







导读
TL;DR: 本文提出了FeatEnHancer,一种用于低光照视觉任务的增强型多尺度层次特征的新方法。提议的解决方案重点增强相关特征,通过提供强大的语义表示,使其优于现有的低光照图像增强方法。该方法不仅改进了单个特征的质量,而且还有效地结合了来自不同尺度的特征,确保在诸如物体检测和分割等任务上达到更好的性能。论文通过在几个基准数据集上的性能指标确认了其方法的有效性,并与 SOTA 方法相比取得了显著的改进。

众所周知,在低光条件下提取有用的视觉线索对下游任务的应用极具挑战性。现有方法要么通过关联视觉质量与机器感知来提升图像质量,要么使用需要在合成数据集(例如叠加噪声、雨雪、光照等)上进行预训练的方法。
本文提出一个名为FeatEnHancer的模块,该模块借鉴了多头注意力机制,层次性地结合多尺度特征。这种方法确保了网络能够提取更具代表性和判别行的增强特征。具体地,该方法着眼于改进每个尺度或级别下的特征质量,同时根据任务的相对重要性结合不同尺度的特征(动态机制)。值得一提的是,所提方法是即插即用的,理论上适用于任何低光视觉任务,从上图可视化的分层表示结果来看网络确实能够提取到有意义的表征。
动机
尽管在高质量图像的 high-level 视觉任务中取得了进展,但当将低光图像增强(LLIE)方法与高级视觉任务结合时,性能会下降。这是由于现有的LLIE方法虽然增强了人眼的视觉效果,但可能与机器视觉不太匹配(模式不匹配),因为它们可能会损害物体的重要特征,如边缘和纹理。
此外,大家都知道低光照图像的像素分布差异很大,这会导致严重的漏检问题。当前的LLIE方法采用的常规损失函数没有“区分”出每个像素的重要程度,这不利于学习对高级任务至关重要的细节信息。
因此,受到LLIE和基于视觉的网络的进展的启发,该论文旨在通过共同优化特征增强和下游任务目标来弥合这一差距。
方法
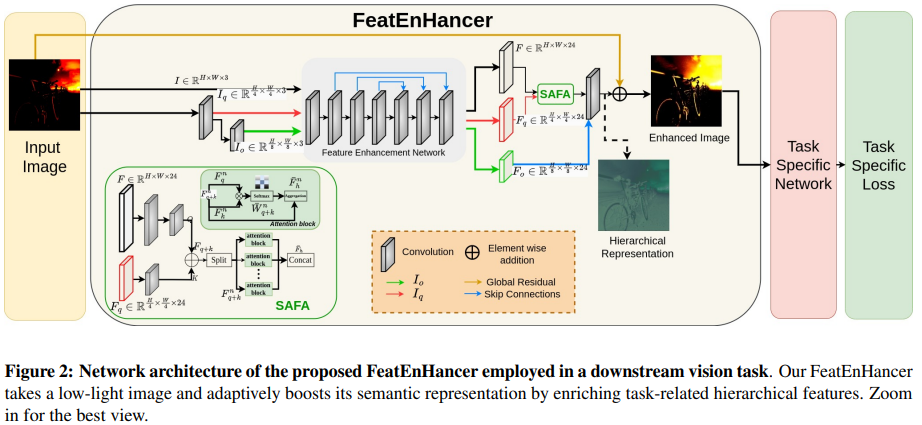
整体的架构如图所示,不难看出就是一个分层的特征表示,中间再结合一些多尺度的特征融合机制,最终得到一张经过低光照增强的图像再送入下游任务做应用。关于这一块其实前面的文章已经讲的很多了,这里我们简要阐述即可。先讲解下整体流程:
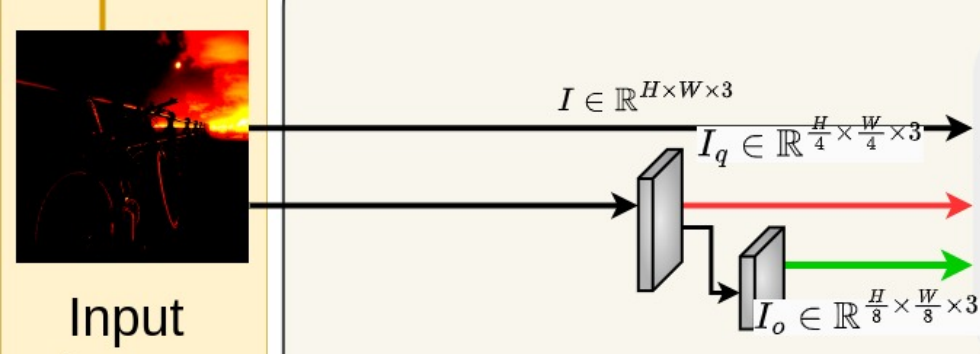
首先,FeatEnHance 对输入的低光照图像进行不同层次的下采样,以构建多尺度层次表示。
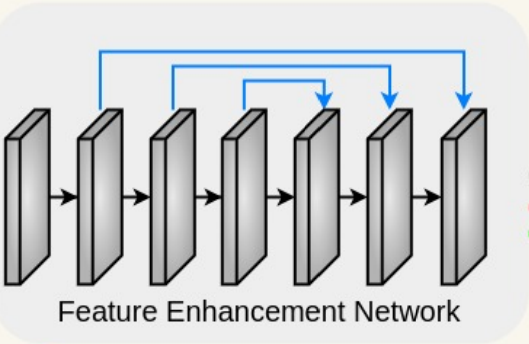
其次,将这些表示提供给特征增强网络(FEN),以丰富内部尺度的语义表示。
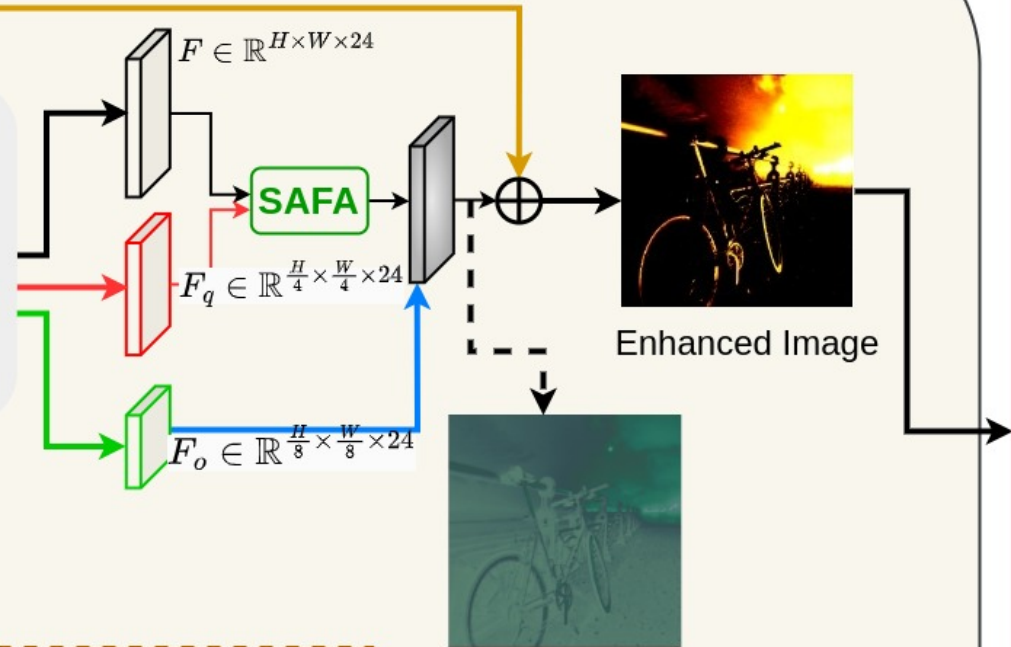
紧接着通过两种策略融合增强的表示:
- 对于高分辨率特征使用尺度感知注意特征聚合(SAFA);
- 对于低分辨率特征使用跳跃连接。
最后,FEN的参数可以通过与任务相关的损失函数进行调整,以侧重于增强与任务相关的特征。
特征增强网络
为了增强每个尺度上的特征,我们需要一个增强网络,该网络能够学习增强下游任务中重要的空间信息。为此,作者参考了Zero-DCE++(TPAMI 2021)中应用的DCENet,并构建了一个全卷积的多尺度特征提取网络FEN。与 DCENet 不同的是:
- FEN 首先引入了一个单独的卷积层,生成一个特征图 F F F,其分辨率 H × W H × W H×W与输入保持一致,但是从3通道变为32通道。
- 应用了六个卷积层,每个卷积层后面都跟
ReLU激活函数,并带有对称的skip connection。 - FEN 分别结合于
stage的输出,从而获得多尺度特征表示,这种多尺度学习允许网络从高和低分辨率特征中增强全局和局部信息。 - 此外,为了保留相邻像素之间的语义关系,FEN 避免使用下采样和
Batch Norm。 - 最后,FEN 丢弃了 DCENet中的最后一个卷积层,并将最终增强的特征表示从每个尺度传递到多尺度特征融合。
当然,此处的特征增强网络是解耦于整个架构的,理论上可以替换为任意的特征提取网络。
多尺度特征融合
这一部分主要是补充上述 FEN 中的第 3 步详细操作。我们知道:
- 低分辨率特征( F o F_{o} Fo):包含细节和边缘。
- 高分辨率特征( F q F_{q} Fq):捕获抽象信息,例如形状和模式。
为此,我们可以应用如下融合策略:
- 尺度感知注意力特征聚合(SAFA):灵感来源于多头注意力机制,使网络能够共同从不同尺度学习信息。
- 跳跃连接(SC):集成
F
o
F_{o}
Fo的低级信息和
SAFA的增强表示,得到最终增强的分层表示。
这里便涉及到 SAFA 模块,其设计理念在于如何在高计算效率下,有效地聚合多尺度特征?
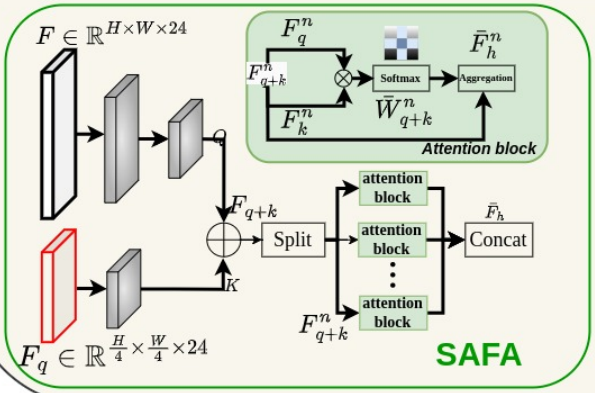
下面结合上图简单说明下该应用策略:
- 高分辨率特征在进行注意力操作之前先被映射到较小的分辨率。
- SAFA 将中间特征 F F F 降采样转化为 Q Q Q,将 F q F_{q} Fq 转化为 K K K。
-
Q
Q
Q 和
K
K
K
concat拼接成一组分层特征 F q + k F_{q+k} Fq+k,这组特征被分割成 N 个块,用于计算注意力权重(参考多头注意力机制的设计)。 - 使用标准的
QKV自注意力操作计算出权重并计算增强的分层表示 F h F_{h} Fh。
需要注意的是,再注意力权重计算之前,卷积层的权重不是共享的。此外, F h F_{h} Fh 与 Q Q Q 和 K K K 尺寸相同,但包含来自多尺度高分辨率特征的更丰富的表示。这里通过跳跃连接操作,我们整合 F o F_{o} Fo 和 F h F_{h} Fh 得到最终增强的分层表示,该表示涵盖全局和局部特征。同时这里上采样操作使用简单的双线性插值,当然,这肯定会比使用转置卷积更快。
实验
本文分别在四个不同的视觉任务下进行了实验,以下是各任务数据集的详细统计:
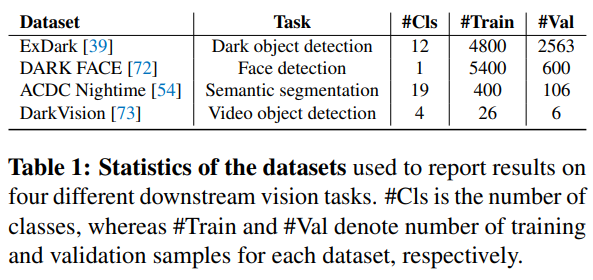
这里涉及到暗光目标检测、人脸检测、语义分割、视觉目标检测。首先给出其定量分析结果:
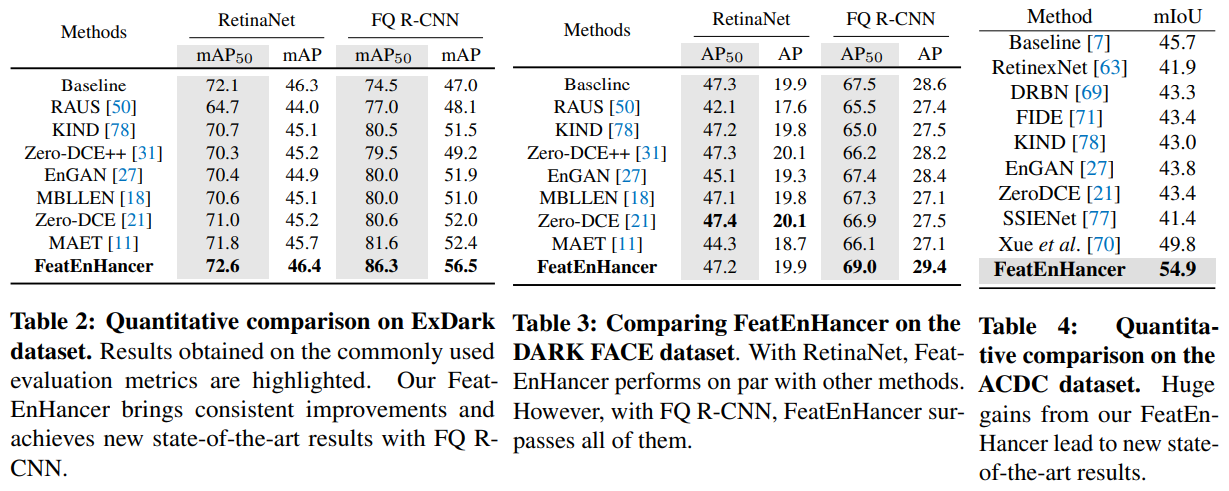
可以看出本文方法在不同任务上涨点还算显著的,大都提升了几个点。接着看看定性分析结果:

最后再来看下中间的可视化结果图,可以明显看出经过增强后的图像可以学习出更好的表征:

总结
本文提出了一种名为FeatEnHancer的新型通用特征增强模块,旨在丰富低光视觉下有利于下游任务的分层特征。所设计的内部尺度特征增强和尺度感知注意力特征聚合策略与视觉主干网络相结合,产生了强大的语义表示。此外,FeatEnHancer既不需要在合成数据集上进行预训练,也不依赖增强损失函数。这些架构创新使FeatEnHancer成为一个即插即用的模块。对四种不同的下游视觉任务进行的广泛实验,涵盖了图像和视频,证明了所提方法相对于基线、LLIE方法和特定任务的最新方法都带来了稳定且显著的改进。
写在最后
欢迎对low-level视觉相关应用感兴趣的童鞋扫描屏幕下方二维码或者直接搜索微信号 cv_huber 添加小编好友,备注:学校/公司-研究方向-昵称,与更多小伙伴一起交流学习!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











