







 本文介绍了编程新手如何运用Gabor滤波器进行掌纹特征提取和相似度比较。通过创建虚拟环境,配置Python与OpenCV,实现掌纹图像的预处理,提取象限特征,并利用汉明距离计算相似度。文中提供了详细的步骤和代码示例。
本文介绍了编程新手如何运用Gabor滤波器进行掌纹特征提取和相似度比较。通过创建虚拟环境,配置Python与OpenCV,实现掌纹图像的预处理,提取象限特征,并利用汉明距离计算相似度。文中提供了详细的步骤和代码示例。
先来写付费专栏的第一个项目吧。
在说这个题目之前,先说一下这个项目的总体思路,如下所示。
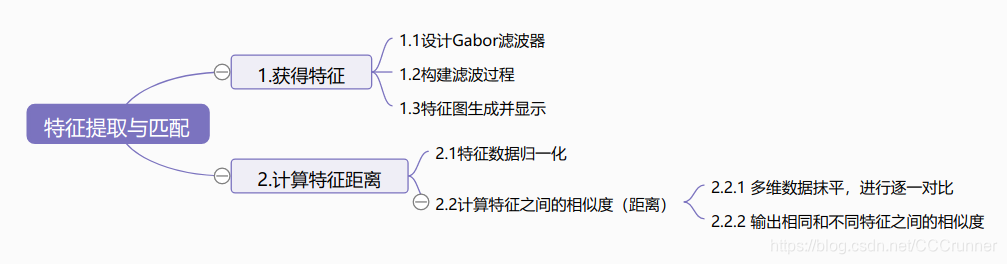
我们的目的是遇到问题,解决问题。
- 那么首先我们看一下我们的问题是什么吧?( 发 现 问 题 \color{green}发现问题 发现问题)
利用Gabor象限特征实现掌纹识别,从网上找到Gabor变换代码,进行象限特征提取和掌纹匹配(分别计算同一个掌纹和不同掌纹的相似度)
-
拿到这个问题,我们首先抓住文章的关键词,
我找到的关键词如下:( 分 析 问 题 \color{green}分析问题 分析问题)
G a b o r , 象 限 特 征 掌 纹 , 识 别 象 限 特 征 提 取 , 掌 纹 匹 配 \color{red}{Gabor,象限特征}\color{pink}{掌纹,识别}\color{blue}{象限特征提取,掌纹匹配} Gabor,象限特征掌纹,识别象限特征提取,掌纹匹配 -
接下来呢,我们理清一下思路:( 提 取 / 总 结 问 题 \color{green}提取/总结问题 提取/总结问题)
题目的要求就是1.进行特征提取,2.将提取的特征进行匹配,查看相似度 -
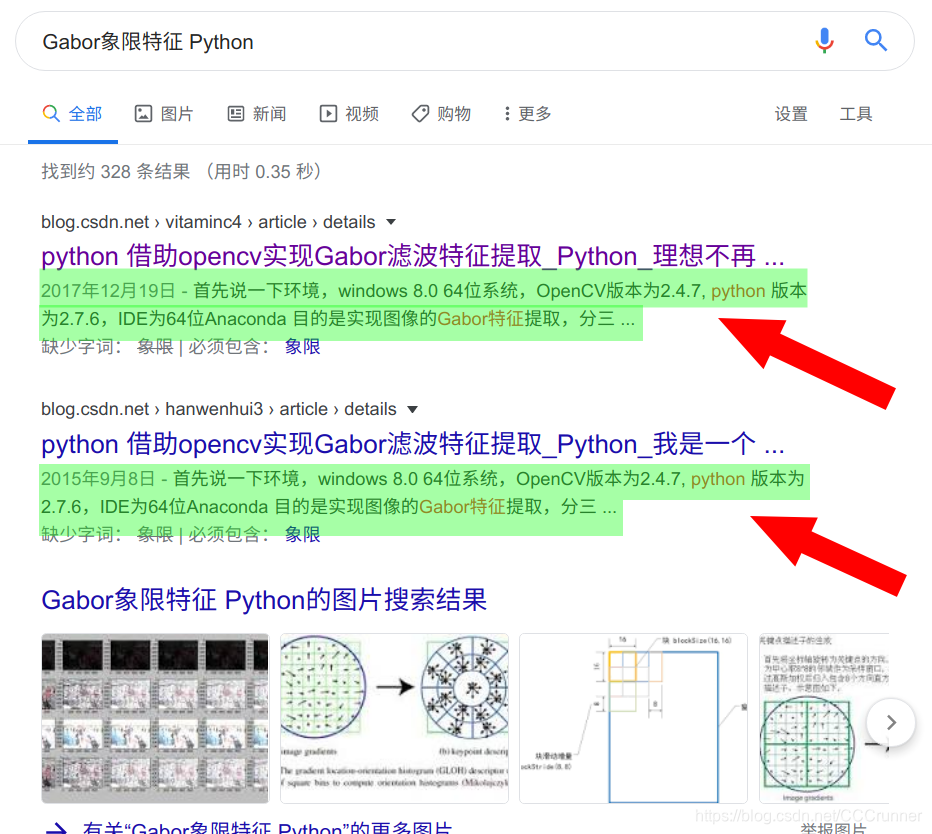
然后呢,我们就要借助搜索引擎了,现在的所有引擎就是基于
关键词搜索,我们可以提炼一下关键词,比如 G a b o r 象 限 特 征 \color{red}{Gabor象限特征 } Gabor象限特征 P y t h o n \color{red}{Python} Python,关键词之间要加空格。第一个关键词Gabor象限特征是要查找的代码类型,第二个关键词Python是说明要用什么代码实现,具体操作如下图所示。

-
除了标题之外,查看文章摘要,来了解文章是否是自己需要的。
-
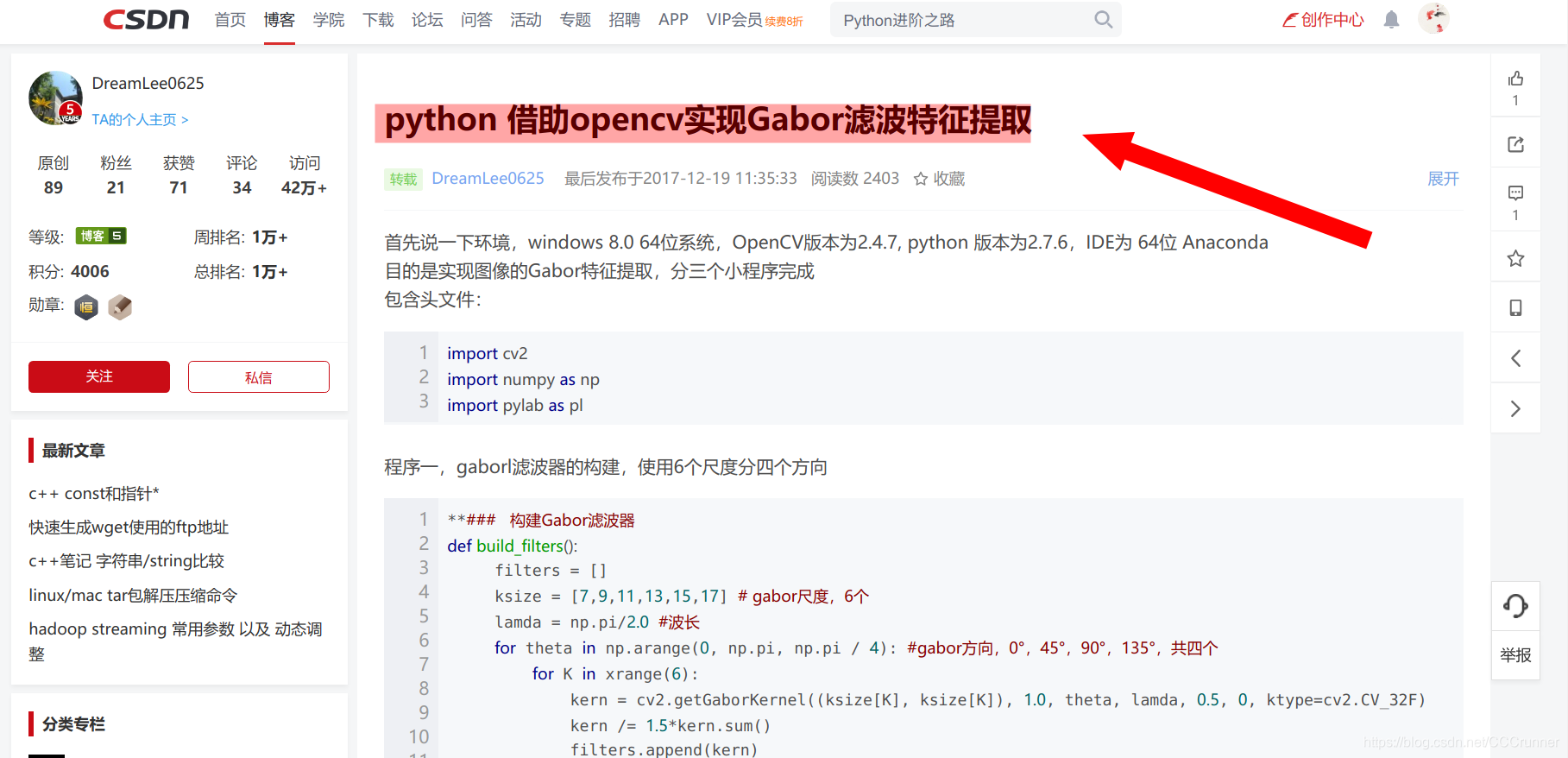
然后我们就点一下符合我们要求的文章,详细查阅。这里我们先点开第一个文章看一下。通过题目感觉到跟我们的题目要求比较吻合。我们再往下细看。
-
他首先说了一下他的运行环境,如下图

而我的运行环境是Ubuntu18.04TLS,默认Python版本是3.74,没关系,我们可以在Terminal中创建一个虚拟环境,命令格式conda create -n xxx python=3.6,xxx为环境名。具体操作如下图。因为我们看到的博客上面说的需要的python2的环境,所以我的创建命令行语句是conda create -n gabor python==2.7.4,效果如下图所示。( 可 以 不 用 指 定 的 环 境 , 比 如 p y t h o n 2 你 可 以 用 p y t h o n 3 代 替 , 只 需 要 把 对 应 的 p y t h o n 2 代 码 换 成 p y t h o n 3 就 可 以 \color{red}{可以不用指定的环境,比如python2你可以用python3代替,只需要把对应的python2代码换成python3就可以} 可以不用指定的环境,比如python2你可以用python3代替,只需要把对应的python2代码换成python3就可以)
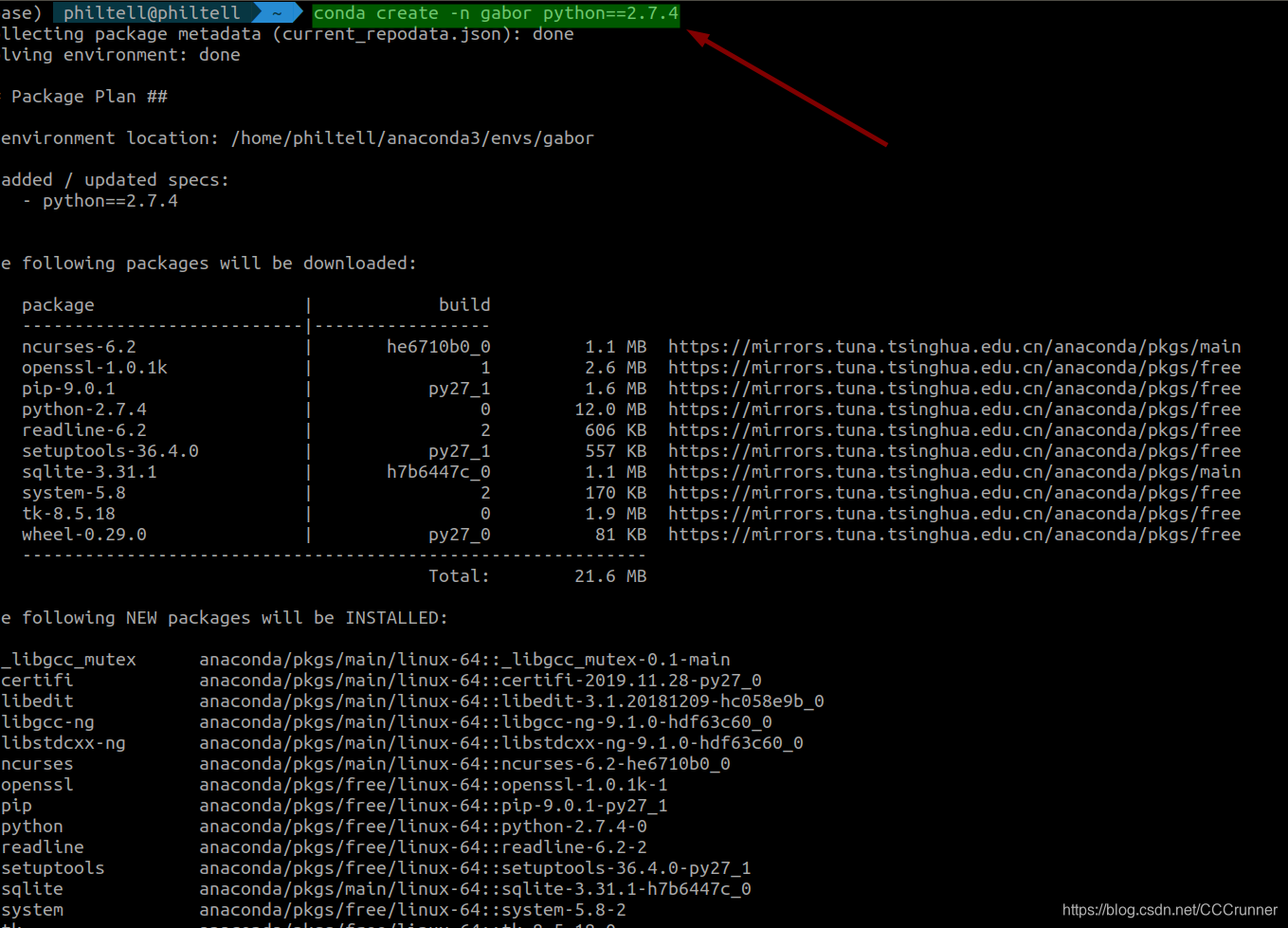
出现如下字样,说明配置环境成功
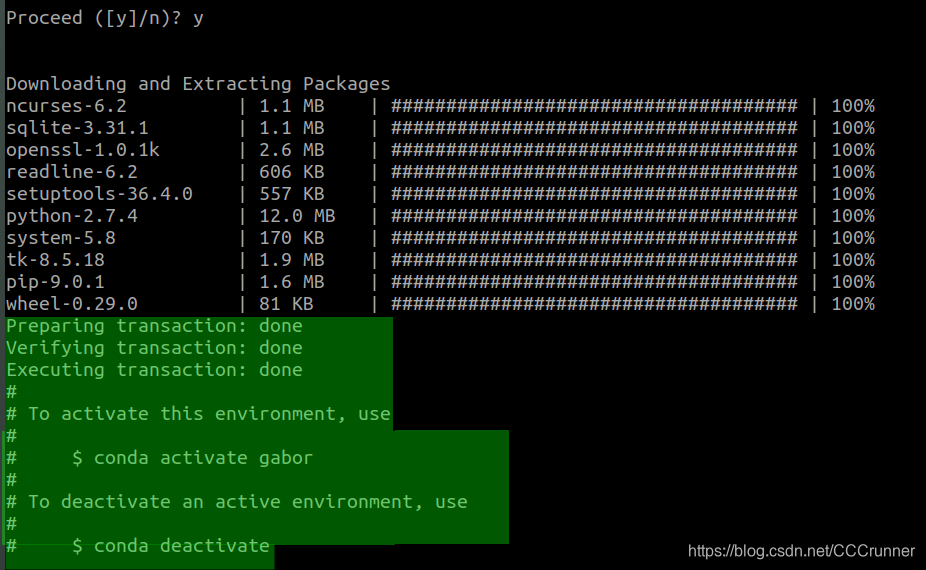
-
进一步的,我们需要进入环境,命令为
conda activate xxx,xxx为环境名称,这里我们是刚才创建的gabor

可以看到绿色部分表示环境已经从base变成gabor了。红色部分则是激活环境的实际代码。
接下来继续配置环境,OpenCV版本为2.4.7,在gabor环境下输入命令行为pip install opencv-python
然后我们就开始书写我们的代码
第一步引入库函数
import cv2 #导入opencv函数库
import numpy as np #引入提供维度数据与矩阵运算的,支持数组运算的数学函数库numpy
import pylab as pl #引入pylab,即可以画图又可以计算,可以交互使用
- 在Ubuntu下在指定的虚拟环境中用Pycharm创建一个py文件,如果不会在在虚拟环境中创建文件,请参考链接,例如
gabor.py,在文件中添加函数库引入。如下图所示。
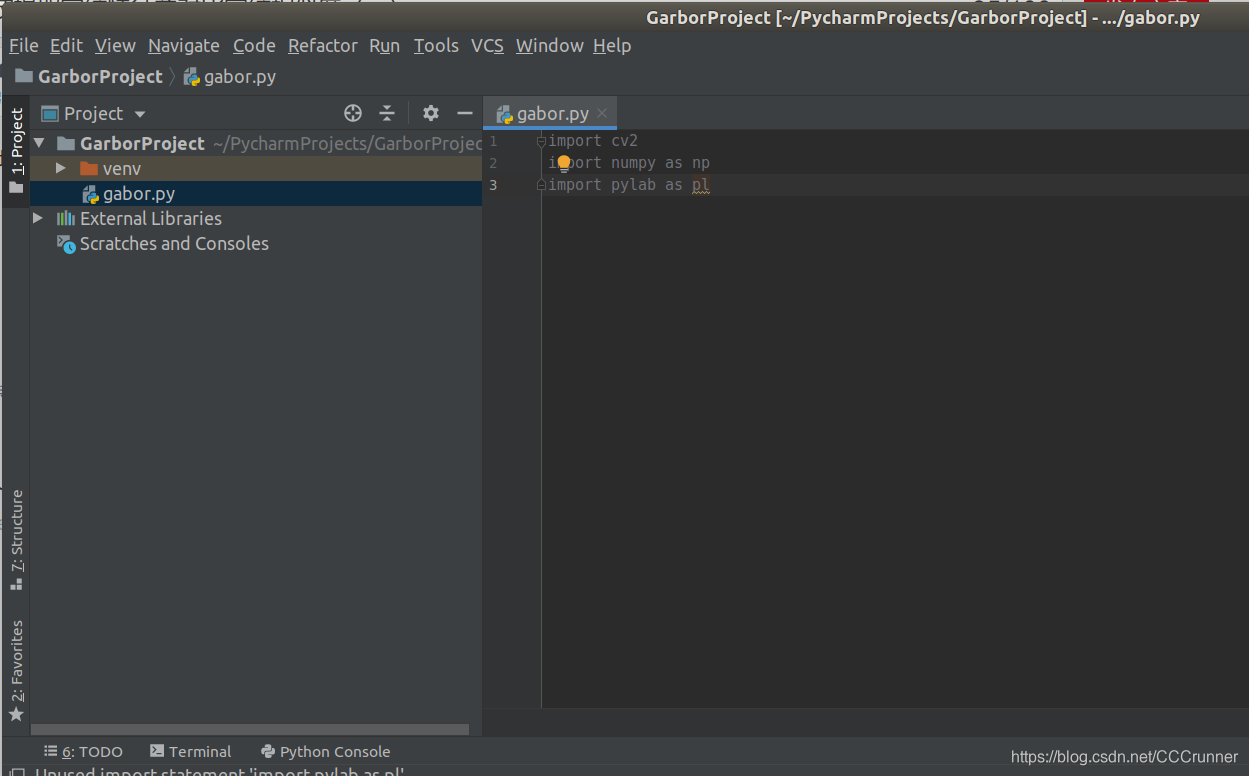
编译器没有报错,说明导入函数库成功。 - 构建Gabor滤波器
import cv2
import numpy as np
import pylab as pl
def build_filters():
filters = []
ksize = [7,9,11,13,15,17] #gabor尺度,6个
lamda = np.pi/2.0 #波长
for theta in np.arange(0,np.pi,np.pi / 4): #gabor方向,0 45,90,135共四个
for K in range(6):
kern = cv2.getGaborKernel((ksize[K],ksize[K]),1.0,theta,lamda,0.5,0,ktype=cv2.CV_32F)
kern /= 1.5*kern.sum()
filters.append(kern)
return filters
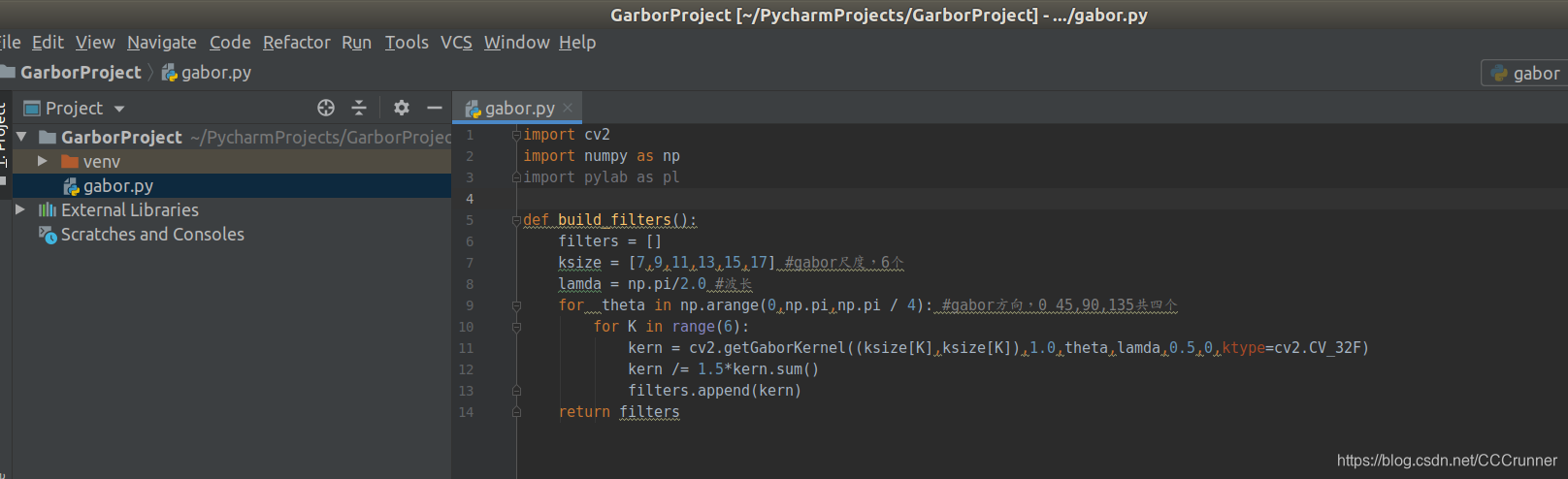
11. 创建滤波过程
def process(img,filters):
accum = np.zeros_like(img)
for kern in filters:
fimg = cv2.filter2D(img,cv2.CV_8UC3,kern)
np.maximum(accum,fimg,accum)
return accum
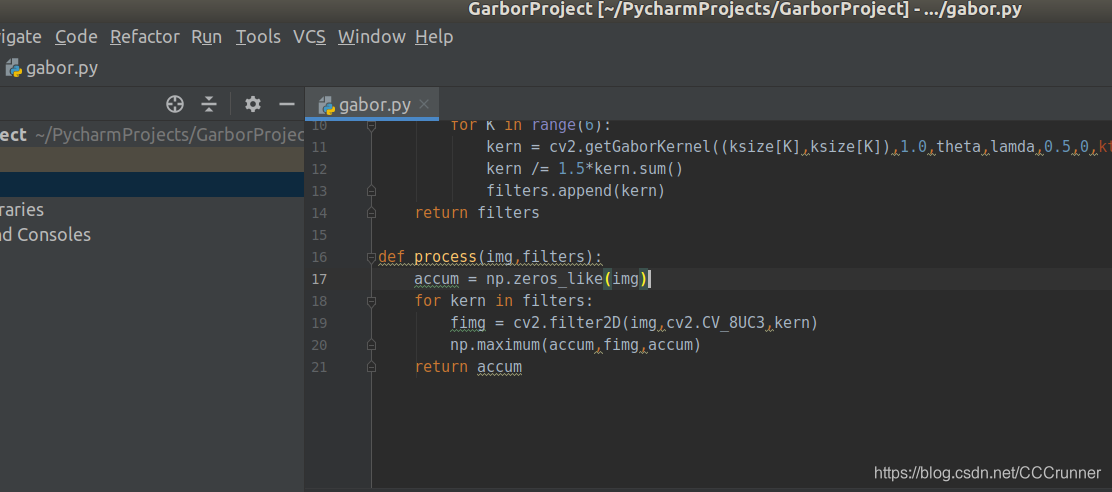
12. 特征图提取并显示
#Gabor特征提取
def getGabor(img,filters):
res = [] #滤波结果
for i in range(len(filters)):
res1 = process(img,filters[i])
res.append(np.asarray(res1))
pl.figure(2)
for temp in range(len(res)):
pl.subplot(4,6,temp+1)
pl.imshow(res[temp],cmap='gray')
pl.show()
return res
- 然后再加入我写的图片读入函数,就可以获得图片效果了。
if __name__ == '__main__':
path = "/home/philtell/Downloads/bmp600" # 待读取的文件夹
path_list = os.listdir(path)
path_list.sort() # 对读取的路径进行排序
filters = build_filters()
for filename in path_list[-1:]:
print(filename)
img_path = os.path.join(path, filename)
image = cv2.imread(img_path)
getGabor(image, filters)
原图如下:

效果图如下:
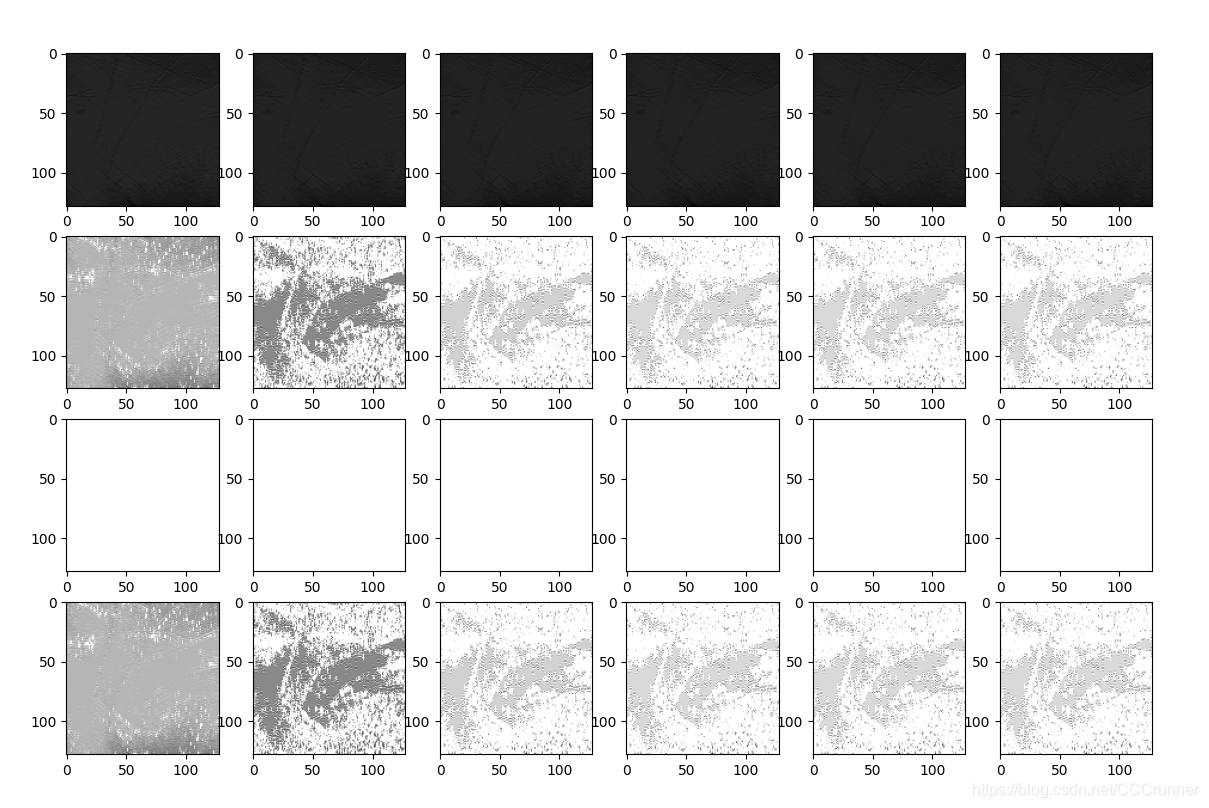
再找一张原图:
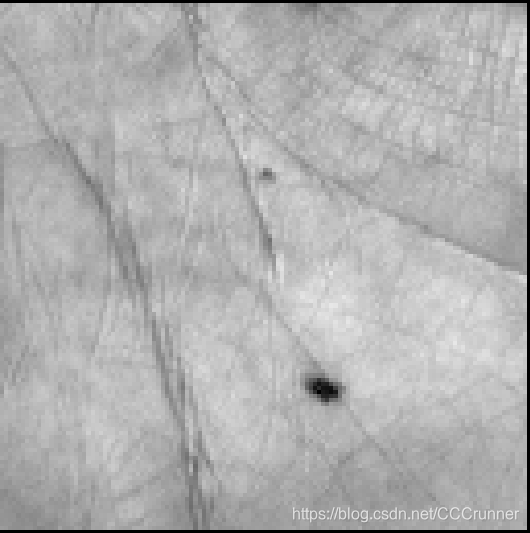
特征效果如下图
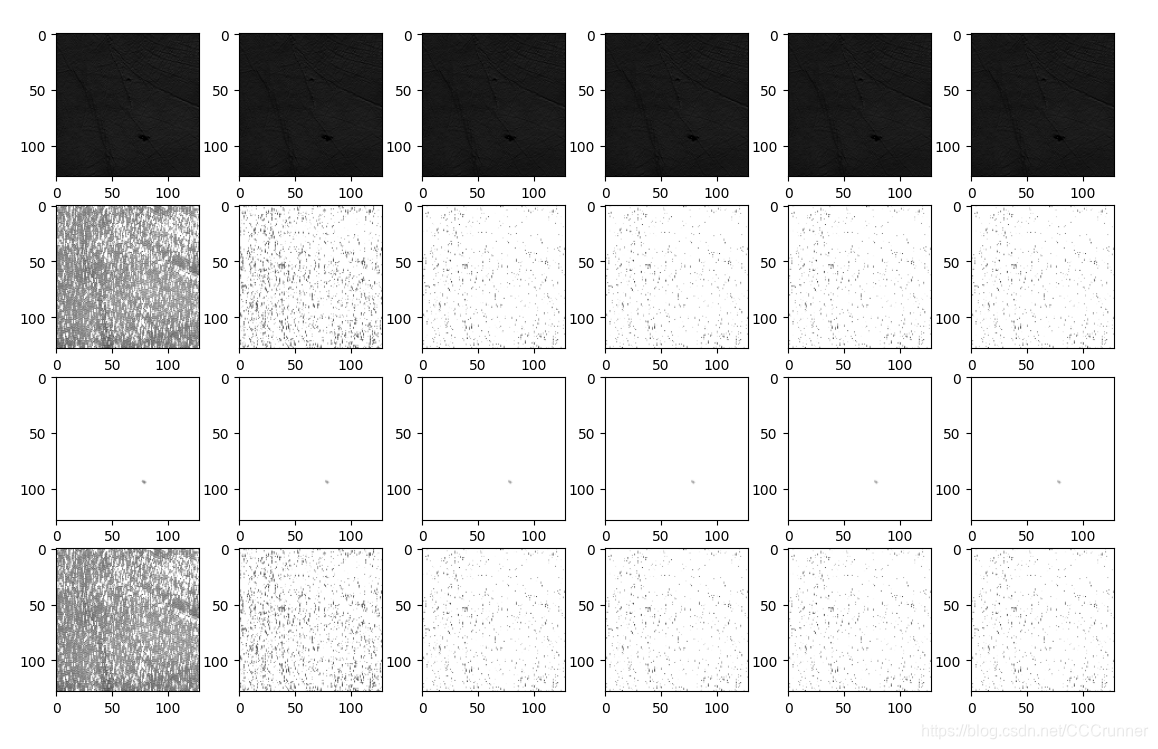
下来就来对提取的特征进行匹配,
- 先对提取的特征进行标准化,我们写一下标准化函数,主要是每一个元素除以最大的元素
#数据归一化
def normalization(data):
return data / np.max(abs(data))
- 计算特征之间的相似度,也就是汉明距离
def getSimilarityDistance(feature1,feature2):
diff = 0
x1 = np.array(feature1).flatten() #将特征抹平,多维矩阵变成一维数组,逐个对比,计算相似度
x2 = np.array(feature2).flatten()
for bit1,bit2 in zip(x1,x2):
if bit1 != bit2:
diff += 1
print(diff)
similarity = 1 - diff/len(x1)
print('相似度',similarity)
diff = 0
print(len(x1))
for bit1,bit2 in zip(x1,x1):
if bit1 != bit2:
diff += 1
print(diff)
similarity = 1 - diff/len(x1)
print(diff)
similarity = 1 - diff/len(x1)
print('相似度',similarity)
- 主函数为:
if __name__ == '__main__':
path = "/home/philtell/Downloads/bmp600" # 待读取的文件夹
filters = build_filters() #构建滤波器
img_path = os.path.join(path, '061_5.bmp') #获得图片地址
img_path2 = os.path.join(path, '062_5.bmp')
image = cv2.imread(img_path) #将图片转化为多维数组
image2 = cv2.imread(img_path2)
result = getGabor(image, filters)
result2 = getGabor(image2, filters)
features = normalization(np.array(result)) #归一化图片特征
features2 = normalization(np.array(result2))
getSimilarityDistance(features,features2) #计算不同图片和相同图片之间相似度
效果如下:
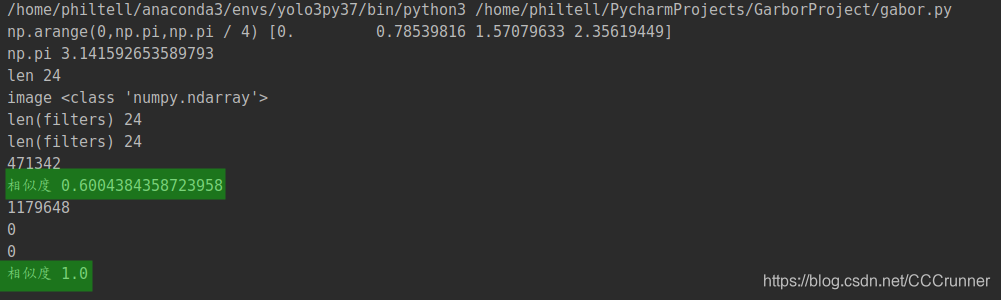
不同图片相似度为 0.60,相同图片相似度为1.0
最后将全部代码上传:
import cv2
import numpy as np
import pylab as pl
import os
def build_filters():
filters = []
ksize = [7,9,11,13,15,17] #gabor尺度,6个
lamda = np.pi/2.0 #波长
for theta in np.arange(0,np.pi,np.pi / 4): #gabor方向,0 45,90,135共四个
for K in range(6):
kern = cv2.getGaborKernel((ksize[K],ksize[K]),1.0,theta,lamda,0.5,0,ktype=cv2.CV_32F)
kern /= 1.5*kern.sum()
filters.append(kern)
print("np.arange(0,np.pi,np.pi / 4)",np.arange(0,np.pi,np.pi / 4))
print("np.pi",np.pi)
print("len",len(filters))
return filters
def process(img,filters):
accum = np.zeros_like(img)
for kern in filters:
fimg = cv2.filter2D(img,cv2.CV_8UC3,kern)
np.maximum(accum,fimg,accum)
return accum
#Gabor特征提取
def getGabor(img,filters):
print('len(filters)',len(filters))
res = [] #滤波结果
for i in range(len(filters)):
res1 = process(img,filters[i])
res.append(np.asarray(res1))
pl.figure(2)
for temp in range(len(res)):
pl.subplot(4,6,temp+1)
pl.imshow(res[temp],cmap='gray')
pl.show()
return res
#数据归一化
def normalization(data):
return data / np.max(abs(data))
def getSimilarityDistance(feature1,feature2):
diff = 0
x1 = np.array(feature1).flatten() #将特征抹平,多维矩阵变成一维数组,逐个对比,计算相似度
x2 = np.array(feature2).flatten()
for bit1,bit2 in zip(x1,x2):
if bit1 != bit2:
diff += 1
print(diff)
similarity = 1 - diff/len(x1)
print('相似度',similarity)
diff = 0
print(len(x1))
for bit1,bit2 in zip(x1,x1):
if bit1 != bit2:
diff += 1
print(diff)
similarity = 1 - diff/len(x1)
print(diff)
similarity = 1 - diff/len(x1)
print('相似度',similarity)
if __name__ == '__main__':
path = "/home/philtell/Downloads/bmp600" # 待读取的文件夹
path_list = os.listdir(path)
path_list.sort() # 对读取的路径进行排序
filters = build_filters()
img_path = os.path.join(path, '061_5.bmp')
img_path2 = os.path.join(path, '062_5.bmp')
image = cv2.imread(img_path)
image2 = cv2.imread(img_path2)
print('image',type(image))
result = getGabor(image, filters)
result2 = getGabor(image2, filters)
features = normalization(np.array(result))
features2 = normalization(np.array(result2))
getSimilarityDistance(features,features2)
如果你能看到我这句话,那么说明你是订阅了专栏,感谢你的订阅~


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











