






目录
Numpy实验
- 实验目的
Numpy库,了解什么是numpy,学习numpy的基础、常用方法及常用统计方法。
- 实验要求
- 使用numpy完成基本的数据创建与处理。
- 完成练习,撰写实验报告。
- 实验内容
使用macrodate.csv文件进行统计
- 实验代码
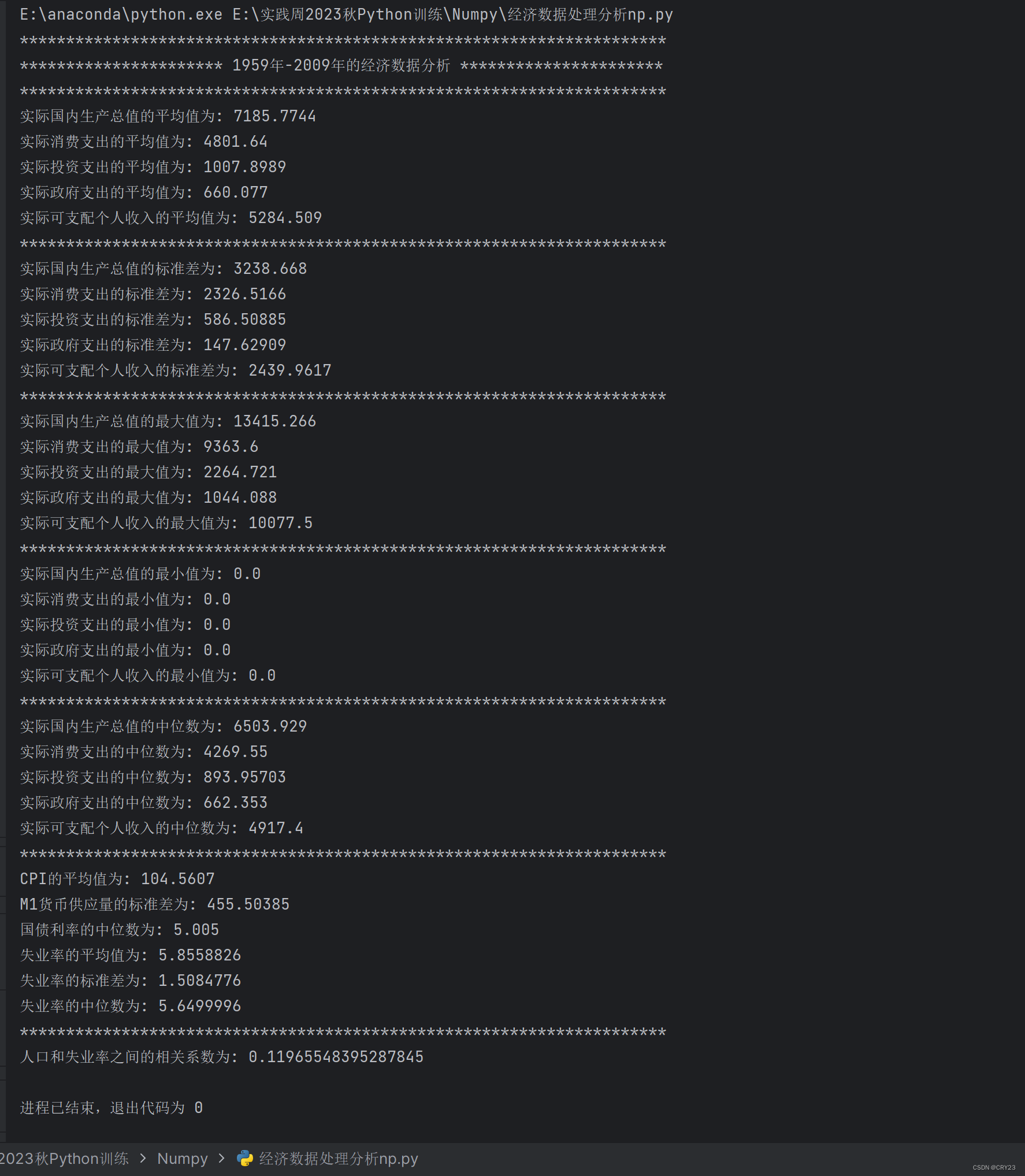
import numpy as np data = np.genfromtxt('../macrodata.csv', delimiter=',', dtype=np.float32, filling_values=0) print('*'*70) print('*'*22,'1959年-2009年的经济数据分析','*'*22) print('*'*70) # 计算第三至七列的平均值,得到1959年-2009年以下平均值: mean1 = np.mean(data[:, 2]) print('实际国内生产总值的平均值为:', mean1) mean2 = np.mean(data[:, 3]) print('实际消费支出的平均值为:', mean2) mean3 = np.mean(data[:, 4]) print('实际投资支出的平均值为:', mean3) mean4 = np.mean(data[:, 5]) print('实际政府支出的平均值为:', mean4) mean5 = np.mean(data[:, 6]) print('实际可支配个人收入的平均值为:', mean5) print('*'*70) # 计算第三至七列的标准差,得到1959年-2009年以下标准差: std1 = np.std(data[:, 2]) print('实际国内生产总值的标准差为:', std1) std2 = np.std(data[:, 3]) print('实际消费支出的标准差为:', std2) std3 = np.std(data[:, 4]) print('实际投资支出的标准差为:', std3) std4 = np.std(data[:, 5]) print('实际政府支出的标准差为:', std4) std5 = np.std(data[:, 6]) print('实际可支配个人收入的标准差为:', std5) print('*'*70) # 计算第三至七列的最大值,得到1959年-2009年以来最大值: max_value1 = np.max(data[:, 2]) print('实际国内生产总值的最大值为:', max_value1) max_value2 = np.max(data[:, 3]) print('实际消费支出的最大值为:', max_value2) max_value3= np.max(data[:, 4]) print('实际投资支出的最大值为:', max_value3) max_value4 = np.max(data[:, 5]) print('实际政府支出的最大值为:', max_value4) max_value5 = np.max(data[:, 6]) print('实际可支配个人收入的最大值为:', max_value5) print('*'*70) # 计算第三至七列的最小值,得到1959年-2009年以来最小值: min_value1 = np.min(data[:, 2]) print('实际国内生产总值的最小值为:', min_value1) min_value2 = np.min(data[:, 3]) print('实际消费支出的最小值为:', min_value2) min_value3= np.min(data[:, 4]) print('实际投资支出的最小值为:', min_value3) min_value4 = np.min(data[:, 5]) print('实际政府支出的最小值为:', min_value4) min_value5 = np.min(data[:, 6]) print('实际可支配个人收入的最小值为:', min_value5) print('*'*70) # 计算第三至七列的中位数,得到1959年-2009年以下中位数: median1 = np.median(data[:, 2]) print('实际国内生产总值的中位数为:', median1) median2 = np.median(data[:, 3]) print('实际消费支出的中位数为:', median2) median3 = np.median(data[:, 4]) print('实际投资支出的中位数为:', median3) median4 = np.median(data[:, 5]) print('实际政府支出的中位数为:', median4) median5 = np.median(data[:, 6]) print('实际可支配个人收入的中位数为:', median5) print('*'*70) # 计算CPI的平均值 cpi_mean = np.mean(data[:, 7]) print('CPI的平均值为:', cpi_mean) # 计算M1货币供应量的标准差 m1_std = np.std(data[:, 8]) print('M1货币供应量的标准差为:', m1_std) # 计算国债利率的中位数 tbilrate_median = np.median(data[:, 9]) print('国债利率的中位数为:', tbilrate_median) # 计算失业率的平均值、标准差和中位数 unemp_mean = np.mean(data[:, 10]) unemp_std = np.std(data[:, 10]) unemp_median = np.median(data[:, 10]) print('失业率的平均值为:', unemp_mean) print('失业率的标准差为:', unemp_std) print('失业率的中位数为:', unemp_median) print('*'*70) # 计算人口和失业率之间的相关系数 corr = np.corrcoef(data[:, 11], data[:, 10]) print('人口和失业率之间的相关系数为:', corr[0, 1])
- 运行结果
- 实验体会
(如:实验遇到的问题及解决办法)
问题:
- 数据一开始使用科学计数法显示
- 导入数据后文字格里出现nan
解决方案:
- 使用:np.set_printoptions(suppress=True) # 禁用科学计数法 及dtype=np.float32修改代码
- 使用:filling_values=0填充丢失的数据
Pandas实验
- 实验目的
Pandas库,了解什么是Pandas,学习pandas的常用数据类型(Series一维、DataFrame二维)等。
- 实验要求
- 使用Series、DataFrame,完成基本的数据创建与处理。
- 完成练习,撰写实验报告。
- 实验内容
使用macrodate.csv文件进行基本操作及统计分析
- 实验代码
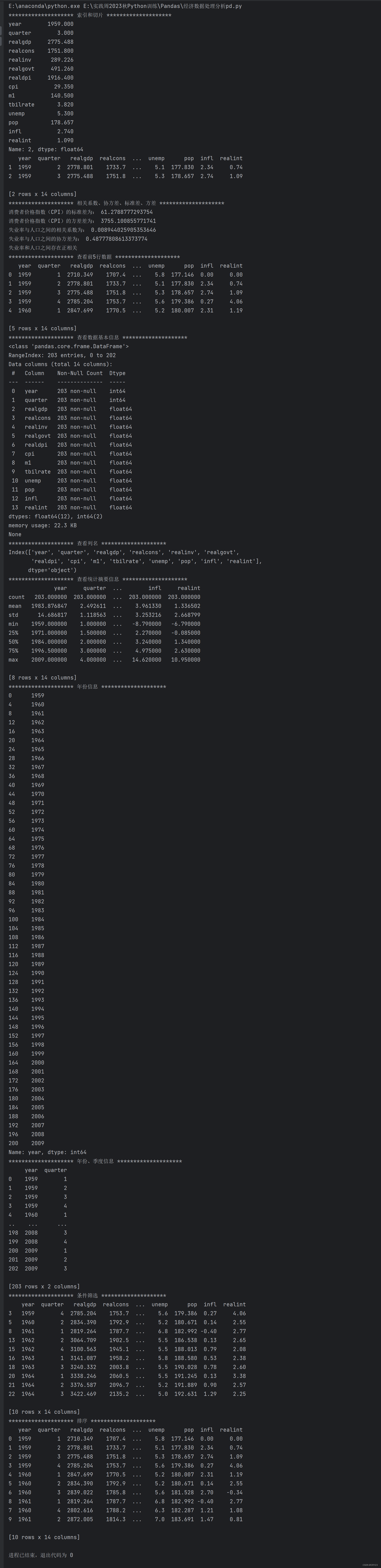
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_csv('../macrodata.csv')
# 填充缺失值
data.fillna(0)
print('*'*20,'索引和切片','*'*20)
# 按标签索引
data2 = data.loc[2] # 返回第3行的数据
print(data2)
# 按位置索引
data23 = data.iloc[1:3] # 返回第2行和第3行的数据
print(data23)
print('*'*20,'相关系数、协方差、标准差、方差','*'*20)
# 计算标准差
std = data['cpi'].std()
print('消费者价格指数(CPI)的标准差为:',std)
# 计算方差
var = data['cpi'].var()
print('消费者价格指数(CPI)的方差差为:',var)
# 计算相关系数
corr = data['unemp'].corr(data['pop'])
print('失业率与人口之间的相关系数为:',corr)
# 计算协方差
cov = data['unemp'].cov(data['pop'])
print('失业率与人口之间的协方差为:',cov)
# 判断相关性
if cov > 0:
print("失业率和人口之间存在正相关")
elif cov < 0:
print("失业率和人口之间存在负相关")
else:
print("失业率和人口之间不存在线性关系")
print('*'*20,'查看前5行数据','*'*20)
print(data.head())
print('*'*20,'查看数据基本信息','*'*20)
print(data.info())
print('*'*20,'查看列名','*'*20)
print(data.columns)
print('*'*20,'查看统计摘要信息','*'*20)
print(data.describe())
print('*'*20,'年份信息','*'*20)
col_1 = data['year'] # 获取一列,用一维数据
data_1 = np.array(col_1)
data_1_unique = col_1.drop_duplicates() # 去重一维数据
print(data_1_unique)
print('*'*20,'年份、季度信息','*'*20)
col_2 = data[['year','quarter']] # 获取两列,要用二维数据
data_2 = np.array(col_2)
data_2_unique = col_2.drop_duplicates() # 去重二维数据
print(data_2_unique)
print('*'*20,'条件筛选','*'*20)
data_3 = data[data['realint'] > 2]
print(data_3.head(10)) # 筛选实际利率(realint)列大于2.0的前十行
print('*'*20,'排序','*'*20)
data_4 = data.sort_values(by='cpi')
print(data_4.head(10)) # 按照消费者物价指数(cpi)列进行排序后的DataFrame的前10行数据- 运行结果
- 实验体会
(如:实验遇到的问题及解决办法)
问题: 无
解决方案:无
相对Numpy,Pandas操作比Numpy清晰,简单得多;Pandas在导入数据、处理数据和操作数据方面提供了更为简单和清晰的方法
- 导入数据:Pandas提供了read_csv()、read_excel()等函数,可以直接从文件中读取数据,并将其转换为DataFrame对象。这些函数具有灵活的参数设置,可以自动处理各种数据格式和缺失值。
- 数据结构:Pandas的核心数据结构是DataFrame,它是一个二维表格,每列可以是不同的数据类型。DataFrame提供了各种操作和方法,使得数据处理更加方便。
- 数据选择和过滤:Pandas使用标签索引而不是传统的数字索引,这使得数据选择和过滤更加直观和清晰。可以使用列标签或条件表达式来选择特定的行和列,还可以通过逻辑运算符组合多个条件。
- 缺失值处理:Pandas内置了处理缺失值的方法,例如dropna()函数可以删除包含缺失值的行或列,fillna()函数可以用指定的值填充缺失值。
- 数据操作:除了基本的数学运算,Pandas还提供了许多用于数据操作和转换的函数,例如排序、合并、分组、聚合等。这些函数易于使用且功能强大,能够帮助我们快速完成常见的数据处理任务。
数据可视化实验
- 实验目的
掌握基本图像绘制,学会使用python的函数库绘制图像,初步掌握matplotlib的使用。
- 实验要求
1.使用完成基本的数据图像绘制任务。
2.完成练习,撰写实验报告。
- 实验内容
使用macrodate.csv文件进行统计分析之后绘画图表
- 实验代码1
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('../macrodata.csv')
plt.rcParams['axes.unicode_minus'] = False #解决坐标轴刻度负号乱码
plt.rcParams['font.family'] = 'SimHei' # 设置中文字体为黑体
# 提取所需的列数据
year = np.array(data['year'].values)
realgdp = np.array(data['realgdp'].values) # 实际国内生产总值
realcons = np.array(data['realcons'].values) # 实际个人消费支出
realgovt = np.array(data['realgovt'].values) # 实际政府支出
realdpi = np.array(data['realdpi'].values) # 实际可支配个人收入
# 创建包含四个子图的画布
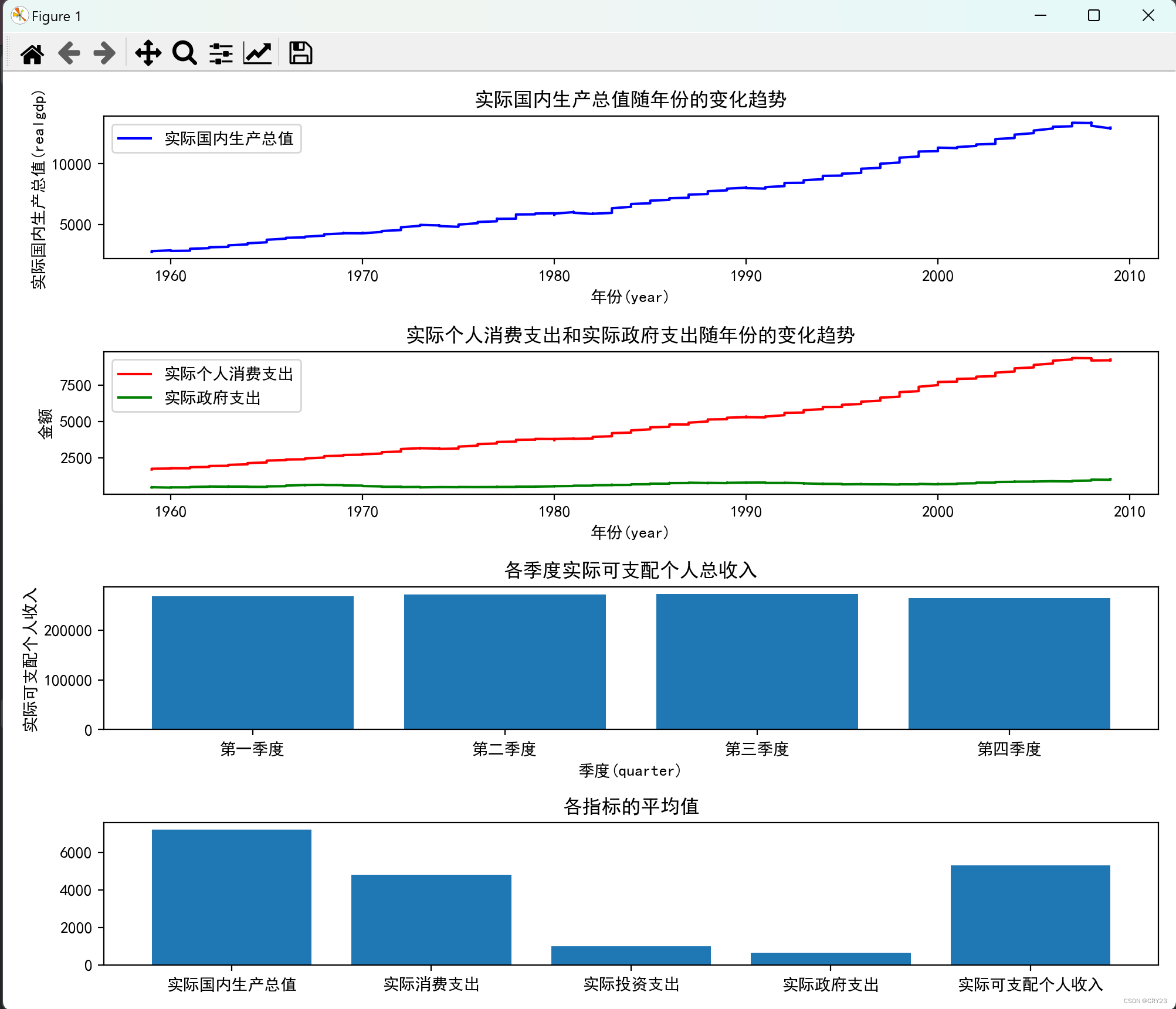
fig, ax = plt.subplots(4, 1, figsize=(10, 8))
# 绘制实际国内生产总值(realgdp)随年份的变化趋势
ax[0].plot(year, realgdp, 'b-', label='实际国内生产总值')
ax[0].set_xlabel('年份(year)') #添加x轴名称
ax[0].set_ylabel('实际国内生产总值(realgdp)') #设置y轴名称
ax[0].set_title('实际国内生产总值随年份的变化趋势') #设置标题
ax[0].legend(loc='upper left') # 将图例放置在左上角
# 绘制实际个人消费支出(realcons)和实际政府支出(realgovt)随年份的变化趋势
ax[1].plot(year, realcons, 'r-', label='实际个人消费支出')
ax[1].plot(year, realgovt, 'g-', label='实际政府支出')
ax[1].set_xlabel('年份(year)')
ax[1].set_ylabel('金额')
ax[1].set_title('实际个人消费支出和实际政府支出随年份的变化趋势')
ax[1].legend(loc='upper left')
'''
# 初始化一个空字典用于存储每个季度的求和结果
sum_data = {}
# 遍历 data 数据框的每一行
for index, row in data.iterrows():
quarter = row['quarter']
realdpi = row['realdpi']
# 检查季度是否已经存在于 sum_data 字典中,如果不存在,则将季度作为键添加到 sum_data 字典中,并将值设为0
if quarter not in sum_data:
sum_data[quarter] = 0
# 将当前季度的值加到对应位置上
sum_data[quarter] += realdpi'''
sum_data = {'第一季度': realdpi[::4].sum(),
'第二季度': realdpi[1::4].sum(),
'第三季度': realdpi[2::4].sum(),
'第四季度': realdpi[3::4].sum()}
# 所需的数据
labels = ['第一季度', '第二季度', '第三季度', '第四季度']
sizes = [sum_data[quarter] for quarter in sum_data]
# 绘制柱状图
ax[2].bar(labels, sizes)
ax[2].set_xlabel('季度(quarter)')
ax[2].set_ylabel('实际可支配个人收入')
ax[2].set_title('各季度实际可支配个人总收入')
# 调整子图之间的垂直间距
plt.subplots_adjust(hspace=0.5)
# 求平均值
means = data.iloc[:,2:7].mean()
# 绘制直方图
ax[3].bar(range(5), means)
ax[3].set_xticks(range(5))
ax[3].set_xticklabels(['实际国内生产总值', '实际消费支出', '实际投资支出', '实际政府支出', '实际可支配个人收入'])
ax[3].set_title('各指标的平均值')
# 显示所有图像
plt.tight_layout() # 自动调整子图之间的间距,避免重叠
plt.show()
- 运行结果1
- 实验代码2
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv('../macrodata.csv')
plt.rcParams['axes.unicode_minus'] = False #解决坐标轴刻度负号乱码
plt.rcParams['font.family'] = 'SimHei'
data = data[['cpi', 'm1', 'tbilrate', 'unemp']]
trans_data = np.log(data).diff().dropna()
#绘制散点图并加一条回归线
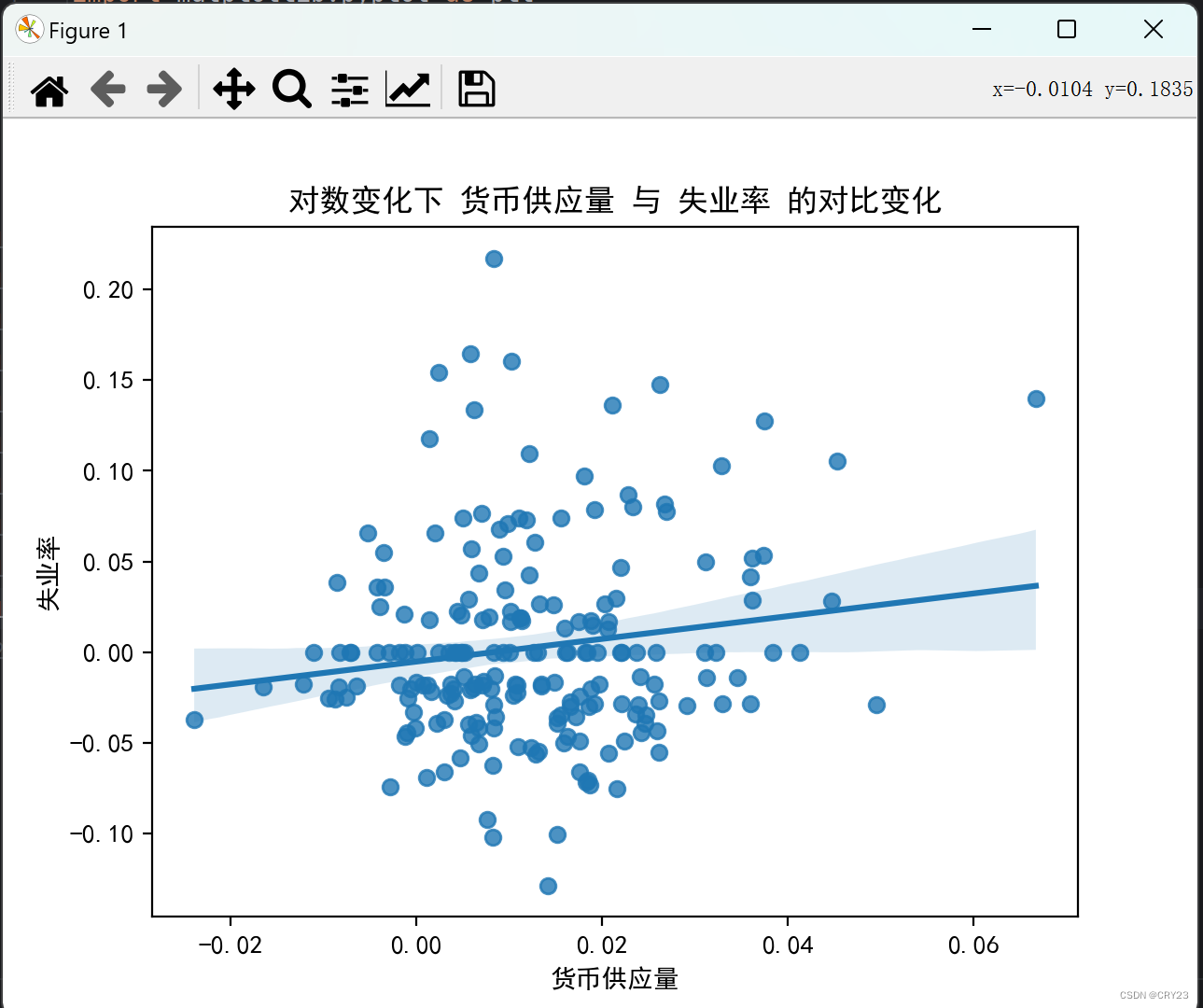
sns.regplot(x='m1', y='unemp', data=trans_data)
plt.xlabel('货币供应量')
plt.ylabel('失业率')
plt.title('对数变化下 %s 与 %s 的对比变化' % ('货币供应量', '失业率'))
plt.show()
- 运行结果2
- 实验体会
(如:实验遇到的问题及解决办法)
问题:
- 图像不显示文字,显示一些框框
- 布局:刚开始没有注意多个图形的布局,导致运行结果只有一幅图
解决方案:
- 使用代码:plt.rcParams['font.family'] = 'SimHei' # 设置中文字体为黑体
- 使用代码:fig, ax = plt.subplots(4, 1, figsize=(10, 8)) # 设置多个子图,将代码:plt.show() 放在最后面,确保所有子图都可以显示出来。















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









