






0、需要知道的相关知识
什么是词向量?
词向量一般被认为是一个词的特征向量,也就是说用计算机可以理解的方式来代表一个词的含义。比如"中国"这个词,是很难被神经网络直接作为输入,我们需要将词向量化(或者说数字化),才能更好的喂进神经网络。
One-Hot编码的缺点
说到词向量最先能想到的就是One-Hot编码,虽然这个东西简单好理解,但是在Word2Vec论文档中占据重要的部分。
怕不知道的人这里解释一下,One-Hot编码我举个例子就知道。
例如有三个词("我","石头","七"),
那么one-hot编码就是[(1,0,0),(0,1,0),(0,0,1)]分别来代表那三个词。
One-Hot编码的缺点也显而易见
1、维度灾难,假如有一万个单词,那维度就是一万。在计算的时候会带来巨大的不便,而且向量矩阵极其稀疏,占据了太多不必要的内存。当然对于维度灾难,我们一般可以使用PCA等降维手段来缓解。
2、语义表达不足。这一点很简单, ”人类"与”生物”两个词,通过One-hot编码得到的向量,计算Cosine Similarity得到相似度为0。One-Hot编码表示出来的词向量是两两正交的,从余弦相似度的角度来看,是互不相关的,所以One-Hot不能很好的表达词语的相似性。
1、Word2Vec模型样式
Word2Vec主要有Skip-Gram和CBOW两种模型。Skip-Gram是给定中心词来预测上下文。CBOW是给定上下文,来预测中心词。这篇文章就仅介绍Skip-Gram模型,也就是图片右边的。

2、Skip-Gram
2.1 详细模型介绍
隐藏层没有使用任何激活函数,但是输出层使用了sotfmax。
我们基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。
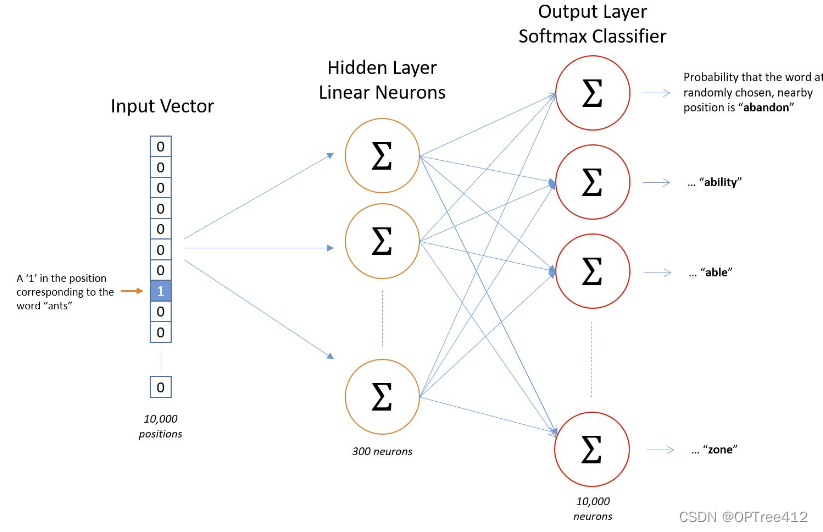
2.1.1 隐藏层
将一个1 x 10000的向量和10000 x 300的矩阵相乘,它会消耗相当大的计算资源,为了高效计算,它仅仅会选择矩阵中对应的向量中维度值为1的索引行,如图所示。
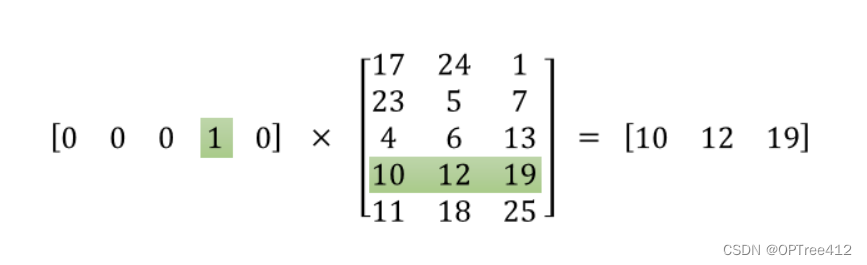
这样模型中的隐层权重矩阵便成了一个”查找表“(lookup table),进行矩阵计算时,直接去查输入向量中取值为1的维度下对应的那些权重值。隐层的输出就是每个输入单词的“嵌入词向量”。
2.1.2 输出层
经过神经网络隐层的计算,ants这个词会从一个1 x 10000的向量变成1 x 300的向量。输出层是一个softmax回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
2.1.3 直觉上思考模型
如果两个不同的单词有着非常相似的“上下文”(也就是窗口单词很相似,比如“Kitty climbed the tree”和“Cat climbed the tree”),那么通过我们的模型训练,这两个单词的嵌入向量将非常相似。
那么两个单词拥有相似的“上下文”到底是什么含义呢?比如对于同义词“intelligent”和“smart”,我们觉得这两个单词应该拥有相同的“上下文”。而例如”engine“和”transmission“这样相关的词语,可能也拥有着相似的上下文。
实际上,这种方法实际上也可以帮助你进行词干化(stemming),例如,神经网络对”ant“和”ants”两个单词会习得相似的词向量。
2.2 目标函数
Skip-gram模型的训练目标是找到对预测句子或文档中周围单词有用的单词表示形式。该模型的目标函数是这个,最大化在给出中心词的条件下背景词出现的概率
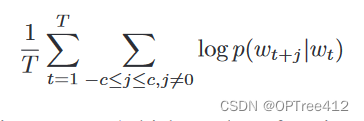
其中,T表示整个词库的词汇量,c表示窗口一半的大小,wt是中心词,wt+j是中心词附近的背景词。
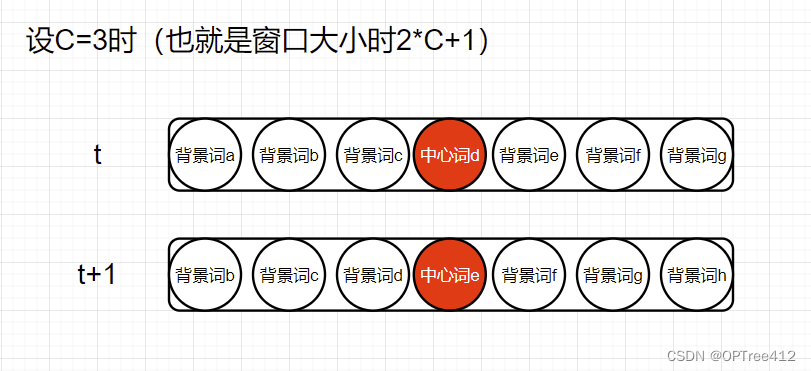
左边第一个累加是要给每一个单词计算这种中心词推出背景词的概率,第二个累加就是计算当前中心词与C*2个背景词之间的概率,就是像下图一样的感觉。
另外,目标函数中概率公式p如下
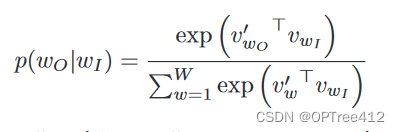
其中,v是向量的意思,wo表示上下文中的背景词,wI表示中心词,W是词汇中的单词数。
2.3 这个模型存在的问题
2.3.1 概率公式p中softmax函数的问题
我们能够观察到一个特点,就是每次更新参数,都会涉及到词典中的全部词汇。这是因为我们在做Softmax的时候,是分母是针对所有词汇的操作。
因为分母涉及到整个词汇表,计算∇log p(WO | WI)的成本与W的大小成正比,通常很大。计算效率底下!!
2.3.2 梯度下降的问题
我们每次其实只需要对窗口中出现的几个单词进行升级,但是在计算梯度的过程中,我们是对整个参数矩阵进行运算,这样参数矩阵中的大部分值都是0,计算效率底下!!
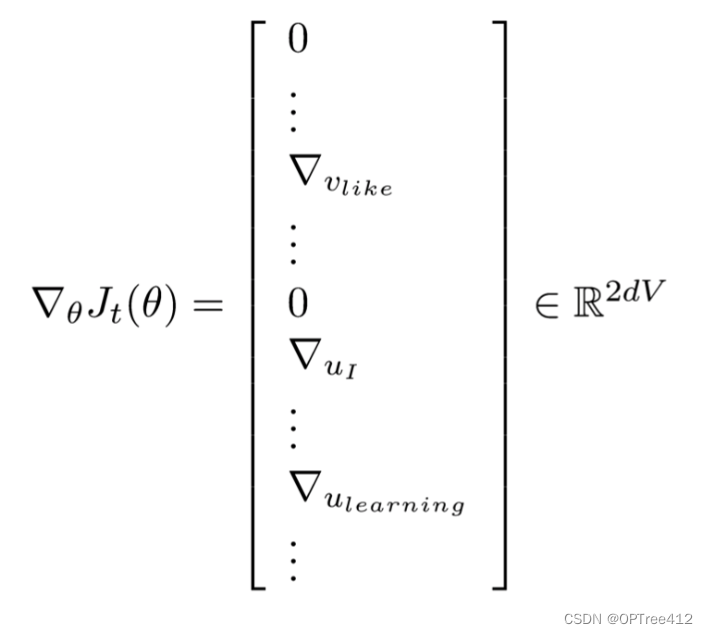
2.3.3 模型参数太过庞大
举个栗子,我们拥有10000个单词的词汇表,我们如果想嵌入300维的词向量,那么我们的输入->隐层权重矩阵和隐层->输出层的权重矩阵都会有 10000 x 300 = 300万个权重,在如此庞大的神经网络中进行梯度下降是相当慢的。更糟糕的是,你需要大量的训练数据来调整这些权重并且避免过拟合。百万数量级的权重矩阵和亿万数量级的训练样本意味着训练这个模型将会是个灾难(太凶残了)。
3、优化方式
3.1 负采样(Negative Sampling)
Word2vec涉及到两种优化方式,一种是负采样(Negative Sampling),一种是层序Softmax。这里就说说负采样。
什么是负采样
负采样是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
负采样的核心思想
在计算目标单词和窗口中的单词的真实单词对“得分”,再加K个“噪声”,即词表中的随机单词和目标单词的“得分”。
当我们输入“OK”进入神经网络,我们会期望窗口内的背景词输出是1,其他的所有单词输出都是0。
其中K个“噪声”是随机选择一小部分的negative words来更新对应的权重。我们也会对我们的“positive” word进行权重更新,大大缩小原来的计算量。
在论文中,作者指出指出对于小规模数据集,选择5-20个negative words会比较好,对于大规模数据集可以仅选择2-5个negative words。
负采样损失函数公式如下
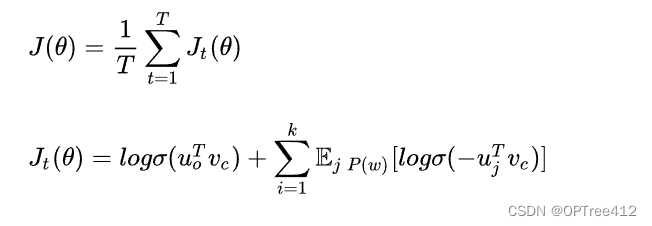
其中,vc表示中心词词向量,uo表示背景词词向量,uj表示噪声词词向量。
采用上述公式解决了之前说的两个问题:
1、我们仅对K个噪声参数进行采样
2、我们放弃softmax函数,采用sigmoid函数,这样就不存在先求一遍中所有单词的‘“得分”的情况了。
梯度计算如图说所示
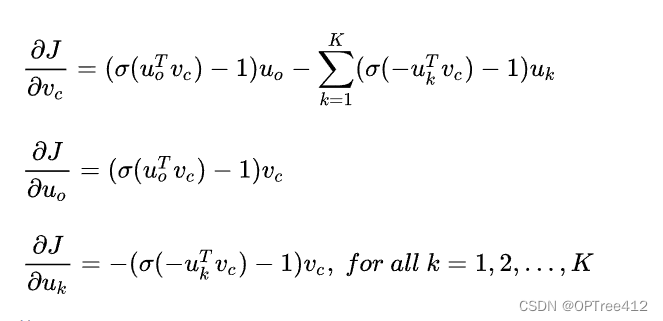
其中,vc表示中心词词向量,uo表示背景词词向量,u表示噪声词词向量。
3.2 如可选择那K个negative words呢?
一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。
公式如下
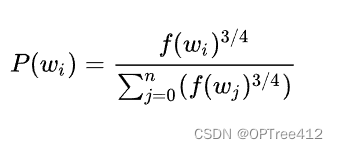
其实中f(w)表示单词出现的频次,公式中开3/4的根号完全是基于经验的,论文中提到这个公式的效果要比其它公式更加出色。
3.3 二次采样(subsampling)
对文本中的每个单词会有一定概率删除掉, 这个概率是和词频有关,越高频的词越有概率被删掉。二次采样的公式如下所示:

其中t是超参数,f(w)是单词w的词频与总数词之比。
这个的作用就是把那些“the”,“of”,"a"这样没什么营养的词删掉。这样的单词在一句话当中的信息是存在冗余的。也就是说,在一个窗口中,一个词和较低频词同时出现比和较高频词同时出现对训练词嵌入模型更有益。
4、CBOW和skip-gram相较而言,彼此相对适合哪些场景
先说CBOW,我们想一下,它的情况是使用周围词预测中心词。如果”爱’是中心词,别的是背景词。对于”爱”这个中心词,只是被预测了一次。
对于Skip-gram,同样,我们的中心词是“爱”, 背景词是其他词,对于每一个背 景词,我们都需要进行一次预测,每进行一次预测,我们都会更新一次词向量。
也就是说,相比CBOW,我们的词向量更新了2k次(假设K为窗口,那么窗口内包含中心词就有2k+1个单词)Skip-gram被训练的次数更多,那么词向量的表达就会越丰富。
如果语料库中,我们的的低频词很多,那么使用Skip-gram就会得到更好的低频词的词向量的表达,相应的训练时长就会更多。
简单来说,我们视线回到一个大小为K的训练窗口(窗 口内全部单词为2k+1个),CBOW只是训练一次,Skip-gram 则是训练了2K次。当然是Skip-gram词向量会更加的准确一点, 相应的会训练的慢一点。
自己实操后的感悟(作者愚笨,勿喷)
-
Word2Vec训练后会有几个词向量呢?
每个单词都会对应两个词向量,一个是作为中心词的时候的词向量,一个是作为背景词的时候的词向量。大家一般选择第一种。 -
初始输入就一定是one-hot吗?
从源码的角度来看,我们是对每个词都初始化了一个词向量作为输入,这个词向量是会随着模型训练而更新的,词向量的维度就是我们想要的维度,比如说200维。
以Skip-gram为例,我们输入的中心词的词向量其实不是One-hot编码,而是随机初始化的一个词向量,它会随着模型训练而更新。















 1525
1525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









