







堆的定义
堆可以看做是一种特殊的树,堆结构满足两个条件:
1、堆是一个完全二叉树。
2、堆的每一个节点的值都大于等于(或小于等于)其子节点的值。
大于等于子节点的值我们叫它:大顶堆
小于等于子节点的值我们叫它:小顶堆
大顶堆
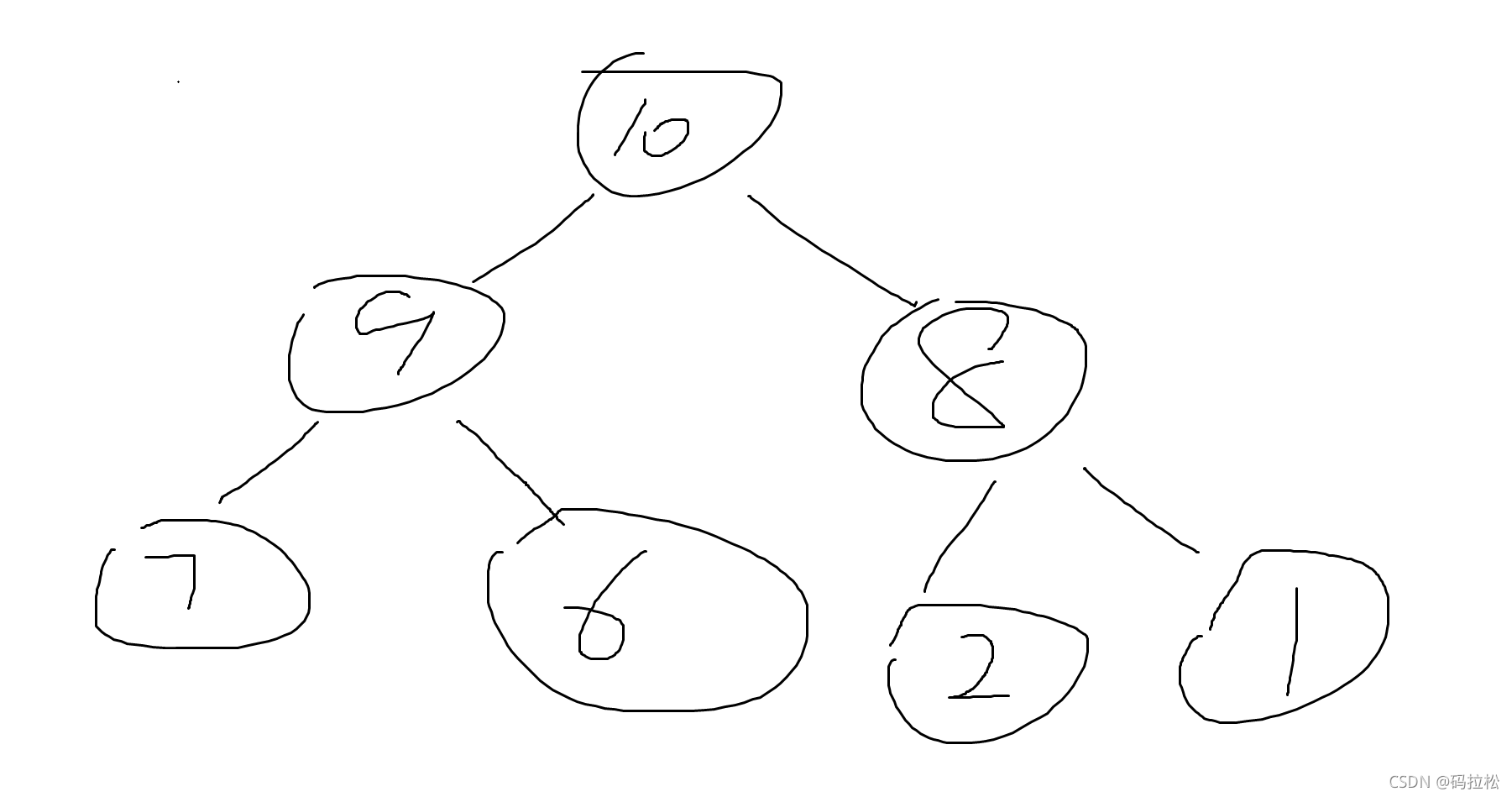
小顶堆
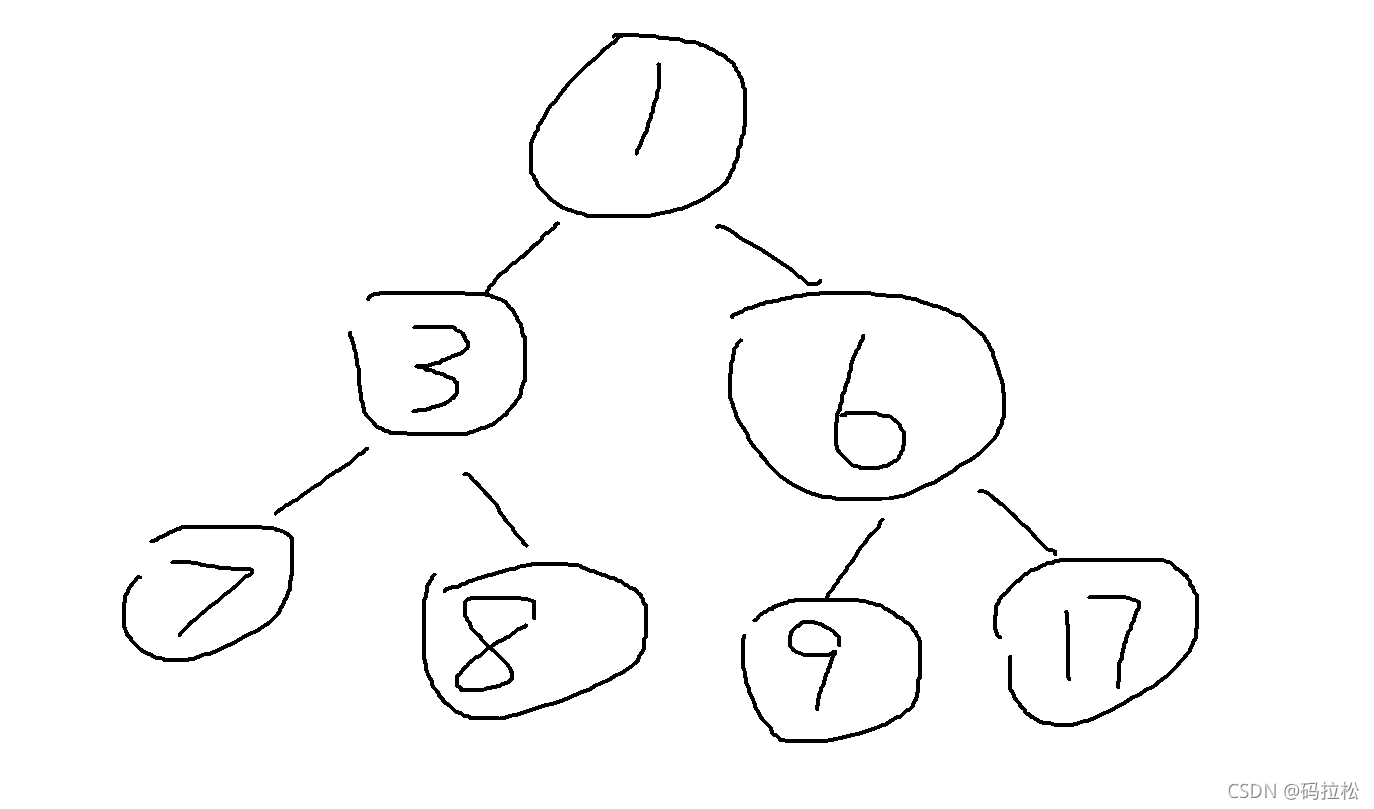
非堆
不满足完全二叉树定义,不是一个堆
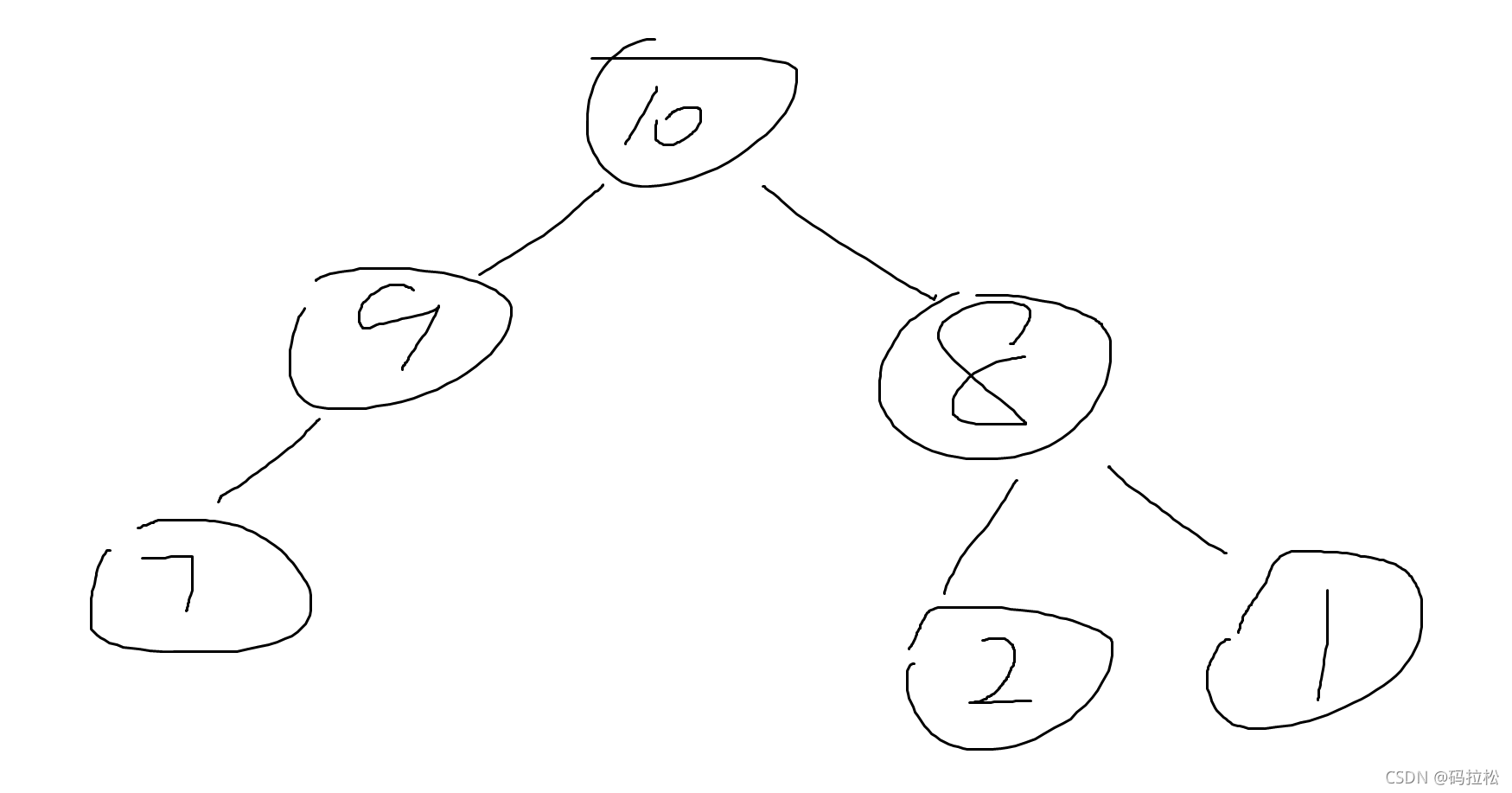
堆的构建
堆化
我们知道堆是一种完全二叉树,所以我们一般直接用数组来表示堆的结构,通过数组的下标就能够定位到树的任意位置,这是一种即高效又节省空间的选择。
举个例子:
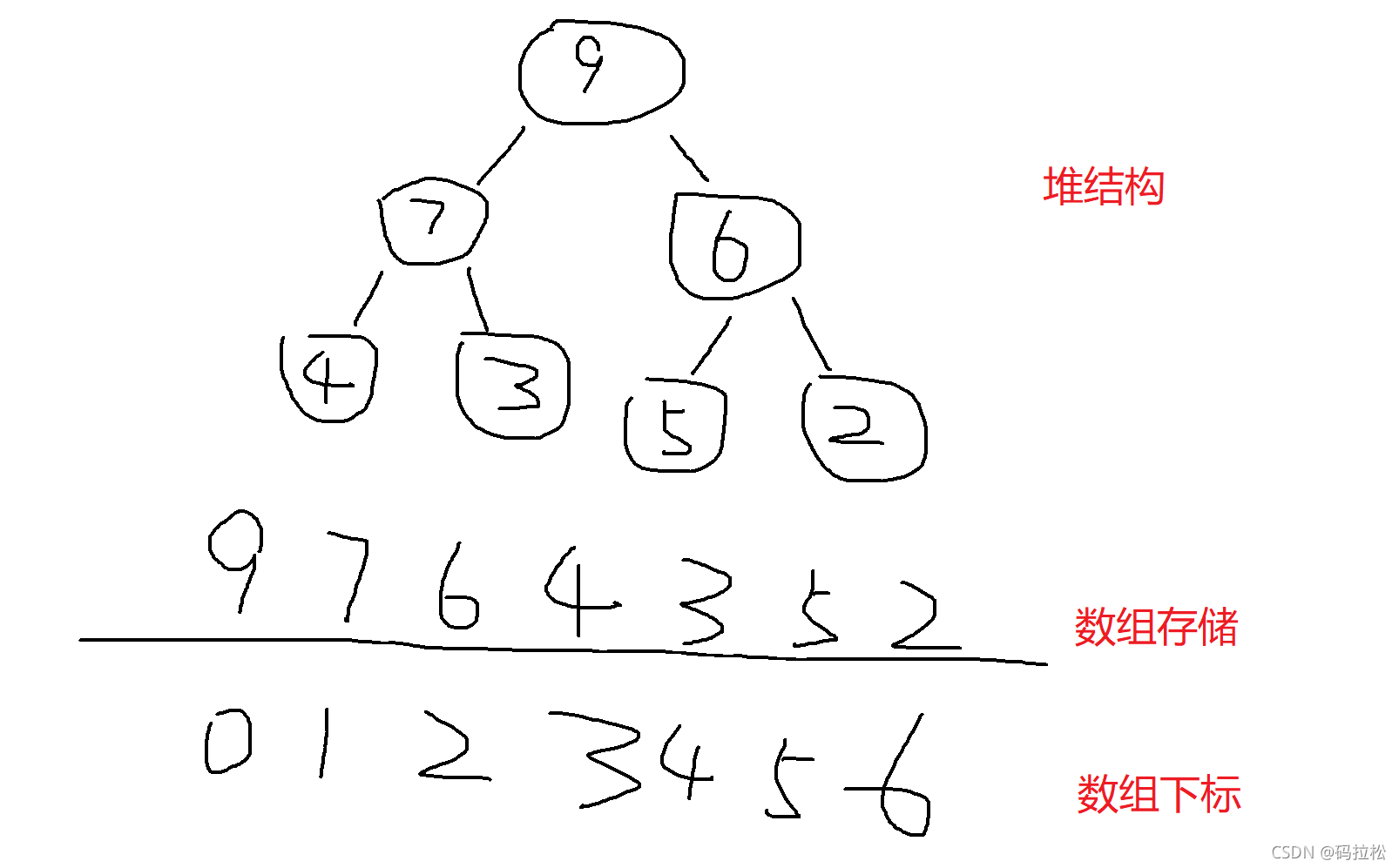
数组下标中:对于第i位置的元素来说,第i2+1的位置是它的左子节点,第i2+2的位置是它的右子节点。对于每个子节点来说第(i-1)/2的位置就是它的父节点。
因此,当我们需要往堆中添加一个元素的时候,只需要直接先把元素添加到数组的最后即可,当然直接添加到数组最后就不满足堆的结构了,比如这时候要添加一个值为8,如果直接添加到数组最后显示不合适,因此我们还需要进行一些调整,而这个调整的过程一般称为堆化(heapify)。
堆化有两种,一种是自下而上,一种是自上而下。
1、向堆中添加一个元素
添加一个新的元素时,一般使用自下而上的方式,思想也比较简单,就是每次和其父节点比较,如果比父节点大,就交换,并继续与其父节点比较,直到比其父节点小,或者已经找到最顶层。
代码示例:
public class MyHeap {
private int[] heapArr;
private final int capacity;
private int heapSize;
public MyHeap(int capacity) {
// 初始化数组大小
heapArr = new int[capacity];
// 初始化堆的大小
this.capacity = capacity;
// 初始化堆的当前大小
heapSize = 0;
}
public void push(int val) {
// 超过了堆的大小
if (heapSize == capacity) {
return;
}
// 先放到数组最后一位
heapArr[heapSize] = val;
heapInsert(heapArr, heapSize++);
}
private void heapInsert(int[] arr, int idx) {
// 用当前节点和其父节点进行比较,如果比父节点大则进行交换,再继续比较。
while (arr[idx] > arr[(idx - 1) / 2]) {
swap(arr, idx, (idx - 1) / 2);
idx = (idx - 1) / 2;
}
}
private void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
2、从堆中取出一个元素
堆化的另一种就是自上而下的,比如要从大顶堆中取出一个最大的数,那就直接从堆顶取即可,但取完之后,肯定还需要从其左子节点或者右子节点中取出一个较大的变成新的堆顶值,依次向下类推。
比如当前堆是这样的,我们现在需要取出最大的值,也就是9
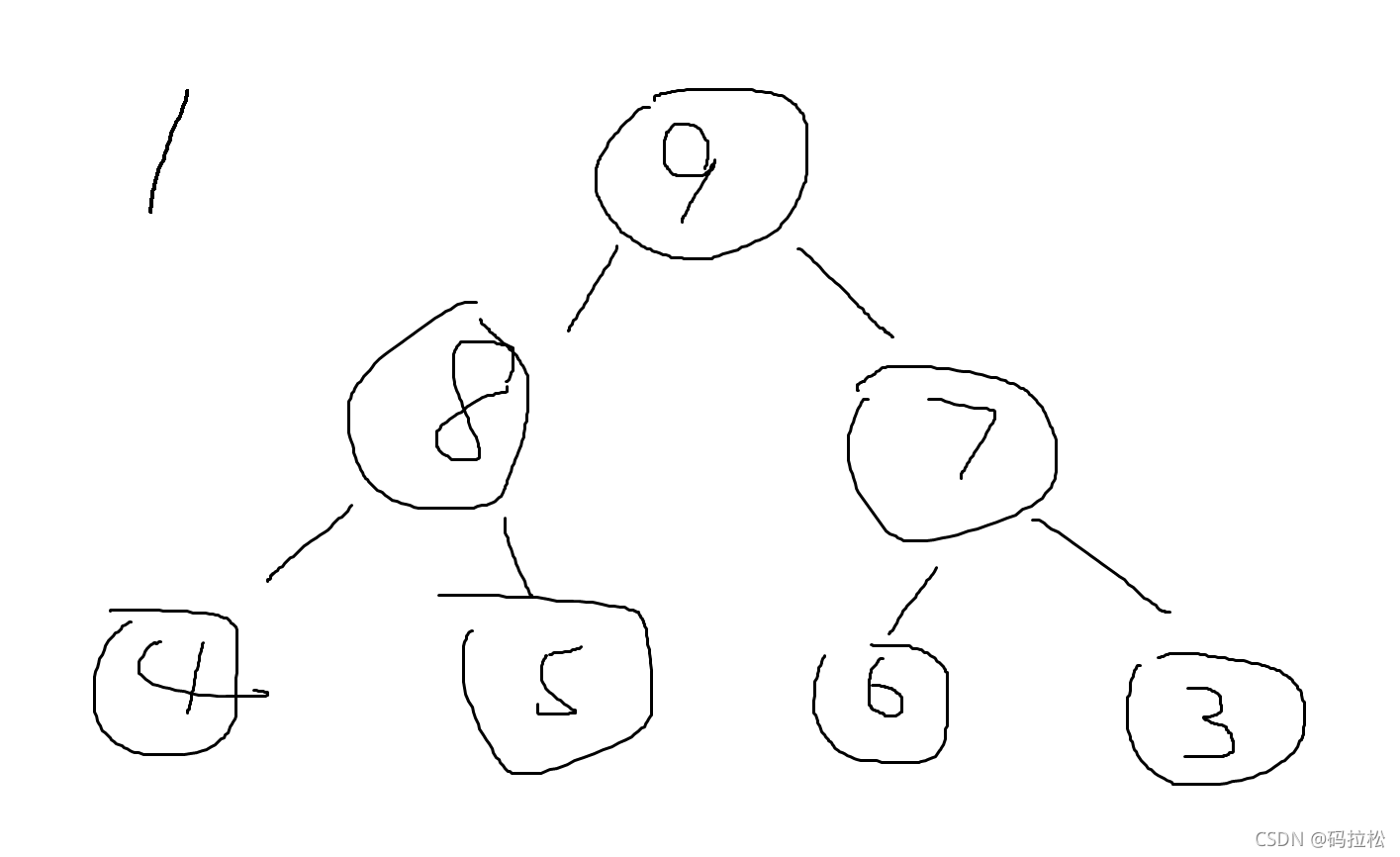
过程应该是把较大的子节点向上移,也就是8,然后再把8下面的子节点中较大的向上移,最后变成这样。
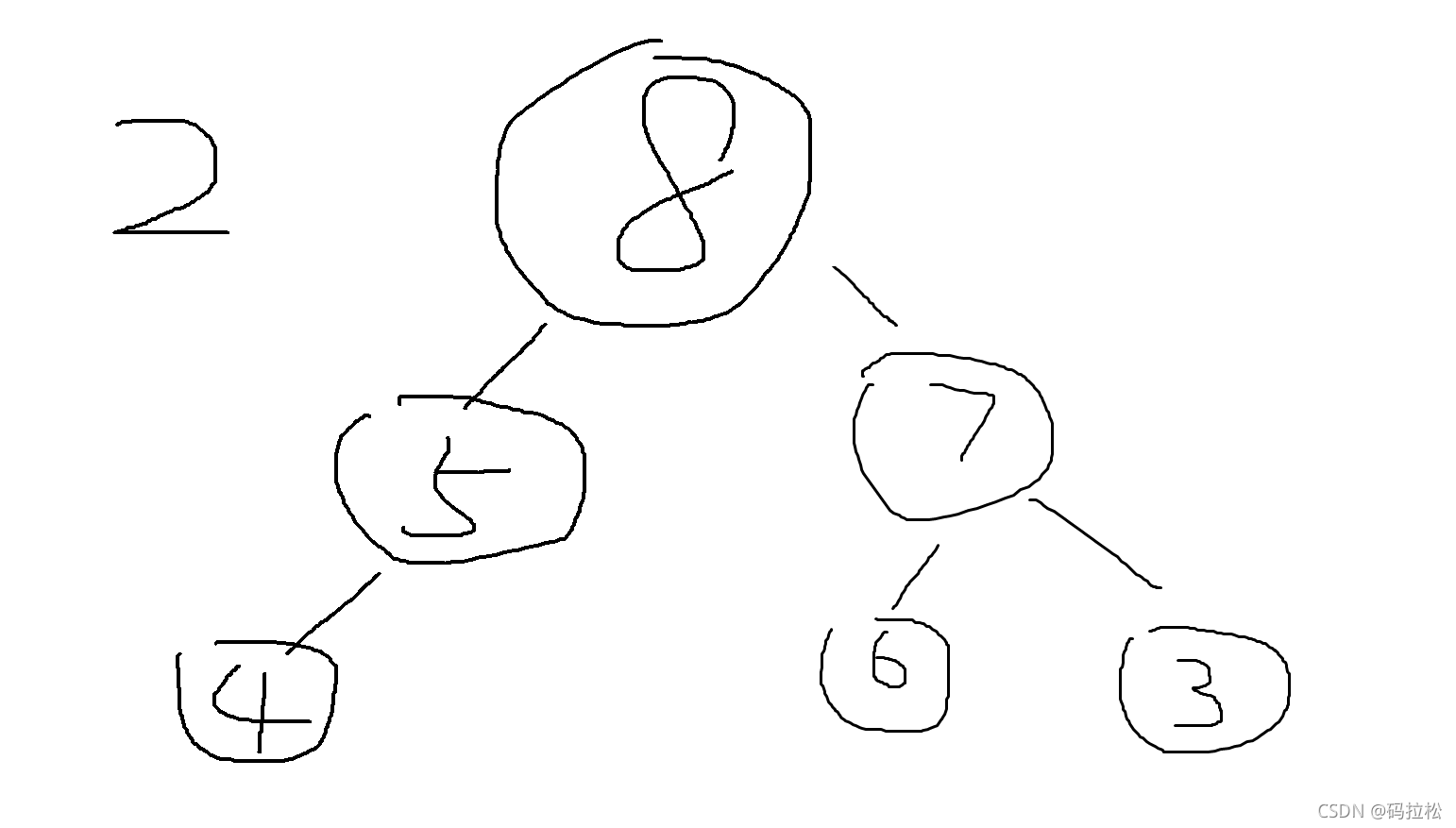
但是这边有个问题就是,你应该已经看出来了,最后的结果已经不满足堆的条件了(不是完全二叉树)。
所以实际上我们需要改变一下思路,每次应当把最后一个节点的值放到最上面,然后再进行判断就好了。
第一步应该是这样,把最后一个节点3移上来。
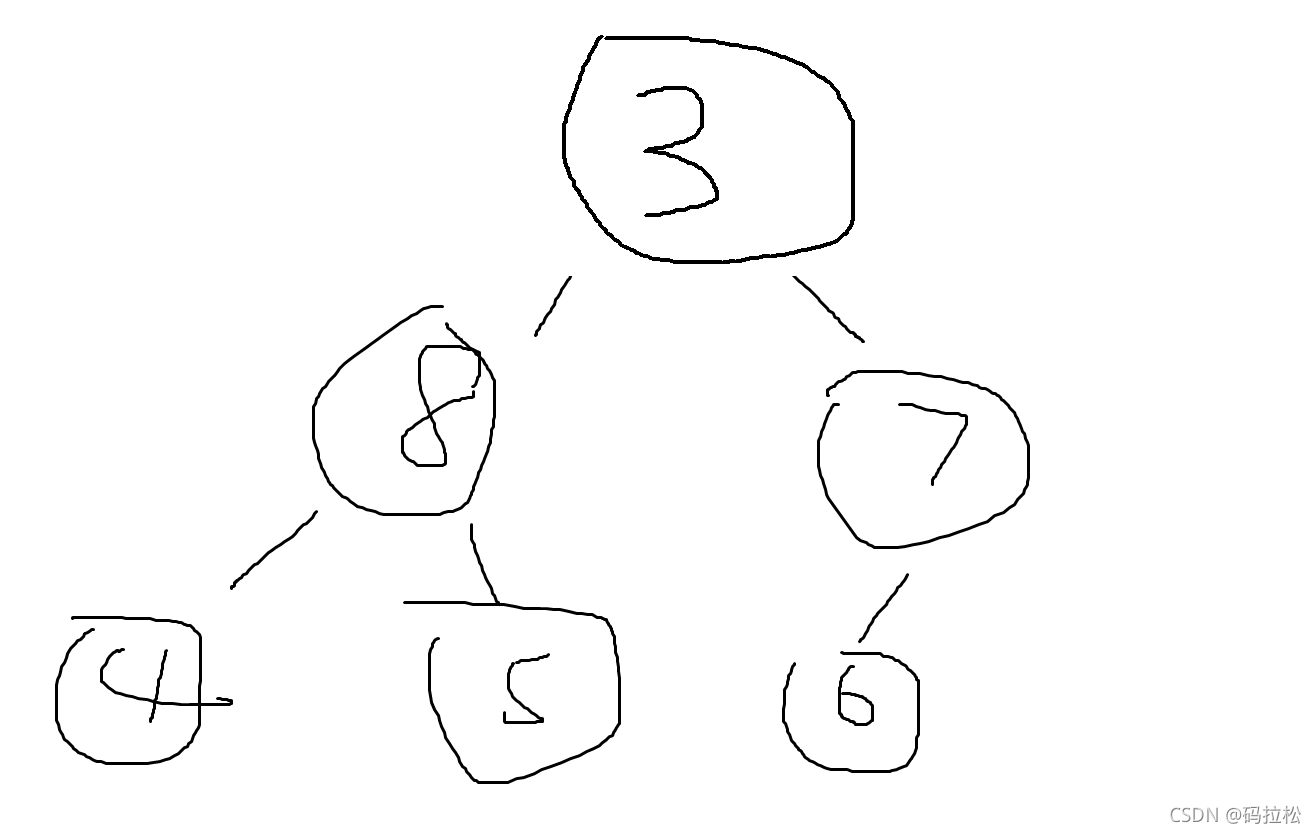
然后进行判断,所以最后应该是这样,保持了大顶堆的结构。

代码示例:
// 取出堆顶的值
public int pop() {
int ans = heapArr[0];
swap(heapArr, 0, --heapSize);
heapify(heapArr, 0, heapSize);
return ans;
}
private void heapify(int[] heapArr, int idx, int heapSize) {
// 拿到当前节点的左子节点
int left = idx * 2 + 1;
// 如果左子节点的下标超过当前堆的大小,说明当前节点已经没有子节点了。
while (left < heapSize) {
// 用于存放,左右子节点中,较大的节点值
int largest;
// 看看是否存在右子节点,如果不存在直接取左子节点为较大的节点即可
if (left + 1 == heapSize) {
largest = left;
} else {
// 取左右子节点中较大的一个
largest = heapArr[left] > heapArr[left + 1] ? left : left + 1;
}
// 取出子节点中较大的一个,再与父节点比较,看看谁大
largest = heapArr[largest] > heapArr[idx] ? largest : idx;
// 如果 largest == idx 说明左右子节点都不比自己大了
if (largest == idx) {
break;
}
// 把子节点中较大的交换上去
swap(heapArr, largest, idx);
// 重新赋值idx位置
idx = largest;
// 继续从子节点的左子节点开始判断
left = idx * 2 + 1;
}
}
堆的应用场景
下篇文章中我们在看看堆有哪些应用场景:数据结构与算法—堆的应用场景















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











