







状态转移方程
常规的Floyd算法目的在于找最短路,状态转移方程为:dis[i,j]=min{dis[i,k]+dis[k,j],dis[i,j]},距离矩阵初始化为正无穷;本实验目的在于找最长路,所以状态转移方程:dis[i,j]=max{dis[i,k]+dis[k,j],dis[i,j]},距离矩阵初始化为负无穷。
优化思路
众所周知Floyd算法的最外层循环k存在dependence,是不能并行的,所以重点在于如何并行内层的两重循环。在之前的实验中我们把内层的i、j两重循环交给了acc gang和vector,看起来似乎没有优化空间了。
其实还有一个优化的方向,那就是将数据分块,不同的显卡负责不同块数据的计算。虽然我们使用的是线性数组,但是你可以将它想象为方阵,方阵的宽高是SIZE,横着把方阵切几刀,这样就有了若干个block,每一个block的高度就是blocksize。
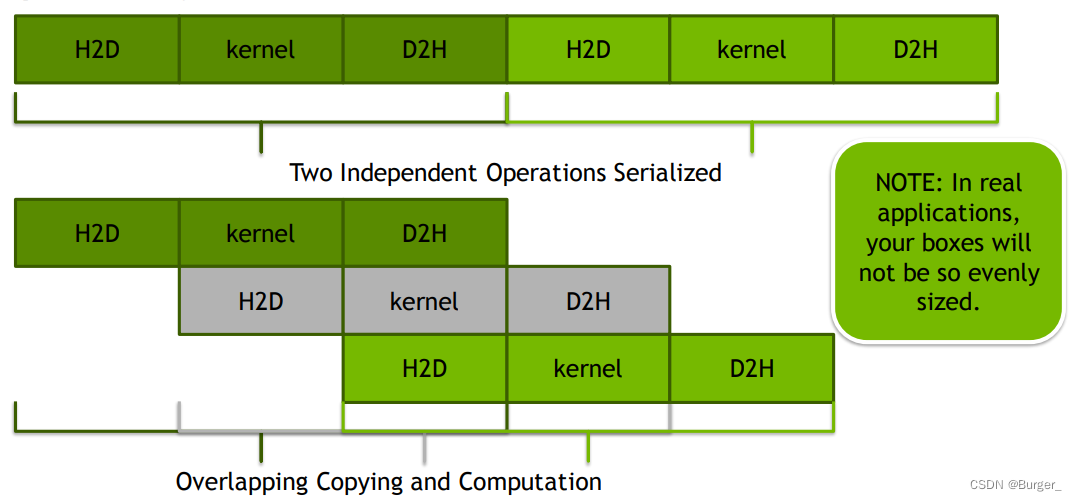
优化的核心思路如下图:
即每张卡并不是齐头并进,而是有先后顺序,通过async来控制异步。
写代码的过程中需要经常思考这样几个问题:
- 我的数据传到了哪里?
- 显卡上计算出了什么数据?
- 显卡上的数据是否回传?
- 计算完成之后哪张显卡有全部计算好的数据?
- ……
有几个小细节需要注意:
- copy的作用是在GPU上申请内存并将CPU数据拷贝到显存,在退出data region的时候会从GPU拷贝数据到CPU。把copy分解便是create、copyin和copyout,copyout在多卡的时候会出现问题,如果最后一次copyout恰巧是从拥有完整计算结果的显卡拷贝,那没有问题,否则就错了。所以在本次实验中我们采用create与copyin的组合。
- 数据不需要更新地太频繁,计算完一个block更新一次就可以。
- data[a:b]的第二个参数是步长而不是终止点。

代码
floyd.cpp
#define INF 1e7 #include <omp.h> #include <openacc.h> #include <math.h> #include <stdio.h> #include <stdlib.h> #include <assert.h> #include <algorithm> using namespace std; inline int index(const int i, const int j) { return i * SIZE + j; } // add your codes begin #define processor 2 // add your codes end int main() { const int size2 = SIZE * SIZE; float *data = new float[size2]; for (int i = 0; i < size2; i++) data[i] = -INF; srand(SIZE); for (int i = 0; i < SIZE*20; i++) { int prev = rand() % SIZE; int next = rand() % SIZE; if ((prev == next) || (data[index(prev, next)] > -INF)) { i--; continue; } data[index(prev, next)] = log((rand() % 99 + 1.0) / 100); } double t = omp_get_wtime(); // add your codes begin int blocksize=SIZE/processor; omp_set_num_threads(processor); #pragma omp parallel { int my_gpu=omp_get_thread_num(); acc_set_device_num(my_gpu,acc_device_nvidia); #pragma acc data copyin(data[0:size2])//不能使用copy { #pragma omp for schedule(static,1) for(int block=0;block<processor;block++){ int istart=block*blocksize; int iend=istart+blocksize; for(int k=0;k<SIZE;k++){ #pragma acc parallel loop gang worker num_workers(4) vector_length(128) async(block) for(int i=istart;i<iend;i++){ #pragma acc loop vector for(int j=0;j<SIZE;j++){ if(data[index(i,j)]<data[index(i,k)]+data[index(k,j)]){ data[index(i,j)]=data[index(i,k)]+data[index(k,j)]; } } } } #pragma acc update self(data[istart*SIZE:SIZE*blocksize]) async(block) } #pragma acc wait } } // add your codes end t = omp_get_wtime() - t; printf("time %f %d\n", t, SIZE); for (int i = 0; i < 20; i++) { int prev = rand() % SIZE; int next = rand() % SIZE; if (prev == next) { i--; continue; } printf("test %d %d %f\n", prev, next, data[index(prev, next)]); } }
run.sh(2卡)
source device.sh 2 make clean # timeout 1m time make serial # timeout 1m time make multicore # timeout 1m time make managed # timeout 1m time make optimize timeout 1m time make multidevice注释掉了serial、multicore、managed、optimize,只编译多卡,这样缩短了等待时间。
运行结果
2卡2线程的话平均运行时间可以达到1.65~1.75左右。
4卡4线程的话平均运行时间可以达到1.45~1.75左右。
写在最后
有问题欢迎在评论区讨论
















 2758
2758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











