







主要参考这篇文献:Nava, L.; Bhuyan, K.; Meena, S.R.; Monserrat, O.; Catani, F. Rapid Mapping of Landslides on SAR Data by Attention U-Net. Remote Sens. 2022, 14, 1449.
滑坡是全球范围内常见的自然灾害,对区域发展与人类活动造成较大威胁。传统的滑坡监测和制图方法主要依赖于光学地球观测(EO)数据,但在云层遮蔽、夜间或极端天气条件下,光学影像的获取和使用受到严重限制。案例通过使用合成孔径雷达(SAR)数据,通过SAR能够在任何天气条件下和夜间获取地表信息的特点,并结合深度学习技术,实现在恶劣天气条件下快速识别滑坡的可能性。
这里采用的模型为Attention U-Net(Attn-U-Net),是一种改进的深度学习模型,基于经典的U-Net架构,通过引入注意力机制(Attention Mechanism),增强了模型对重要特征的关注能力,从而提高了分割的准确性和鲁棒性。
资料来源
安装依赖
- segmentation-models是一个基于PyTorch的图像分割库,提供了多种强大的模型架构(如U-Net、DeepLabV3+等),用于精确识别图像中的每个像素属于哪个目标。
- rasterio是一个用于处理栅格数据的Python库,基于GDAL。
- pencv-python是OpenCV的Python接口,是一个开源的计算机视觉库,提供了丰富的图像和视频处理功能。
!pip install segmentation-models rasterio -i https://mirrors.cloud.tencent.com/pypi/simple
!pip install opencv-python -i https://mirrors.cloud.tencent.com/pypi/simple
模型构建
构建模型,包括卷积层(Conv2D)、池化层(MaxPooling2D)、上采样层(UpSampling2D)、批归一化层(BatchNormalization)、Dropout层等
import cv2
import time
import os
import h5py
import pandas as pd
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Conv2DTranspose
from tensorflow.keras.layers import Activation, add, multiply, Lambda
from tensorflow.keras.layers import AveragePooling2D, average, UpSampling2D, Dropout
from tensorflow.keras.optimizers import Adam, SGD, RMSprop
from tensorflow.keras.initializers import glorot_normal, random_normal, random_uniform
from tensorflow.keras.callbacks import ModelCheckpoint, TensorBoard, EarlyStopping
from tensorflow.keras import backend as K
from tensorflow.keras.layers import BatchNormalization
from tensorflow.keras.applications import VGG19, densenet
from tensorflow.keras.models import load_model
import tensorflow as tf
import numpy as np
from matplotlib import pyplot as plt
import segmentation_models as sm
from tensorflow.keras.metrics import MeanIoU
import random
import rasterio
from rasterio.plot import show
from sklearn.model_selection import train_test_split
from tensorflow.keras import layers
from tensorflow import keras
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenate, Conv2DTranspose, BatchNormalization, Dropout, Lambda
from tensorflow.keras import backend as K
K.set_image_data_format('channels_last')
kinit = 'glorot_normal'
def expend_as(tensor, rep,name):
my_repeat = Lambda(lambda x, repnum: K.repeat_elements(x, repnum, axis=3), arguments={'repnum': rep}, name='psi_up'+name)(tensor)
return my_repeat
# 定义注意力门控块函数
def AttnGatingBlock(x, g, inter_shape, name):
shape_x = K.int_shape(x) # 32
shape_g = K.int_shape(g) # 16
theta_x = Conv2D(inter_shape, (2, 2), strides=(2, 2), padding='same', name='xl'+name)(x) # 16
shape_theta_x = K.int_shape(theta_x)
phi_g = Conv2D(inter_shape, (1, 1), padding='same')(g)
upsample_g = Conv2DTranspose(inter_shape, (3, 3),strides=(shape_theta_x[1] // shape_g[1], shape_theta_x[2] // shape_g[2]),padding='same', name='g_up'+name)(phi_g) # 16
concat_xg = add([upsample_g, theta_x])
act_xg = Activation('relu')(concat_xg)
psi = Conv2D(1, (1, 1), padding='same', name='psi'+name)(act_xg)
sigmoid_xg = Activation('sigmoid')(psi)
shape_sigmoid = K.int_shape(sigmoid_xg)
upsample_psi = UpSampling2D(size=(shape_x[1] // shape_sigmoid[1], shape_x[2] // shape_sigmoid[2]))(sigmoid_xg) # 32
upsample_psi = expend_as(upsample_psi, shape_x[3], name)
y = multiply([upsample_psi, x], name='q_attn'+name)
result = Conv2D(shape_x[3], (1, 1), padding='same',name='q_attn_conv'+name)(y)
result_bn = BatchNormalization(name='q_attn_bn'+name)(result)
return result_bn
# 定义U-Net中的卷积块函数
def UnetConv2D(input, outdim, is_batchnorm, name):
x = Conv2D(outdim, (3, 3), strides=(1, 1), kernel_initializer=kinit, padding="same", name=name+'_1')(input)
if is_batchnorm:
x =BatchNormalization(name=name + '_1_bn')(x)
x = Activation('relu',name=name + '_1_act')(x)
x = Conv2D(outdim, (3, 3), strides=(1, 1), kernel_initializer=kinit, padding="same", name=name+'_2')(x)
if is_batchnorm:
x = BatchNormalization(name=name + '_2_bn')(x)
x = Activation('relu', name=name + '_2_act')(x)
return x
# 定义U-Net中的门控信号函数
def UnetGatingSignal(input, is_batchnorm, name):
shape = K.int_shape(input)
x = Conv2D(shape[3] * 1, (1, 1), strides=(1, 1), padding="same", kernel_initializer=kinit, name=name + '_conv')(input)
if is_batchnorm:
x = BatchNormalization(name=name + '_bn')(x)
x = Activation('relu', name = name + '_act')(x)
return x
定义损失函数和评估指标
Dice 系数常用于评估图像分割任务中预测结果与真实标签的相似度,取值范围在 0 到 1 之间,越接近 1 表示预测结果与真实标签越相似。而 Dice 损失函数则是基于 Dice 系数定义的,用于在训练模型时作为优化目标,使得模型在训练过程中不断减小该损失值,从而提高预测的准确性。
import tensorflow.keras.backend as K
smooth = 1
#Dice 系数
def dsc(y_true, y_pred):
smooth = 1.
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
score = (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
return score
#Dice 损失函数
def dice_loss(y_true, y_pred):
loss = 1 - dsc(y_true, y_pred)
return loss
加载数据
数据已划分为训练集和测试集,X包含4个波段,由Sentinel-1和坡度组成,Y则为滑坡label
# Load data
X_train = np.load(f'/home/mw/input/landslide_data7730/trainX.npy')
Y_train = np.load(f'/home/mw/input/landslide_data7730/trainY.npy')
X_test = np.load(f'/home/mw/input/landslide_data7730/testX.npy')
Y_test = np.load(f'/home/mw/input/landslide_data7730/testY.npy')
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape
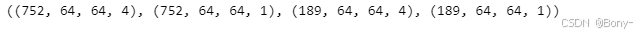
i=11
f, axarr = plt.subplots(1,2,figsize=(10,10))
axarr[0].imshow(X_test[i][:,:,3])
axarr[1].imshow(np.squeeze(Y_test[i]))
定义评估指标
精确率关注预测的准确性,召回率关注对正例的捕捉能力,F分数综合了两者,交并比则直观地反映了预测区域和真实区域的重合程度。
# define matrics
metrics = [sm.metrics.Precision(threshold=0.5),
sm.metrics.Recall(threshold=0.5),
sm.metrics.FScore(threshold=0.5,beta=1),
sm.metrics.IOUScore(threshold=0.5)]
模型训练和调参
进行模型训练和超参数调优,使用注意力 U-Net(Attention U-Net)模型进行预测,将不同超参数组合下的训练结果保存,同时绘制训练过程中的 F1 分数和损失曲线。
size = 64
img_bands = X_train.shape[3]
sampling = "no_overlap"
filters = [4, 8]
lr = [10e-3, 5e-4, 10e-5]
batch_size = [4, 8]
# Epochs
epochs = 200
dic = {}
dic["model"] = []
dic["batch_size"] = []
dic["learning_rate"] = []
dic["filters"] = []
dic["precision_area"] = []
dic["recall_area"] = []
dic["f1_score_area"] = []
dic["iou_score_area"] = []
# 超参数组合循环
for fiilter in filters:
for learning_rate in lr:
for batch in batch_size:
# 定义注意力 U-Net 模型
def attn_unet(lr,filtersFirstLayer, pretrained_weights = None,input_size = (size,size,img_bands)):
inputs = Input(shape=input_size)
conv1 = UnetConv2D(inputs, filtersFirstLayer, is_batchnorm=True, name='conv1')
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = UnetConv2D(pool1, filtersFirstLayer, is_batchnorm=True, name='conv2')
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = UnetConv2D(pool2, filtersFirstLayer*2, is_batchnorm=True, name='conv3')
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = UnetConv2D(pool3, filtersFirstLayer*2, is_batchnorm=True, name='conv4')
pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
center = UnetConv2D(pool4, filtersFirstLayer*4, is_batchnorm=True, name='center')
g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
attn1 = AttnGatingBlock(conv4, g1, filtersFirstLayer*4, '_1')
up1 = concatenate([Conv2DTranspose(filtersFirstLayer, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
attn2 = AttnGatingBlock(conv3, g2, filtersFirstLayer*2, '_2')
up2 = concatenate([Conv2DTranspose(filtersFirstLayer*2, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
attn3 = AttnGatingBlock(conv2, g3, filtersFirstLayer, '_3')
up3 = concatenate([Conv2DTranspose(filtersFirstLayer, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
up4 = concatenate([Conv2DTranspose(filtersFirstLayer, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
conv10 = Conv2D(1, (1, 1), activation='sigmoid', kernel_initializer=kinit, name='final')(up4)
model = Model(inputs, conv10)
model.compile(optimizer = Adam(lr = lr), loss = dice_loss, metrics = metrics)
model.summary()
if(pretrained_weights):
model.load_weights(pretrained_weights)
return model
# 加载模型
model = attn_unet(filtersFirstLayer=fiilter, lr=learning_rate, input_size=(size, size, img_bands))
# 如果验证损失在30个周期后没有下降,则停止训练
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', # 监测的指标是什么
patience=30, # 在看到val_loss增加后,继续运行模型的周期数
restore_best_weights=True) # 更新模型权重为最佳值
# 仅在验证损失下降时保存模型
model_checkpoint = tf.keras.callbacks.ModelCheckpoint(
f'/home/mw/data/weights/unet_{sampling}_size_{size}_filters_{fiilter}_batch_size_{batch}_lr_{learning_rate}.hdf5',
monitor='val_loss', mode='min', verbose=1, save_best_only=True, save_weights_only=True)
print(fiilter, learning_rate, batch)
# 训练模型,20%的数据集被用作验证集
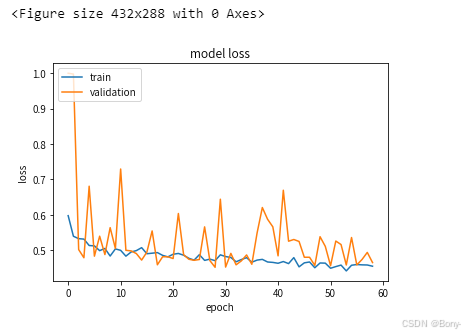
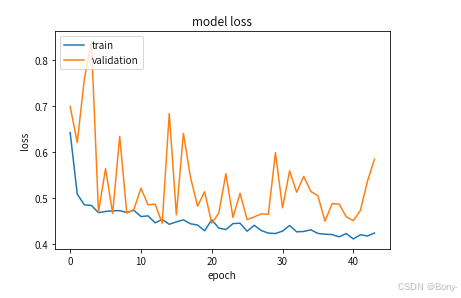
history = model.fit(X_train, Y_train, batch_size=batch, epochs=epochs, validation_split=0.2, callbacks=[model_checkpoint, early_stop])
# 保存
plt.savefig(f"/home/mw/data/plots/unet_{sampling}_size_{size}_filters_{fiilter}_batch_size_{batch}_lr_{learning_rate}_iou_score.png")
plt.show()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.savefig(f"/home/mw/data/plots/unet_{sampling}_size_{size}_filters_{fiilter}_batch_size_{batch}_lr_{learning_rate}_val_loss.png")
plt.show()
# 模型评估和结果保存
attn_unet = attn_unet(filtersFirstLayer= fiilter, lr = learning_rate,input_size=(size,size,img_bands))
attn_unet.load_weights(f"/home/mw/data/weights/unet_{sampling}_size_{size}_filters_{fiilter}_batch_size_{batch}_lr_{learning_rate}.hdf5")
res_1= attn_unet.evaluate(X_test,Y_test)
dic["model"].append("Attention_Unet")
dic["batch_size"].append(batch)
dic["learning_rate"].append(learning_rate)
dic["filters"].append(fiilter)
dic["precision_area"].append(res_1[1])
dic["recall_area"].append(res_1[2])
dic["f1_score_area"].append(res_1[3])
dic["iou_score_area"].append(res_1[4])
results = pd.DataFrame(dic)
# csv导出
results.to_csv(f'/home/mw/data/results/results_Att_Unet.csv', index = False)


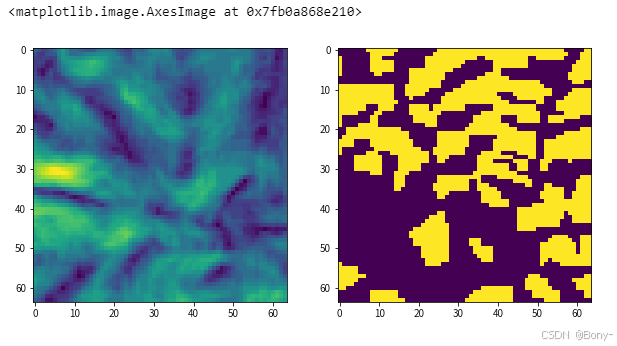
…
def attn_unet(lr,filtersFirstLayer, pretrained_weights = None,input_size = (size,size,img_bands)):
inputs = Input(shape=input_size)
conv1 = UnetConv2D(inputs, filtersFirstLayer, is_batchnorm=True, name='conv1')
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = UnetConv2D(pool1, filtersFirstLayer, is_batchnorm=True, name='conv2')
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = UnetConv2D(pool2, filtersFirstLayer*2, is_batchnorm=True, name='conv3')
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = UnetConv2D(pool3, filtersFirstLayer*2, is_batchnorm=True, name='conv4')
pool4 = MaxPooling2D(pool_size=(2, 2))(conv4)
center = UnetConv2D(pool4, filtersFirstLayer*4, is_batchnorm=True, name='center')
g1 = UnetGatingSignal(center, is_batchnorm=True, name='g1')
attn1 = AttnGatingBlock(conv4, g1, filtersFirstLayer*4, '_1')
up1 = concatenate([Conv2DTranspose(filtersFirstLayer, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(center), attn1], name='up1')
g2 = UnetGatingSignal(up1, is_batchnorm=True, name='g2')
attn2 = AttnGatingBlock(conv3, g2, filtersFirstLayer*2, '_2')
up2 = concatenate([Conv2DTranspose(filtersFirstLayer*2, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up1), attn2], name='up2')
g3 = UnetGatingSignal(up1, is_batchnorm=True, name='g3')
attn3 = AttnGatingBlock(conv2, g3, filtersFirstLayer, '_3')
up3 = concatenate([Conv2DTranspose(filtersFirstLayer, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up2), attn3], name='up3')
up4 = concatenate([Conv2DTranspose(filtersFirstLayer, (3,3), strides=(2,2), padding='same', activation='relu', kernel_initializer=kinit)(up3), conv1], name='up4')
conv10 = Conv2D(1, (1, 1), activation='sigmoid', kernel_initializer=kinit, name='final')(up4)
model = Model(inputs, conv10)
model.compile(optimizer = Adam(lr = lr), loss = dice_loss, metrics = metrics)
# model.summary()
if(pretrained_weights):
model.load_weights(pretrained_weights)
return model
加载和显示训练结果
# 加载结果csv
results_df = pd.read_csv(f'/home/mw/data/results/results_Att_Unet.csv')
print("Training Results:")
print(results_df)
#表格绘制显示
for metric in ["precision_area", "recall_area", "f1_score_area", "iou_score_area"]:
plt.figure(figsize=(10, 6))
for batch in batch_size:
subset = results_df[results_df["batch_size"] == batch]
plt.plot(subset["learning_rate"], subset[metric], label=f"Batch Size {batch}")
plt.title(f"Comparison of {metric}")
plt.xlabel("Learning Rate")
plt.ylabel(metric)
plt.legend()
plt.grid(True)
plt.savefig(f"/home/mw/data/plots/results_comparison_{metric}.png")
plt.show()
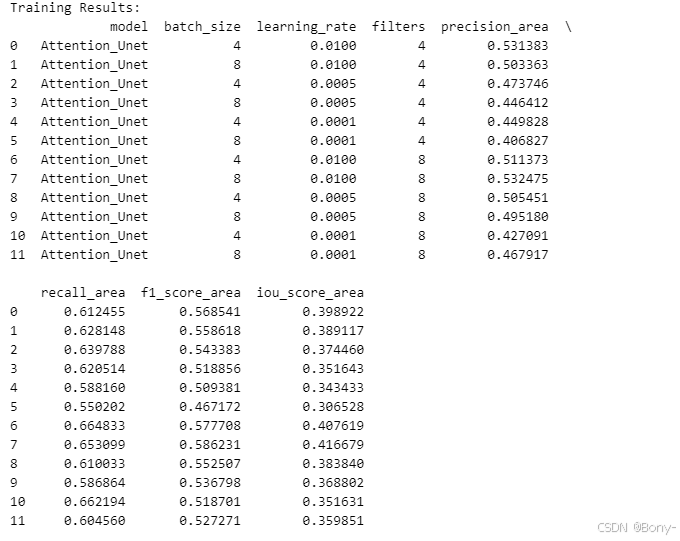
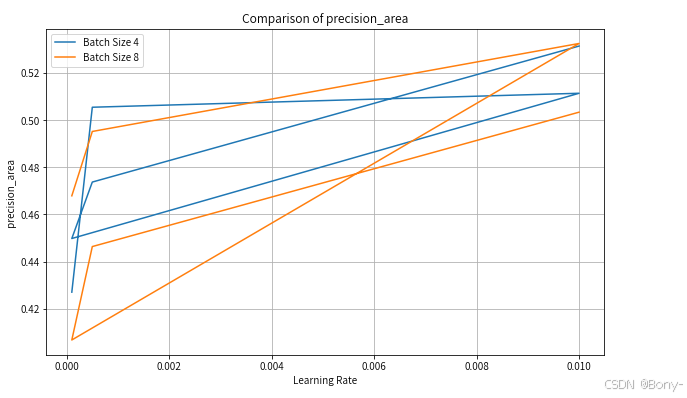
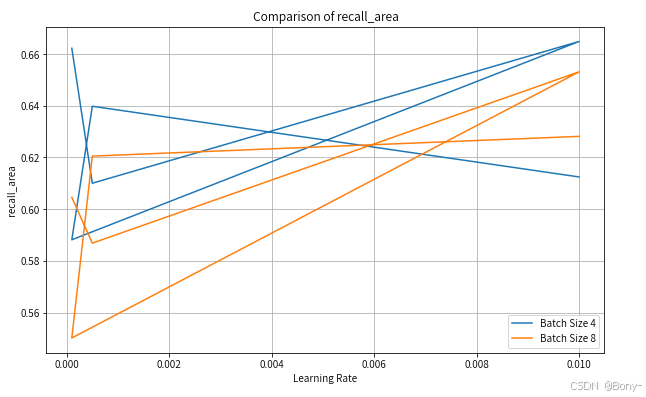
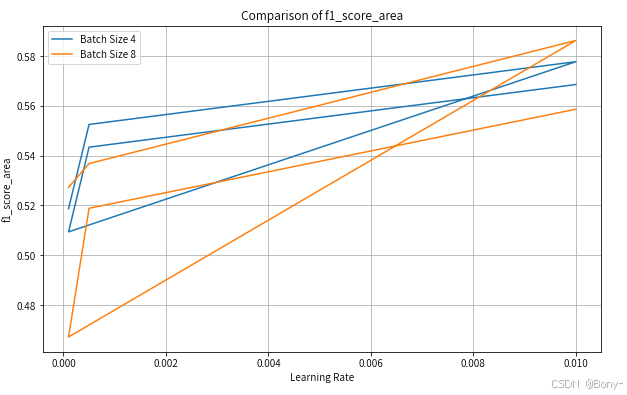
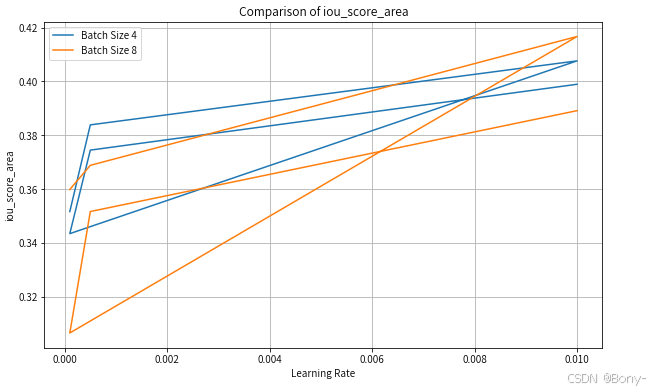
其实精度都不怎么好,算力限制,可以增加超参数的选择和循环次数,不过作为案例演示也够了,这里learning_rate和filters分别设置0.01和4,选择为最优模型
# 选取最优模型
size = 64
img_bands=4
print(size, img_bands)
attn_unet_best = attn_unet(filtersFirstLayer=4, lr = 0.01, input_size =(size,size,img_bands)) # 使用与权重文件一致的学习率
print(attn_unet_best.summary())
# 加载预训练权重
attn_unet_best.load_weights("/home/mw/data/weights/unet_no_overlap_size_64_filters_4_batch_size_4_lr_0.01.hdf5")

import numpy as np
import matplotlib.pyplot as plt
# 指定要预测的测试样本索引
sample_index = 30
# 对指定样本进行预测
preds_train_1 = attn_unet_best.predict(np.expand_dims(X_test[sample_index], axis=0), verbose=1)
preds_train_t1 = (preds_train_1 > 0.5).astype(np.uint8) # 应用阈值
# 绘制原始图像、预测结果和真实标签
f, axarr = plt.subplots(1, 3, figsize=(15, 5))
# 原始图像
axarr[0].imshow(X_test[sample_index][:, :, 0])
axarr[0].set_title('Original Image')
axarr[0].axis('off')
# 预测结果
axarr[1].imshow(np.squeeze(preds_train_t1))
axarr[1].set_title('Predicted Mask')
axarr[1].axis('off')
# 真实标签
axarr[2].imshow(np.squeeze(Y_test[sample_index]))
axarr[2].set_title('True Mask')
axarr[2].axis('off')
# 显示图表
plt.show()


















 1213
1213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









