






大模型中的计算精度——FP32, FP16, bfp16之类的都是什么???
这些精度是用来干嘛的??
省流:硬件不够,精度来凑。
举个例子:关于长度单位有各种各样的单位,高精度就是一个超级精细的测量长度的仪器,可以测量到非常小的单位。低精度就是类似我们手中的尺子,到毫米为止了,再往下就测量不到了。现在让你测量一根头发有多粗,用精密的仪器测量会比较麻烦,但很精确;用尺子就不会很准确,但很快就能得到结果。无论使用那种工具,总会得到一个结果的。
如果我们想要更高的精度,就需要更多的存储空间和计算资源,这可能会增加计算的复杂性和成本。所以精度是我们在使用计算机进行数值计算时必须考虑的一个重要因素。准确结果 or 节省计算资源?
在大模型的训练和推理中因为没有足够的硬件设施(mei qian),有些大模型就没办法享受到。因此就有了这种通过降低精度而加快模型训练速度、降低显存占用率的方法——混合精度
混合精度 mixed precision training
什么是混合精度?
这是一种加速深度学习训练的技术。其主要思想是在精度降低可忍受的范围内,使用较低精度的浮点数来表示神经网络中的权重和激活值,从而减少内存使用和计算开销,进而加速训练过程。
FP32、FP16、BF16和FP8都是计算中使用的数字表示形式,特别是在浮点运算领域。这些格式主要通过它们使用的位数来区分,这影响了它们的精度、范围和内存要求。
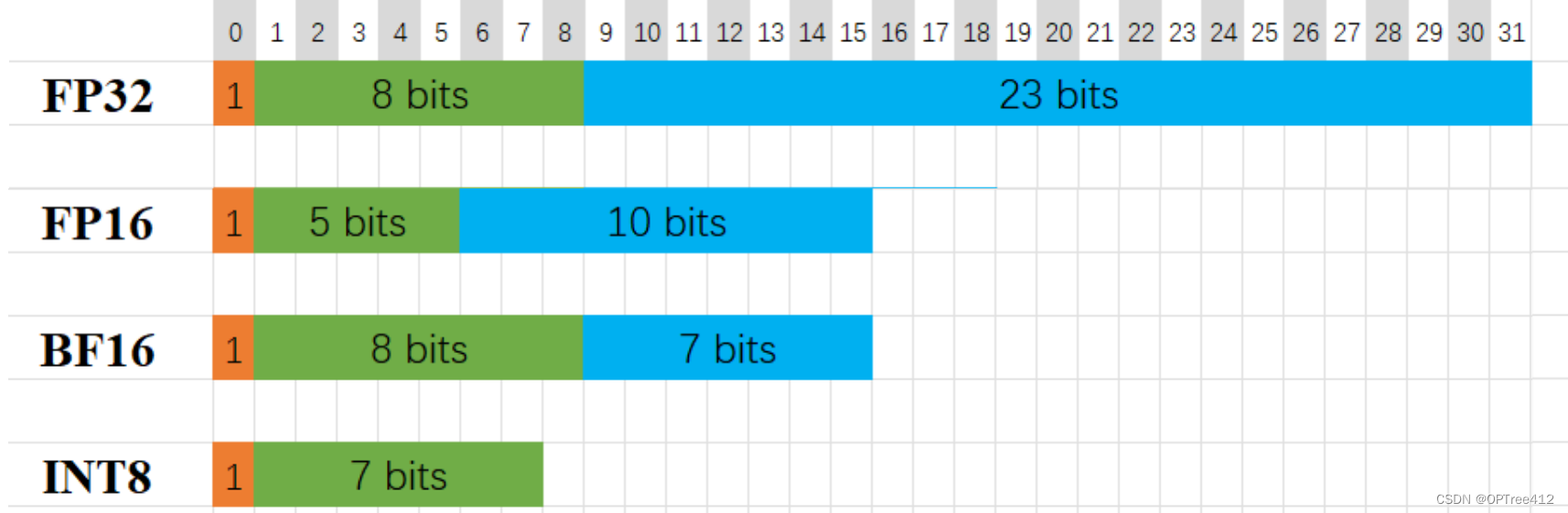
详细的精度范围我就不说了,知道了也没啥用,了解每个精度用来干嘛的就行
| 精度 | 应用 | 性能 |
|---|---|---|
| FP16 | 深度学习、神经网络训练 | 相对于FP32有更快的计算速度和更低的内存使用量 |
| FP16 | 深度学习、神经网络训练 | 相对于FP32有更快的计算速度和更低的内存使用量 |
| BF16 | 混合精度训练、深度学习 | 性能各异,但通常允许比FP16更快的训练和更宽的范围 |
| FP16 | 深度学习(DL)、神经网络训练 | 相对于FP32有更快的计算速度和更低的内存使用量 |
怎么转换呢?
混合精度训练的流程如下:
- 将FP32的权重转换为FP16格式,然后进行前向计算,得到FP32的损失(loss)。
- 使用FP16计算梯度。
- 将梯度转换为FP32格式,并将其更新到权重上。
为什么大语言模型通常使用FP32精度训练
大型语言模型通常使用FP32(32位浮点)精度进行训练,因为其较高的数值精度可以带来更好的整体模型。以下是一些关键点:
- 较高的数值精度:FP32比如FP16(16位浮点)这样的低精度格式提供更高的数值精度。这种更高的精度可以在训练期间导致更准确的计算,从而产生更有效的模型。
- 稳定性:在像FP16这样的低精度格式中进行训练可能会引入数值稳定性问题。例如,梯度下溢或溢出的机会更高,优化器的计算精度较低,累加器超出数据类型的范围的风险更高。
- 兼容性:像PyTorch这样的深度学习框架带有内置的工具来处理FP16的限制,但即使有了这些安全检查,由于参数或梯度超出可用范围,大型训练工作常常失败。
然而,尽管有这些优势,FP32也带来了更大的内存和训练时间要求。为了缓解这些问题,经常使用混合精度训练。混合精度训练将一些训练操作放在FP16而不是FP32中。在FP16中进行的操作需要较少的内存,并且在现代GPU上的处理速度可以比FP32快达8倍。尽管精度较低,但大多数在FP16中训练的模型没有显示任何可测量的性能下降。
量化
与混合精度有啥区别?
省流:量化精度是整形的,不再是浮点数了。
这是通过整型数值表示浮点的计算方式,减少数字表示的位数来减小模型存储量和计算量的方法。因为精度可能会导致计算和存储的开销非常高,因此量化使用更短的整数表示权重和激活值,从而减少内存和计算开销。
量化怎么用?
这里使用load_in_8bit来举例
使用load_in_8bit方法可以实现模型的量化。该方法可以将模型权重和激活值量化为8位整数,从而减少内存和计算开销。具体实现方法如下:
from transformers import AutoTokenizer, AutoModel
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",
revision='v0.1.0',
load_in_8bit=True,
trust_remote_code=True,
device_map="auto")
需要注意的是,使用load_in_8bit方法量化模型可能会导致模型精确度下降。另外,不是所有的模型都可以被量化,只有支持动态量化的模型才可以使用该方法进行量化。
参考博客:
关于LLM你或许不知道的事情-为什么大语言模型的训练和推理要求比较高的精度,如FP32、FP16?浮点运算的精度概念详解//(转载)















 3875
3875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









