










标注工具doccano介绍
基于大模型进行自动化标注的结果不太好,需要人工校正,目前使用工具工具标注。
doccano是documment anotation的缩写,是一个开源的文本标注工具,我们可以用它为NLP任务的语料库进行打标。它支持情感分析,命名实体识别,文本摘要等任务。
它的操作非常便捷,在小型语料库上,只要数小时就能完成全部的打标工作。
doccano使用
本次使用docker-compose进行部署。
version: "3"
services:
doccanno:
image: doccano/doccano
ports:
- "6036:8000"
environment:
ADMIN_USERNAME: admin
ADMIN_EMAIL: admin@example.com
ADMIN_PASSWORD: password
浏览器打开127.0.0.1:6036
- 创建项目
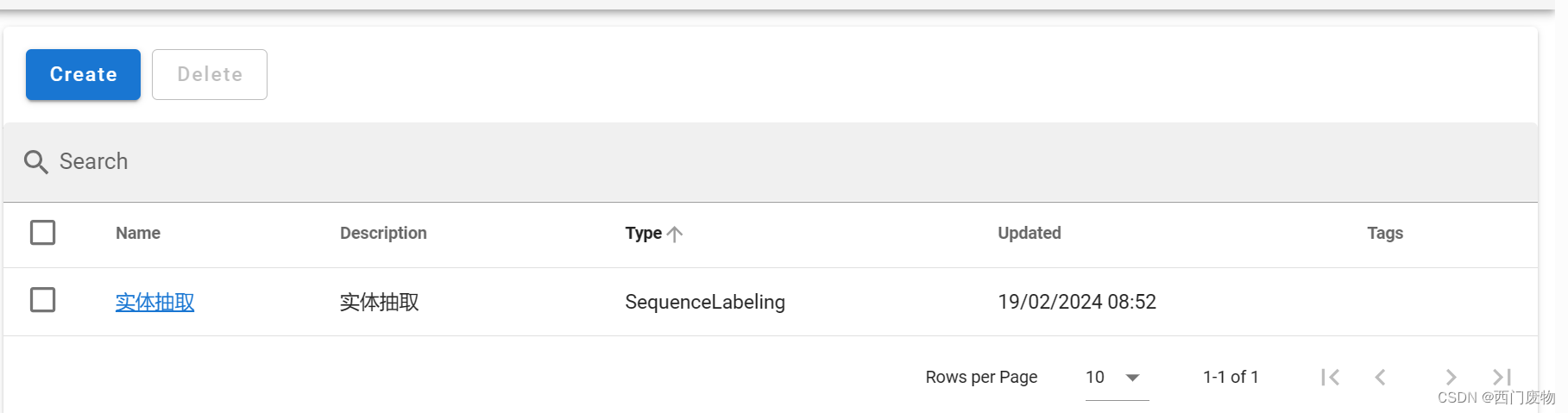
2.创建标签
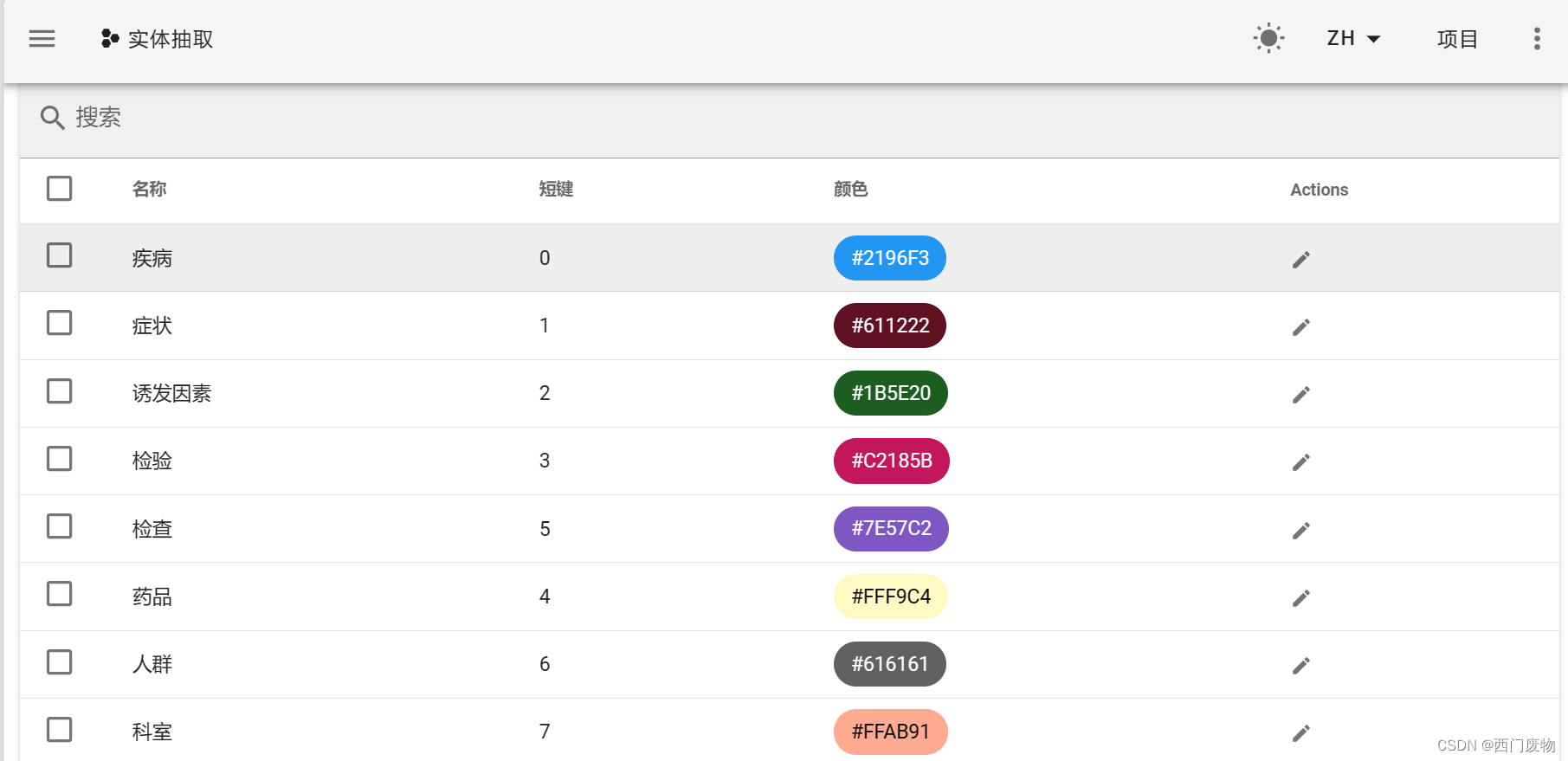
3.导入数据集
数据集格式为jsonl,转换格式代码如下所示。
import json,re
cc = 0
import jsonlines
al_ = []
for line in open("right.txt",encoding="utf8"):
line = line.strip("\n")
if "接下里你作为一名nlp工作者来进行实体识别" in line:
line = line.split("***")
try:
cc =cc+1
etx = line[0].replace("接下里你作为一名nlp工作者来进行实体识别,请提取句子《","").replace("》关于疾病、症状、诱发因素、检验、检查、药品、人群、科室这八种对应的实体,输出格式为{'疾病': [], '症状': [], '诱发因素': [], '检验': [], '检查': [], '药品': [], '人群': [], '科室': []}","")
temp = json.loads(line[1].replace("'", '"').replace(" ", '').strip(".").strip("]"))
my_result = []
for key,value in temp.items():
for element in value:
matches = re.finditer(element, etx)
for match in matches:
start = match.start()
end = match.end()
my_result.append([start,end,key])
al_.append({"text": etx, "label":my_result})
except:
pass
with jsonlines.open('data.jsonl', mode='w') as writer:
for item in al_:
writer.write(item)
最终开始人工校正
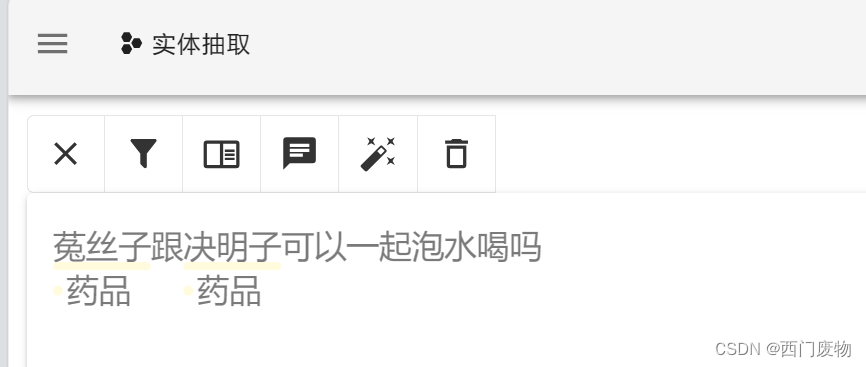
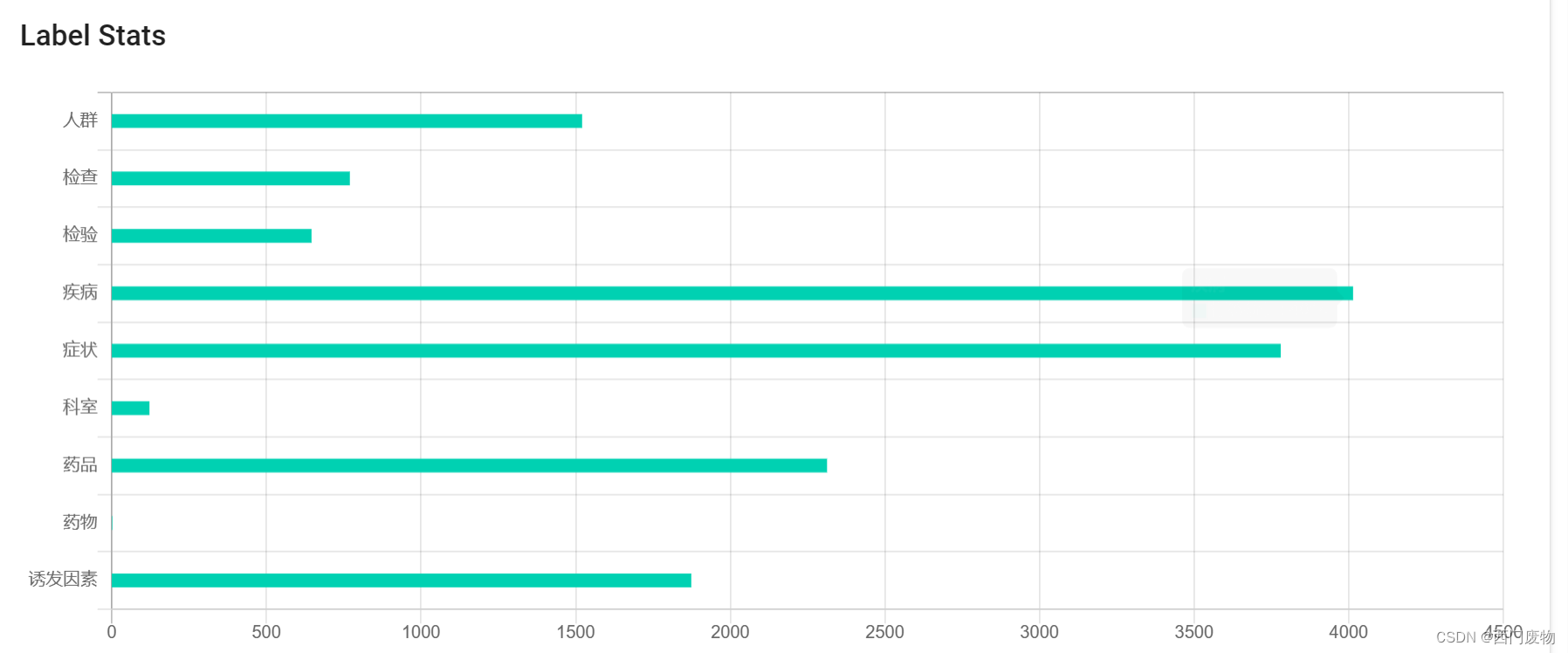
标注完的数据集可以直接导出。















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











