






持续更新修改
什么是Nacos
Nacos是 Dynamic Naming and Configuration Service的首字母简称,相较之下,它更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Nacos 帮助您发现、配置和管理微服务。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据及流量管理。
Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。 Nacos 是构建以“服务”为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。
Nacos 的关键特性包括:
- 服务发现和服务健康监测
Nacos 支持基于 DNS 和基于 RPC 的服务发现。服务提供者使用 原生SDK、OpenAPI、或一个独立的Agent TODO注册 Service 后,服务消费者可以使用DNS TODO 或HTTP&API查找和发现服务。
Nacos 提供对服务的实时的健康检查,阻止向不健康的主机或服务实例发送请求。Nacos 支持传输层 (PING 或 TCP)和应用层 (如 HTTP、MySQL、用户自定义)的健康检查。 对于复杂的云环境和网络拓扑环境中(如 VPC、边缘网络等)服务的健康检查,Nacos 提供了 agent 上报模式和服务端主动检测2种健康检查模式。Nacos 还提供了统一的健康检查仪表盘,帮助您根据健康状态管理服务的可用性及流量。 - 动态配置服务
动态配置服务可以让您以中心化、外部化和动态化的方式管理所有环境的应用配置和服务配置。
动态配置消除了配置变更时重新部署应用和服务的需要,让配置管理变得更加高效和敏捷。
配置中心化管理让实现无状态服务变得更简单,让服务按需弹性扩展变得更容易。
Nacos 提供了一个简洁易用的UI (控制台样例 Demo) 帮助您管理所有的服务和应用的配置。Nacos 还提供包括配置版本跟踪、金丝雀发布、一键回滚配置以及客户端配置更新状态跟踪在内的一系列开箱即用的配置管理特性,帮助您更安全地在生产环境中管理配置变更和降低配置变更带来的风险。 - 动态 DNS 服务
动态 DNS 服务支持权重路由,让您更容易地实现中间层负载均衡、更灵活的路由策略、流量控制以及数据中心内网的简单DNS解析服务。动态DNS服务还能让您更容易地实现以 DNS 协议为基础的服务发现,以帮助您消除耦合到厂商私有服务发现 API 上的风险。
Nacos 提供了一些简单的 DNS APIs TODO 帮助您管理服务的关联域名和可用的 IP:PORT 列表. - 服务及其元数据管理
Nacos 能让您从微服务平台建设的视角管理数据中心的所有服务及元数据,包括管理服务的描述、生命周期、服务的静态依赖分析、服务的健康状态、服务的流量管理、路由及安全策略、服务的 SLA 以及最首要的 metrics 统计数据。
什么是RPC ?
RPC是远程过程调用(Remote Procedure Call)。 RPC 的主要功能目标是让构建分布式计算(应用)更容易,在提供强大的远程调用能力时不损失本地调用的语义简洁性。为实现该目标,RPC 框架需提供一种透明调用机制,让使用者不必显式的区分本地调用和远程调用。
特性
- 1、RPC框架一般使用长链接,不必每次通信都要3次握手,减少网络开销。
- 2、RPC框架一般都有注册中心,有丰富的监控管理。发布、下线接口、动态扩展等,对调用方来说是无感知、统一化的操作协议私密,安全性较高
- 3、RPC 协议更简单内容更小,效率更高,服务化架构、服务化治理,RPC框架是一个强力的支撑。
涉及到的技术
- 动态代理
生成Client Stub(客户端存根)和Server Stub(服务端存根)的时候需要用到java动态代理技术。 - 序列化 在网络中,所有的数据都将会被转化为字节进行传送,需要对这些参数进行序列化和反序列化操作。目前主流高效的开源序列化框架有Kryo、fastjson、Hessian、Protobuf等。
- NIO通信
Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的 NIO.2 支持。可以采用Netty或者mina框架来解决NIO数据传输的问题。开源的RPC框架Dubbo就是采用NIO通信,集成支持netty、mina、grizzly。 - 服务注册中心
通过注册中心,让客户端连接调用服务端所发布的服务。主流的注册中心组件:Redis、Zookeeper、Consul、Etcd。Dubbo采用的是ZooKeeper提供服务注册与发现功能。 - 负载均衡
在高并发的场景下,需要多个节点或集群来提升整体吞吐能力。 - 健康检查
健康检查包括,客户端心跳和服务端主动探测两种方式
缓存雪崩
什么是缓存雪崩、缓存击穿、缓存穿透? - 知乎 (zhihu.com)
Redis
为什么要用消息队列呢?
引入一个新的技术产品,肯定是要考虑为什么要用它呢?消息队列也不列外,说到为什么要用,还真是因为它能在某些场景下发挥奇效。例如:解耦,异步,削峰,这三个词你也听说过吧,那下面就就从这三个好处出发,讲讲到底什么是解耦,异步,削峰。
降低耦合,系统对于主系统的接口的调用需求不需要反复修改主系统代码,将该数据写到MQ中,主系统就不管了
系统A就只需要把产生的数据放到MQ里就行了,就可以立马返回用户响应。而不用//系统A中的代码
Data newData = productData();//系统A经过一些逻辑处理后产生了数据,耗时200ms
Response responseB = callSysB(newData);//系统A调系统B接口发送数据,耗时300ms
Response responseC = callSysC(newData);//系统A调系统C接口发送数据,耗时300ms
Response responseD = callSysD(newData);//系统A调系统D接口发送数据,耗时300ms
去等1秒
削峰 每秒就有可能举个例子是5000单,如果说下单要实时操作数据库,假设数据库最大承受一秒2000,那大促的时候一秒5000的话数据库肯定会被打死的,数据库一挂导致系统直接不可用,那是多么严重的事情
Session、Cookie、Token 【浅谈三者之间的那点事】
Session、Cookie、Token 【浅谈三者之间的那点事】-腾讯云开发者社区-腾讯云 (tencent.com)
JVM中如何理解强引用、软引用、弱引用、虚引用?
JVM中如何理解强引用、软引用、弱引用、虚引用? - 知乎 (zhihu.com)
MySQL百万级数据量分页查询方法及其优化
MySQL百万级数据量分页查询方法及其优化 - 知乎 (zhihu.com)
秒懂消息队列MQ,看这篇就够了!
秒懂消息队列MQ,看这篇就够了!-腾讯云开发者社区-腾讯云 (tencent.com)
反向代理和正向代理(nginx)负载均衡
深入理解 http 反向代理(nginx) - 知乎 (zhihu.com)
CDN Content Delivery Network,即内容分发网络。
CDN概念基本介绍 - 全能程序猿 - 博客园 (cnblogs.com)
分布式数据库的架构
彻底理解什么叫分布式数据库!! - 知乎 (zhihu.com)
分布式架构中的三高:高并发、高性能、高可用-腾讯云开发者社区-腾讯云 (tencent.com)
强一致性和最终一致性(主从复制)
微服务中的数据一致性:最终一致性与强一致性 (zhihu.com)
图解分布式之:最终一致性,一致只会迟到,但绝不缺席 - 四猿外 - 博客园 (cnblogs.com)
小白都能懂的Mysql主从复制原理(原理+实操) - 知乎 (zhihu.com)
本地(Native)方法
Java是解释性语言,因为它的源代码首先被编译成二进制字节码。 这个字节码运行在Java虚拟机 (JVM)上,JVM通常是一个基于软件的解释器,并不是直接在操作系统运行。
C/C++为编译型语言,源代码经过编译和链接后生成可执行的二进制代码,它依赖于底层操作系统和硬件特性
java native本地方法详解(转) - myseries - 博客园 (cnblogs.com)
JDK开放给用户的源码中随处可见Native方法,被Native关键字声明的方法说明该方法不是以Java语言实现的,而是以本地语言实现的,Java可以直接拿来用。这里有一个概念,就是本地语言,本地语言这四个字,个人理解应该就是可以和操作系统直接交互的语言。
Jvm和操作系统关系
一篇JVM详细图解,坚持看完!带你真正搞懂Java虚拟机! - 掘金 (juejin.cn)
JVM和操作系统的关系是什么?-腾讯云开发者社区-腾讯云 (tencent.com)

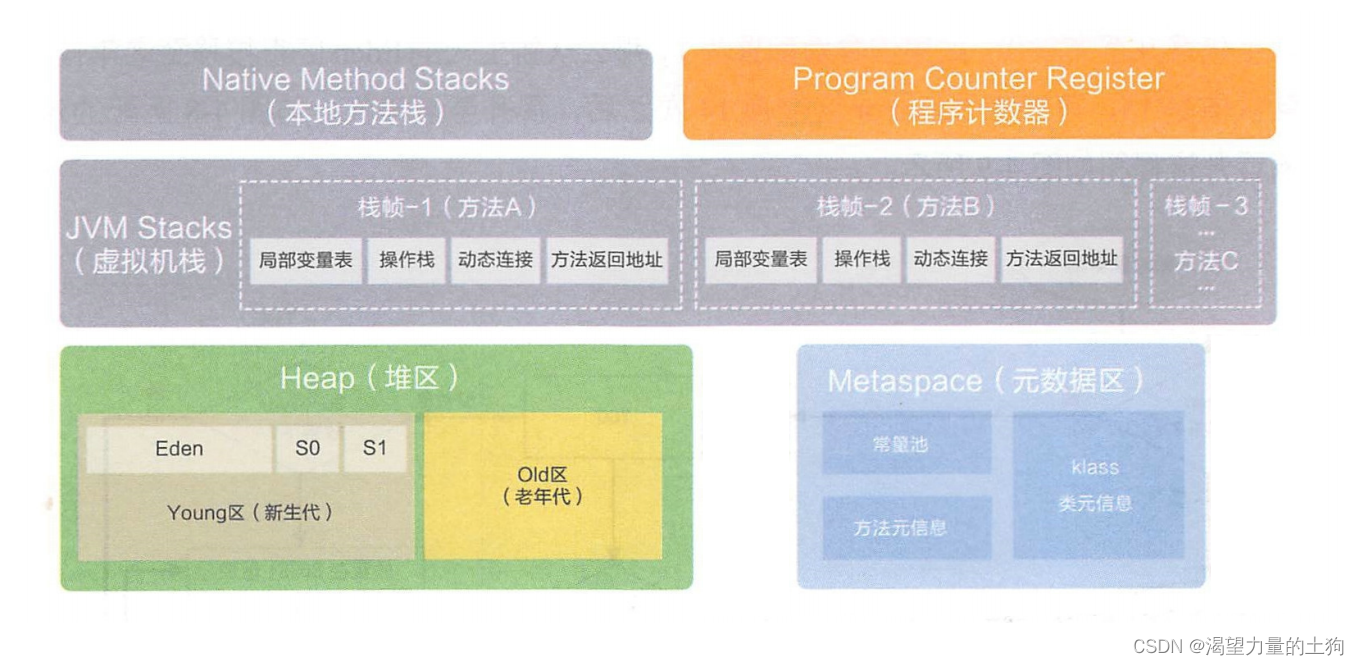
JVM 本地方法栈
理解JVM运行时数据区(一)概念 - 掘金 (juejin.cn)
理解JVM运行时数据区(四)本地方法栈 - 掘金 (juejin.cn)
分布式之CAP原则详解
协程
线程调度需要操作系统用户态转型内核态,线程被调度切换到另一个线程上下文的时候,需要保存一个用户线程的状态到内存,恢复另一个线程状态到寄存器,然后更新调度器的数据结构,这几步操作设计用户态到内核态转换,开销较多
协程调度不需要用到内核
干货 | 进程、线程、协程 10 张图讲明白了! - 知乎 (zhihu.com)
Go语言协程 vs. Java 21虚拟线程
Go语言协程 vs. Java 21虚拟线程 - 掘金 (juejin.cn)
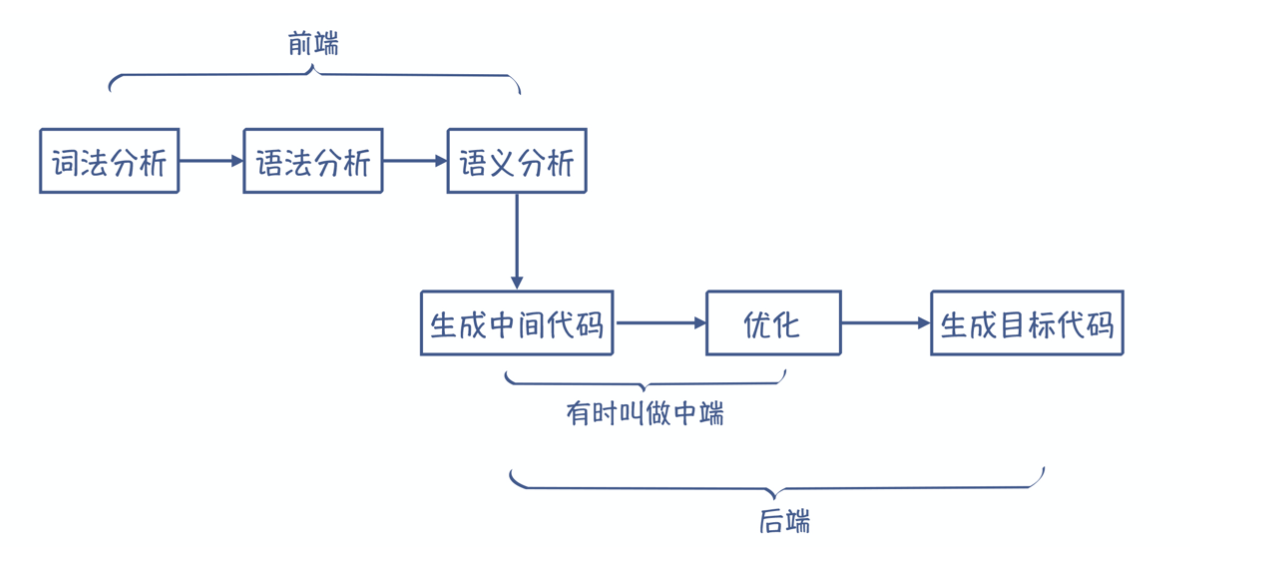
编译过程
编译原理入门篇|一篇文章理解编译全过程 - fishers - 博客园 (cnblogs.com)
内存泄漏(重点)
Memory leak:内存泄漏是指程序中动态分配的堆内存由于某种原因未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果,内存泄漏的堆积终将导致内存溢出
六大设计原则
IntelliJ IDEA总结(12) -- IntelliJ IDEA查看接口或抽象类的实现类 + 接口或类继承关系(向下+向上)_idea怎么查看一个接口的所有实现-CSDN博客
- 单一职责原则(Single Responsibility Principle);
- 开闭原则(Open Closed Principle);
- 里氏替换原则(Liskov Substitution Principle);
- 迪米特法则(Law of Demeter),又叫“最少知道法则”;
- 接口隔离原则(Interface Segregation Principle);
- 依赖倒置原则(Dependence Inversion Principle
六大设计原则超详细介绍(再不理解你打我) - 知乎 (zhihu.com)
Mybatis中强大的resultMap - 知乎 (zhihu.com)
resultMap的constructor(idArg、arg)和id、result使用的区别_resultmap constructor-CSDN博客
SQL去重的三种方法
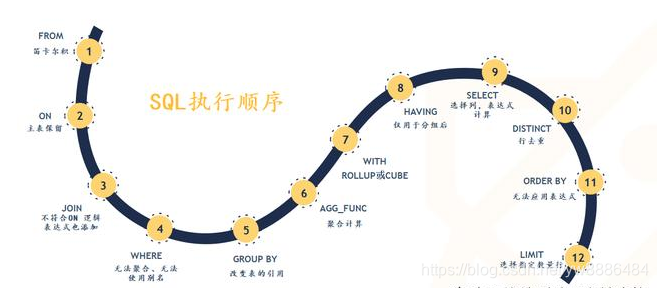
SELECT(窗口函数在此发生)
distinct
-- 列出 task_id 的所有唯一值(去重后的记录)
-- select distinct task_id
-- from Task;
-- 任务总数
select count(distinct task_id) task_num
from Task;
distinct 通常效率较低。它不适合用来展示去重后具体的值,一般与 count 配合用来计算条数。
distinct 使用中,放在 select 后边,对后面所有的字段的值统一进行去重。比如distinct后面有两个字段,那么 1,1 和 1,2 这两条记录不是重复值 。
group by(先分组,列出唯一值)
-- 列出 task_id 的所有唯一值(去重后的记录,null也是值)
-- select task_id
-- from Task
-- group by task_id;
-- 任务总数
select count(task_id) task_num
from (select task_id
from Task
group by task_id) tmp;
row_number
row_number 是窗口函数,语法如下:
row_number() over (partition by <用于分组的字段名> order by <用于组内排序的字段名>)
其中 partition by 部分可省略。
-- 在支持窗口函数的 sql 中使用
select count(case when rn=1 then task_id else null end) task_num
from (select task_id
, row_number() over (partition by task_id order by start_time) rn
from Task) tmp;
图解MySQL 内连接、外连接、左连接、右连接、全连接……太多了-CSDN博客
LeetCode 官方70道 SQL 精选题汇总(附MySQL代码) - 知乎 (zhihu.com)
为什么cap要保持为2的幂次方?
绝了!这是我见过最详细的HashMap源码解析-腾讯云开发者社区-腾讯云 (tencent.com)
线程池原理
创建线程池,待提交任务请求才调用方法创建线程
添加请求任务,正在运行的线程数量小于核心线程数,马上创建线程运行任务
大于等于核心线程数,把任务放在任务队列
任务队列满了,并且线程数量小于最大线程数,就创建非核心线程立即运行任务
虽然还在队列的任务不公平,因为创建线程都会绑定一个初始任务
队列满了,线程池满了就直接拒绝任务
InnoDB MySQL 上第一个提供外键约束的数据存储引擎
有Buffer Pool和 Redo LogBuffer。
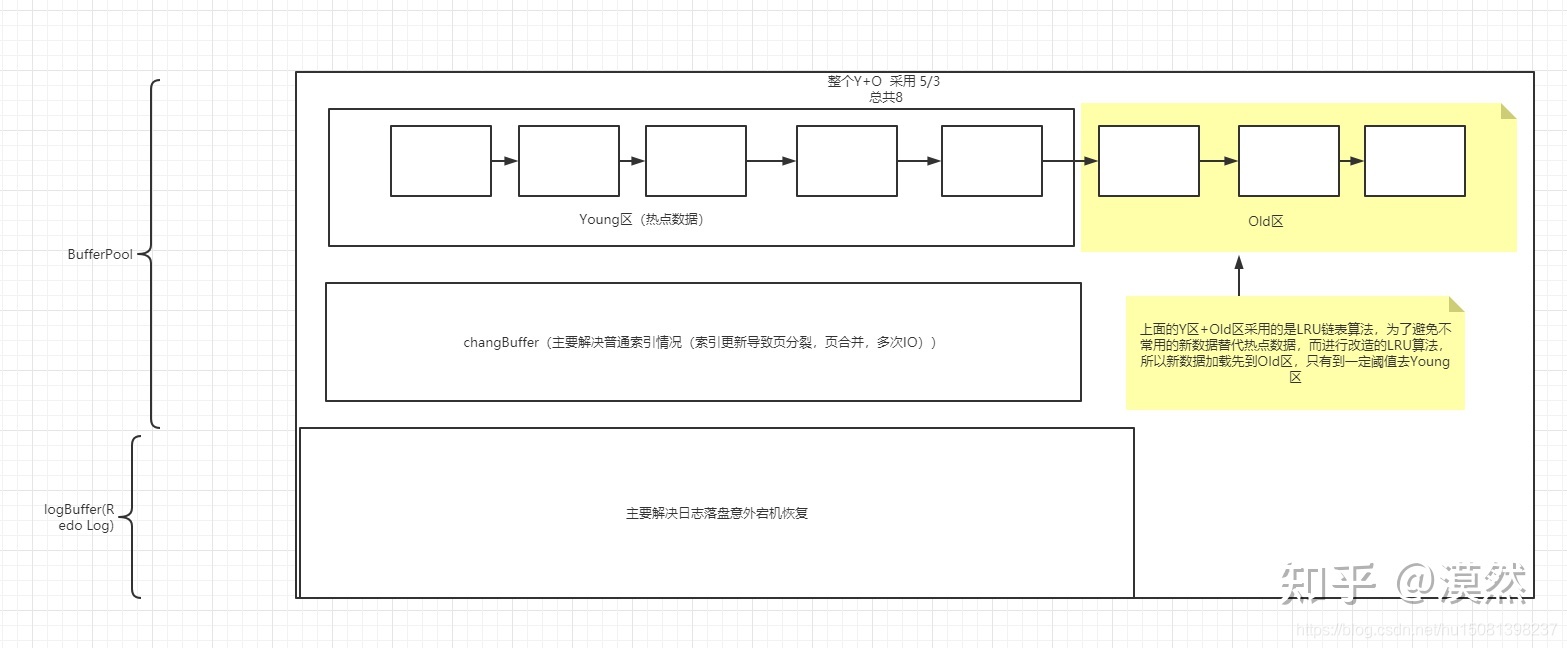
BufferPool 作为内存中的一块区域,在Innodb访问表的时候会将数据页和索引页缓存到缓冲池中。Innodb不管是主键索引还是辅助索引都是以页为单位存储在磁盘空间中的。当Innodb访问某个页的数据时候,会先把这个页整体加载到缓冲池中,然后在进行读写操作。在操作执行完毕后,也不会立即删除将这个页缓冲从缓冲池中删除,而是将它缓存起来,这样当下次再有操作访问这个页时,会直接从缓冲池获取,这样省去了磁盘IO开销,加快了数据访问速度。
LRU淘汰策略 毕竟缓存区大小是有限制的,不能数据一直存放在缓冲区中,所以就涉及到如何高效的清理,那么LRU淘汰算法就出来了
Change Buffer是一种特殊的数据结构,是针对二级索引(辅助索引)页的更新优化措施。当二级索引 页不在Buffer Pool中,InnoDB会将对二级索引的数据更改操作先暂时缓存在Change Buffer中,稍后当索引页面因为其他读取操作加载到Buffer Pool的时候,会将这些更改操作合并更新到索引页中
如果每次insert,update,delete操作完成后,都立即将脏页刷新到磁盘文件上,而一次更新操作可能需要多次磁盘IO,整个操作的IO成本会很高,更新效率就会很低。所以MySQL会将更新先缓存在内存中,当服务器空闲时才会选择将脏页刷新到磁盘中。
如果在脏页落盘之前如果服务器异常关机或者MySQL崩溃宕机,就会造成脏页这些数据的丢失
InnoDB把对页面的修改操作会同时写入一个日志文件持久化到磁盘上,这样当MySQL崩溃重启后,MySQL就会使用这个日志文件执行恢复操作,将更改重新应用到数据文件,实现了更新操作的持久化。这个日志文件就是Redo Log。
面试老大难:锁
第25章 工作面试老大难-锁 · 《MySQL 是怎样运行的:从根儿上理解 MySQL》 (kilvn.com)
面试中的老大难-mysql事务和锁,一次性讲清楚! - 掘金 (juejin.cn)
5分钟精通数据库MVCC原理-事务的隔离性_哔哩哔哩_bilibili
redo日志和undo日志
我们只是想让已经提交了的事务对数据库中数据所做的修改永久生效,即使后来系统崩溃,在重启后也能把这种修改恢复出来。所以我们其实没有必要在每次事务提交时就把该事务在内存中修改过的全部页面刷新到磁盘,只需要把修改了哪些东西记录一下就好。redo日志本质上只是记录了一下事务对数据库做了哪些修改
第20章 说过的话就一定要办到-redo日志(上) · 《MySQL 是怎样运行的:从根儿上理解 MySQL》 (kilvn.com)
第22章 后悔了怎么办-undo日志(上) · 《MySQL 是怎样运行的:从根儿上理解 MySQL》 (kilvn.com)
B++树
【面试被怼】什么是B树?为啥文件/数据库索引要用B树而不用二叉查找树? - 知乎 (zhihu.com)
图解:什么是B-树、B+树、B*树-腾讯云开发者社区-腾讯云 (tencent.com)
内存的运算速度是非常快的,至少比磁盘的寻址加载速度,快了几百倍,而我们进行数值比较的时候,是在内存中进行的,虽然 B 树的比较次数可能比二叉查找树多,但是单个节点储存数据多(内存比较),磁盘操作次数少(减少节点寻址加载),所以总体来说,还是 B 树快的多,这也是为什么我们用使用 B 树来存储的原因
困扰多年的Java泛型 extends T> super T>,终于搞清楚了!-腾讯云开发者社区-腾讯云 (tencent.com)
















 9318
9318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









