







本篇思维导图
图像配准(Registration)
1.配准刚性物体
- 变换:旋转(rotation)、平移(translation)、缩放(scale)
∑i[(sR(θ)xi+t)−yc(i)]2 - 迭代最近点:通过估计对应点寻找正确的变换,然后估计基于对应点的变换,不断重复
- 通过对应点搜索变换:搜索对应的局部区域(图形符号而不是点),使用它们来估计变换
- 应用:图像拼接(Image Masaics)
2.基于模型的视觉:用投影配准刚性物体
- 假设一个图像特征集合与一个物体特征集合对应,用这个对应关系产生一个从物体坐标系到图像坐标系的投影框架的猜测
- 使用这个投影假设来产生一个物体的图像,称为反向投影
- 比较图像与所产生的物体图像,如果它们两个足够相似,就接受上述假设
3.配准可变形的物体
学习分类
1.分类、错误和损失
- 使用损失确定决策
- 训练误差、测试误差和过拟合
- 正则化
- 错误率和交叉验证
- ROC曲线
2.主要的分类策略
2.1 两大通用策略
- 明确的概率模型(可理解为生成模型,如朴素贝叶斯模型)
- 直接确定决策边界(可理解为判别模型)
2.2 策略1:使用基于马氏距离的正态类条件概率密度

注:马氏距离表示数据的协方差距离,它是一种有效计算两个未知样本集间相似度的方法。与欧式距离不同的是它考虑到各种特征之间的联系,并且是尺度无关的。
该算法的几何解释:在考虑方差情况下将数据项划分到距类均值最近的类中(特别地,沿某一方向方差小的距类均值的距离有大权重,方差大的距类均值的距离权重小)
评价:在有很多训练数据和类别的低维问题可以尝试。马氏距离的适用场景相对较少,因为当特征向量是高维时求协方差矩阵比较困难。
2.3 策略2:类条件直方图和朴素贝叶斯
如果有足够的标记数据,就可以对类条件密度直方图建模,这在低维情况下是有用的。
- 利用贝叶斯公式直接算出后验概率然后进行比较
2.4 策略3:使用最近邻的非参数分类器
对一个类别未知的样本,可以假设其类别是在特征空间中距离这个样本最近的训练样本的类别,或找出距离待识别样本最近的几个,然后用这几个训练样本的类别进行投票来确定待识别样本的类别

评价:这一策略总是有用的,当训练数据很多时与其他分类方法相比也保持有竞争力。
2.5 策略4:线性SVM
- 线性可分情况
- 线性不可分情况
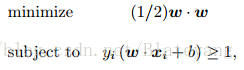
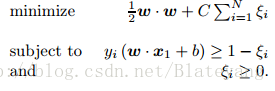
2.6 策略5:核SVM
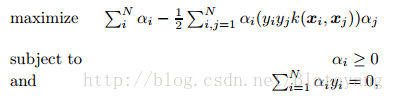
2.7 策略6:Boosting和Adaboost
集合多个弱分类器构造强分类器
3.建立分类器的实际方法
3.1 选择分类器的经验
经验建议对大多数问题可以首先用线性SVM去尝试,如果效果不理想,接下来换用核SVM或boosting方法
3.2 训练数据处理的两个技巧
- 数据增广:缩放、裁剪、旋转、翻转等
- bootstrapping(自助法)
- 基本思想:将被分类错误的正负样本插入到训练集中重新训练分类器,反复迭代
- 变体:hard negative mining
从负样本中选取出一些有代表性的负样本(分类器检测出的错误的正样本,被称作hard negative),不断重新训练,使得分类器的训练结果更好
3.3 从二分类器中建立多分类器
- all-vs-all方法:为每类都建立一个分类器
- one-vs-all方法:为每类和其余类建立一个分类器(比all-vs-all方法往往要更可靠和有效一些)
3.4 求解SVM和核SVM
分类图像
基本思路:利用一个已标记的数据集,建立特征,然后训练分类器
1. 建立好的图像特征
不同的特征构建适用于不同的情况。关键是建立那些能暴露类间变化并且抑制类内变化的特征。
任何一种特征表示形式都应该是对图像的旋转、平移或缩放鲁棒的,因为这些变换并不会影响图像的含义
1.1 应用例子
- 检测特定图像(如色情图片识别)
- 材料分类
- 场景分类
1.2 用GIST特征编码布局
GIST特征综合了一幅图像不同部分的梯度信息(尺度和方向),提供了关于一个场景的粗略描述
- 对于场景分类一个自然的线索就是图片的整体布局,GIST特征企图捕获的正是这种布局。
- GIST特征的计算过程
- 用32个Gabor滤波器(4个尺度,8个方向)卷积图像,产生32幅特征图
- 把每个特征图等分成16个区域(4*4网格),求每个区域的特征值均值
- 连接所有32幅特征图的特征均值,形成一个16*32=512维的GIST特征
1.3 用视觉单词(visual words)概况图像
- 记录具有特点的局部图像块,用某些局部特征(如SIFT特征)描述这些局部邻域并进行向量量化得到视觉单词,然后通过直方图的形式对视觉单词集进行统计概括,如果在一幅图像中大多数单词与另一幅图像中的大多数单词匹配,它们的视觉单词直方图就会是相似的。
- 衡量直方图的相似性,普遍采用的是直方图的交距离: K(h,g)=∑imin(hi,gi)
1.4 空间金字塔核
是视觉单词直方图方法的一个重要变体,能产生可有效粗略编码空间布局的核
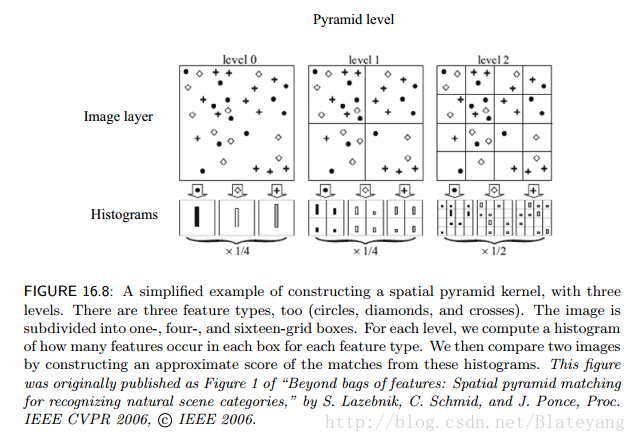
- 模型
wl 表示相匹配的grid权重,越精细的grid权重越大 - 应用
空间金字塔核在场景图像分类上做得很好,在标准图像分类任务上也要优于直方图交核;它能够很好地表示相对独立的物体或自然场景,但对于缺少纹理的物体或与背景相似的物体会遇到麻烦
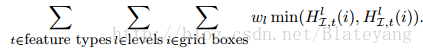
1.5 用主成分(PCA)降维

PCA建立了在特定维数下最能表达原高维数据变化的新的特征集,但是并不能保证这个特征集能帮助我们实现有效分类。
1.6 用典型变量(canonical variates)降维
典型变量指能够明显地反映出不同类别样本间差异的线性特征,这些特征能使类间尽可能分开

2. 分类含有单个物体的图像
2.1 图像分类策略
- 通用策略是计算特征,利用特征向量构建多分类器
- 典型方法
- 使用HOG和SIFT特征的变体,结合颜色特征
- 视觉单词字典(计算图像的视觉单词,进行向量量化,用视觉单词的直方图表示图像然后使用直方图交方法对其分类)
- 空间金字塔核金字塔匹配核
3. 图像分类实践
3.1 关于图像特征的代码
3.2 图像分类数据集
- Caltech系列数据集(Caltech-101、Caltech-256等)
- LabelMe数据集(是一个图像标注环境,可用来标注该数据集图像中的物体)
- ImageNet数据集(某种程度上成就了深度学习)
- SUN数据集(关于场景的最大数据集)
- 其他
3.3 数据集偏差(bias)
指数据集的性质与真实世界的性质存在表示偏差
- 避免偏差的策略:
- 从多种不同的途径收集大量数据
- 在使用数据集评估复杂方法前使用基本方法小心地评估数据集
- 采取与收集训练数据不同的策略来收集数据,并通过评估它们来量化偏差的影响















 2870
2870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









