






我们今天给大家分享一波python当中,列转行的骚操作。
最原始的需求如下:

需要达到如下目的:

换句话说,每家被投企业要一一对应一家投资企业。当pandas版本很低的时候,没有什么好的方法直接实现,操纵起来比较繁琐,通过升级pandas达到0.25版本以上,pandas就提供了explode方法来出来像上面的这种情况。
首先我们先用之前的方法来实现,最后再用explode方法来实现,进行相互对比。
下面我们用4种方法来实现:

方法一
import pandas as pddf = pd.DataFrame({"投资企业":["xxx清奇科技有限公司","xxx宇塔字节科技有限公司","xxx金羽新能科技有限公司"], "被投企业":["xxx电波科技有限公司","xxx宇塔健康科技有限公司,xxx优叶堂健康科技有限公司", "xxx金羽新能源科技有限公司,xxx河金羽新能科技有限公司"]})df1 = df['被投企业'].str.split(",")print(df1)
我们先用字符串的split方法,按","分隔,没一行会形成一个列表,如下:
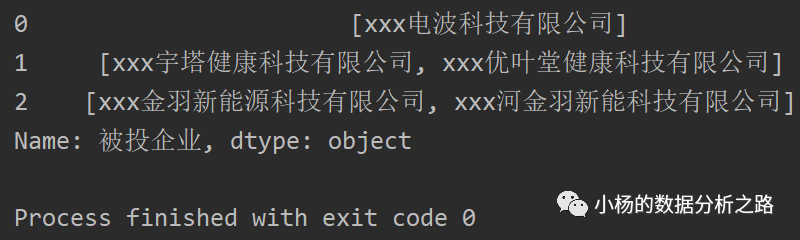
然后我们再分别创建两个列表,from_investment_list 和 to_investment_list。我们再通过两个循环遍历存储,外层循环遍历被投企业,内层循环遍历每行列表的元素,代码如下:
from_investment_list = []to_investment_list = []for i,name in enumerate(df1): for j in name: from_investment_list.append(df['投资企业'][i]) to_investment_list.append(j)df2 = pd.DataFrame({"投资企业":from_investment_list,"被投企业":to_investment_list})print(df2)
效果如下:

方法二
方法二和方法一有些相似,同样建立两个列表,from_investment_list 和 to_investment_list。再用zip方法遍历投资企业和被投企业,代码如下:
import pandas as pddf = pd.DataFrame({"投资企业":["xxx清奇科技有限公司","xxx宇塔字节科技有限公司","xxx金羽新能科技有限公司"], "被投企业":["xxx电波科技有限公司","xxx宇塔健康科技有限公司,xxx优叶堂健康科技有限公司", "xxx金羽新能源科技有限公司,xxx河金羽新能科技有限公司"]})from_investment_list = []to_investment_list = []for from_name,to_names in zip(df["投资企业"],df["被投企业"]): for name in to_names.split(","): from_investment_list.append(from_name) to_investment_list.append(name)df1 = pd.DataFrame({"投资企业":from_investment_list,"被投企业":to_investment_list})print(df1)
效果如下:

方法三
先上代码
import pandas as pddf = pd.DataFrame({"投资企业":["xxx清奇科技有限公司","xxx宇塔字节科技有限公司","xxx金羽新能科技有限公司"], "被投企业":["xxx电波科技有限公司","xxx宇塔健康科技有限公司,xxx优叶堂健康科技有限公司", "xxx金羽新能源科技有限公司,xxx河金羽新能科技有限公司"]})df = df.drop("被投企业",axis = 1).join(df["被投企业"].str.split(",",expand = True).stack().reset_index(level=1,drop = True).rename("被投企业"))print(df)
代码分解:
① 我们先用split方法进行分隔,再加一个参数,expand = True,可以把每一行的元素,转换成列,里面的元素不够,则以None值填充。
df1 = df["被投企业"].str.split(",",expand = True)print(df1)

②通过stack方法,level默认为-1,从列轴堆叠到索引上的级别轴,定义为一个索引或标签或索引列表或标签。
df1 = df["被投企业"].str.split(",",expand = True)df2 = df1.stack()print(df2)

③我们重置索引,reset_index(level=-1,drop=True),level = 1带表删除两个索引,默认删除全部。drop = True 代表删除原有索引。
df1 = df["被投企业"].str.split(",",expand = True)df2 = df1.stack()df3 = df2.reset_index(level=1,drop = True)print(df3)

df1 = df["被投企业"].str.split(",",expand = True)df2 = df1.stack()df3 = df2.reset_index(level=1,drop = True)df4 = df.drop("被投企业",axis = 1).join(df3.rename("被投企业"))print(df4)

这一步可能大家,有的小伙伴可能不太理解,是如何用join方法拼接的。这里我再给大家细分如下:
df1 = df["被投企业"].str.split(",",expand = True)df2 = df1.stack()df3 = df2.reset_index(level=1,drop = True)df4 = df.drop("被投企业",axis = 1)print(df4)

通过对应的索引来连接的,和merge、append、concat有异曲同工之妙。
方法四
最后,王炸方法来了。什么都不说,先上代码
df['被投企业'] = df['被投企业'].str.split(",")df1 = df.explode('被投企业')print(df1)

这个就是我们开头的给大家说的explode方法,是不是非常简单,以后遇到此类情况,我们可以优先考虑方法四。
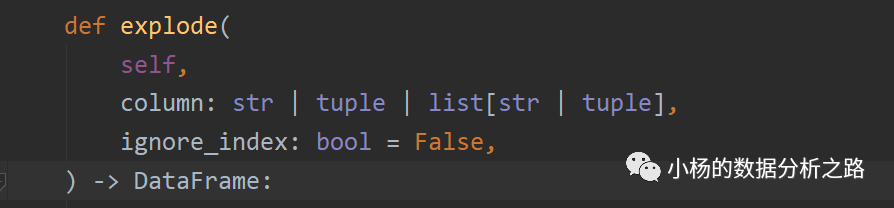
对于这么高效的exlode方法,大家也可以阅读源码,简单如下
-END-
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、自动化测试带你从零基础系统性的学好Python!
👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)
👉Python学习大礼包👈
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)
👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python书籍和视频合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉Python面试刷题👈

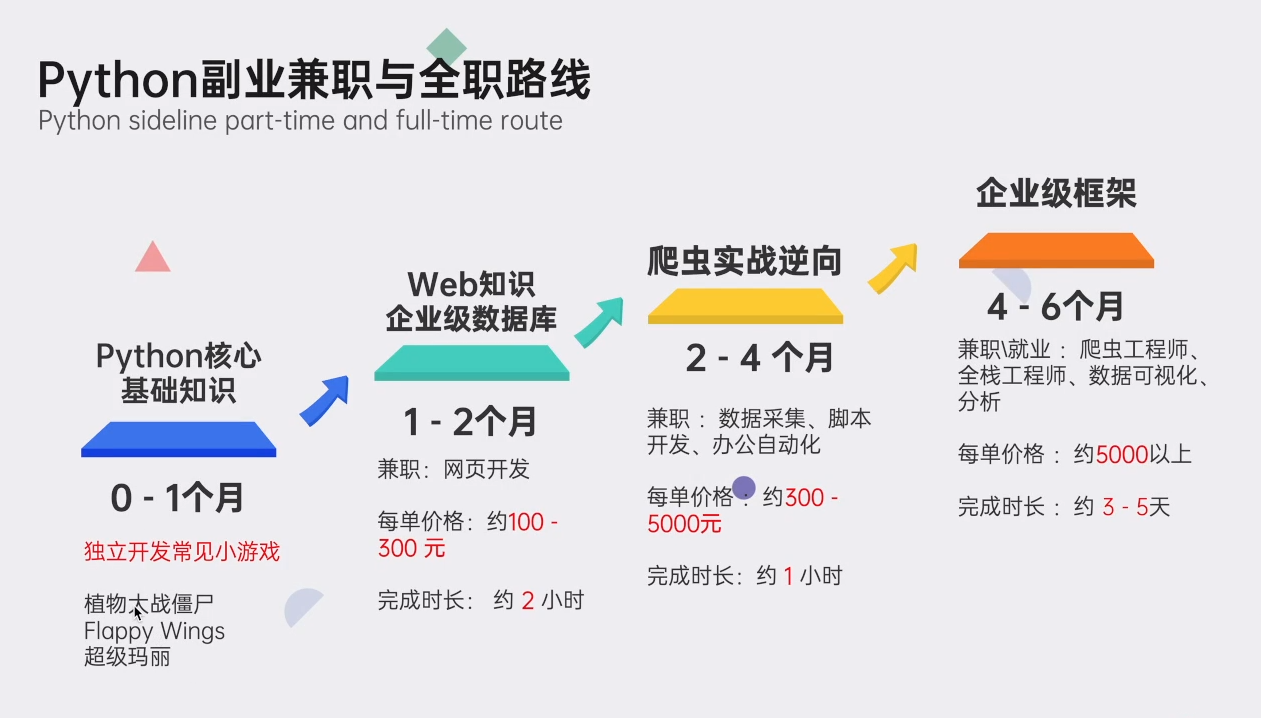
👉Python副业兼职路线👈

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以点击链接免费领取或者保存图片到wx扫描二v码免费领取 【保证100%免费】
👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)
















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









