






Softmax简介
Softmax 是一个用于多类别分类问题的激活函数,它通常用于神经网络的输出层。
Softmax 函数将一个实数向量转换为概率分布,其中每个元素表示一个类别的概率。
简单来说,Softmax的输出代表了一个样本属于某一类别的概率。
输出是概率分布:Softmax 将输入转换成一个概率分布,其中每个元素表示相应类别的概率。这意味着所有输出元素的总和将等于 1。
分类任务:Softmax 常用于多类别分类问题,其中有多个互斥的类别需要被分配概率。

图中,an代表了该y=n的概率预测。
注意:实际操作中,并不推荐使用y=10这样的形式,因为会使得成本函数计算时产生偏见,即10本身会让成本函数变大。推荐使用下文中的one-hot独热编码对标签进行重构。
One-hot独热编码
独热编码(One-Hot Encoding)是一种用于将分类数据转换成机器学习算法可以更好理解的形式的技术。它常用于处理分类特征,将每个分类值映射为一个二进制向量,其中只有一个元素为 1,其余为 0。这个二进制向量表示了数据点所属的类别或分类。

2种方法实现one-hot标签重构:
# pandas方法
import pandas as pd
target = pd.get_dummies(data['result'])
# tensorflow内置方法
from tensorflow.keras.utils import to_categorical
target = to_categorical(data['result'])
softmax的成本函数——多分类交叉熵
为真实值,
为拟合值(预测值)
这里
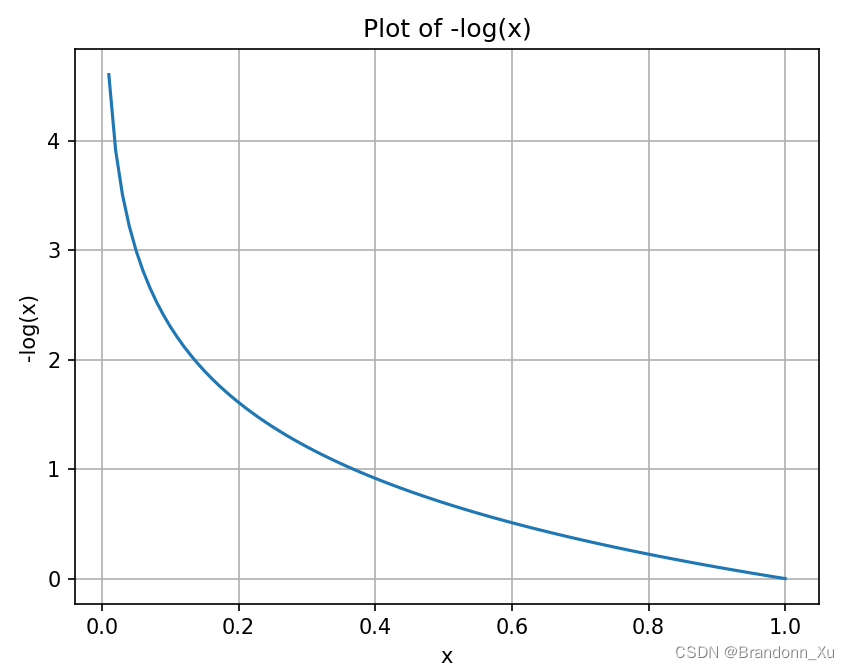
例如:
- 假设模型预测3个类别,
- Softmax输出的预测概率为[0.8,0.1,0.1],但该样本真实类别为[0,1,0]
- 成本函数值= -1* [ 0*log(0.8)+1*log(0.1)+0*log(0.1) ] = -log(0.1)
- 此处预测失败,-1*log(0.1)的绝对值较大,故作为本次判断的惩罚
- 假设预测正确——样本真实类别为[1,0,0],成本函数值= -1* [ 1*log(0.8)+0*log(0.1)+0*log(0.1) ] = -log(0.8)
- 此处预测正确,-1 * log(0.8)的绝对值较小
Tensorflow代码实现
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 构建神经网络
model = Sequential(
[
Dense(50, activation = 'relu'),
Dense(10, activation = 'relu'),
Dense(5, activation = 'softmax')
]
)
# 编译模型
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy,
optimizer=tf.keras.optimizers.Adam(0.01),
)
# 训练模型,设置20%的数据为交叉验证集
model.fit(
X_train,
y_train,
validationi_split=0.2,
epochs=10
)
优化Tensorflow代码
一种优化的思路是把最后一层设置为线性层,直接输出类别分数an。再通过from_logits=True,使模型在计算loss值时考虑softmax的交叉熵函数。
如此一来,模型会直接把an给到log函数,再通过对指数运算与对数运算的重新编排减少精度丢失。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 构建神经网络,设置最后一层为线性层,而非Softmax
model = Sequential(
[
Dense(50, activation = 'relu'),
Dense(10, activation = 'relu'),
Dense(5, activation = 'linear')
]
)
# 编译模型,指定From_logits=True。这里等于告诉模型,用softmax计算最后一层的线性输出
model.compile(
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(0.01),
)
# 训练模型,其中设置20%数据为交叉验证集
model.fit(
X_train,
y_train,
validationi_split=0.2,
epochs=10
)参考文献:GitHub - kaieye/2022-Machine-Learning-Specialization














 2485
2485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









