能要意会,要更好学习怎么写匹配规则的可以参考我该专栏对应的文章或者其他优秀开发者的文章
如果您对我的内容感兴趣,请关注我,我会持续更新该系列,其他专栏系列设计网络安全,javafx开发等等,十分感谢

















 5475
5475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









