



💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 题目

- 背景
在如今各类通用神经网络加速处理器(Neural Processing Unit,NPU)中,基于单指令多数据流(Single Instruction Multiple Data,SIMD)架构的处理器硬件设计简单,面效高,成为边缘推理任务的首选,但其软件模型适配的复杂性成为其大规模商用的关键瓶颈。在神经网络推理过程中,算子(如矩阵乘Matmul、卷积Conv、注意力Attention等)是最小任务单元,其执行效率直接影响模型在平台上端到端的推理性能。我们将算子在SIMD架构硬件平台上的完整计算过程拆解为由硬件单元操作构成的细粒度计算图,并通过手工或自动的方式编排成可在SIMD平台上执行的任务。由于这类计算图具有高度异构性(算子类型多样、输入形状动态变化、拓扑结构复杂),人工编排方式难度大,缺乏通用性,且效率低下,无法在如今日益复杂的计算场景下大规模推广。
因此,亟需设计一种通用调度算法,自动地将计算图中各原子操作编排调度到各硬件单元上执行,取代低效的人工编排计算单元流水的过程。该算法需面向SIMD平台的硬件限制,给出由硬件单元操作组成的计算图的优化调度顺序,使得多个不同单元能并行执行,缩短流水线延迟。同时,调度算法还需考虑内存与计算协同,动态管理多级缓存,自动决定缓存数据换入换出,减少数据搬运开销。
- 核内调度算法
- 任务
计算图为有向无环图(DAG),本题开始给出的图,其节点分为两类:在特定硬件单元上执行的操作节点,以及用于缓存资源分配的缓存管理节点。给定的一个计算图,需要通过调度算法提供一个包含计算图所有节点的有序列表作为调度顺序,以及为所有缓存管理节点中的申请节点分配相应类型的地址。在本核内调度问题中,处理核心由多个执行单元和多级缓存共同组成(参考附录A)。
计算图中的每个操作节点具有如下关键属性:
- Id:从0开始的节点唯一标识符。
- Op:操作指令名。可以是除ALLOC/FREE以外的任意操作名(例如数据搬运类操作COPY_IN,COPY_OUT等,计算类操作ADD,MUL等)。
- Pipe:指定该操作在哪个执行单元上运行。如附录A图3中,Cube、Vector为计算单元,MTE1/2/3/FIXP为数据搬运单元。
- Cycles:表示在该执行单元上操作运行所需的时钟周期数。
- Bufs:表示该操作所需输入和输出数据缓冲区的唯一标识符(BufId)组成的列表。
计算图中的每个缓存管理节点具有如下关键属性:
- Id:从0开始的节点唯一标识符。
- Op:ALLOC或FREE,分别代表申请或释放数据缓冲区。
- BufId:所申请或释放的数据缓冲区的唯一标识符。
- Size:申请或释放的数据缓冲区长度。
- Type:该数据缓冲区所处的缓存类型(如附录A图3中L1/UB/L0A/L0B/L0C等)。
计算图中的每条有向边(下文中也称之为依赖边)表示源节点和目的节点之间的执行依赖关系,节点必须严格按照依赖边约束的前后顺序执行。
图1为一个示例Exp计算图,其表现出计算图如下基本规则:
- 首先,忽略缓存管理节点后,所有的计算图都以COPY_IN节点开始(将数据从核外内存搬入核内缓存),经过一系列核内基本运算,最终以COPY_OUT节点结束(将计算结果从核内缓存搬出至核外内存)。
- 其次,所有操作节点的执行都受事先分配好的缓存资源限制。因此,计算图中所有根节点均为ALLOC节点,所有叶子节点均为FREE节点,反之亦然。
- 最后,ALLOC节点发出的有向边通常指向对应缓冲区数据的生产者(例如,Id为0的ALLOC节点指向COPY_IN节点);而该缓冲区内数据的消费者则通过有向边指向FREE节点(例如,EXP节点指向Id为4的FREE节点);生产者和消费者之间也通过有向边相连。
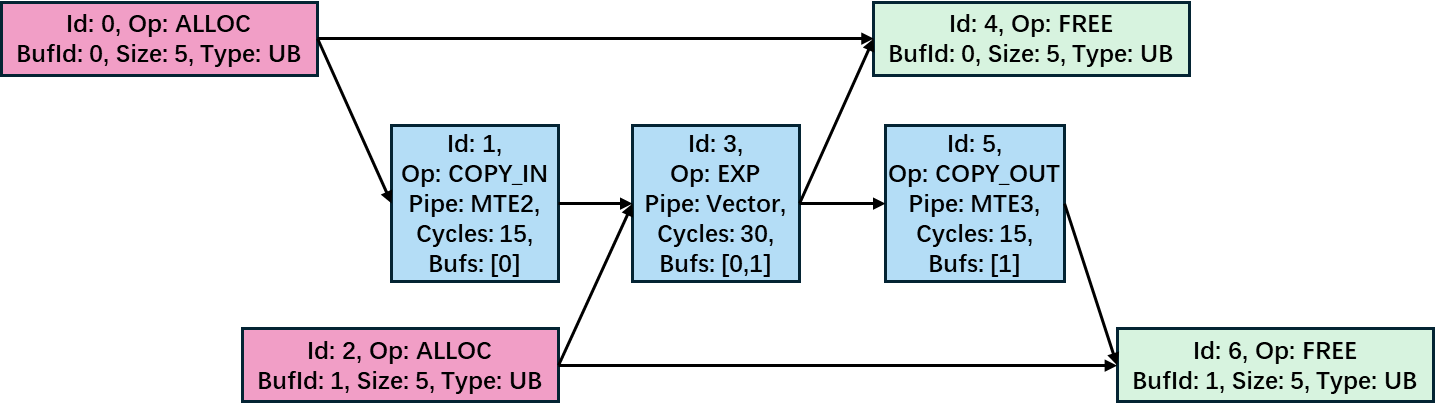
调度算法的首要任务是给出一个满足计算图拓扑序的节点执行序列
,该序列应该包含计算图中所有节点(该序列由节点Id组成)。以图1所示的示例Exp计算图为例,调度序列(0 ® 1 ® 2 ® 3 ® 4 ® 5 ® 6)为一个有效的调度序列,因为该序列包含了所有节点,且满足拓扑序。
调度算法需要为计算图中每个数据缓冲区(即每个BufId)分配一个起始地址偏移(Offset),以确定其在硬件缓存中所占的位置。硬件上的各类缓存均为有限长度的连续地址空间,每个缓冲区需在指定缓存空间中占据一片连续的地址区间,其区间长度由Size字段指定。不同数据缓冲区可以分时复用同一片区间,但同一时刻存在的缓冲区,必须分配在不重叠地址区间。
对于图1中的示例计算图,Buf0(BufId为0的缓冲区)和Buf1在给出的调度序列上生命周期重叠,因此需分配至不重叠的地址区间。Buf0和Buf1的长度都为5,若UB类型缓存容量为10,则可为Buf0分配[0-4]的地址区间,为Buf1分配[5-9]的地址区间,因此缓存地址分配方案{Buf0:Offset=0,Buf1:Offset=5}是可行的。
这样就得到了一个包括节点调度顺序和缓存地址分配在内的完整调度方案,其在实际硬件上的执行过程如图2所示。
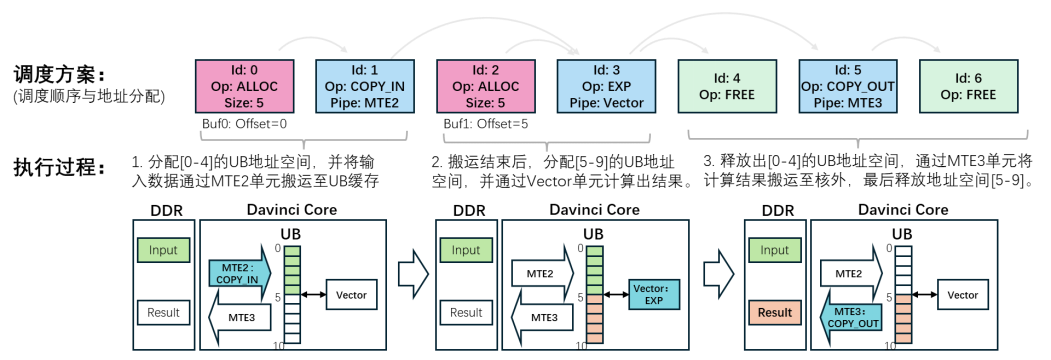
由于硬件缓存大小有限,调度算法可能会遇到空间不足的问题:在执行中的某一个时刻,需要驻留数个缓冲区,然而硬件空间大小可能不满足这些数据缓冲区的需要,无法生成可行的调度方案。此时,调度算法需要在计算图中加入数据搬运操作节点,将部分核内缓冲区数据临时移出至核外内存(Double Data Rate SDRAM,简称DDR)上,释放出硬件缓存空间,并在后续计算需要时,重新载入至核内缓存。上述操作称为缓存换入换出操作(简称SPILL操作),具体给出方式见附录B。
-
- 算法评估指标
评估调度算法的性能主要依据两个关键指标:任务的总执行时间和总额外数据搬运量。
-
-
- 总执行时间
-
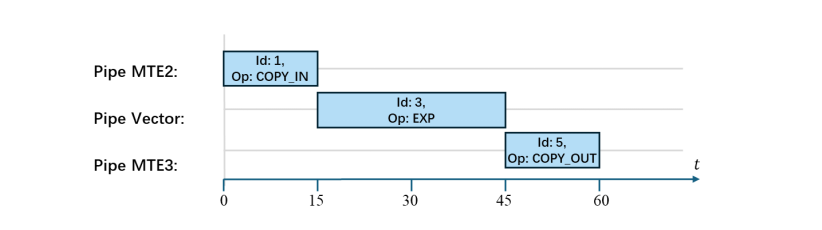
总执行时间表示在硬件上执行完计算图需要的总时钟周期数,用于衡量调度方案在硬件上的实际运行效率。硬件上各个不同单元虽然可以同时工作,但由于指令间存在依赖关系,某条指令要能在某个单元上执行,必须等待其前序指令(在其他单元上)执行完毕。两种依赖关系可能导致节点执行时需要等待:一是计算图中节点间已有的依赖边,二是缓存物理地址复用带来的执行依赖。调度方案下的总执行时间根据调度顺序与依赖关系确定(具体计算方法请参考附录C)。
优良的调度方案能使得各执行单元交替工作,并行地流水化处理计算图各节点,最小化各执行单元等待时间,从而减少总执行时间,提升运行效率。
-
-
- 总额外数据搬运量
-
总额外数据搬运量指由缓存换入换出操作(SPILL操作)所引起的额外DDR访问数据量。DDR访问通常伴随较高功耗,该值越低,代表计算图在平台上执行的能效越高。具体计算方法详见附录C。
调度方案需要尽可能避免资源不够时产生的缓存换入换出操作。一方面,调度需要减少缓存碎片化,尽可能地在有限空间内放下更多的缓存数据;另一方面,调度需要尽可能优化调度顺序,压缩每个缓冲区数据的生命周期,避免缓冲区数据持久驻留在缓存。
- 最小缓存驻留调度

附件中提供了六个示例计算图(文件格式参见附录E),请设计调度算法方案,给出所有示例计算图上的
结果(一定要放在论文内),并且以附件形式提供各计算图的调度顺序结果(文件格式见附录E)。
- 缓存分配与换入换出
基于问题1得到的调度顺
的基础上,设计一种使得总额外数据搬运量指标尽可能小的缓存分配方案。方案需给出计算图中每个缓冲区对应的地址偏移、分配过程需要的SPILL操作列表,以及加入SPILL节点后的完整调度序列。可从减少缓存碎片的角度分析如何优化最终结果。若以问题1中调度序列结果为基础进行缓存分配,无法充分实现总额外数据搬运量最小化的目标,可进一步对调度序列生成策略进行优化调整。
| 缓存 | 容量 | 缓存 | 容量 |
| L1 | 4096 | L0B | 256 |
| UB | 1024 | L0C | 512 |
| L0A | 256 |
参赛论文中需提供附件中示例计算图上的总额外数据搬运量结果(一定要放在论文内),并在提交附件中提供这些示例计算图上的详细调度结果(格式见附录E)。
- 性能优化策略
结合问题1得到的调度顺序和问题2得到的缓存分配方案,已经可以组成一套完整的调度算法,但由于前两个问题的优化目标围绕减少数据搬运量展开,因此问题2得到的总运行时间指标可能不理想。
请在总额外数据搬运量指标不显著增加的前提下,进一步设计优化策略,尽可能降低算子的总运行时间(也可对两项指标联合优化)。可以从如何优化调度顺序入手,也可以从如何优化缓存分配方案入手。实现其设计的性能优化策略,在参赛论文中给出附件中示例计算图上两项主要指标数据的提升效果(一定要放在论文内),并以附件的形式提供优化后的详细调度结果(格式见附录E)。
附录
在本核内调度问题中,我们将SIMD架构中的处理核心抽象为多个可并行工作的执行单元与多级缓存共同组成的计算结构,如图3所示。执行单元主要包括计算单元(Cube核与Vector核)以及数据搬运单元(MTE1/2/3和FIXP)。每个单元具备独立的指令队列,由统一的调度核心进行指令分发与协同调度。各单元功能如下:
数据搬运单元 (包括MTE1/2/3单元和FIXP单元):负责在核外内存(DDR)、多级缓存(L1, L0A/L0B/L0C)以及统一缓存(UB)之间传输数据。
计算单元 (包括Cube核和Vector核):
-
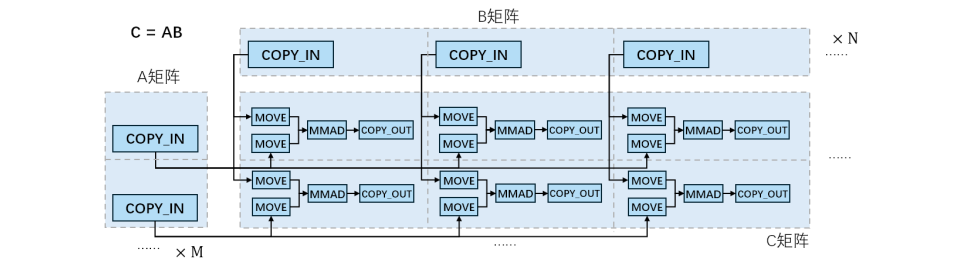
- Cube核: 专用于矩阵乘法计算。输入数据(左矩阵A、右矩阵B)经由MTE2(DDR®L1)和MTE1(L1®L0)加载至专用的L0A与L0B缓存。计算结果写入L0C缓存,最后由FIXP单元写回DDR。
- Vector核: 负责通用向量计算。输入数据和中间结果都存储在统一缓存(UB)内,输入数据通过MTE2单元从DDR加载至UB,最终运算结果则通过MTE3单元从UB写回DDR。
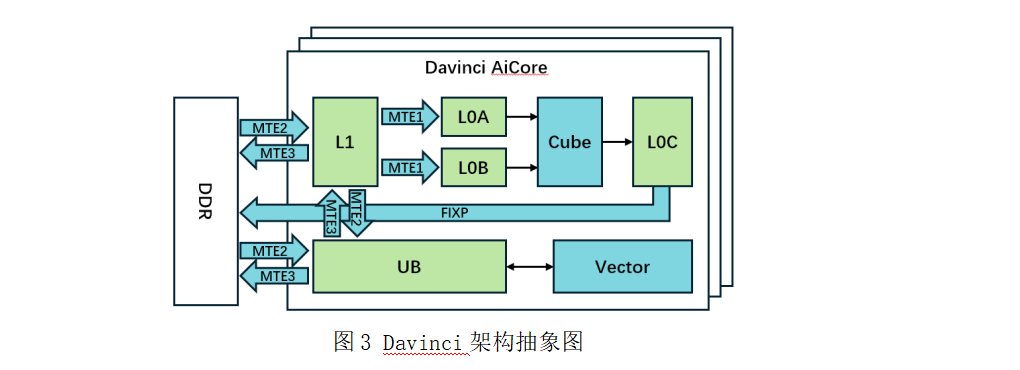
图3 Davinci架构抽象图
核心内设有多级缓存:L0缓存为紧邻Cube核的高速缓存,分为L0A(左矩阵输入)、L0B(右矩阵输入)、L0C(结果输出);L1缓存容量更大,作为矩阵运算数据的中间缓存;统一缓存UB则用于存储Vector核的输入、输出及中间结果。MTE单元也支持在L1和UB之间交换数据,以支持矩阵计算和向量计算交替执行的场景。
在本核内调度问题中,计算图的每个节点可视为一条在特定单元上执行的指令。调度算法的首要任务是为所有节点(指令)生成一个满足计算图节点依赖关系的有效拓扑序。基于该序列中的指令间依赖关系,系统将自动插入同步指令,并由调度核心分发指令流,驱动各单元协同完成计算任务(该过程由框架自动实现,无需调度算法处理)。
此外,调度算法需管理缓存资源的使用。每种缓存资源可以看作是连续的地址空间,且有固定的总长度,行为完全由程序控制。因此,调度算法需为计算图中每个缓冲区分配指定类型与大小的缓存地址区间。
当调度算法遇到缓存资源死锁时(即:缓存空间已分配或接近分配完、已分配缓冲区因依赖指令未完成而无法释放,同时新指令的执行需要分配缓存),需通过缓存数据换入换出操作(SPILL操作)临时将部分缓冲区数据移至核心外的内存DDR上,释放出这部分缓存空间,并在后续计算需要时再搬移回来。我们将硬件上缓存数据搬出和搬入的过程,作为两个新增的特殊操作节点:SPILL_OUT和SPILL_IN。
如图4所示,若引入一次SPILL操作,并指定某一缓冲区(如图4中Buf0)作为操作对象,会向计算图中插入两个操作节点:
SPILL_OUT节点将当前Buf0的数据搬移至DDR,SPILL_IN节点再将其重新搬回UB缓存。这两个节点分别需要占用MTE3单元和MTE2单元的执行时间。
对于新增的操作节点,其属性自动设置如下:
- Id:从
 开始自动递增。若原计算图共有个节点,Id范围为至。首次SPILL操作对应的SPILL_OUT和SPILL_IN节点Id分别为和。以此类推,第次SPILL操作引入的节点Id依次为和。
开始自动递增。若原计算图共有个节点,Id范围为至。首次SPILL操作对应的SPILL_OUT和SPILL_IN节点Id分别为和。以此类推,第次SPILL操作引入的节点Id依次为和。 - Op:SPILL_OUT或SPILL_IN。
- Pipe:SPILL_OUT在MTE3单元上执行,SPILL_IN在MTE2单元上执行。
- Cycles:执行周期与当前目标缓冲区的大小有关,计算公式参考附录D。
- Bufs:仅包含当前目标缓冲区BufId的列表。
若调度算法给
次SPILL操作,则最终调度序列必须包含所有原计算图节点和新增的
新增节点的依赖边按如下规则生成:首先,生成三条基本依赖边:ALLOC ® SPILL_OUT、SPILL_OUT ® SPILL_IN、SPILL_IN ® FREE。其次,将当前计算图中所有使用到目标缓冲区的操作节点分为“已执行”和“未执行”两部分(以SPILL_OUT节点在调度序列中的位置为界)。对于“已执行”的操作节点
的依赖边。
由于SPILL_IN节点可将数据加载至新的核内缓存地址区间,调度算法需明确给出每次操作的目标缓冲区以及新的目标地址偏移。具体表示方式参考附录E。
- 总执行时间
根据调度算法给出的执行顺序、缓存分配方案、缓存换入换出操作列表,可以通过如下步骤计算出总执行时间:
步骤1:插入SPILL节点。依照附录B所述,在原计算图中插入SPILL_OUT节点和SPILL_IN节点,并添加相应的依赖边(若不需要缓存换入换出,则跳过该步骤)。
步骤2:计算缓存复用依赖。按ALLOC执行顺序遍历各缓冲区,检查其是否复用了之前已分配缓冲区的地址。若缓冲区b复用了缓冲区a的地址空间,则需要添加一条从a的FREE节点到b的ALLOC节点的依赖边。
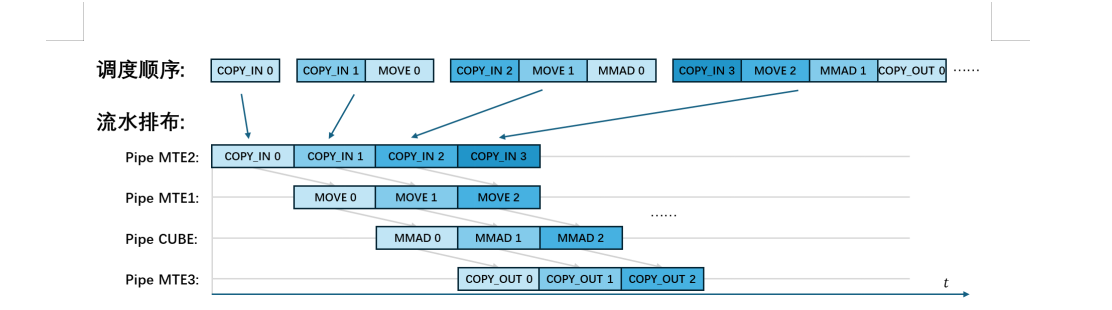
步骤3:流水排布。按步骤1和2修改得到计算
不同硬件单元可以并行执行。若计算图中存在多个Exp子计算图,在总缓存容量允许的情况下,后续COPY_IN节点可提前执行(图6中节点8、节点15),从而实现多个执行单元间的流水并行,减少总执行时间。
- 总额外数据搬运量
总额外数据搬运量根据调度算法给出的SPILL操作列表中的目标缓冲区进行统计。对不同的目标缓冲区,按如下两种情况分别计算:
情况1:若目标缓冲区在计算图中未被任何COPY_IN节点使用(即所有COPY_IN节点的Bufs属性列表中均不包含该缓冲区),则此次SPILL操作将引入两次核外DDR存取:SPILL_OUT和SPILL_IN分别执行一次数据搬出与搬入。因此,增加的额外数据搬运量为该缓冲区大小的两倍。
情况2:若目标缓冲区在计算图中被某个COPY_IN节点使用,则仅SPILL_IN节点需要执行一次从DDR至核内的数据搬入,SPILL_OUT不产生实际核外存取。因此,增加的额外数据搬运量等于该缓冲区大小。
总额外数据搬运量为所有SPILL操作所带来的额外数据搬运量之和。
对于每个SPILL_OUT操作和SPILL_IN操作,其消耗的时间跟目标缓冲区大小成线性相关。对不同的目标缓冲区,按如下两种情况分别计算:
情况1:若目标缓冲区在计算图中未被任何COPY_IN节点使用,则按如下公式计算耗时:
本赛题提供一系列示例计算图,以供参赛队伍验证针对设置问题所提出解决方案的效果。这些示例计算图的任务名以及节点数量等特性列在表2中。
需要说明的是,这一系列示例计算图仅提供给参赛队伍作思路验证使用。实际场景下的计算图可能是任意多个算子的排列组合,因此,参赛队伍提出的解题思路应尽可能具有泛化性与通用性,尽可能避免针对某一特定算子的计算图结构(附录F中所示的典型算子计算图结构)进行优化。
| 任务名 | 节点数量 | 依赖边数量 |
| Matmul_Case0 | 4160 | 7104 |
| Matmul_Case1 | 30976 | 55040 |
| FlashAttention_Case0 | 1716 | 2712 |
| FlashAttention_Case1 | 6952 | 11184 |
| Conv_Case0 | 2580 | 3869 |
| Conv_Case1 | 36086 | 85653 |
上述示例计算图提供Json和CSV两种版本。对于Json版本,表中每个计算图以<任务名>.json文本文件的形式提供。每个文件中包含内容的格式如下:
<任务名>.json:
{
"Nodes" : [
{
"Id" : 0,
"Op" : "ALLOC",
"BufId" : 0,
"Size" : 1,
"Type" : "UB"
},
{
"Id" : 1,
"Op" : "COPY_IN",
"Pipe" : "MTE2",
"Cycles" : 15,
"Bufs" : [0]
},
......
],
"Edges" : [
[0, 1],
......
]
}
其中,“Nodes”字段下为包含计算图所有操作节点和缓存管理节点的列表,每个元素为一个节点;“Edges”字段下为包含计算图所有有向依赖边信息的列表,其每条有向边通过“[源节点Id,目标节点Id]”表示。
对于CSV版本,每个计算图的节点和有向边信息分别通过<任务名>_Nodes.csv和<任务名>_Edges.csv文本文件提供,其包含内容格式如下:
<任务名>_Nodes.csv:
Id,Op,BufId,Size,Type,Pipe,Cycles,Bufs
0,ALLOC,0,1,UB,,,
1,COPY_IN,,,,MTE2,15,"0"
……
<任务名>_Edges.csv:
StartNodeId,EndNodeId
0,1
……
CSV文件中,第一行为表头信息,后续每一行代表一个节点或一条有向边。Json版本与CSV版本计算图仅文件格式不同,其包含的计算图信息是完全相同的。
问题1至3均需提供算法运行结果作为附件。附件压缩包需组织成如下形式:
Attachment.rar
├── Problem1
│ └── <任务名>_schedule.txt
├── Problem2
│ ├── <任务名>_schedule.txt
│ ├── <任务名>_memory.txt
│ └── <任务名>_spill.txt
└── Problem3
├── <任务名>_schedule.txt
├── <任务名>_memory.txt
└── <任务名>_spill.txt
在该压缩包中,问题1至3的结果分为三个目录存放。问题1中,仅需提供调度序列结果。问题2和问题3需要提供完整调度结果,包括调度序列、缓存分配、换入换出操作列表。每个目录下各个文件格式如下:
- <任务名>_schedule.txt文件为该计算图上给出的调度顺序结果,以文本形式按序给出各个节点Id,节点Id间通过换行符隔开:
<任务名>_schedule.txt:
0
2
4
1
....
- <任务名>_memory.txt文件为该计算图上给出的缓存分配结果,以“BufId:Offset”的形式给出各个缓存分配的地址偏移,各BufId间通过换行符隔开:
<任务名>_memory.txt:
0:0
1:5
2:30
3:10
....
- <任务名>_spill.txt文件为该计算图上给出的SPILL操作,以“BufId:NewOffset”的形式依次给出各个SPILL操作,各操作间通过换行符隔开(若不需要SPILL操作,则提供空文件):
<任务名>_spill.txt:
5:400
9:20
1:40
....
参赛队伍需将上述结果打包并压缩成rar文件作为附件单独上传。附件文件名统一格式:A<队号>.rar。
F.1 Matmul计算图结构
图7展示了硬件完成矩阵乘法的典型计算图结构。对于大尺寸矩阵乘法(左矩阵
尺寸为
尺寸为
和
通常无法一次性载入至L1缓存,需采用分块加载并计算的策略。如图所示:将
矩阵
轴切分为
矩阵沿
块(
轴切分未展示),则结果
和

的所有分块,计算过程中必然涉及矩阵分块的重复载入(通过SPILL机制实现),而
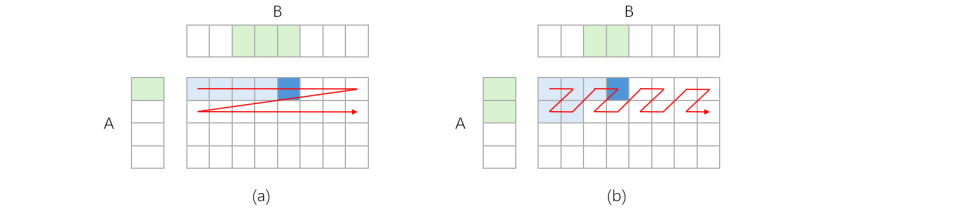
矩阵分块的计算顺序将直接影响额外数据搬运量。图9展示了两种计算顺序,(a)顺序按行计算
矩阵分块,(b)顺序按之字形路径计算。
假设L1缓存仅能容纳4个矩阵块,可以看出:在顺序(a)中,每个A矩阵块只需载入一次,可重复利用于整行计算;但在行间切换时,B矩阵块需重新载入(通过SPILL机制),导致B矩阵总共需载入四次。因此,顺序(a)带来的额外数据搬运量相当于矩阵B大小的三倍。同理,可以得到顺序(b)中B矩阵总共仅需载入两次,其带来的额外数据搬运量仅相当于矩阵B大小的一倍。因此,顺序(b)优于顺序(a)。
F.2 FlashAttention计算结构图
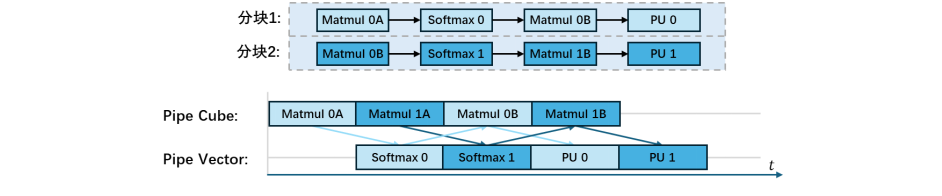
FlashAttention(FA)是一种高效计算Transformer网络中注意力机制的算法。它通过巧妙的分块计算和在线softmax技巧,将中间结果保留在高速缓存中,在保持数学等价性的同时,大幅提升了计算速度并降低了内存访问量。该算法已成为大型语言模型推理加速的关键技术之一。FA典型计算图结构如图10所示,其整体与Matmul类似,但存在如下区别:
- 分块内部计算结构更为复杂:FA中的每个分块计算包含四个部分:Matmul、Softmax、Matmul和PostUpdate,每个部分均为一个结构较为复杂的子计算图(图中未展示细节)。其中,Matmul部分主要依靠Cube计算单元完成,而Softmax和 PostUpdate部分则主要依赖Vector计算单元实现。
- 输出方式不同:与Matmul中每个分块独立输出不同,FA 中每一行内的所有分块共同输出一个矩阵块。具体而言,每一行前面分块的计算结果会与同一行后面分块进行加权融合,最终每行输出的是一个合并后的结果。
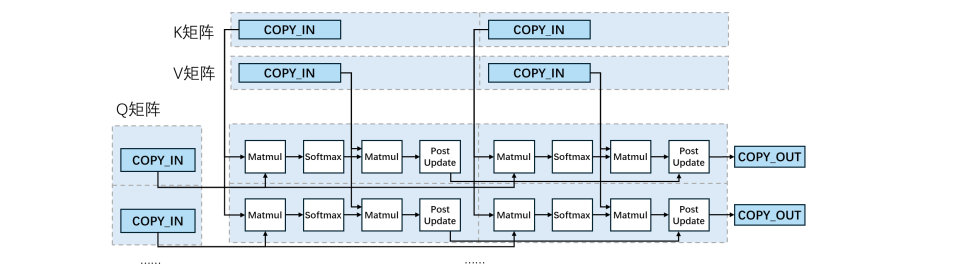
不同子计算图之间的中间数据结果通过MTE2和MTE3单元在UB缓存和L1缓存之间进行传输。由于每个部分同时包含Cube类计算和Vector类计算,在调度FA计算图时,需考虑Cube与Vector计算单元之间的流水并行,以及 QKV 矩阵的数据复用情况。一般而言,通过两个分块四个阶段间的交替执行,来最大化Cube单元和Vector单元的利用率,如图11所示。
F.3 卷积计算结构图
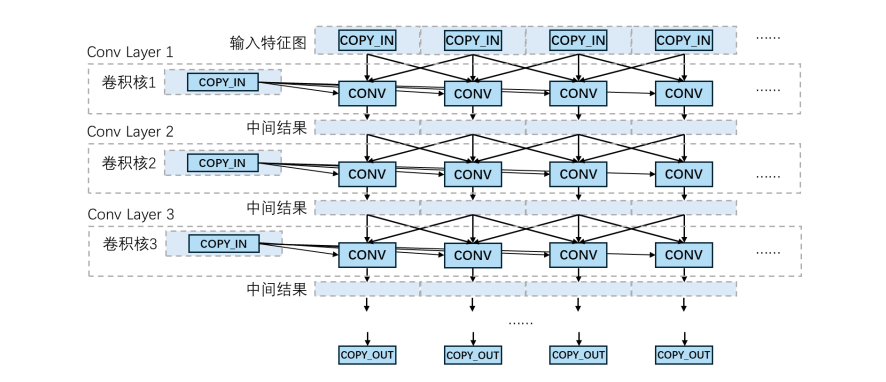
卷积神经网络(CNN)是一种专用于处理网格结构数据(如图像)的深度学习架构。CNN核心在于其多层卷积结构。通过堆叠多个卷积层,网络能够逐层提取并组合输入数据中的特征:浅层卷积捕获局部细节(如边缘和纹理),深层卷积则将这些基础特征融合成更加抽象的高级语义特征。CNN已成为计算机视觉领域最为基础和广泛的骨干网络之一。
如图12所示,一个典型的多层卷积网络计算图以前端特征图载入缓存为起点,数据被切分为多个小块载入。每一卷积层由卷积核载入操作和多个卷积操作(CONV)构成,每个卷积操作的输入包括前一层输出的多个特征块与当前层的卷积核。输出结果继续流向后续卷积层作为输入,通过不断重复这一卷积过程,最终完成对整个输入数据的特征提取与推理。
卷积计算图在层间呈现交错的依赖结构,因此调度顺序对缓存驻留影响显著。通常可采用深度优先与广度优先两种调度策略,分别适用于不同场景。如图13所示,(a)和(b)分别表示深度优先和广度优先策略,图中通过节点颜色深浅表示调度顺序先后。
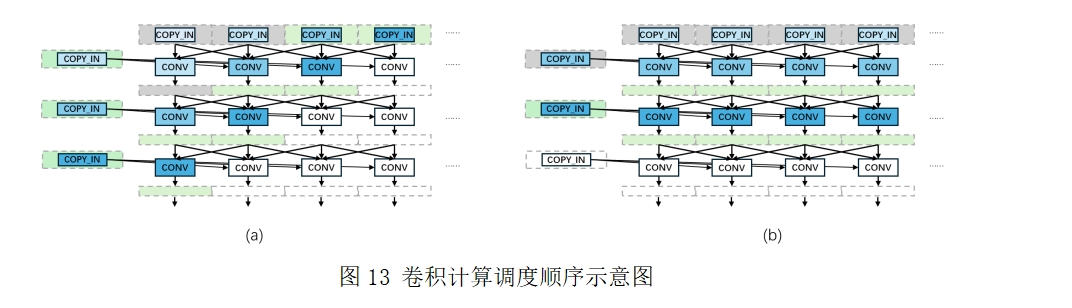
在深度优先策略中,不同层的卷积操作交替执行,每层仅需将少量数据(图中绿色部分)驻留于缓存,灰色部分为可释放的数据块。该策略适用于特征图较大而卷积核较小的场景。而在广度优先策略中,每层卷积计算完毕后再进入下一层,卷积核使用后即可释放,因此更适用于特征图较小而卷积核较大的场景。
📚2 完整资源下载
通过网盘分享的文件:25华为杯
链接: https://pan.baidu.com/s/1NpT9h6UwwcB6SLFh2RAXzQ?pwd=2kui提取码: 2kui
--来自百度网盘超级会员v6的分享
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈4 A题思路、代码、论文持续更新.....
后台回复:25华为杯
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









