







使用中文维基百科语料库的word2vec模型计算书籍距离
前言
书蕴笔记系列索引在这里:书蕴——基于书评的人工智能推荐系统
前面说到了我们已经提取出每本书的标签集合了,那么现在的关键问题就是通过标签来进行书籍推荐了,这大概也是一个阶段性重点了,毕竟这个时间节点是直接见成效的时刻。这篇博客将以“计算书籍之间的距离”为主,先介绍思路,重点通过控制变量法调节各个参数,罗列出不同的效果,并确定效果最好的阈值。
思路
当我们已经拿到每本书的标签(tags[])之后,剩下的就是去找tags列表里每一项之间的距离。
这里每一项都是上一篇文章的思路下计算得到的标签集合
具体思路是:使用中文维基百科语料库训练出的word2vec模型作为泛集,在泛集中找到两本书标签之间的距离,使用平均值等不同方式计算书与书的距离。
泛集与中文维基百科
这里先谈一谈“泛集”的概念。我们把使用平时说话、正常语境下的语料库训练出的word2vec模型称为泛集,因为泛集“泛”的特点,它涵盖的内容更加贴近我们的生活,比如我们在生活中知道“男人之于女人正如男孩之于女孩”,我们知道,泛集也知道。所以把这些标签放在泛集中计算关联度更具有生活层面上意义,具体的做法可以见下图
[题外话]我使用gensim的word2vec训练维基百科语料库的内容在 [书蕴笔记-1]word2vec模型训练 中有过提及,参考资料也不少,欢迎查看
结合例子
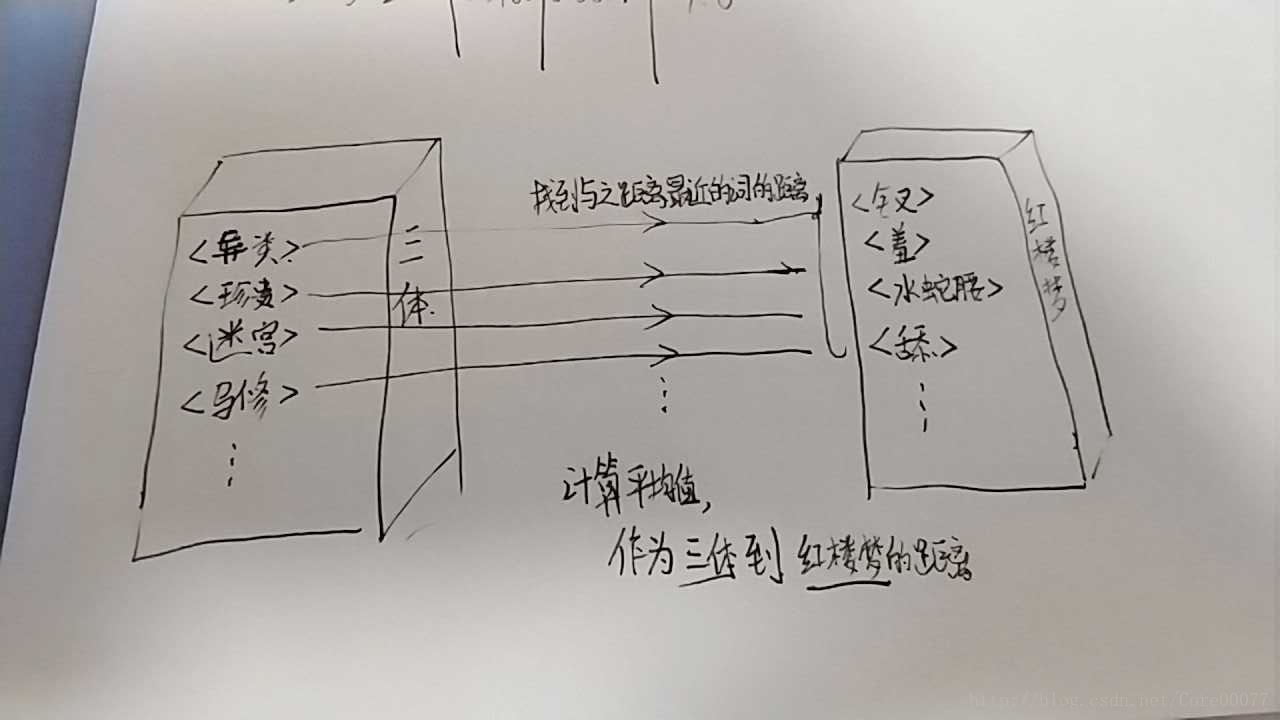
结合这张图比方说《三体》这本书有很多个标签,标签<异类>这个词和《红楼梦》这本书的众多标签都有距离,那么我们取最近的1个(或多个求平均)的距离,称之为“标签-书最近距离”,重复整个过程,然后《三体》的所有标签都有一个值,取平均值,这个平均值作为《三体》到《红楼梦》两本书直接的距离。
合理性
稍微解释下这样计算的合理性:
一开始我是计算《三体》中每个标签到《红楼梦》中所有标签的距离的平均值,因为一个标签到所有标签的距离的平均,不就该是这个标签到这本书的距离么?然而结果却不尽人意(后面结果部分会提及),当我测试到这本书到自己的距离的时候,竟然结果差强人意到只有0.058,这显然是不符合的。
为了表述清晰,这里把源书称作为书A,目标书称作为书B。书A的标签列表称作为A.tag,第一个标签为A.tag[0],B也类似。
分析其实不难看出,关键就在A书的标签A.tag[0]到B.tag的所有标签而言,大部分的关联度本就是非常低的。假设A.tag[0]最近的那个标签是B.tag[x],那这个距离我们假设是1(1是最近距离,即这个标签在B书中也存在),而A.tag[0]到其他标签的距离都比较远(这种情况很容易出现,比如在泛集中,三体中的标签<宇宙>和三体3中的标签<宇宙>距离很近,而和三体3的标签<马修>距离非常远——毕竟我们平时说起宇宙,没人会想到马修)那么A.tag[0]这B书的联系,就会被大量不相关的词语给“分摊”掉,从而得到一个非常低的结果。
所以我们改为取A.tag[0]到B.tag中最近标签的距离,即取A书到B书关联度最大的词的距离,再求平均。
这就是一个词到一本书的距离的计算,取这个词到一本书的所有词距离最近的那一个。
当然这样也是有缺陷的。毕竟一个词到一本书的距离不能只由这本书最近的一个标签来决定,至少应该取前几求平均。
流程
如果一本书有n个标签,那么计算这本书与其他书之间的距离分为两步:
- 计算标签X到一群标签的距离
- 反复步骤1,取这些距离的平均值。
所以不难看出重点在于第一步。
下面通过不同的维度的不同参数、使用控制变量法来对第一步进行实验。
源码
from gensim.models import Word2Vec
import os
def extract_tag_set(model_name, new_word_set):
word2vec_base = '书评\\word2vec\\model\\'
model = Word2Vec.load(word2vec_base + model_name) # type: Word2Vec
word_set = set() # 结果集
# new_word_set = {"阿米尔"} # 新词集
temp_word_set = set() # 关联词集
for i in range(3):
for word in new_word_set:
top5 = model.wv.most_similar(word, topn=5)
for l in top5:
temp_word_set.add(l[0])
word_set = temp_word_set | word_set
new_word_set.clear()
new_word_set = temp_word_set.copy()
temp_word_set.clear()
# print(word_set)
return word_set
def calculate_distance(book_a, book_b):
distances = set()
for tag_a in book_a:
avg_max_distance = 0
loop_times = 3
for temp in range(loop_times):
top_word = ""
max_distance = 0
top_word_set = set()
for tag_b in book_b:
if tag_b not in top_word_set:
try:
distance = wiki_model.wv.similarity(tag_a, tag_b)
if distance > max_distance:
max_distance = distance
top_word = tag_b
except KeyError:
continue
# print(tag_a + " " + tag_b + " distance: " + str(distance))
if max_distance != 0:
top_word_set.add(top_word)
avg_max_distance += max_distance
avg_max_distance /= loop_times
distances.add((tag_a, avg_max_distance))
distance_sum = 0
for distance in distances:
distance_sum += distance[1]
return distance_sum / len(distances)
if __name__ == '__main__':
models = os.listdir("书评\\word2vec\\model\\")
print("正在读取中文维基百科语料库word2vec模型…")
wiki_model = Word2Vec.load(
r"D:\zhwiki_model\word2vec_gensim") # type: Word2Vec
tags = list()
for model in models:
words = set()
with open("书评\\word2vec\\vocabulary\\vocabulary_" + model,
"r", encoding="utf-8")as vocabulary:
words.add(vocabulary.readline().split(" ")[0])
words.add(vocabulary.readline().split(" ")[0])
words.add(vocabulary.readline().split(" ")[0])
# print(words)
print("正在提取 %s 中的标签…" % model)
tag = extract_tag_set(model, words)
print("%s 中的标签为:" % model)
print(tag)
tags.append((model, tag))
print("{0:{space}<10}".format("", space=chr(12288)), end='')
for a in tags:
print("{0:{space}<15}".format(a[0], space=chr(12288)), end='')
print()
for a in tags:
print("{0:{space}<15}".format(a[0], space=chr(12288)), end='')
for b in tags:
# print("正在计算 %s 到 %s 的距离..." % (a[0], b[0]))
# print("%s to %s 距离为 %f" % (
# a[0], b[0], calculate_distance(a[1], b[1])))
print("%-20f" % calculate_distance(a[1], b[1]), end='')
print()
稍微解释一下,其中extract_tag方法是上一篇提到的,不予赘述。
……好像也没什么好解释的。摆结果分析结果吧。
测试与结论
计算的样本是1000条评论,书籍分别是三体、三体3、红楼梦以及一个无关书籍追风筝的人
期望:
三体与三体3的距离较近,三体与红楼梦的距离较远
以提取标签环节的 取高频词冷启动、迭代深度、迭代广度以及 计算标签-书距离4个维度 使用控制变量法 来实验,总结出参数的影响,使用试错法调节出最佳参数。
关键参数表
参考标准
|冷启动高频词前n|迭代深度|迭代广度|标签-书距离|
|-|||
|3|3|5|取最大值前3的平均值|
下列参数表均以参考标准表对照做比较
标签-书距离
|编号|冷启动高频词前n|迭代深度|迭代广度|标签-书距离|
|-||||
|1|3|3|5|取平均值|
|2|3|3|5|取最大值|
|3|3|3|5|取最大值前2的平均值|
|4|3|3|5|取最大值前5的平均值|
高频词
|编号|冷启动高频词前n|迭代深度|迭代广度|标签-书距离|
|-||||
|1|1|3|5|取最大值前3的平均值|
|2|2|3|5|取最大值前3的平均值|
|3|5|3|5|取最大值前3的平均值|
迭代深度
|编号|冷启动高频词前n|迭代深度|迭代广度|标签-书距离|
|-||||
|1|3|1|5|取最大值前3的平均值|
|2|3|2|5|取最大值前3的平均值|
|3|3|5|5|取最大值前3的平均值|
迭代广度
|编号|冷启动高频词前n|迭代深度|迭代广度|标签-书距离|
|-||||
|1|3|3|1|取最大值前3的平均值|
|2|3|3|3|取最大值前3的平均值|
|3|3|3|7|取最大值前3的平均值|
结果
先发出去吧,结果吃晚饭了跑
怠惰的我竟然又隔了一天才写……我背锅
强调一下,出于效率考虑,标签使用的是python的set数据结构,所以看起来输出的标签有所不同。实际上经测试,对同一本书而言,其余参数不变的情况下,标签是相同的。
结果根据上面的标准跑出各种结果如下:
参考标准结果
|冷启动高频词前n|迭代深度|迭代广度|标签-书距离|
|-|||
|3|3|5|取最大值前3的平均值|
正在读取中文维基百科语料库word2vec模型…
正在提取 model_seg_三体 中的标签…
model_seg_三体 中的标签为:
{'生死存亡', '挫败', '星人', '消除', '三者', '处境', '要义', '讽刺', '一瞬间', '忠诚', '顽强', '之中', '信徒', '第一次', '狂妄', '异常', '日子', '救赎', '相通', '说到底', '对此', '弱者', '困境', '集体', '中三体', '众生', '轻松', '开启', '本性', '代价', '注定', '无可', '光明', '外部', '行走', '演变', '统治', '揭开', '初衷', '和平共处', 'lt', '留恋', '或者说', '浮现', '了爱', '并未', '面纱', '跳出', '防卫', '慢', '忠实', '潜意识', '名', '逃避', '后半段', '从头到尾', '地方', '第一步', '款', '一遍', '伏笔', '刚刚', '派别', '好奇', '结尾', '起源', '截然不同', '稳藏', '挽救', '重复', '恶劣', '不算', '一员', '生态系统', '融合', '两本', '适宜', '异化', '路上', '试', '解脱', '蛮荒', '网游', '星期', '映射', '灭亡', '可谓', '一段时间', '美妙', '接触', '意志', '子孙', '处于', '争当', '终结', '初步', '降临到', '曙光', '逃过', '赤裸裸', '思绪', '更何况', '期盼', '三册', '一度', '主观', '艰难', '人类文明', '一幕', '外力', '张力', '精神领袖', '寻求', '隐隐约约', '前提', '一切都是', '产物', '探寻', '监督', '当做', '打开', '透露', '解答', '全局', '面前', '参透', '安全感', '淘汰', '推向', '第三本', '正义', '作出', '丧失', '关乎', '条件', '在精神上', '交代', '说起', '不利于', '守护者', '哭', '开端', '残忍', '慢慢', '改善', '开发', '暗示', '舒适', '一章', '终于', '不用说', '不可避免', '不禁', '覆灭', '一页', '书名', '奇异', '所有人', '现状', '变革', 'boss', '罪恶', 'high', '灿烂', '博弈', '招募', '厌恶', '引向', '尾', '出路', '插叙', '不值一提', '反抗', '世界末日', '介入', '住', '重如泰山', '守护', '未必', '知晓', '悟', '刷', '正式', 'gt', '对外', '最深', '共鸣', '登陆', '无关', '生死', '一口气', '一周', '萌芽', '第二本', '野蛮', '斗争', '灾难', '抑制', '稍微', '人权', '至极', '流浪', 'PS', '剿灭', '引子', '想着', '是否是', '珍贵', '困难', '堕落', '外来', '打算', '迫使', '融入', '宇宙空间', '详细', '2', '斥', '持续', '看待', '科学界', '后续', '相遇', '疑问', '状态', '移居', '短', '24.', '审视', '演化', '消亡', '引出', '民众', '一共', '相', '语', '愿望', '安德', '面对', '没想到', '几天', '分为', '终将', '里', '巧合', '悄然', '翻开', '4.', '怪物', '后果', '异类', '残酷', '揭晓', '搏杀', '悲惨', '寄希望于', '好奇心', '支配', '意识', '做法', '画卷', '推演', '拉开', '警方', '自相残杀', '审问者', '抱', '如饥似渴'}
正在提取 model_seg_三体Ⅲ 中的标签…
model_seg_三体Ⅲ 中的标签为:
{'生死存亡', '存亡', '庞大', '点睛之笔', '后记', '浩劫', '回顾', '数次', '领袖', '复杂性', '衰亡', '赶上', '气势', '媲美', '之中', '理由', '归还给', '赢得', '回应', '选择题', '旧', '简介', '功夫', '局面', '球', '狂妄', '深意', '忠于', '物竞天择', '愤怒', '怜悯', '救赎', '灭顶之灾', '直面', '当作', '新', '无垠', '超出', '弱者', '续集', '足以', '无能为力', '光亮', '催生出', '归宿', '中三体', '料到', '气势磅礴', '抵抗', '忽视', '举动', '刷新', '达成', '版本', '看不见', '和平共处', '总体', '至高无上', '拍成电影', '高潮迭起', '看成', '短视', '足够', '保卫战', '公斤', '回到', '渴望', '跳跃', '一款', '绝境', '战胜', '直至', '压力', '重生', '蝗虫', '刚刚', '初次', '尘埃', '倒计时', '繁衍', '挽救', '小儿科', '新生', '重启', '引来', '唏嘘', '还给', '微不足道', '无可救药', '求生', '奇迹', '抛弃', '瓜葛', '误读', '归于', '最为', '两本书', '灭亡', '防备', '接触', '已然', '五公斤', '一抹', '以求', '共同努力', '诞生', '高于', '想来', '初步', '希冀', '视为', '摆脱', '一二', '潘多拉', '远方', '权利', '领导者', '走到', '人类文明', '临时', '紧张', '失效', '寻求', '输给', '无边', '数量级', '预言', '一具', '热寂', '自取灭亡', '号召', '关乎', '完结', '亿万年', '归还', '死尸', '全宇宙', '送向', '意图', '冒失', '一页', '小事', '暗黑', '严锋', '诡谲', '俗套', '罪恶', '孕育', '不为过', '最让人', '轮回', '辛苦', '不复存在', '漂流瓶', '时刻', '定格', '反抗', '如果说', '恐慌', '证据', '疑点', '挣扎', '正式', '疏忽', '生死', '终点', '罪人', 'I', '消化', '鱼缸', '跨入', '看作', '众矢之的', '面临', '上看', '可知', '灾难', '死去', '平淡', '归零', '自大', '惊喜', '暗无天日', '浅', '应对', '超凡脱俗', '光锥', '跨', '序', '贴切', '大同', '已有', '后续', '生态', '一小', '启示', '浮云', '外形', '有害', '循环', '消亡', '贯穿', '惊讶', '怨恨', '显而易见', '数量', '招来', '长时间', '了前', '忘却', '盲目', '娓娓道来', '留在', '翻开', '这时候', '折磨', '沧海一粟', 'NB', '漫长', '灭绝', '临界值', '安利', '危难', '搏杀', '遭受', '寄希望于', '记录', '所处', '回归', '苟延残喘', '笼罩', '百年', '自信', '卑微', '定位', '自相残杀', '亿万', '抗争'}
正在提取 model_seg_红楼梦 中的标签…
model_seg_红楼梦 中的标签为:
{'终归', '后悔', '妨碍', '口里', '小性儿', '有没有', '闺阁', '说完', '书外', '儒林外史', '当初', '说道', '黛', '包容', '正册', '篇幅', '你好', '表白', '越发', '要紧', '矫情', '模仿', '出入', '由来', '邢岫烟', '生平', '不理', '抢', '心中', '不远', '列', '独独', '宝琴', '太多太多', '多行', '几十回', '那段', '册', '此话', '爱黛玉', '出彩', '可说', '穿插', '半天', '无处', '无可', '作诗', '婶子', '脸谱化', '没意思', '林姑娘', '册页', '图册', '不至', '并未', '差点', '中', '好好', '不信', '晚年', '貌似', '爱哭', '口气', '紫鹃', '第十三回', '成亲', '正面', '回去', '假寐', '留神', '无不', '这话', '回到', '绝妙', '暧昧', '真情', '隐晦', '象', '吃醋', '胡说', '聪明伶俐', '哭哭啼啼', '许', '坏', '问问', '一下子', '好歹', '尖酸刻薄', '学诗', '情敌', '听到', '臭男人', '着墨', '推', '周到', '吟诗', '联诗', '言语', '场面', '出口', '心目', '提示', '阿Q', '后期', '放心', '早知如此', '伴侣', '宝', '提醒', '咬', '心病', '猫', '多疑', '谜团', '体谅', '笔法', '着力', '一流', '细致', '站住', '晓得', '惋惜', '问道', '三次', '发现自己', '见到', '解答', '倒像', '混账', '十二支', '之口', '多早晚', '写到', '小气', '冤', '不明', '交代', '刻薄', '关切', '开端', '第二回', '生分', '第五回', '淋漓尽致', '瞧', '一名', '湘云', '第三十一回', '热闹', '醪曲', '大方', '围绕', '撒谎', '小性', '之时', '顺序', '听见', '奢华', '哭泣', '硬', '仅凭', '安慰', '亲密', '宝贝', '猜测', '黛玉', '要说', '虎狼', '雪雁', '取笑', '乱说', '可不是', '神秘', '在意', '通考', '仿佛', '怔', '难过', '后事', '一口气', '房中', '堵', '亲姐姐', '推之于', '打趣', '摔', '没人', '贴心', '十二钗', '玩笑话', '第三回', '极妙', '删掉', '褒贬', '厕所', '妹纸', '面貌', '回来', '真性情', '外', '玉宝钗', '反面', '留得', '曲笔', '感激', '走进', '小心眼', '计较', '不见得', '疑惑', '吵架', '提及', '冷笑', '心意', '心碎', '金锁', '细微', '曲折', '心爱', '好像', '说不出来', '和宝钗', '青梅竹马', '多处', '混帐', '颇为', '平空', '出场', '伤感', '哄', '走出', '里', '留在', '判曲', '寻觅', '懂事', '脑海中', '惜墨如金', '多半', '槛', '小人物', '心直口快', '夸', '俯拾皆是', '岔开', '和黛玉', '言情', '相爱', '敬重', '开心', '信息', '淘气', '剧中', '说错', '不该', '试探', '饱满', '说出', '宝钗', '传神', '谜', '柜', '点头'}
正在提取 model_seg_追风筝的人 中的标签…
model_seg_追风筝的人 中的标签为:
{'后记', '奴仆', '胜利', '参加', '哈桑', '风险', '佣人', '包容', '上书', '喉结', '冬日', '赢得', '米尔', '高手', '欺凌', '他家', '忠心', '人能', '捡', '一只', '无条件', '胜利者', '陪伴', '阿米尔', '荣耀', '翱翔', '忠实', '玩伴', '揍', '比赛', '那年', '人世', '无动于衷', '1975', '对手', '赢回', '领养', '理所当然', '放飞', '最出色', '亲生', '直视', '情同手足', '头发', '追到', '停止', '天空', '不肯', '奉献', '动摇', '但他却', '玻璃', '阿桑', '无怨无悔', '骗子', '抚养', '当做', '出头', '相仿', '冬天', '掠起', '宠爱', '飞翔', '亲人', '惨死', '伤', '奋力', '遇上', '隐忍', '天上', '手足', '长长的', '亲密', '坏孩子', '学会', '竟是', '灿烂', '侵犯', '亲', '弟弟', '亲密无间', '守护', '羞辱', '占有', '冠军', '命中注定', '线', '情同', '捍卫', '死去', '维护', '上前', '求', '追回', '深爱', '离去', '坠落', '一同', '斗', '毫无保留', '关爱', '合', '久久', '疼爱', '蠕动', '打败', '阿赛夫', '忠心耿耿', '挺身', '兼', '怨恨', '激怒', '至死', '塞尔', '服侍', '空中', '亲兄弟', '大赛', '伙伴', '无私', '飞', '吞咽', '落地', '哈森', '祝你好运', '掉落', '冷淡', '不顾', '爱和', '追', '逆来顺受', '割断', '好受'}
model_seg_三体 model_seg_三体Ⅲ model_seg_红楼梦 model_seg_追风筝的人
model_seg_三体 0.641413 0.444835 0.384929 0.354435
model_seg_三体Ⅲ 0.451066 0.632567 0.373845 0.361493
model_seg_红楼梦 0.410419 0.398263 0.635157 0.369873
model_seg_追风筝的人0.415998 0.421336 0.416097 0.647488
标签-书距离
- 取平均值
正在读取中文维基百科语料库word2vec模型…
正在提取 model_seg_三体 中的标签…
model_seg_三体 中的标签为:
{'萌芽', '日子', '消除', '尾', '从头到尾', '当做', '前提', '众生', '一口气', '三册', '安德', '防卫', '适宜', '生死', '对外', '结尾', '巧合', '慢', '厌恶', '一页', '寻求', '罪恶', '监督', '终结', '异化', '信徒', '好奇', '探寻', '顽强', '后果', '消亡', '伏笔', '灭亡', '融入', '移居', '之中', '住', '演化', '至极', '持续', '引子', '稍微', '书名', '人类文明', '光明', '疑问', '自相残杀', '外部', '世界末日', '赤裸裸', '灾难', '丧失', '舒适', '逃避', '一度', '起源', '了爱', '地方', '愿望', '一遍', '2', '映射', '美妙', '一共', '意志', '星期', '打算', '现状', '怪物', '奇异', '后半段', '审问者', '想着', '反抗', '刷', '重如泰山', 'boss', '关乎', '未必', '网游', '斥', '刚刚', '初步', '外力', '拉开', '几天', '面纱', 'PS', '期盼', '登陆', '悄然', '星人', '4.', '搏杀', '和平共处', '中三体', '交代', '后续', '不值一提', '24.', '留恋', '思绪', '第二本', '说起', '详细', '三者', '或者说', '透露', '一切都是', '轻松', '蛮荒', '潜意识', '宇宙空间', '灿烂', '一幕', '解脱', '一章', '淘汰', '救赎', '相遇', '款', '两本', '分为', '接触', '条件', '本性', '跳出', '不算', '行走', '寄希望于', '改善', '一段时间', '短', '不利于', '引出', '代价', '哭', '面前', '困难', '挫败', '名', '招募', '争当', '不用说', '在精神上', '忠诚', '不禁', 'high', '无关', '知晓', '处于', '曙光', '流浪', '困境', '意识', '第一步', '作出', '介入', '终将', '试', '开端', '子孙', '统治', '抱', '演变', '揭晓', '第三本', '更何况', '看待', '守护者', '野蛮', '逃过', '对此', '并未', '重复', '斗争', '全局', '慢慢', '产物', '如饥似渴', '做法', '状态', '挽救', '解答', '生死存亡', '安全感', '正义', '打开', '审视', '悲惨', '狂妄', '共鸣', '异类', '不可避免', '张力', '一员', '暗示', '堕落', '引向', '残忍', '剿灭', '是否是', '迫使', '讽刺', '变革', '融合', '悟', '里', '博弈', '珍贵', '艰难', '浮现', '集体', '忠实', '一瞬间', '推向', '处境', '终于', 'gt', '可谓', '截然不同', '主观', '开启', '推演', '揭开', '面对', '降临到', '恶劣', '覆灭', '抑制', '守护', '残酷', '外来', '所有人', '第一次', '生态系统', '隐隐约约', '派别', '要义', '路上', '弱者', '插叙', '无可', '正式', '画卷', '科学界', '出路', '稳藏', '说到底', '最深', '参透', '注定', '没想到', '支配', '好奇心', '开发', '翻开', '语', '相', 'lt', '相通', '人权', '民众', '初衷', '异常', '一周', '精神领袖', '警方'}
正在提取 model_seg_三体Ⅲ 中的标签…
model_seg_三体Ⅲ 中的标签为:
{'完结', '以求', '后记', '倒计时', '灭顶之灾', '罪人', 'I', '局面', '所处', '亿万年', '忠于', '生死', '求生', '惊讶', '数量', '旧', '高潮迭起', '一二', '盲目', '一页', '领导者', '怨恨', '寻求', '罪恶', '孕育', '笼罩', '存亡', '诞生', '一具', '有害', '引来', '热寂', '防备', '一款', '消亡', '诡谲', '看成', '灭亡', '漂流瓶', '权利', '临时', '无垠', '之中', '刷新', '一小', '光亮', '人类文明', '自相残杀', '繁衍', '最为', '衰亡', '物竞天择', '定位', '自大', '微不足道', '光锥', '显而易见', '苟延残喘', '灾难', '奇迹', '贴切', '一抹', '当作', '点睛之笔', '抛弃', '失效', '初次', '无可救药', '长时间', '自信', '可知', '续集', '尘埃', '绝境', '自取灭亡', '拍成电影', '危难', '回归', '高于', '领袖', '已有', '反抗', '深意', '消化', '大同', '关乎', '简介', '浅', '浩劫', '初步', '刚刚', '应对', '辛苦', '轮回', '死尸', '数次', '疑点', '希冀', '搏杀', '和平共处', '足以', '中三体', '瓜葛', '忘却', '共同努力', '疏忽', '后续', '百年', '回应', '全宇宙', '看不见', '跳跃', '超凡脱俗', '想来', '意图', '看作', '记录', '不复存在', '忽视', '救赎', '接触', '寄希望于', '催生出', '跨', '重生', '赶上', '冒失', '惊喜', '走到', '归宿', '保卫战', '气势磅礴', '紧张', '遭受', '潘多拉', '鱼缸', '庞大', '预言', '送向', '娓娓道来', '误读', '公斤', '料到', '沧海一粟', '折磨', '输给', '怜悯', '平淡', '球', '理由', '版本', '足够', '摆脱', '已然', '最让人', '恐慌', '愤怒', '举动', '定格', '归还', '视为', '严锋', '功夫', '短视', '五公斤', '数量级', '气势', '浮云', '如果说', '灭绝', '挽救', '生态', '无边', '生死存亡', '亿万', '还给', '贯穿', '临界值', '号召', '死去', '归还给', '狂妄', '两本书', '卑微', '循环', '直至', '达成', '抵抗', '上看', '漫长', '抗争', '留在', '序', '暗无天日', '至高无上', '暗黑', '小事', '终点', '众矢之的', '挣扎', '启示', '小儿科', '证据', '归零', '无能为力', '归于', '回顾', '新', '渴望', '超出', '面临', '直面', '招来', '媲美', '赢得', '时刻', '重启', '选择题', '安利', '弱者', '新生', '正式', '不为过', 'NB', '唏嘘', '回到', '总体', '跨入', '蝗虫', '压力', '远方', '翻开', '战胜', '复杂性', '这时候', '了前', '外形', '俗套'}
正在提取 model_seg_红楼梦 中的标签…
model_seg_红楼梦 中的标签为:
{'反面', '体谅', '后悔', '寻觅', '柜', '宝贝', '面貌', '一名', '胡说', '一口气', '多早晚', '由来', '站住', '虎狼', '岔开', '妨碍', '真情', '作诗', '几十回', '小心眼', '早知如此', '传神', '不见得', '阿Q', '模仿', '放心', '绝妙', '终归', '不该', '俯拾皆是', '醪曲', '仿佛', '中', '象', '周到', '冷笑', '说错', '走出', '难过', '吃醋', '回来', '情敌', '吵架', '堵', '书外', '推', '生平', '留神', '在意', '林姑娘', '曲折', '槛', '伤感', '差点', '心病', '提及', '那段', '多处', '发现自己', '留得', '篇幅', '信息', '半天', '惜墨如金', '儒林外史', '谜团', '小性', '判曲', '后事', '十二支', '推之于', '你好', '紫鹃', '臭男人', '谜', '没意思', '坏', '心碎', '貌似', '玉宝钗', '饱满', '多疑', '和黛玉', '曲笔', '撒谎', '之口', '抢', '说完', '混账', '好像', '十二钗', '惋惜', '心爱', '交代', '多半', '写到', '亲密', '言情', '闺阁', '咬', '宝', '相爱', '吟诗', '仅凭', '联诗', '试探', '褒贬', '一下子', '剧中', '黛', '言语', '雪雁', '问道', '围绕', '见到', '可不是', '问问', '不理', '当初', '通考', '敬重', '听到', '正面', '极妙', '场面', '哄', '第三回', '哭哭啼啼', '真性情', '三次', '宝琴', '册页', '越发', '着力', '爱黛玉', '奢华', '晓得', '细致', '尖酸刻薄', '关切', '猜测', '金锁', '和宝钗', '删掉', '黛玉', '开心', '淋漓尽致', '隐晦', '此话', '晚年', '成亲', '婶子', '册', '平空', '这话', '心意', '开端', '出场', '说不出来', '有没有', '包容', '出口', '小人物', '图册', '聪明伶俐', '着墨', '猫', '刻薄', '贴心', '出入', '并未', '后期', '邢岫烟', '疑惑', '小气', '不信', '房中', '口气', '神秘', '矫情', '不至', '摔', '解答', '学诗', '不明', '笔法', '外', '假寐', '好歹', '计较', '脑海中', '倒像', '感激', '硬', '宝钗', '爱哭', '顺序', '打趣', '一流', '安慰', '回去', '无不', '提醒', '留在', '热闹', '不远', '生分', '混帐', '淘气', '里', '许', '走进', '玩笑话', '没人', '好好', '夸', '列', '提示', '独独', '多行', '懂事', '出彩', '穿插', '第十三回', '颇为', '可说', '哭泣', '说道', '妹纸', '取笑', '怔', '脸谱化', '小性儿', '点头', '乱说', '心直口快', '青梅竹马', '第二回', '冤', '无可', '心目', '第三十一回', '说出', '回到', '之时', '伴侣', '正册', '要紧', '表白', '心中', '瞧', '第五回', '无处', '暧昧', '要说', '太多太多', '厕所', '听见', '大方', '细微', '口里', '亲姐姐', '湘云'}
正在提取 model_seg_追风筝的人 中的标签…
model_seg_追风筝的人 中的标签为:
{'伙伴', '坠落', '离去', '后记', '亲兄弟', '当做', '掠起', '弟弟', '无条件', '参加', '怨恨', '骗子', '久久', '追', '捍卫', '亲人', '理所当然', '亲生', '追到', '飞翔', '相仿', '天上', '他家', '斗', '玻璃', '荣耀', '情同手足', '激怒', '冠军', '毫无保留', '哈森', '奋力', '出头', '阿桑', '服侍', '长长的', '赢回', '冬天', '人世', '亲密无间', '情同', '好受', '无私', '蠕动', '无动于衷', '米尔', '飞', '捡', '那年', '亲密', '比赛', '欺凌', '逆来顺受', '吞咽', '冷淡', '灿烂', '天空', '抚养', '陪伴', '祝你好运', '兼', '人能', '胜利者', '掉落', '至死', '忠心耿耿', '忠心', '坏孩子', '挺身', '深爱', '上前', '塞尔', '领养', '线', '学会', '羞辱', '最出色', '揍', '空中', '包容', '阿赛夫', '直视', '宠爱', '对手', '无怨无悔', '关爱', '哈桑', '惨死', '手足', '不顾', '一只', '爱和', '喉结', '死去', '隐忍', '占有', '胜利', '风险', '大赛', '一同', '佣人', '不肯', '疼爱', '上书', '合', '伤', '忠实', '打败', '奉献', '维护', '竟是', '阿米尔', '动摇', '停止', '守护', '落地', '追回', '高手', '冬日', '玩伴', '放飞', '赢得', '遇上', '奴仆', '亲', '头发', '割断', '翱翔', '求', '侵犯', '命中注定', '但他却', '1975'}
model_seg_三体 model_seg_三体Ⅲ model_seg_红楼梦 model_seg_追风筝的人
model_seg_三体 0.088230 0.079731 0.074904 0.068008
model_seg_三体Ⅲ 0.079731 0.079169 0.071153 0.067319
model_seg_红楼梦 0.074904 0.071153 0.151354 0.103012
model_seg_追风筝的人0.068008 0.067319 0.103012 0.121055
- 取最大值
正在读取中文维基百科语料库word2vec模型…
正在提取 model_seg_三体 中的标签…
model_seg_三体 中的标签为:
{
'对外', '忠实', '一度', '共鸣', 'gt', '巧合', '打算', '解脱', '想着', '一员', '悲惨', '逃过', '拉开', '星人', '和平共处', '生死', '审视', '挫败', '信徒', '留恋', '潜意识', '覆灭', '派别', '曙光', '人权', '罪恶', '变革', '详细', '状态', '4.', '引子', '不值一提', '异常', '科学界', '疑问', '所有人', '好奇心', '一幕', '引向', '三册', '赤裸裸', '愿望', '出路', '灿烂', '说起', '外部', '作出', '顽强', '对此', '悄然', '不可避免', '挽救', '适宜', '2', '映射', '博弈', '未必', '子孙', '之中', '注定', '不利于', '跳出', '无可', '第一次', '最深', '争当', '一章', '搏杀', '说到底', '救赎', '期盼', '两本', '揭晓', '不算', '光明', '讽刺', '演化', '要义', '相通', '张力', '不用说', '揭开', '开启', '当做', '灭亡', '哭', '众生', '世界末日', '暗示', '一遍', '好奇', '书名', '三者', '外来', '参透', '厌恶', '第一步', '狂妄', '异化', '第三本', '面纱', '插叙', '舒适', '更何况', '一页', '登陆', '轻松', '演变', '困境', '现状', '后半段', '防卫', '初衷', '残忍', '迫使', '统治', '生态系统', '终于', '意识', '正式', '语', '开发', '解答', '消亡', '后续', '民众', '人类文明', '反抗', '野蛮', '精神领袖', '结尾', '透露', '集体', '前提', '思绪', '招募', '丧失', '相', '尾', '意志', '监督', '守护', '改善', '融合', '里', '星期', '慢', '一共', '恶劣', '网游', '后果', '奇异', '打开', '开端', '路上', '24.', '伏笔', '融入', '探寻', '困难', '斥', '本性', '刷', '持续', '宇宙空间', '知晓', '产物', '灾难', '交代', '淘汰', '推演', '或者说', '残酷', '款', '推向', '全局', 'high', '萌芽', '安全感', '异类' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1461
1461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









