




 文章讲述了在使用PyTorch训练CIFAR10数据集的卷积神经网络模型时遇到CUDA内存溢出问题,通过调整batch_size和网络结构解决了问题。具体表现为调整输入输出shape,减少模型复杂度,最终实现模型的训练并保存权重。
文章讲述了在使用PyTorch训练CIFAR10数据集的卷积神经网络模型时遇到CUDA内存溢出问题,通过调整batch_size和网络结构解决了问题。具体表现为调整输入输出shape,减少模型复杂度,最终实现模型的训练并保存权重。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 8.00 GiB (GPU 0; 7.92 GiB total capacity; 1.48 MiB already allocated; 6.91 GiB free; 22.00 MiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
遇到这个错误,按网上改小batch_size改的很小了,依然报错。
后改小了网络结构,搞定。
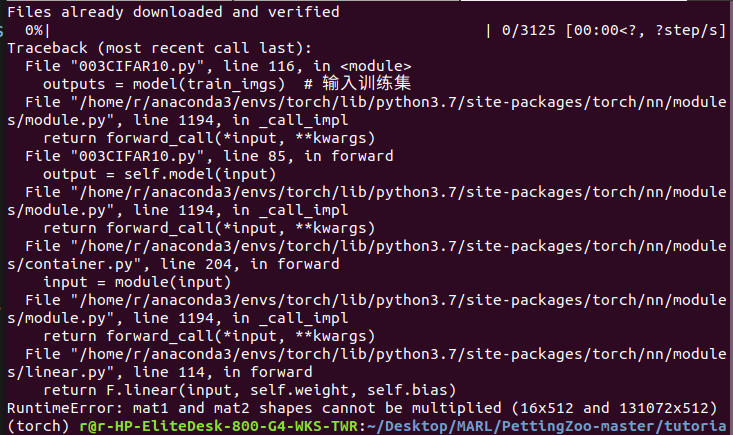
错误原因是网络的输入输出shape不一致。
错误的shape
128 * 128 * 8=131072
改后。
torch.nn.Flatten(),
torch.nn.Linear(in_features=8 * 8 * 8, out_features=512),
import torch
from matplotlib import pyplot as plt
from torch import nn, optim
# from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from tqdm import tqdm
from matplotlib.ticker import MaxNLocator
# 超参数
batch_size = 128 # 批大小
learning_rate = 0.0001 # 学习率
epochs = 20 # 迭代次数
channels = 3 # 图像通道大小
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer','dog', 'frog', 'horse', 'ship', 'truck']
# 数据集下载和预处理
transform = transforms.Compose([transforms.ToTensor(), # 将图片转换成PyTorch中处理的对象Tensor,并且进行标准化0-1
transforms.Normalize([0.5], [0.5])]) # 归一化处理
path = './data/' # 数据集下载后保存的目录
# 下载训练集和测试集
trainData = datasets.CIFAR10(path, train=True, transform=transform, download=True)
testData = datasets.CIFAR10(path, train=False, transform=transform)
# 将数据集前20个图片数据可视化显示
# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









