







前面我们基于Minimind项目从代码层面介绍了大模型的推理全流程、 大模型加载LoRA层的方式,但对构建的大模型的具体细节没有做过多的剖析,这篇博客就以稠密模型和MoE稀疏专家模型为切入点,具体分析对比一下它们之间在模型构造方面的区别;
该博客分为两个部分,第一部分会从理论部分出发,通过文字描述来解释这两类模型结构以及它们之间的区别;第二部分会结合模型构建代码,剖析模型中的每一个子层;
一、两类模型结构介绍
1.1 Dense Model
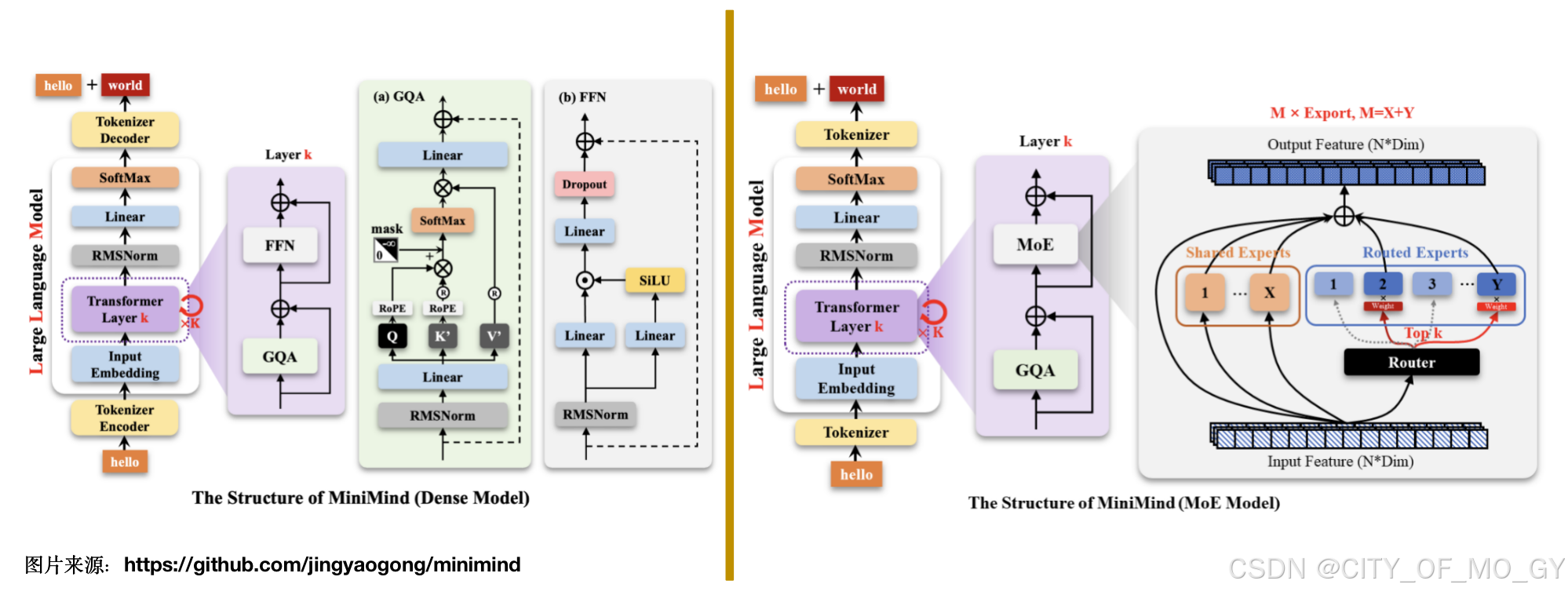
稠密模型也就是我们传统意义上的transformer模块构建起来的大模型,虽然不同的大模型在transformer模块中有不同的结构改变和创新,但其使用的子层和整体框架其实是大致相同的;大概是上图中左侧拓扑图的一个结构,包括输入Embedding层、稠密transformer模块堆叠、归一化层、全联接层,稠密transformer模块细分又包括自注意力层、前馈神经网络层;需要注意的是在稠密模型中的transformer模块中,每个transformer模块只包含一个FFN前馈神经网络;
1.2 MoE Model
对于MoE模型,它诞生的还是比较早的,最初只用在一些NLP领域的递归循环神经网络上,但是我知道它还是因为Deepseek模型的兴起;接着就是铺天盖地的自媒体和营销号对其MoE架构的宣传;起初通过一些自媒体博主的介绍,误以为MoE模型是基于transformer的门控路由模型和超多个小的专家模型完全割裂的拼接,模型输入通过门控路由分配给一个或者多个专家模型解码,然后直接由各个专家模型进行输出或者多个专家模型的输出结果融合输出;看过源码之后,才知道这个认知是错误的;如果也有和我相同认知的同学,可以认真了解一下接下来的内容,或许会对你有所帮助;
其实MoE模型和Dense模型之间的区别只在于transformer模块中自注意力模块后的前馈神经那一部分;通过上图中右侧的拓扑图可以看到,MoE模型在transformer模块中将FFN层替换成了MoE层,这个MoE层包括一个门控路由层和若干个并联FFN网络;而这些并联的若干个FFN网络就是对应的一个一个的专家,由前面的门控网络(Gate)来动态的控制调用,具体如何调用,调用几个专家,调用后的专家输出结果融合都可以通过不同的策略进行指定;对于MoE模型,如果有多个transformer模块,就会有多个这样的结构对应到每一个transformer模块中,当然也可以创新性的只将模型中的部分稠密transformer模块替换为MoEtransformer,如果可以涨点的话,对于硕士生研究感觉是毕设上一个小的创新点;
二、模型结构剖析
还是以Minimind项目为基础,从代码入手,看一看作者是如何一步一步构建大模型框架的;这里我们还是分两步,首先加载不使用MoE结构的模型和使用MoE结构的模型,打印它们的子模块,对比一下有什么区别,然后我们就以使用MoE结构的模型为例,具体剖析整个模型结构;
2.1 模型结构对比
和之前一样,依然在eval_model.py同级目录创建一个jujupyterNotebook文件,我们加载并打印模型结构进行对比;
2.1.1 导包
代码:
import argparse
import random
import time
import numpy as np
import torch
import warnings
from transformers import AutoTokenizer, AutoModelForCausalLM
from model.model import MiniMindLM
from model.LMConfig import LMConfig
from model.model_lora import *
warnings.filterwarnings('ignore')2.1.2 定义并实例化超参
代码:
class ARG():
def __init__(self):
self.lora_name = 'None'
self.out_dir = 'out'
self.temperature = 0.85
self.top_p = 0.85
self.device = 'cpu'
self.dim = 512
self.n_layers = 8
self.max_seq_len = 8192
self.use_moe = False
self.history_cnt = 0
self.stream = True
self.load = 0
self.model_mode = 1
args = ARG()2.1.3 加载稠密模型
代码:
model_dense = MiniMindLM(LMConfig(
dim=args.dim,
n_layers=args.n_layers,
max_seq_len=args.max_seq_len,
use_moe=args.use_moe
))
for name, tensor in model.state_dict().items():
print(name)输出结果:
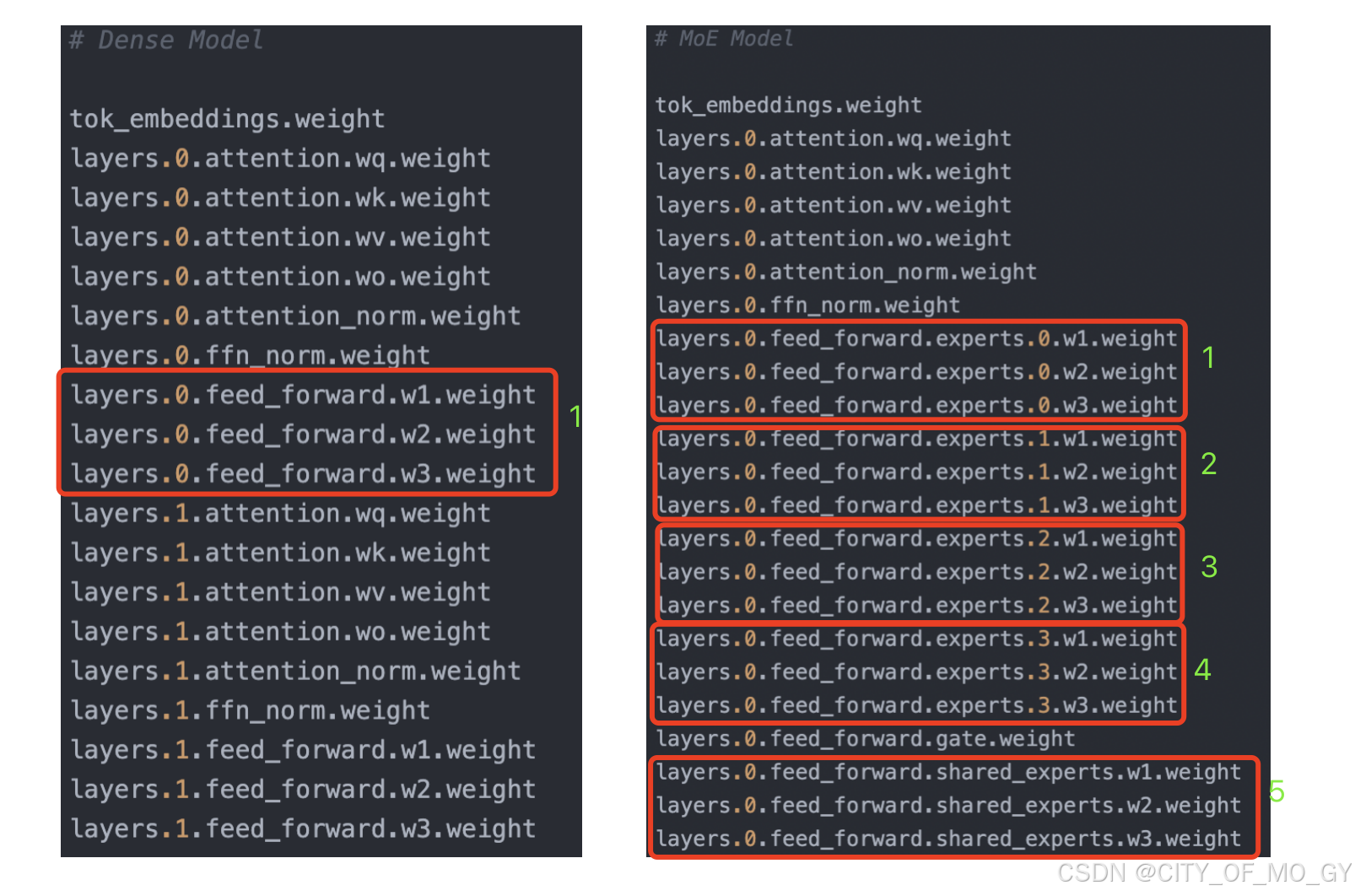
# Dense Model
tok_embeddings.weight
layers.0.attention.wq.weight
layers.0.attention.wk.weight
layers.0.attention.wv.weight
layers.0.attention.wo.weight
layers.0.attention_norm.weight
layers.0.ffn_norm.weight
layers.0.feed_forward.w1.weight
layers.0.feed_forward.w2.weight
layers.0.feed_forward.w3.weight
layers.1.attention.wq.weight
layers.1.attention.wk.weight
layers.1.attention.wv.weight
layers.1.attention.wo.weight
layers.1.attention_norm.weight
layers.1.ffn_norm.weight
layers.1.feed_forward.w1.weight
layers.1.feed_forward.w2.weight
layers.1.feed_forward.w3.weight
......
layers.7.attention.wq.weight
layers.7.attention.wk.weight
layers.7.attention.wv.weight
layers.7.attention.wo.weight
layers.7.attention_norm.weight
layers.7.ffn_norm.weight
layers.7.feed_forward.w1.weight
layers.7.feed_forward.w2.weight
layers.7.feed_forward.w3.weight
norm.weight
output.weight2.1.4 初始化MoEModel
这里,我们需要将‘use_moe’参数改为True;
代码:
model_moe = MiniMindLM(LMConfig(
dim=args.dim,
n_layers=args.n_layers,
max_seq_len=args.max_seq_len,
use_moe=True
))
for name, tensor in model_moe.state_dict().items():
print(name)输出结果:
# MoE Model
tok_embeddings.weight
layers.0.attention.wq.weight
layers.0.attention.wk.weight
layers.0.attention.wv.weight
layers.0.attention.wo.weight
layers.0.attention_norm.weight
layers.0.ffn_norm.weight
layers.0.feed_forward.experts.0.w1.weight
layers.0.feed_forward.experts.0.w2.weight
layers.0.feed_forward.experts.0.w3.weight
layers.0.feed_forward.experts.1.w1.weight
layers.0.feed_forward.experts.1.w2.weight
layers.0.feed_forward.experts.1.w3.weight
layers.0.feed_forward.experts.2.w1.weight
layers.0.feed_forward.experts.2.w2.weight
layers.0.feed_forward.experts.2.w3.weight
layers.0.feed_forward.experts.3.w1.weight
layers.0.feed_forward.experts.3.w2.weight
layers.0.feed_forward.experts.3.w3.weight
layers.0.feed_forward.gate.weight
layers.0.feed_forward.shared_experts.w1.weight
layers.0.feed_forward.shared_experts.w2.weight
layers.0.feed_forward.shared_experts.w3.weight
layers.1.attention.wq.weight
layers.1.attention.wk.weight
layers.1.attention.wv.weight
layers.1.attention.wo.weight
layers.1.attention_norm.weight
layers.1.ffn_norm.weight
layers.1.feed_forward.experts.0.w1.weight
layers.1.feed_forward.experts.0.w2.weight
layers.1.feed_forward.experts.0.w3.weight
layers.1.feed_forward.experts.1.w1.weight
layers.1.feed_forward.experts.1.w2.weight
layers.1.feed_forward.experts.1.w3.weight
layers.1.feed_forward.experts.2.w1.weight
layers.1.feed_forward.experts.2.w2.weight
layers.1.feed_forward.experts.2.w3.weight
layers.1.feed_forward.experts.3.w1.weight
layers.1.feed_forward.experts.3.w2.weight
layers.1.feed_forward.experts.3.w3.weight
layers.1.feed_forward.gate.weight
layers.1.feed_forward.shared_experts.w1.weight
layers.1.feed_forward.shared_experts.w2.weight
layers.1.feed_forward.shared_experts.w3.weight
......
layers.7.attention.wq.weight
layers.7.attention.wk.weight
layers.7.attention.wv.weight
layers.7.attention.wo.weight
layers.7.attention_norm.weight
layers.7.ffn_norm.weight
layers.7.feed_forward.experts.0.w1.weight
layers.7.feed_forward.experts.0.w2.weight
layers.7.feed_forward.experts.0.w3.weight
layers.7.feed_forward.experts.1.w1.weight
layers.7.feed_forward.experts.1.w2.weight
layers.7.feed_forward.experts.1.w3.weight
layers.7.feed_forward.experts.2.w1.weight
layers.7.feed_forward.experts.2.w2.weight
layers.7.feed_forward.experts.2.w3.weight
layers.7.feed_forward.experts.3.w1.weight
layers.7.feed_forward.experts.3.w2.weight
layers.7.feed_forward.experts.3.w3.weight
layers.7.feed_forward.gate.weight
layers.7.feed_forward.shared_experts.w1.weight
layers.7.feed_forward.shared_experts.w2.weight
layers.7.feed_forward.shared_experts.w3.weight
norm.weight
output.weight2.1.5 结果对比
通过对比我们发现同样是layers.0Transformer模块,稠密模型只有一个FFN层,而MoE模型却有5个FFN层,而这五个FFN层就是5个专家,其中包含4个门控专家和一个共享专家;接下来,我们就通过代码来探究一下MoE模型它是如何构建的;
 2.2 MiniMindLM-MoE模型结构剖析
2.2 MiniMindLM-MoE模型结构剖析
这里我们就直接到模型构建的脚本minimind/model/model.py中来看,MiniMindLM是整个模型的主体,我们就从class MiniMindLM切入,通过forward函数逐步深入,解析MoE模型结构;
# minimind/model/model.py
import math
import struct
import inspect
import time
from .LMConfig import LMConfig
from typing import Any, Optional, Tuple, List
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
from transformers import PreTrainedModel
from transformers.modeling_outputs import CausalLMOutputWithPast
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
return self.weight * self._norm(x.float()).type_as(x)
def precompute_pos_cis(dim: int, end: int = int(32 * 1024), theta: float = 1e6):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # type: ignore
freqs = torch.outer(t, freqs).float() # type: ignore
pos_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return pos_cis
def apply_rotary_emb(xq, xk, pos_cis):
def unite_shape(pos_cis, x):
ndim = x.ndim
assert 0 <= 1 < ndim
assert pos_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return pos_cis.view(*shape)
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
pos_cis = unite_shape(pos_cis, xq_)
xq_out = torch.view_as_real(xq_ * pos_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * pos_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
class Attention(nn.Module):
def __init__(self, args: LMConfig):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
assert args.n_heads % self.n_kv_heads == 0
self.n_local_heads = args.n_heads
self.n_local_kv_heads = self.n_kv_heads
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wv = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False)
self.attn_dropout = nn.Dropout(args.dropout)
self.resid_dropout = nn.Dropout(args.dropout)
self.dropout = args.dropout
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and args.flash_attn
# print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf"))
mask = torch.triu(mask, diagonal=1)
self.register_buffer("mask", mask, persistent=False)
def forward(self,
x: torch.Tensor,
pos_cis: torch.Tensor,
past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
use_cache=False):
bsz, seq_len, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, pos_cis)
# kv_cache实现
if past_key_value is not None:
xk = torch.cat([past_key_value[0], xk], dim=1)
xv = torch.cat([past_key_value[1], xv], dim=1)
past_kv = (xk, xv) if use_cache else None
xq, xk, xv = (
xq.transpose(1, 2),
repeat_kv(xk, self.n_rep).transpose(1, 2),
repeat_kv(xv, self.n_rep).transpose(1, 2)
)
if self.flash and seq_len != 1:
dropout_p = self.dropout if self.training else 0.0
output = F.scaled_dot_product_attention(
xq, xk, xv,
attn_mask=None,
dropout_p=dropout_p,
is_causal=True
)
else:
scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim)
scores += self.mask[:, :, :seq_len, :seq_len]
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
scores = self.attn_dropout(scores)
output = scores @ xv
output = output.transpose(1, 2).reshape(bsz, seq_len, -1)
output = self.resid_dropout(self.wo(output))
return output, past_kv
class FeedForward(nn.Module):
def __init__(self, config: LMConfig):
super().__init__()
if config.hidden_dim is None:
hidden_dim = 4 * config.dim
hidden_dim = int(2 * hidden_dim / 3)
config.hidden_dim = config.multiple_of * ((hidden_dim + config.multiple_of - 1) // config.multiple_of)
self.w1 = nn.Linear(config.dim, config.hidden_dim, bias=False)
self.w2 = nn.Linear(config.hidden_dim, config.dim, bias=False)
self.w3 = nn.Linear(config.dim, config.hidden_dim, bias=False)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
class MoEGate(nn.Module):
def __init__(self, config: LMConfig):
super().__init__()
self.config = config
self.top_k = config.num_experts_per_tok
self.n_routed_experts = config.n_routed_experts
self.scoring_func = config.scoring_func
self.alpha = config.aux_loss_alpha
self.seq_aux = config.seq_aux
self.norm_topk_prob = config.norm_topk_prob
self.gating_dim = config.dim
self.weight = nn.Parameter(torch.empty((self.n_routed_experts, self.gating_dim)))
self.reset_parameters()
def reset_parameters(self) -> None:
import torch.nn.init as init
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
def forward(self, hidden_states):
bsz, seq_len, h = hidden_states.shape
hidden_states = hidden_states.view(-1, h)
logits = F.linear(hidden_states, self.weight, None)
if self.scoring_func == 'softmax':
scores = logits.softmax(dim=-1)
else:
raise NotImplementedError(f'insupportable scoring function for MoE gating: {self.scoring_func}')
topk_weight, topk_idx = torch.topk(scores, k=self.top_k, dim=-1, sorted=False)
if self.top_k > 1 and self.norm_topk_prob:
denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
topk_weight = topk_weight / denominator
if self.training and self.alpha > 0.0:
scores_for_aux = scores
aux_topk = self.top_k
topk_idx_for_aux_loss = topk_idx.view(bsz, -1)
if self.seq_aux:
scores_for_seq_aux = scores_for_aux.view(bsz, seq_len, -1)
ce = torch.zeros(bsz, self.n_routed_experts, device=hidden_states.device)
ce.scatter_add_(1, topk_idx_for_aux_loss,
torch.ones(bsz, seq_len * aux_topk, device=hidden_states.device)).div_(
seq_len * aux_topk / self.n_routed_experts)
aux_loss = (ce * scores_for_seq_aux.mean(dim=1)).sum(dim=1).mean() * self.alpha
else:
mask_ce = F.one_hot(topk_idx_for_aux_loss.view(-1), num_classes=self.n_routed_experts)
ce = mask_ce.float().mean(0)
Pi = scores_for_aux.mean(0)
fi = ce * self.n_routed_experts
aux_loss = (Pi * fi).sum() * self.alpha
else:
aux_loss = 0
return topk_idx, topk_weight, aux_loss
class MOEFeedForward(nn.Module):
def __init__(self, config: LMConfig):
super().__init__()
self.config = config
self.experts = nn.ModuleList([
FeedForward(config)
for _ in range(config.n_routed_experts)
])
self.gate = MoEGate(config)
if config.n_shared_experts is not None:
self.shared_experts = FeedForward(config)
def forward(self, x):
identity = x
orig_shape = x.shape
bsz, seq_len, _ = x.shape
# 使用门控机制选择专家
topk_idx, topk_weight, aux_loss = self.gate(x)
x = x.view(-1, x.shape[-1])
flat_topk_idx = topk_idx.view(-1)
if self.training:
# 训练模式下,重复输入数据
x = x.repeat_interleave(self.config.num_experts_per_tok, dim=0)
y = torch.empty_like(x, dtype=torch.float16)
for i, expert in enumerate(self.experts):
y[flat_topk_idx == i] = expert(x[flat_topk_idx == i]).to(y.dtype) # 确保类型一致
y = (y.view(*topk_weight.shape, -1) * topk_weight.unsqueeze(-1)).sum(dim=1)
y = y.view(*orig_shape)
else:
# 推理模式下,只选择最优专家
y = self.moe_infer(x, flat_topk_idx, topk_weight.view(-1, 1)).view(*orig_shape)
if self.config.n_shared_experts is not None:
y = y + self.shared_experts(identity)
self.aux_loss = aux_loss
return y
@torch.no_grad()
def moe_infer(self, x, flat_expert_indices, flat_expert_weights):
expert_cache = torch.zeros_like(x)
idxs = flat_expert_indices.argsort()
tokens_per_expert = flat_expert_indices.bincount().cpu().numpy().cumsum(0)
token_idxs = idxs // self.config.num_experts_per_tok
# 例如当tokens_per_expert=[6, 15, 20, 26, 33, 38, 46, 52]
# 当token_idxs=[3, 7, 19, 21, 24, 25, 4, 5, 6, 10, 11, 12...]
# 意味着当token_idxs[:6] -> [3, 7, 19, 21, 24, 25, 4]位置的token都由专家0处理,token_idxs[6:15]位置的token都由专家1处理......
for i, end_idx in enumerate(tokens_per_expert):
start_idx = 0 if i == 0 else tokens_per_expert[i - 1]
if start_idx == end_idx:
continue
expert = self.experts[i]
exp_token_idx = token_idxs[start_idx:end_idx]
expert_tokens = x[exp_token_idx]
expert_out = expert(expert_tokens).to(expert_cache.dtype)
expert_out.mul_(flat_expert_weights[idxs[start_idx:end_idx]])
# 使用 scatter_add_ 进行 sum 操作
expert_cache.scatter_add_(0, exp_token_idx.view(-1, 1).repeat(1, x.shape[-1]), expert_out)
return expert_cache
class MiniMindBlock(nn.Module):
def __init__(self, layer_id: int, config: LMConfig):
super().__init__()
self.n_heads = config.n_heads
self.dim = config.dim
self.head_dim = config.dim // config.n_heads
self.attention = Attention(config)
self.layer_id = layer_id
self.attention_norm = RMSNorm(config.dim, eps=config.norm_eps)
self.ffn_norm = RMSNorm(config.dim, eps=config.norm_eps)
self.feed_forward = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
def forward(self, x, pos_cis, past_key_value=None, use_cache=False):
h_attn, past_kv = self.attention(
self.attention_norm(x),
pos_cis,
past_key_value=past_key_value,
use_cache=use_cache
)
h = x + h_attn
out = h + self.feed_forward(self.ffn_norm(h))
return out, past_kv
class MiniMindLM(PreTrainedModel):
config_class = LMConfig
def __init__(self, params: LMConfig = None):
self.params = params or LMConfig()
super().__init__(self.params)
self.vocab_size, self.n_layers = params.vocab_size, params.n_layers
self.tok_embeddings = nn.Embedding(params.vocab_size, params.dim)
self.dropout = nn.Dropout(params.dropout)
self.layers = nn.ModuleList([MiniMindBlock(l, params) for l in range(self.n_layers)])
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = nn.Linear(params.dim, params.vocab_size, bias=False)
self.tok_embeddings.weight = self.output.weight
self.register_buffer("pos_cis",
precompute_pos_cis(dim=params.dim // params.n_heads, theta=params.rope_theta),
persistent=False)
self.OUT = CausalLMOutputWithPast()
def forward(self,
input_ids: Optional[torch.Tensor] = None,
past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,
use_cache: bool = False,
**args):
past_key_values = past_key_values or [None] * len(self.layers)
start_pos = args.get('start_pos', 0)
h = self.dropout(self.tok_embeddings(input_ids))
# print(h.shape)
pos_cis = self.pos_cis[start_pos:start_pos + input_ids.size(1)]
past_kvs = []
for l, layer in enumerate(self.layers):
h, past_kv = layer(
h, pos_cis,
past_key_value=past_key_values[l],
use_cache=use_cache
)
past_kvs.append(past_kv)
logits = self.output(self.norm(h))
aux_loss = sum(l.feed_forward.aux_loss for l in self.layers if isinstance(l.feed_forward, MOEFeedForward))
self.OUT.__setitem__('logits', logits)
self.OUT.__setitem__('aux_loss', aux_loss)
self.OUT.__setitem__('past_key_values', past_kvs)
return self.OUT
@torch.inference_mode()
def generate(self, input_ids, eos_token_id=2, max_new_tokens=1024, temperature=0.75, top_p=0.90,
stream=False, rp=1., use_cache=True, pad_token_id=0, **args):
# 流式生成
if stream:
return self._stream(input_ids, eos_token_id, max_new_tokens, temperature, top_p, rp, use_cache, **args)
# 直接生成
generated = []
for i in range(input_ids.size(0)):
non_pad = input_ids[i][input_ids[i] != pad_token_id].unsqueeze(0)
out = self._stream(non_pad, eos_token_id, max_new_tokens, temperature, top_p, rp, use_cache, **args)
tokens_list = [tokens[:, -1:] for tokens in out]
gen = torch.cat(tokens_list, dim=-1) if tokens_list else non_pad
full_sequence = torch.cat([non_pad, gen], dim=-1)
generated.append(full_sequence)
max_length = max(seq.size(1) for seq in generated)
generated = [
torch.cat(
[seq, torch.full((1, max_length - seq.size(1)), pad_token_id, dtype=seq.dtype, device=seq.device)],
dim=-1)
for seq in generated
]
return torch.cat(generated, dim=0)
def _stream(self, input_ids, eos_token_id, max_new_tokens, temperature, top_p, rp, use_cache, **args):
start, first_seq, past_kvs = input_ids.shape[1], True, None
while input_ids.shape[1] < max_new_tokens - 1:
if first_seq or not use_cache:
out, first_seq = self(input_ids, past_key_values=past_kvs, use_cache=use_cache, **args), False
else:
out = self(input_ids[:, -1:], past_key_values=past_kvs, use_cache=use_cache,
start_pos=input_ids.shape[1] - 1, **args)
logits, past_kvs = out.logits[:, -1, :], out.past_key_values
logits[:, list(set(input_ids.tolist()[0]))] /= rp
logits /= (temperature + 1e-9)
if top_p is not None and top_p < 1.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True, dim=-1)
sorted_probs = F.softmax(sorted_logits, dim=-1)
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
sorted_indices_to_remove = cumulative_probs > top_p
sorted_indices_to_remove[:, 1:] = sorted_indices_to_remove[:, :-1].clone()
sorted_indices_to_remove[:, 0] = False
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
logits[indices_to_remove] = -float('Inf')
input_ids_next = torch.multinomial(F.softmax(logits, dim=-1), num_samples=1)
input_ids = torch.cat((input_ids, input_ids_next), dim=1)
yield input_ids[:, start:]
if input_ids_next.item() == eos_token_id:
break
Class MiniMindLM forward:
def forward(self,
input_ids: Optional[torch.Tensor] = None,
past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,
use_cache: bool = False,
**args):
# 1
past_key_values = past_key_values or [None] * len(self.layers)
# 2
start_pos = args.get('start_pos', 0)
# 3
h = self.dropout(self.tok_embeddings(input_ids))
# 4
pos_cis = self.pos_cis[start_pos:start_pos + input_ids.size(1)]
# 5
past_kvs = []
# 6
for l, layer in enumerate(self.layers):
# 6.1
h, past_kv = layer(
h, pos_cis,
past_key_value=past_key_values[l],
use_cache=use_cache
)
past_kvs.append(past_kv)
# 7
logits = self.output(self.norm(h))
# 8
aux_loss = sum(l.feed_forward.aux_loss for l in self.layers if isinstance(l.feed_forward, MOEFeedForward))
self.OUT.__setitem__('logits', logits)
self.OUT.__setitem__('aux_loss', aux_loss)
self.OUT.__setitem__('past_key_values', past_kvs)
return self.OUT
- 1——past_key_values是缓存的历史上下文token在每一个transformer模块中的K_V张量,减少重复运算,用于提高运算速度;
- 2——start_pos是位置编码的开始索引,这里使用的是旋转位置编码;
- 3——通过self.tok_embeddings层将tokenID转换为高维语义张量;self.tok_embeddings层属于pytorch的标准层nn.Embedding,是 PyTorch 中的一个模块,用于将离散的索引(通常是整数)映射到连续的向量空间中;self.dropout层只在训练阶段会使用,防止过拟合,推理阶段默认不起作用;
4——pos_cis是存放在缓冲区的一种预计算的位置编码,具体编码详情请看2.2.1;
5——实例化一个列表past_kvs,存放past_key_values;
6——self.layers是一个迭代器,里面存放了8个transformer模块,遍历这个迭代器;
6.1——向单个transformer模块传入语义张量和位置编码张量,返回运算后的语义张量和K_Vcache缓存,transformer模块具体编码详情请看2.2.2;
7——self.output是一个全链接层,将语义张量维度由dim的512转换为词汇表的6400;
8——
aux_loss是 MoE 模型在训练过程中用于解决专家负载不均衡问题的关键机制。它通过正则化手段惩罚不均匀的专家激活分布,从而提升模型的稳定性和性能;
2.2.1 位置编码API-precompute_pos_cis
def precompute_pos_cis(dim: int, end: int = int(32 * 1024), theta: float = 1e6):
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # type: ignore
freqs = torch.outer(t, freqs).float() # type: ignore
pos_cis = torch.polar(torch.ones_like(freqs), freqs) # complex64
return pos_cis
这个函数的核心目的是:
- 根据给定的维度
dim和最大长度end,生成一组复数形式的位置编码。- 这些位置编码是基于正弦和余弦波的频率计算的,具体来说:
- 每个时间步长对应一组复数。
- 每个复数的模长为 1,相位角由频率决定。
- 返回的结果可以用于注意力机制(如 Rotary Positional Encoding, RoPE),以引入位置信息。
具体实现:
- 函数参数:dim——表示位置编码的维度;
end——表示需要生成的位置编码的最大长度(默认值为 32 * 1024 = 32768,即支持最长 32768 的序列长度);
theta——控制频率的缩放因子,默认值为 1e6。它影响正弦和余弦波的周期;freqs——是一个形状为(dim // 2,)的张量 ,表示不同频率的正弦和余弦波;- t——生成一个从 0 到
end-1的整数序列,是一个形状为(end,)的张量t,表示不同的时间步长;freqs——计算外积,是一个形状为(end, dim // 2)的张量 ,表示每个时间步长在不同频率下的值;pos_cis——根据极坐标形式生成复数,第一个参数是模长,第二个参数是相位角,返回是一个形状为(end, dim // 2)的复数张量 ,表示每个时间步长对应的复数形式的位置编码;
2.2.2 transformer模块-MiniMindBlock
# Transformer结构层
class MiniMindBlock(nn.Module):
def __init__(self, layer_id: int, config: LMConfig):
super().__init__()
self.n_heads = config.n_heads
self.dim = config.dim
self.head_dim = config.dim // config.n_heads
self.attention = Attention(config)
self.layer_id = layer_id
self.attention_norm = RMSNorm(config.dim, eps=config.norm_eps)
self.ffn_norm = RMSNorm(config.dim, eps=config.norm_eps)
self.feed_forward = FeedForward(config) if not config.use_moe else MOEFeedForward(config)
def forward(self, x, pos_cis, past_key_value=None, use_cache=False):
# 1
h_attn, past_kv = self.attention(
# 1.1
self.attention_norm(x),
pos_cis,
past_key_value=past_key_value,
use_cache=use_cache
)
# 2
h = x + h_attn
# 3
out = h + self.feed_forward(self.ffn_norm(h))
return out, past_kvClass MiniMindBlock forward:
推理函数(forward)接收来自词嵌入层或者上一个transformer模块输出的语义张量、位置编码信息和K_Vcache缓存;
- 1——self.attention是自定义实现的一个自注意力层,接收归一化层self.attention_norm的输出、位置编码和历史K_Vcache;关于自定义的自注意力层的详细信息请看2.2.2.1;
- 1.1——self.attention_norm是一种和BN、LN一样的归一化技术,叫做RMSNorm,即均方根归一化,用于神经网络中的归一化,详细信息请看2.2.2.2;
- 2——将输入的语义张量x与自注意力的输出进行加和操作,实现了一个残差结构;
- 3——将残差后的输出在此进行归一化操作,将归一化的输出送入自定义的FFN层(因为我们看的是MoE模型结构,所以这个self.feed_forward是MoE层),同时将FFN输出在此与进入归一化前的张量进行残差连接后再输出;关于自定义FFN层的详细信息请看2.2.2.3;
2.2.2.1 自注意力模块-Attention
# 自注意力机制层
class Attention(nn.Module):
def __init__(self, args: LMConfig):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
assert args.n_heads % self.n_kv_heads == 0
self.n_local_heads = args.n_heads
self.n_local_kv_heads = self.n_kv_heads
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = nn.Linear(args.dim, args.n_heads * self.head_dim, bias=False)
self.wk = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wv = nn.Linear(args.dim, self.n_kv_heads * self.head_dim, bias=False)
self.wo = nn.Linear(args.n_heads * self.head_dim, args.dim, bias=False)
self.attn_dropout = nn.Dropout(args.dropout)
self.resid_dropout = nn.Dropout(args.dropout)
self.dropout = args.dropout
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention') and args.flash_attn
# print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
mask = torch.full((1, 1, args.max_seq_len, args.max_seq_len), float("-inf"))
mask = torch.triu(mask, diagonal=1)
self.register_buffer("mask", mask, persistent=False)
def forward(self,
x: torch.Tensor,
pos_cis: torch.Tensor,
past_key_value: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
use_cache=False):
# 1
bsz, seq_len, _ = x.shape
# 2
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
# 3
xq = xq.view(bsz, seq_len, self.n_local_heads, self.head_dim)
# 4
xk = xk.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
# 5
xv = xv.view(bsz, seq_len, self.n_local_kv_heads, self.head_dim)
# 6
xq, xk = apply_rotary_emb(xq, xk, pos_cis)
# kv_cache实现
# 7
if past_key_value is not None:
# 7.1
xk = torch.cat([past_key_value[0], xk], dim=1)
# 7.2
xv = torch.cat([past_key_value[1], xv], dim=1)
# 8
past_kv = (xk, xv) if use_cache else None
# 9
xq, xk, xv = (
xq.transpose(1, 2),
repeat_kv(xk, self.n_rep).transpose(1, 2),
repeat_kv(xv, self.n_rep).transpose(1, 2)
)
# 10
if self.flash and seq_len != 1:
# 10.1
dropout_p = self.dropout if self.training else 0.0
# 10.2
output = F.scaled_dot_product_attention(
xq, xk, xv,
attn_mask=None,
dropout_p=dropout_p,
is_causal=True
)
else:
# 10.3
scores = (xq @ xk.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 10.4
scores += self.mask[:, :, :seq_len, :seq_len]
# 10.5
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
# 10.6
scores = self.attn_dropout(scores)
# 10.7
output = scores @ xv
# 11
output = output.transpose(1, 2).reshape(bsz, seq_len, -1)
# 12
output = self.resid_dropout(self.wo(output))
return output, past_kvClass Attention forward:
这个模块就是展开的自注意力机制的数据处理流程及具体的计算过程:
- 1——获取输入张量的batch_size维度和token序列维度的数量;
- 2——self.wq, self.wk, self.wv分别是转换token为Q、K、V的权重层,通过上面的定义可以看到它们都是全链接层,不同的是它们的尺寸;
- 2.1——self.wq:在其定义中args.dim是每个token张量的维度,这里是512;args.n_heads是定义的Query自注意力的头数,这里是8个头;self.head_dim是每个头的token张量的维度,是由args.dim/args.n_heads得到,其值为64,所以self.wq还是一个512*512的权重矩阵,得到的xq大小为(1,seq_len,512);
- 2.2——self.wk:在其定义中args.dim是每个token张量的维度,这里是512;self.n_kv_heads是定义的Key自注意力的头数,这里是2个头;self.head_dim同上,所以self.wk是一个512*128的权重矩阵,得到的xk大小为(1,seq_len,128);
- 2.3——self.wv:同self.wk,得到的xv大小为(1,seq_len,128);
- 3——将xq最后一维按照定义头数进行切分,维度变为(1,seq_len,8,64);
- 4——将xk最后一维按照定义头数进行切分,维度变为(1,seq_len,2,64);
- 5——同xk,xv维度变为(1,seq_len,2,64);
- 6——通过apply_rotary_emb()API将位置编码信息嵌入到Q、K向量上,返回包含位置信息的Q、K张量;详细的apply_rotary_emb信息请看2.2.2.1.1;
- 7——将新的预测的token张量生成的的K、V张量进行K_VCache保存;
- 7.1——如果不是第一轮预测,则会有缓存的之前的K_VCache张量,只需要将新的K张量添加到对应的transformer层的注意力层即可,注意是在序列的维度上进行拼接;
- 7.2——同7.1拼接V张量;
- 8——如果是第一轮的推理,那K_VCache缓存为空,这时直接添加即可,得到的past_kv就是K_VCache缓存的变量;
- 9——通过维度变化操作将Q、K、V的维度进行变换,方便后续的矩阵运算,这里对Q张量的序列维度和头数维度进行了交换,有(1, seq_len, 8, 64)变为(1, 8, seq_len, 64);对K、V张量进行与Q维度的填充对其以及维度的交换;具体对K、V填充的处理过程请看2.2.2.1.2;
- 10——
flash-attn是一种优化技术,旨在加速 Transformer 模型中的自注意力机制;当开启flash-attn并且输入序列长度大于1时启用;10.1——dropout是训练阶段用于防治过拟合的一种操作,这里判断是否为训练阶段决定是否启用dropout_p;- 10.2——
F.scaled_dot_product_attention()是 PyTorch 中的一个函数,用于实现缩放点积注意力,它简化了注意力机制的实现,同时提供了灵活性和高性能;- 10.3——如果不启用
flash-attn,或者输入序列为1的话,对Q、K张量进行点积运算;这里先将K张量的倒数两维进行了交换,然后同Q张量进行矩阵运算,计算结果再除以每个头的最后一个维度,即64;10.4——self.mask是一个上三角遮罩;当输入序列为1时不起作用,当输入序列大于1时,里面会包含已生成的token,这样在重新计算Q、K关注度的时候,之前的token也会对它后面的token计算出一个关注度值,但是在之前这些token生成的时候是没有后面这些token影响的,所以对于序列中比较靠前的token来讲,它后面的token就是未来token,需要通过一个上三角遮罩将前token对后token的关注度调整为负无穷,这样就达到其不受未来token影响的效果了;- 10.5——对掩码遮罩后的输出在最后一个维度计算softmax,获得当前token对每个token的关注度权重;
- 10.6——训练阶段会通过Dropout层随机丢弃一些概率防止过拟合;
- 10.7——将包含概率关注度的张量通过矩阵运算加权作用到V张量上,得到新的token张量;
- 11——还原输出新的token张量的维度到输入transformer模块之前的维度;
- 12——self.wo是一个全链接层,通过该层将多个头的拼接结果进行映射,因为self.wo与wq维度一致,所以输出维度不会发生变化,依然是(1,seq_len,512);
2.2.2.1.1 位置编码嵌入API-apply_rotary_emb
def apply_rotary_emb(xq, xk, pos_cis):
def unite_shape(pos_cis, x):
ndim = x.ndim
assert 0 <= 1 < ndim
assert pos_cis.shape == (x.shape[1], x.shape[-1])
shape = [d if i == 1 or i == ndim - 1 else 1 for i, d in enumerate(x.shape)]
return pos_cis.view(*shape)
# 1
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
# 2
pos_cis = unite_shape(pos_cis, xq_)
# 3
xq_out = torch.view_as_real(xq_ * pos_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * pos_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
- 函数接收token张量对应的Q、K张量和位置编码张量;
- 1——将实数张量(
xq、xk)转换为复数张量;- 2——
unite_shape函数的作用是将pos_cis调整为与xq_兼容的形状,以便通过广播机制进行位置编码嵌入;- 3——将复数张量xq_与位置编码
pos_cis相乘后,转为实数张量;
2.2.2.1.2 维度对齐API-repeat_kv
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)在前面的超参中,Q的头有8个,K、V的头只有2个,所以在做Q、K点积运算的时候就会因为维度不匹配而无法计算,需要进行维度变换;
变换的思路也非常简单,就是将Q的头均分成与K、V头相同的组数,即每4个Q头共享一个K、V头;
所以该函数就是将K、V张量在倒数第二维度进行复制,复制4份,使得复制后的K、V张量的维度与Q张量保持一致;
2.2.2.2 归一化模块-RMSNorm
# 归一化层
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
# 2
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
# 1
return self.weight * self._norm(x.float()).type_as(x)
Class RMSNorm forward:
RMSNorm(Root Mean Square Normalization)是一种归一化技术,旨在提高神经网络训练的稳定性和效率。它与更常见的 LayerNorm(层归一化)相似,但计算上更为简单和高效;
具体计算流程是对输入的张量计算元素平方的均值,加上一个很小的数值,防止分母为零,再对结果开根号,最后用张量中的元素除以这个标量,可训练参数作用在RMSNorm函数最外侧;
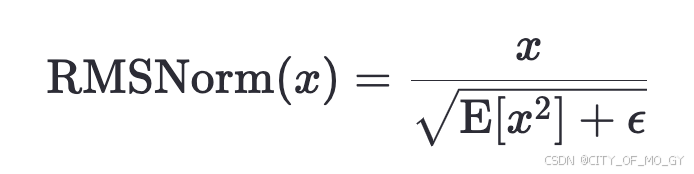
2.2.2.3 MoE前馈神经层-MOEFeedForward
# MoE层
class MOEFeedForward(nn.Module):
def __init__(self, config: LMConfig):
super().__init__()
self.config = config
self.experts = nn.ModuleList([
FeedForward(config)
for _ in range(config.n_routed_experts)
])
self.gate = MoEGate(config)
if config.n_shared_experts is not None:
self.shared_experts = FeedForward(config)
def forward(self, x):
# 1
identity = x
orig_shape = x.shape
bsz, seq_len, _ = x.shape
# 使用门控机制选择专家
# 2
topk_idx, topk_weight, aux_loss = self.gate(x)
# 3
x = x.view(-1, x.shape[-1])
# 4
flat_topk_idx = topk_idx.view(-1)
# 5
if self.training:
# 训练模式下,重复输入数据
# 5.1
x = x.repeat_interleave(self.config.num_experts_per_tok, dim=0)
# 5.2
y = torch.empty_like(x, dtype=torch.float16)
# 5.3
for i, expert in enumerate(self.experts):
y[flat_topk_idx == i] = expert(x[flat_topk_idx == i]).to(y.dtype) # 确保类型一致
# 5.4
y = (y.view(*topk_weight.shape, -1) * topk_weight.unsqueeze(-1)).sum(dim=1)
# 5.5
y = y.view(*orig_shape)
# 6
else:
# 推理模式下,只选择最优专家
y = self.moe_infer(x, flat_topk_idx, topk_weight.view(-1, 1)).view(*orig_shape)
# 7
if self.config.n_shared_experts is not None:
y = y + self.shared_experts(identity)
# 8
self.aux_loss = aux_loss
return y
@torch.no_grad()
def moe_infer(self, x, flat_expert_indices, flat_expert_weights):
# 6.1
expert_cache = torch.zeros_like(x)
# 6.2
idxs = flat_expert_indices.argsort()
# 6.3
tokens_per_expert = flat_expert_indices.bincount().cpu().numpy().cumsum(0)
# 6.4
token_idxs = idxs // self.config.num_experts_per_tok
# 例如当tokens_per_expert=[6, 15, 20, 26, 33, 38, 46, 52]
# 当token_idxs=[3, 7, 19, 21, 24, 25, 4, 5, 6, 10, 11, 12...]
# 意味着当token_idxs[:6] -> [3, 7, 19, 21, 24, 25, 4]位置的token都由专家0处理,token_idxs[6:15]位置的token都由专家1处理......
# 6.5
for i, end_idx in enumerate(tokens_per_expert):
# 6.6
start_idx = 0 if i == 0 else tokens_per_expert[i - 1]
# 6.7
if start_idx == end_idx:
continue
# 6.8
expert = self.experts[i]
# 6.9
exp_token_idx = token_idxs[start_idx:end_idx]
# 6.10
expert_tokens = x[exp_token_idx]
# 6.11
expert_out = expert(expert_tokens).to(expert_cache.dtype)
# 6.12
expert_out.mul_(flat_expert_weights[idxs[start_idx:end_idx]])
# 使用 scatter_add_ 进行 sum 操作
# 6.13
expert_cache.scatter_add_(0, exp_token_idx.view(-1, 1).repeat(1, x.shape[-1]), expert_out)
return expert_cacheClass MOEFeedForward forward:
- 1——identity用于共享专家FFN层的输入;orig_shape是输出张量的尺寸元组;
- 2——topk_idx, topk_weight, aux_loss分别是每个token序列的前k个专家索引(这里k=2),以及对应的置信度,训练阶段用于专家负载均衡的loss值,关于门控网络的详细信息可以查看2.2.2.3.1;
- 3——将输入张量的batch维和seq_len维合并降维,变为(bs*seq_len, dim);
- 4——将门控网络输出的前k个索引也降维,变为(bs*seq_len*k,);
- 5——如果是训练阶段,要将推荐的前k个专家都进行运算,算一个加权输出;
- 5.1——将输入张量x(bs*seq_len, dim)沿第一个维度复制k=2个,变为(bs*seq_len*k, dim);
- 5.2——
torch.empty_like()是一个高效的函数,用于快速分配一个与输入张量形状和数据类型相同的张量;这里的y的尺寸为(bs*seq_len*k, dim);- 5.3——self.experts是一个迭代器,里面包含n_routed_experts=4个门控专家FFN层,遍历这个迭代器,选出门控网络推荐的前k个门控专家进行运算,获取前k个专家的输出;关于前馈神经网络FFN的详细信息请看2.2.2.3.2;
- 5.4——将前k个专家的输出结果按照对应的权重加权求和;
- 5.5——将合并后的专家输出结果张量的尺寸还原为(bs,seq_len, dim);
- 6——如果是推理阶段,调用moe_infer函数,返回结果还原为(bs,seq_len, dim)张量输出;
- 6.0——moe_infer函数的主要目标是:
- 根据
flat_expert_indices将输入张量x分配给不同的专家网络。- 使用对应的专家权重
flat_expert_weights对专家输出进行加权。- 将所有专家的输出汇总到一个缓存张量
expert_cache中,确保每个 token 的最终输出是多个专家输出的加权和。- 7——如果设置了共享专家的话,单独运行共享专家推理,并将输出结果与门控专家输出结果加和输出;
2.2.2.3.1 门控网络-MoEGate
class MoEGate(nn.Module):
def __init__(self, config: LMConfig):
super().__init__()
self.config = config
self.top_k = config.num_experts_per_tok
self.n_routed_experts = config.n_routed_experts
self.scoring_func = config.scoring_func
self.alpha = config.aux_loss_alpha
self.seq_aux = config.seq_aux
self.norm_topk_prob = config.norm_topk_prob
self.gating_dim = config.dim
self.weight = nn.Parameter(torch.empty((self.n_routed_experts, self.gating_dim)))
self.reset_parameters()
def reset_parameters(self) -> None:
import torch.nn.init as init
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
def forward(self, hidden_states):
# 1
bsz, seq_len, h = hidden_states.shape
# 2
hidden_states = hidden_states.view(-1, h)
# 3
logits = F.linear(hidden_states, self.weight, None)
# 4
if self.scoring_func == 'softmax':
scores = logits.softmax(dim=-1)
# 5
else:
raise NotImplementedError(f'insupportable scoring function for MoE gating: {self.scoring_func}')
# 6
topk_weight, topk_idx = torch.topk(scores, k=self.top_k, dim=-1, sorted=False)
# 7
if self.top_k > 1 and self.norm_topk_prob:
# 7.1
denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
# 7.2
topk_weight = topk_weight / denominator
# 8
if self.training and self.alpha > 0.0:
# 8.1
scores_for_aux = scores
# 8.2
aux_topk = self.top_k
# 8.3
topk_idx_for_aux_loss = topk_idx.view(bsz, -1)
# 8.4
if self.seq_aux:
# 8.4.1
scores_for_seq_aux = scores_for_aux.view(bsz, seq_len, -1)
# 8.4.2
ce = torch.zeros(bsz, self.n_routed_experts, device=hidden_states.device)
# 8.4.3
ce.scatter_add_(1, topk_idx_for_aux_loss,
torch.ones(bsz, seq_len * aux_topk, device=hidden_states.device)).div_(
seq_len * aux_topk / self.n_routed_experts)
# 8.4.4
aux_loss = (ce * scores_for_seq_aux.mean(dim=1)).sum(dim=1).mean() * self.alpha
# 8.5
else:
# 8.5.1
mask_ce = F.one_hot(topk_idx_for_aux_loss.view(-1), num_classes=self.n_routed_experts)
# 8.5.2
ce = mask_ce.float().mean(0)
# 8.5.3
Pi = scores_for_aux.mean(0)
# 8.5.4
fi = ce * self.n_routed_experts
# 8.5.5
aux_loss = (Pi * fi).sum() * self.alpha
# 9
else:
aux_loss = 0
return topk_idx, topk_weight, aux_lossClass MoEGate forward:
从网络的定义中我们可以看到,整个网络就只有一个可训练的全链接层,用于根据token信息给各门控专家分配任务;该函数主要的目标就是将token语义张量分配给符合的前k个门控专家,返回top_k个门控专家的索引以及对该门控专家的置信度;
- 需要留意的是该可训练的全链接层的输入必须与dim一致,输出必须和门控专家的数量一致;
- 在门控网络的训练阶段,模型会通过统计每个专家被调用的频率来计算损失函数,通过对aux_loss的计算确保模型在训练阶段输入 token 被分配到不同的专家时,能够尽量均匀分布,避免某些专家过载而其他专家闲置;
- 还有一个在训练阶段会用的的超参数aux_loss_alpha,是为了在总的loss函数中调节aux_loss辅助损失的权重,从而调整aux_loss在总的loss中的影响效果;
2.2.2.3.2 前馈神经网络-FeedForward
class FeedForward(nn.Module):
def __init__(self, config: LMConfig):
super().__init__()
if config.hidden_dim is None:
hidden_dim = 4 * config.dim
hidden_dim = int(2 * hidden_dim / 3)
config.hidden_dim = config.multiple_of * ((hidden_dim + config.multiple_of - 1) // config.multiple_of)
self.w1 = nn.Linear(config.dim, config.hidden_dim, bias=False)
self.w2 = nn.Linear(config.hidden_dim, config.dim, bias=False)
self.w3 = nn.Linear(config.dim, config.hidden_dim, bias=False)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
return self.dropout(self.w2(F.silu(self.w1(x)) * self.w3(x)))
这个前馈神经网络定义的比较简单,我们可以直观的看到它是由三个全链接层组成;先进过w3,同时经过w1,w1的输出再经过一个激活函数送入w2, 将w3和w2层的输出结果相乘的到输出张量;
三、总结
该博客通过对MoE架构的MinimindLM大模型的模型结构分析,明确了MoE架构的工作流程以及和传统Dense模型的区别,并且详细展示了数据张量在不同模块之间的各种变换;如果该博客的内容有错误之处还请不吝指正,如果该博客有帮助到你也请不吝给一个关注,我会持续更新,继续探索基于代码解读的模型预训练、全量微调、lora微调、强化学习、模型蒸馏等技术,谢谢~

















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









