







1、实验名称
Numpy 实现全连接神经网络实验指南
2、实验要求
- 用 python 的 numpy 模块实现全连接神经网络。
- 网络结构为一个输入层、一个隐藏层、一个输出层。
- 隐藏层的激活函数为 Relu 函数。
- 输出层的激活函数为 softmax 函数。
- 损失函数为交叉熵。
3、实验目的
学习如何使用 Numpy 实现一个只有一个输入层、一个中间层和一个输出层全连接神经网络,并利用它来处理一个简单的分类任务,即识别手写数字,通过实践来加深对神经网络内部机制的理解。
4、实验过程
4.1 操作过程
- 创建虚拟环境
在终端中输入conda create −n <你想起的虚拟环境的名字> python =3.7
- 初始化虚拟环境
输入 conda init

- 进入环境
关闭终端,然后重新打开终端,输入conda activate <你刚才起的那个虚拟环境的名字>
- 安装tensorflow
输入 conda isntall tensorflow-gpu=2.0,在虚拟环境中安装tensorflow。


- 安装结束后输入python,再检查一下是否能正常使用。

如果没有报错,说明安装成功。如果报错,仔细按以上步骤重新进行。
退出python交互模式
输入“CTRL”+ Z,回到终端。
创建python文件
用touch 文件名.py 创建一个python文件
用 vim 文件名.py 对一个python文件进行编辑
编辑python文件
进入编辑页面后输入i,进入编辑模式,此时才可以对该文件进行编辑。
保存并退出python文件
敲完所有代码之后,需要保存退出,在该页面先按键盘左上角的esc键,然后输入:wq,并回车。(该指令是保存并推出该文件。其中,冒号务必用英文的输入法输入,是对文本进行命令行操作,此后输入的命令可以显示在左下角,如图所示,w是保存,q是退出)
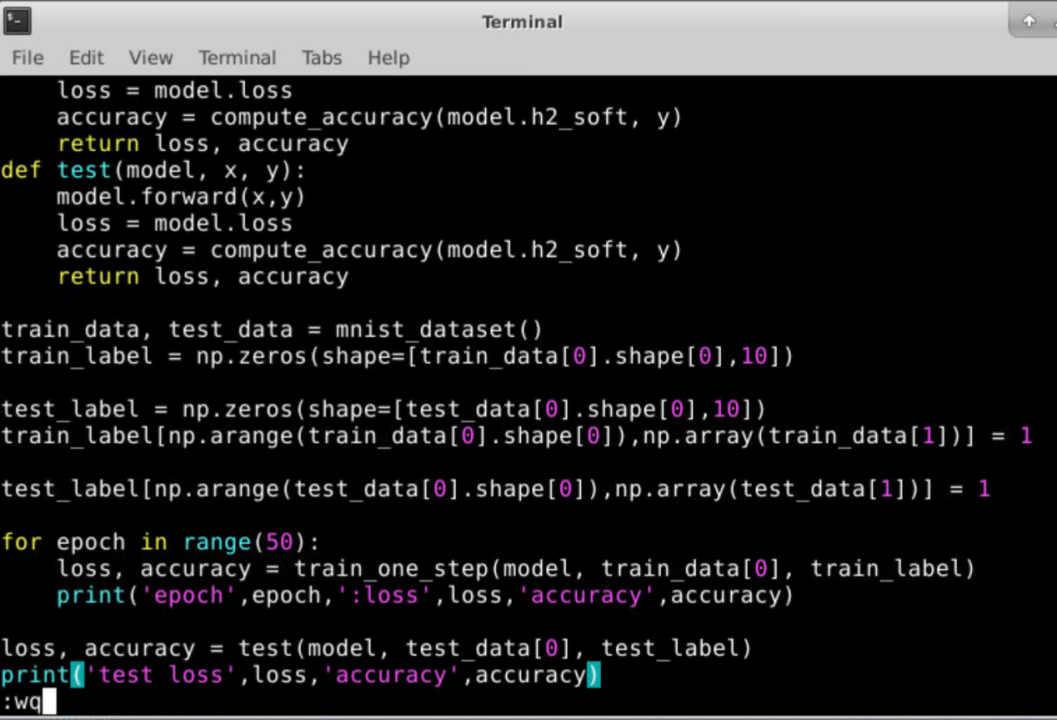
- 运行python文件
输入回车后,来到终端,运行该python文件,输入python3 文件名.py即可得到实验结果(当然,如果你的代码没有错误的话)
4.2 代码过程
- 数据预处理
函数def mnist_dataset ( ) :输入训练集和测试集的数据,并将数据标准化,便于后续数据处理。
- 模型建立
本全连接神经网络采用Relu函数作为中间层激活函数,采用softmax函数作为输出层激活函数。
定义矩阵乘法类:class Matmul ( ) ,用于对样本数据进行处理和计算。
定义relu类:class Relu ( ),用于中间隐藏层的激活函数,可以用来表示任何非线性的特征。
定义softmax类:class Softmax ( ),用于输出层的激活函数,可以将数据输出结果划分到0到1范围内,便于分类。
定义交叉熵类:Cross_entropy ( ) ,交叉熵在分类问题中常常与softmax是标配,softmax将输出的结果进行处理,使其多个分类的预测值和为1,再通过交叉熵来计算损失。
构建模型,通过以上类的正向传播和反向传播相结合,来构建最佳模型。
- 预测结果
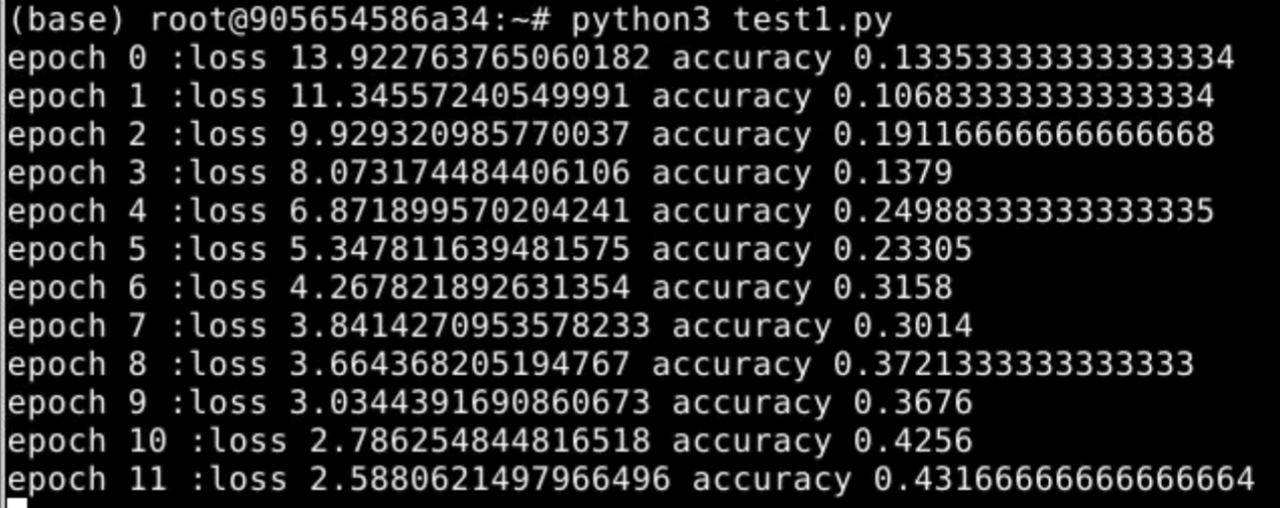
得到输出结果后,计算准确率,迭代50次,得到并观察实验结果。
5、实验结果
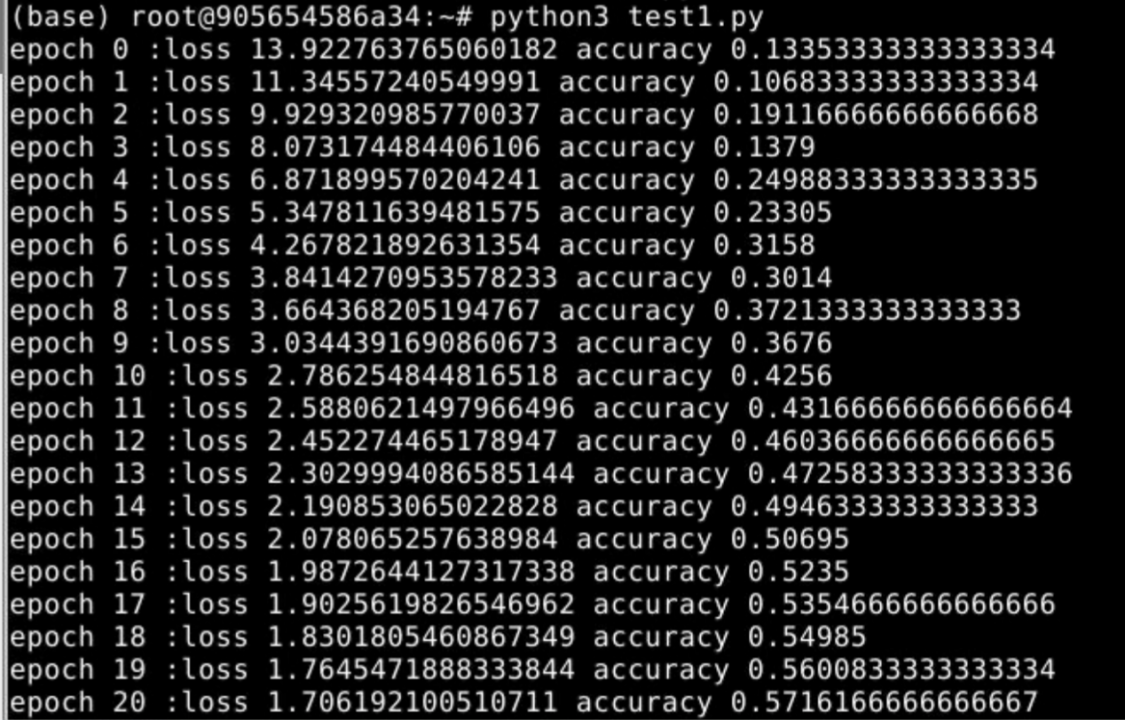
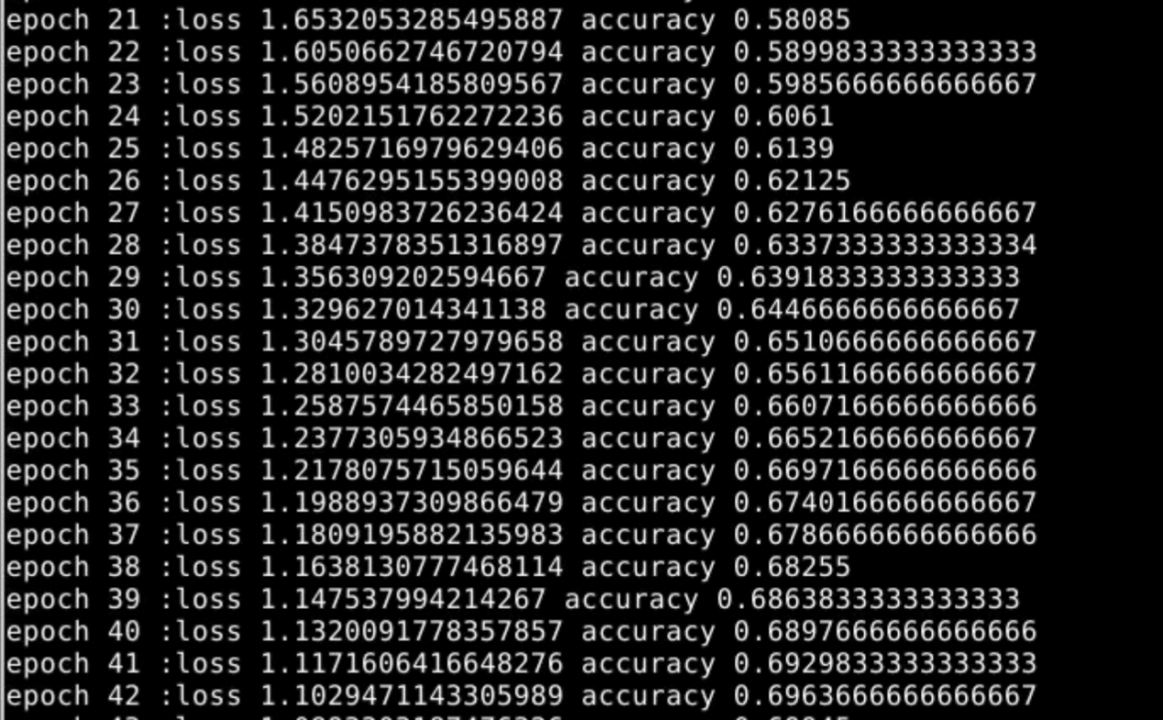
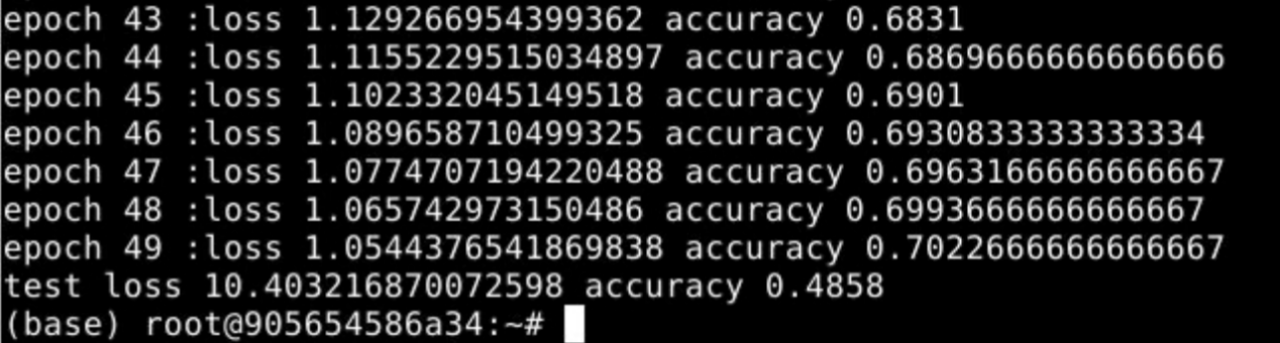
6、实验总结
6.1 知识总结
- 全连接神经网络
包含输入层、中间层、输出层。中间隐藏层的数量以及各层(输入层、隐藏层、输出层)的神经单元数量均可自由设置,层内神经元无连接,层与层之间神经元全连接。全连接神经网络是一种最简单、最基础的神经网络。
- RELU激活函数
当输入值小于0,就输出0;当输入值大于0,就输出这个输入值。RELU激活函数是非线性函数,通过无数个relu函数来拟合出一条最符合数据集的曲线,可以学习数据中的复杂关系。
- softmax激活函数
用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类,其多用于神经网络的最后一层。
- 交叉熵损失
交叉熵刻画的是实际输出的概率与期望输出的概率的距离,表示真实概率分布与预测概率分布之间的差异。即交叉熵损失的值越小,两个概率分布就越接近,模型预测效果就越好。
6.2 整体理解
本次实验是完成一个全连接神经网络,输入层输入的样本特征数(向量维度)为28*28+1,中间层100个神经元采用Relu激活函数,将得到的结果输入到含有10个神经元的输出层,输出层10个神经元采用Softmax激活函数,得到结果,最后通过交叉熵来计算,完成分类。
6.3 遇到的困难
- 对各种基础概念不清晰
比如全连接神经网络、relu激活函数,softmax激活函数,交叉熵等,但是通过查阅教材、论文和各种其他网络资料最终对各种概念有了较为深刻的理解和掌握。
- 对代码较为陌生
由于是第一次真正接触神经网络的代码,对于一些函数比较陌生,但是随着手写了一遍代码后,对整体代码有了一个整体对把握,对于部分代码细节可以做到理解和掌握,相信熟能生巧,随着一次又一次的复习和巩固,可以对代码有进一步的理解和掌握。
- 环境搭建困难
在环境搭建时遇到一些困难,也正是搭建环境时遇到的bug,让我对虚拟机、容器等概念有了更加深刻的理解,并且了解和掌握了一些搭建虚拟环境的方法,为日后更加复杂的项目打下了坚实的基础。
6.4 收获
- 理解更加深刻
通过本次实验,我对神经网络有了更加深刻的理解,神经网络的全过程通过python和numpy等工具得到了实现,对神经网络的感受不再停留在书本和课堂,在本次实验中当看到神经网络真正跑起来并且得到实验结果时,还是很开心欣慰很有成就感的。
- 锻炼自学能力和独立思考能力
这次实验锻炼了我的独立解决问题的能力,遇到的bug通过查阅各种资料自学最终都解决掉了,最终看到结果run了出来。
- 锻炼心态
但是本次实验的成功不是终点,恰恰是神经网络学习的起点,真正的学习才刚刚开始,过程虽然辛苦,但是克服困难的喜悦更加强烈,本次试验锻炼了我强大而坚韧的内心,让我有勇气面临更加困难的处境。
7、源码
import os
import numpy as np
import tensorflow
import tensorflow as tf
from tensorflow import keras
from keras import layers, datasets, optimizers
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
def mnist_dataset():
(x, y), (x_test, y_test) = datasets.mnist.load_data()
x = x / 2255.0
x_test = x_test / 255.0
return (x, y), (x_test, y_test)
class Matmul():
def __init__(self):
self.mem = {}
def forward(self, x, W):
h = np.matmul(x, W)
self.mem = {"x":x, "W":W}
return h
def backward(self, grad_y):
x = self.mem["x"]
W = self.mem["W"]
grad_x = np.matmul(grad_y, W.T)
grad_W = np.matmul(x.T, grad_y)
return grad_x, grad_W
class Relu():
def __init__(self):
self.mem = {}
def forward(self, x):
self.mem["x"] = x
return np.where(x>0, x, np.zeros_like(x))
def backward(self, grad_y):
x = self.mem["x"]
return (x>0).astype(np.float32)*grad_y
class Softmax():
def __init__(self):
self.mem = {}
self.epsilon = 1e-12
def forward(self, x):
x_exp = np.exp(x)
denominator = np.sum(x_exp, axis=1, keepdims=True)
out = x_exp/(denominator + self.epsilon)
self.mem["out"] = out
self.mem["x_exp"] = x_exp
return out
def backward(self, grad_y):
s = self.mem["out"]
sisj = np.matmul(np.expand_dims(s, axis=2), np.expand_dims(s,axis=1))
g_y_exp = np.expand_dims(grad_y, axis=1)
tmp = np.matmul(g_y_exp, sisj)
tmp = np.squeeze(tmp, axis=1)
softmax_grad = -tmp + grad_y*s
return softmax_grad
class Cross_entropy():
def __init__(self):
self.mem = {}
self.epsilon = 1e-12
def forward(self, x, labels):
log_prob = np.log(x + self.epsilon)
out = np.mean(np.sum(-log_prob*labels,axis=1))
self.mem["x"] = x
return out
def backward(self, labels):
x = self.mem["x"]
return -1/(x + self.epsilon)*labels
class myModel():
def __init__(self):
self.W1 = np.random.normal(size=[28*28+1,100])
self.W2 = np.random.normal(size=[100, 10])
self.mul_h1 = Matmul()
self.relu = Relu()
self.mul_h2 = Matmul()
self.softmax = Softmax()
self.cross_en = Cross_entropy()
def forward(self, x, labels):
x = x.reshape(-1, 28*28)
bias = np.ones(shape=[x.shape[0], 1])
x = np.concatenate([x, bias], axis=1)
self.h1 =self.mul_h1.forward(x, self.W1)
self.h1_relu = self.relu.forward(self.h1)
self.h2 = self.mul_h2.forward(self.h1_relu, self.W2)
self.h2_soft = self.softmax.forward(self.h2)
self.loss = self.cross_en.forward(self.h2_soft, labels)
def backward(self, labels):
self.loss_grad = self.cross_en.backward(labels)
self.h2_soft_grad = self.softmax.backward(self.loss_grad)
self.h2_grad, self.W2_grad = self.mul_h2.backward(self.h2_soft_grad)
self.h1_relu_grad = self.relu.backward(self.h2_grad)
self.h1_grad, self.W1_grad = self.mul_h1.backward(self.h1_relu_grad)
model = myModel()
def compute_accuracy(prob, labels):
predictions = np.argmax(prob, axis=1)
truth = np.argmax(labels,axis=1)
return np.mean(predictions==truth)
def train_one_step(model, x, y):
model.forward(x, y)
model.backward(y)
model.W1 -= 1e-5*model.W1_grad
model.W2 -= 1e-5*model.W2_grad
loss = model.loss
accuracy = compute_accuracy(model.h2_soft, y)
return loss, accuracy
def test(model, x, y):
model.forward(x,y)
loss = model.loss
accuracy = compute_accuracy(model.h2_soft, y)
return loss, accuracy
train_data, test_data = mnist_dataset()
train_label = np.zeros(shape=[train_data[0].shape[0],10])
test_label = np.zeros(shape=[test_data[0].shape[0],10])
train_label[np.arange(train_data[0].shape[0]),np.array(train_data[1])] = 1
test_label[np.arange(test_data[0].shape[0]),np.array(test_data[1])] = 1
for epoch in range(50):
loss, accuracy = train_one_step(model, train_data[0], train_label)
print('epoch',epoch,':loss',loss,';accuracy',accuracy)
loss, accuracy = test(model, test_data[0], test_label)
print('test loss',loss,';accuracy',accuracy)














 3997
3997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









