







参考
关于torch.cuda.is_available() 返回False 详细说明及解决
一、前言
windows11 版本安装 CUDA ,首先需要下载两个安装包
- CUDA toolkit(toolkit就是指工具包)
- cuDNN
注:cuDNN 是用于配置深度学习使用
二、官方教程
CUDA:Installation Guide Windows :: CUDA Toolkit Documentation
cuDNN:Installation Guide :: NVIDIA Deep Learning cuDNN Documentation
查看支持CUDA的GPU显卡型号:https://developer.nvidia.com/cuda-gpus
三、版本选择
CUDA的版本选择需要根据电脑GPU的型号来决定,比如是nvidia卡
在电脑桌面,点击右键菜单找到NVIDIA控制面板打开如下页面:
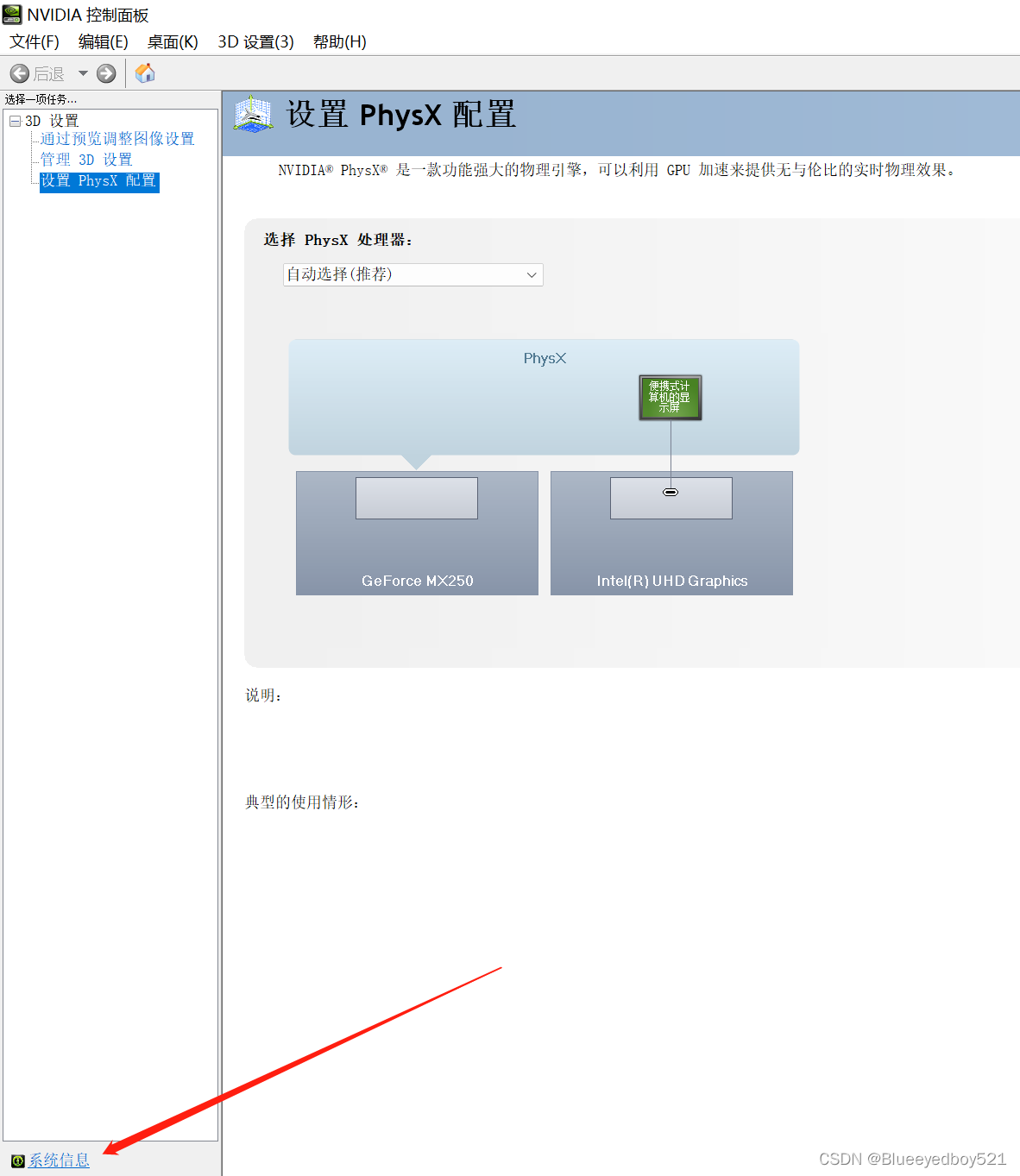
点击左下角的系统信息,然后在弹框中切换到组件tab
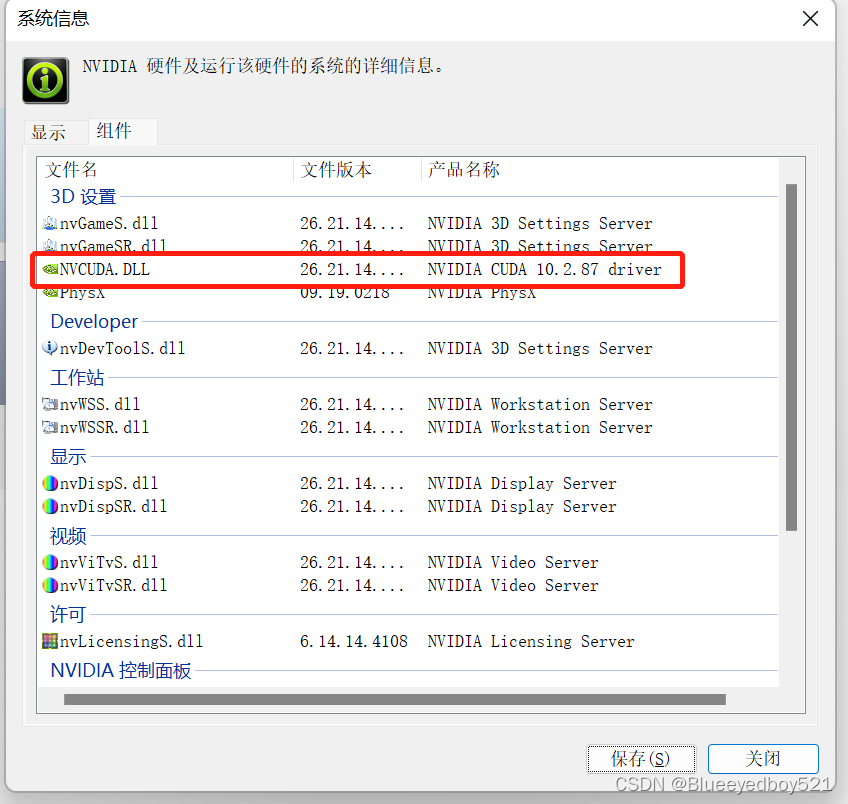
可以发现我们电脑支持的版本是10.2
四、下载CUDA
各个版本下载地址可以参考:https://blog.csdn.net/weixin_44177494/article/details/120444922

最新版下载页面:https://developer.nvidia.com/cuda-downloads
10.2下载页面:https://developer.nvidia.com/cuda-10.2-download-archive
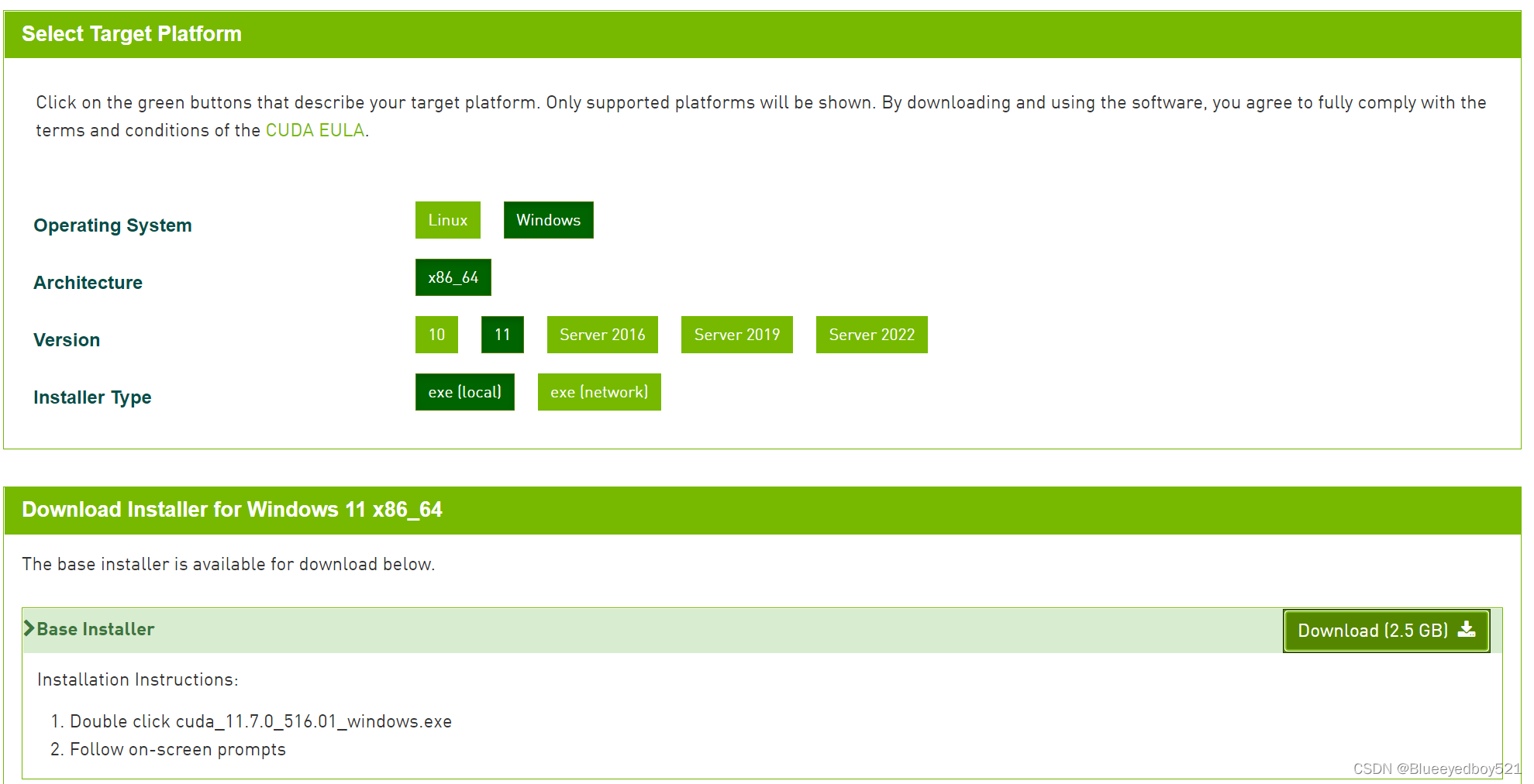
10.2下载地址:https://developer.download.nvidia.cn/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_441.22_win10.exe
五、安装CUDA
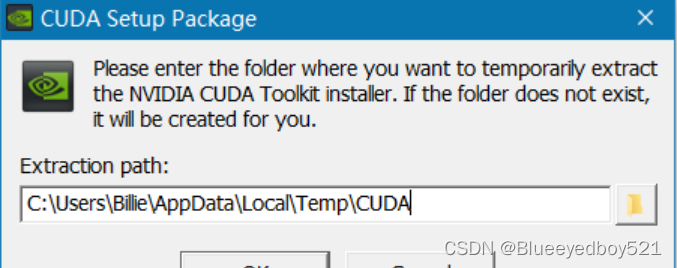
1、选择解压路径
可以在其他盘新建一个临时文件夹,用来存储解压之后的内容,也可以默认
2、解压完之后系统检查
3、选择自定义安装
第一次使用选择自定义安装
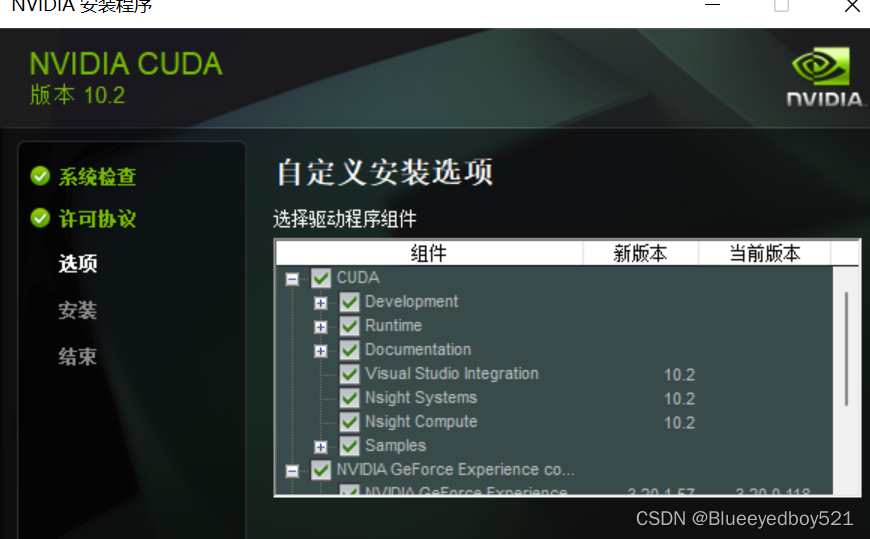
可以选择默认,也可以选择自定义位置,提前在文件夹创建好
D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2
D:\cuda\NVIDIA Corporation\CUDA Samples\v10.2
4、测试安装是否成功
运行cmd,输入nvcc --version或者nvcc -V,即可查看版本号
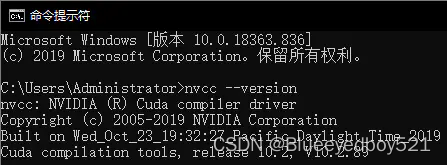
查看安装路径
set cuda
六、下载cuDNN
cuDNN地址如下,不过要注意的是,我们需要注册一个账号,才可以进入到下载界面。大家可以放心注册的。
https://developer.nvidia.com/rdp/cudnn-download
可以使用下面网址,查看适配的 cuDNN
cuDNN Archive | NVIDIA Developer
选择跟自己的cuda版本适配的cudnn版本

下载地址:Download cuDNN v8.3.3 (March 18th, 2022), for CUDA 10.2
七、安装
1、解压缩
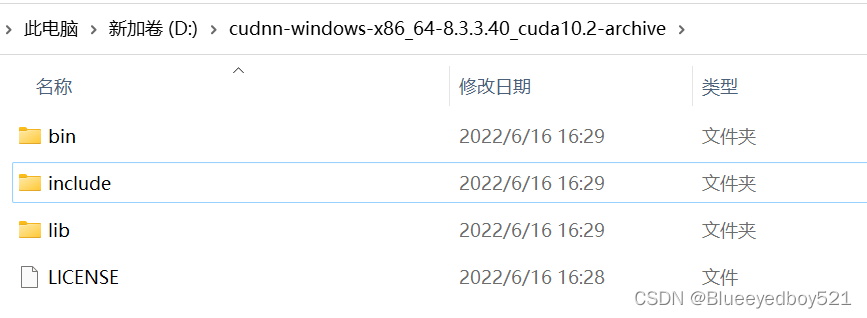
- 先找到cuda的安装路径,比如我们是:D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2
- 然后把cudnn解压后的三个文件夹复制进入上面cuda的目录
- 由于bin目录等已经存在,则会合并现在大家应该可以理解,cuDNN 其实就是 CUDA 的一个补丁而已,专为深度学习运算进行优化的。然后再参加环境变量
2、添加Path环境变量-系统变量
D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin
D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib
D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2\libnvvp

3、验证安装是否成功
配置完成后,我们可以验证是否配置成功,主要使用CUDA内置的deviceQuery.exe 和 bandwithTest.exe:
首先win+R启动cmd,cd到安装目录下的 …\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe,应该得到下图:
执行bandwidthTest.exe
D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite>bandwidthTest.exe
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: GeForce MX250
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 3043.2
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 3194.2
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 47408.0
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
执行deviceQuery.exe
D:\cuda\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite>deviceQuery.exe
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce MX250"
CUDA Driver Version / Runtime Version 10.2 / 10.2
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 2048 MBytes (2147483648 bytes)
( 3) Multiprocessors, (128) CUDA Cores/MP: 384 CUDA Cores
GPU Max Clock rate: 1582 MHz (1.58 GHz)
Memory Clock rate: 3504 Mhz
Memory Bus Width: 64-bit
L2 Cache Size: 524288 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 5 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.2, CUDA Runtime Version = 10.2, NumDevs = 1, Device0 = GeForce MX250
Result = PASS
八、配置
修改默认安装envs和pkgs位置
【Anaconda配置】修改conda虚拟环境路径及安装包路径
step1:找到.condarc文件,以我的为例:C:\Users\Zhang cyne

step2:用记事本打开.condarc文件,删除里面的内容。增加以下内容(找自己文件夹的路径)
envs_dirs:
- D:\Anaconda3\envs
pkgs_dirs:
- D:\Anaconda3\pkgs
step3:保存并关闭
step4:在cmd检查conda的配置信息,第一个显示的是自己设置好的路径就没问题了
conda config --show
九、验证pytorch是否匹配cuda
(Rope) D:\software\cuda\NVIDIA GPU Computing Toolkit\CUDA\v12.2\extras\demo_suite>python
Python 3.10.13 | packaged by conda-forge | (main, Dec 23 2023, 15:27:34) [MSC v.1937 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>>
>>> print(torch.__version__)
2.0.1+cu118
>>> print(torch.cuda.is_available())
True
>>> print(torch.version.cuda)
11.8
>>> print(torch.cuda.device_count())
1
>>> print(torch.cuda.get_device_name(0))
NVIDIA T600 Laptop GPU
>>> quit()
















 7487
7487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









