







动手点关注 干货不迷路 👇
前言
HiveServer2 属于 Hive 组件的一个服务,主要提供 Hive 访问接口,例如可通过 JDBC 的方式提交 Hive 作业,HiveServer2 基于 Java 开发,整个服务运行过程中,内存的管理回收均由 JVM 进行控制。在 JVM 语言中的内存泄漏与 C/C++ 语言的内存泄漏会有些差异,JVM 的内存泄漏更多的是业务代码逻辑错误引起大量对象引用被持有,导致多次 GC 均无法被回收,或者部分对象占用内存过大,直接超过 JVM 分配的内存上限,导致 JVM 内存耗尽,引起 JVM 的 OOM。这种情况下该 JVM 服务会停止响应并且退出,但是并不会引起操作系统的崩溃。
背景
近期收到反馈,一套开启高可用的 EMR 集群中的 HiveServer2 一段时间后便会停止服务,此集群的 HiveServer2 一共有3个节点,状态信息注册至 Zookeeper 中,提供 HA 的能力,一段时间后几乎3个节点都会停止服务,通过对 HiveServer2 的日志查看发现是大量的 FULL GC后出现 OOM:
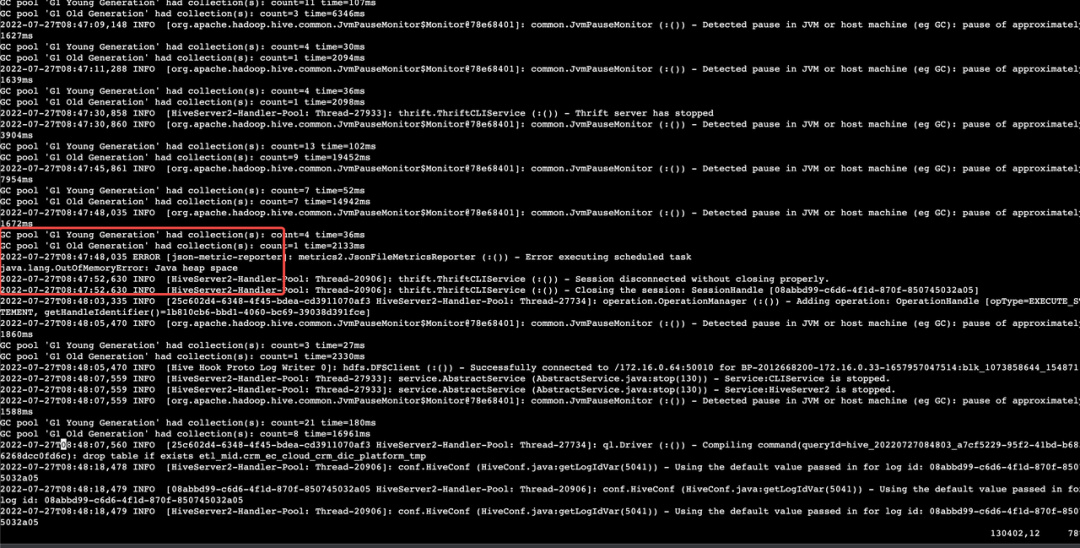
了解到该集群是一套从线下私有化部署的集群迁移而来,迁移前的集群中 HiveServer2 的 heapsize 为 2G,于是为了对齐业务参数将 heapsize 调整至 2G,间隔一天后,再次收到反馈,OOM 的问题依旧存在,查看日志,问题依旧是 HiveServer2 发生了 OOM,由于参数已经对齐之前的配置,那么问题可能不单纯是内存不足,可能会有其他问题。于是首先将 HiveServer2 的 heapsize 调整为 4G,确保可以在一定时间内稳定运行,留下定位时间。
定位
定位方向为两个方向:一个是分析 dump file,查看在内存不足的时候,内存消耗在哪些地方;第二个方向是针对日志进行细粒度分析,确保整个流程执行顺序是合理的。
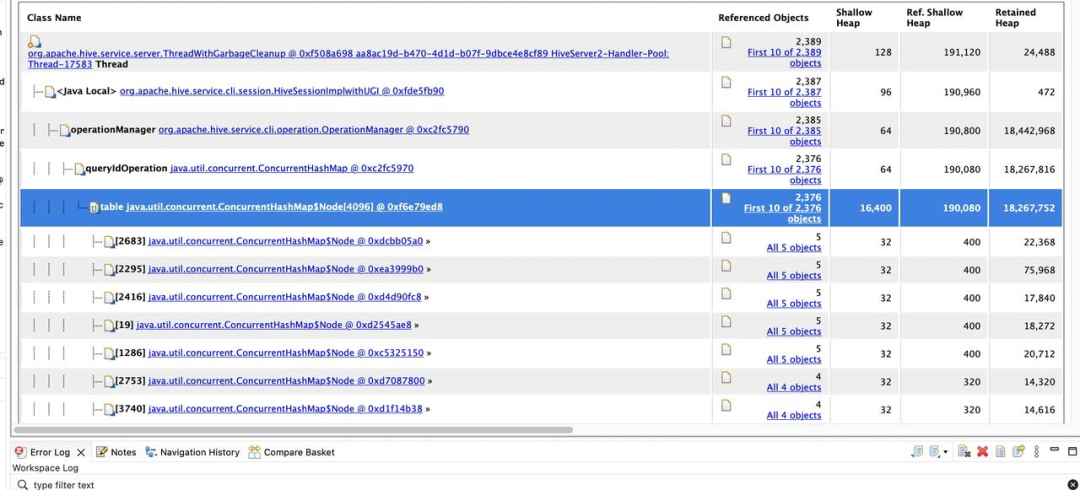
通过对 JVM 的 dump 文件进行分析,定位到在发生 HiveServer2 的 OOM 的时候,queryIdOperation 这个 ConcurrentHashMap 占据了大量的内存,而此时 HiveServer2 的负载非常低。

再基于具体的 QueryId 进行跟踪日志,HiveServer2 对作业处理的逻辑为在建立 Connection 的时候会调用一次 OpenSession,拿到一个HiveConnection 对象,此后便通过 HiveConnection 对象调用 ExecuteStatement 执行 SQL,后台每接收到一个 SQL 作业便生成一个 Operation 对象用来对 SQL 作业实现隔离。
每一个 Operation 有自己独立的 QueryId,每条 SQL 作业会经历编译,执行,关闭环节,注意此关闭指的是关闭当前执行的 SQL 作业,而不是关闭整个 HiveServer2 的连接,基于此思路追踪日志,发现部分 QueryId 没有执行 Close operation 方法。
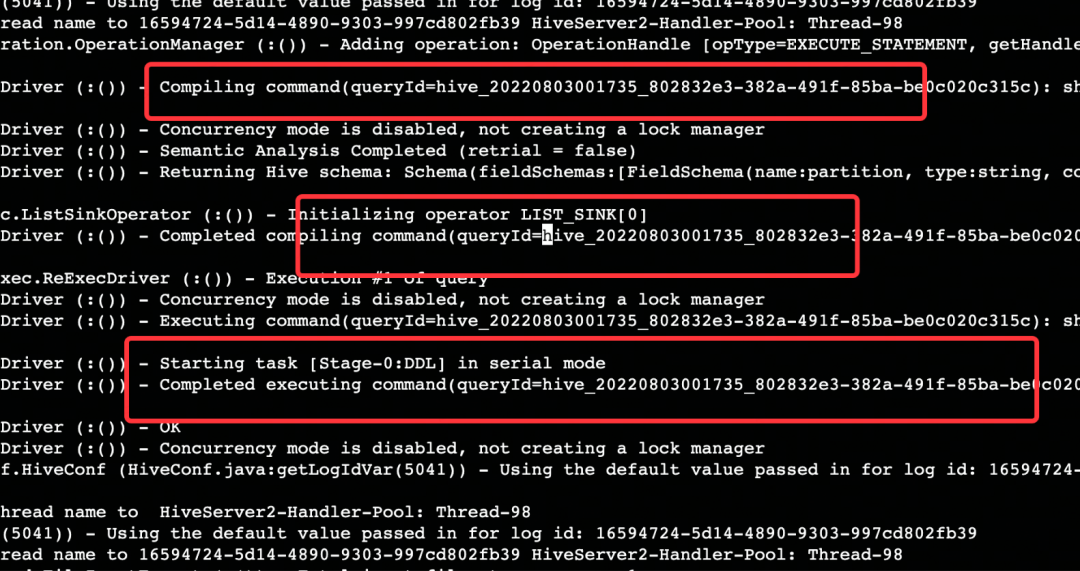
有了这个思路后,再对 Hive 的源码进行查阅,发现 Close operation 方法被调用的前提是在一个名称为 queryIdOperation 的 Map 对象中可以找出 QueryId,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









