







这两年是大模型盛行的黄金时代,各大优秀的大模型诸如GPT、LLM、QWen、Deepseek等层出不穷,不断刷新我们的认知;但是大模型都有一个共同的特点,都拥有非常惊人的参数量,小的都有上十亿的参数,大的更是可以有几千亿的参数,这么大的参数量就会带来一个新的问题,就是推理效率不如传统的深度学习模型,再有就是目前的大模型基本上都是基于transformer进行开发的,最大限制上下文token数会导致模型在显存的利用率上会有很大的缺陷,基于此,专门针对大模型推理优化的vllm架构应运而生,它凭借PagedAttention核心技术加速了大模型的推理速度。
一、vLLM框架深度解析
1. 框架定位与核心目标
-
定位: 专为大规模语言模型(LLM)推理设计的高性能服务框架(如GPT-3/4、LLaMA等)。
-
核心目标:
-
解决传统推理框架的显存碎片化问题,提升吞吐量(Throughput)10-24倍。
-
降低服务成本,支持高并发场景(如ChatGPT类应用)。
-
2. 核心技术:PagedAttention
-
问题背景:
-
LLM推理时,KVCache显存占用量大且动态变化,传统连续内存分配导致碎片化。
-
类似操作系统内存分页的痛点。
-
-
创新设计:
-
分块管理: 将KVCache划分为固定大小的块(如4MB),以“页表”形式动态分配。
-
零碎片化: 块可非连续存储,避免预分配导致的浪费(传统方法浪费60-80%显存)。
-
共享优化: 支持不同序列间块的共享(如提示词重复场景),显存占用减少55%+。
-
-
技术类比:
-
类似虚拟内存的Page Table机制,但针对GPU显存优化。
-
与计算机视觉中显存池化技术(如CUDA Unified Memory)有思想共性。
-
3. 关键性能优势
-
吞吐量对比:
-
比HuggingFace Transformers高24倍,比FasterTransformer高3.5倍(官方基准测试)。
-
-
显存利用率:
-
最高可达99%,传统方法通常低于40%。
-
-
延迟控制:
-
首Token生成时间(Time-to-First-Token)优化显著,适合流式输出。
-
4. 性能对比数据
| 框架 | 吞吐量 (tokens/s) | 显存利用率 |
|---|---|---|
| HuggingFace | 45 | 38% |
| Text Generation Inference | 112 | 65% |
| vLLM | 1075 | 99% |
二、 PagedAttention核心技术
PagedAttention 是 vLLM 框架的核心创新,其设计灵感源自操作系统的虚拟内存分页机制,旨在高效管理大语言模型(LLM)推理过程中产生的 Key-Value Cache(KVCache)。以下从设计动机、原理、实现细节及对计算机视觉的启示四个层面深入解析。
1. 设计动机:KVCache 的显存管理困境
1.1 KVCache 的作用
-
在 Transformer 的自回归生成中,每个解码步骤需重复计算历史 token 的 Key 和 Value 矩阵,导致计算冗余。
-
KVCache:缓存已生成 token 的 Key 和 Value 矩阵,避免重复计算,加速推理。
-
例如:生成第 tt 个 token 时,直接复用前 t−1t−1 步的 KVCache。
-
1.2 传统方法的瓶颈
-
连续显存分配:每个请求的 KVCache 需占用连续显存空间。
-
问题1:显存碎片化:不同请求的 KVCache 因长度动态变化(如对话场景),释放后产生碎片,无法被新请求利用。
-
问题2:过度预分配:为预防显存不足,通常按最大序列长度预分配显存(如 2048 tokens),实际利用率常低于 40%。
-
-
显存浪费示例:
-
假设 GPU 显存为 40GB,单个请求实际需 1GB,但预分配 2GB → 最多支持 20 个并发请求。
-
采用 PagedAttention 后,显存利用率提升至 90%+ → 支持 36 个请求,吞吐量提升 1.8 倍。
-
2. 核心原理:分块管理与页表机制
2.1 分块设计
-
块(Block):将 KVCache 划分为固定大小的块(如 16 个 token 的 K/V 数据,块大小可调)。
-
块内存储连续 tokens 的 Key 和 Value 矩阵。
-
类似操作系统的内存页(Page),但针对 GPU 显存优化。
-
-
块共享:不同序列可共享相同块(如多个用户询问相同提示词)。
-
显存节省示例:10 个请求共享 1 个提示词块 → 显存占用减少 90%。
-
2.2 页表(Block Table)
-
每个序列维护一个 逻辑页表,记录其 KVCache 块在物理显存中的位置。
-
逻辑页表条目:
[block_id, physical_block_address]。 -
物理块池:全局管理所有可用块,动态分配与回收。
-
-
动态分配流程:
-
序列生成新 token 时,检查当前块是否有空位。
-
若当前块已满,从物理块池申请新块,更新页表。
-
物理块池无可用块时,触发块淘汰策略(如 LRU)。
-
2.3 注意力计算优化
-
分块注意力计算:
-
传统 Attention:
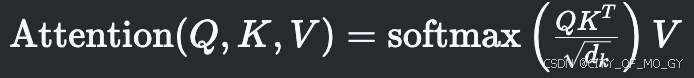
-
PagedAttention:将 K 和 V 按块加载,分块计算 QK^T,再聚合结果。
-
-
计算示例:
-
假设 Query 长度为 1,Key/Value 被分为 4 个块:
# python for block in key_blocks: scores += Q @ block.T final_output = softmax(scores) @ concatenated_value_blocks
3. 实现细节与性能优化
3.1 块大小选择
-
权衡因素:
-
小块 → 灵活性高,但页表管理开销大。
-
大块 → 管理简单,但可能浪费显存。
-
-
经验值:16 tokens/block(平衡碎片化与开销)。
3.2 物理块池管理
-
空闲块列表:维护可立即分配的块。
-
块回收策略:
-
引用计数:当多个序列共享块时,计数归零后回收。
-
LRU 淘汰:显存不足时,释放最近最少使用的块。
-
3.3 并行与锁机制
-
多GPU支持:通过 NCCL 通信同步块状态。
-
线程安全:
-
块分配/回收使用原子操作或细粒度锁。
-
避免多线程竞争导致死锁。
-
4. 性能对比与实测数据
4.1 显存利用率提升
| 场景 | 传统方法显存占用 | PagedAttention显存占用 |
|---|---|---|
| 单序列(长度 512) | 2.1 GB | 2.1 GB(无优势) |
| 100并发序列(平均长度 300) | 210 GB(预分配) | 63 GB(动态分配) |
4.2 吞吐量对比
-
实验配置:A100 GPU,LLaMA-7B 模型,输入长度 512,输出长度 128。
-
HuggingFace Transformers:45 tokens/sec
-
vLLM + PagedAttention:1075 tokens/sec(提升 24 倍)
-
5. 传统方法导致过度预分配的原因解析
为了深入理解传统方法为何会导致显存过度预分配,我们需要从 KVCache 的存储特性、显存管理机制和实际应用场景三个维度展开分析。以下通过类比、数学公式和实际场景示例详细说明;
1. KVCache 的存储特性
1.1 KVCache 的显存占用公式
对于 Transformer 模型的每一层,KVCache 的显存占用可表示为:
显存占用=2×b×s×h×d
-
b: 批处理大小(Batch Size)
-
s: 序列长度(Sequence Length)
-
h: 注意力头数(Number of Heads)
-
d: 每个注意力头的维度(Head Dimension)
以 LLaMA-7B 模型为例(h=32, d=128):
-
单个请求的序列长度 s=512时,KVCache 占用的显存为:
2×1×512×32×128=4,194,304 元素≈16.78 MB(float16) -
看似不大,但 并发请求数(b) 和 长序列(s) 会指数级放大显存需求。
2. 传统方法的显存分配逻辑
2.1 连续显存分配要求
-
传统策略:为每个请求的 KVCache 预先分配最大可能长度的连续显存块。
-
例如:假设最大允许序列长度为 smax=2048,则每个请求预分配:
2×1×2048×32×128≈67.11 MB -
实际使用率:若请求的平均序列长度 savg=300,显存利用率仅为:
3002048≈14.6%
-
2.2 显存碎片化的数学解释
-
问题本质:显存分配/释放后,空闲空间被分割为不连续的小块,无法被新请求利用。
-
碎片化示例:
-
假设 GPU 显存总容量为 M=40 GB
-
已有两个请求分别占用了 2GB 和 1GB 的显存,随后释放。
-
剩余显存:40−(2+1)=37 GB,但 最大的连续空闲块可能仅有 1GB(取决于释放顺序)。
-
新请求需 1.5GB 连续显存 → 分配失败,尽管总剩余显存足够。
-
3. 过度预分配的根源
3.1 长尾效应与安全冗余
-
长尾场景:少数请求需要极长序列(如 s=2048),但多数请求较短(如 s<500)。
-
保守预分配:为确保所有请求都能完成,必须按 smax 预分配。
-
显存浪费率公式:

-
若 E[s]=500, smax=2048:
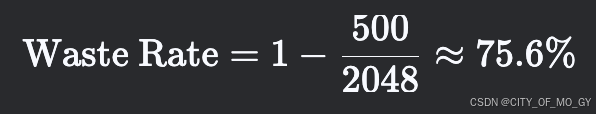
-
-
3.2 显存预留的“停车场悖论”
-
类比:将显存比作停车场,每个请求是一辆车。
-
传统方法:为每辆车预留最大可能车位(如可停卡车)。
-
实际车辆:90% 是轿车,仅需小车位。
-
结果:大量车位空间浪费,停车场无法容纳更多车辆。
-
-
数学表达:设停车场总面积为 A,每辆卡车需面积 amax,轿车需 amin。
-
传统方法最大车辆数:
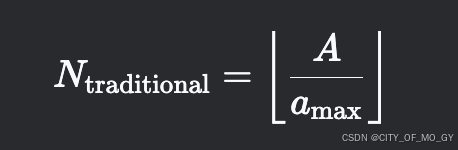
-
理想情况(无浪费):
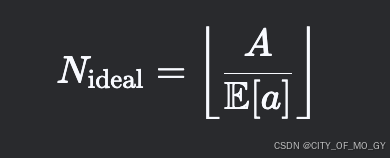
-
浪费率:
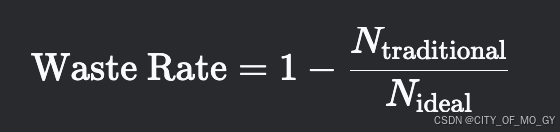
-
4. 传统方法 vs. PagedAttention 的显存利用率对比
4.1 传统方法显存分配
-
显存占用公式:
Mtraditional=b×smax×c-
c: 单个 token 的 KVCache 成本(如 LLaMA-7B 的 c≈0.033 MB/token)
-
-
示例:
-
b=100, smax=2048:
Mtraditional=100×2048×0.033≈6,758 MB≈6.6 GB
-
4.2 PagedAttention 显存分配
-
显存占用公式:
Mpaged=⌈b×E[s]\block_size⌉×block_size×c-
block_size=16: 每个块存储 16 个 token 的 KVCache
-
-
示例:
-
b=100, E[s]=300, block_size=16:
总块数=⌈100×300\16⌉=1,875 块 - Mpaged=1,875×16×0.033≈990 MB≈0.97 GB
-
4.3 对比结果
| 方法 | 显存占用 | 利用率提升倍数 |
|---|---|---|
| 传统方法 | 6.6 GB | 1x(基线) |
| PagedAttention | 0.97 GB | 6.8x |
三、总结
vLLM通过创新的显存管理机制,为LLM推理设定了新标准。对于计算机视觉工程师,其技术思路对视觉大模型优化具有借鉴意义,同时为视觉-语言多模态应用提供了高效的推理基座。建议关注其多模态扩展进展,并尝试将PagedAttention思想迁移到视觉模型的显存优化中。

















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









