






作者 | 石桥 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/597554089?
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【BEV感知】技术交流群
自动驾驶:BEV感知
背景介绍
早期的自动驾驶感知通常是在图像空间进行,但是随着摄像头的增多,多相机融合和下游规控的应用需求,使得基于BEV空间的感知算法日趋流行。BEV感知首先要解决的问题是图像空间到BEV空间的变换,从相机视图到鸟瞰图视角转换,由于没有图片上每个像素点的深度信息,无法简单地利用几何投影将图像投回到鸟瞰视角。常用的PV2BEV方案:
depth:使用估计深度赋值RGB像素完成图像2d->3d变换,然后取XY维度生成BEV特征
VED[1]:用具有 MLP bottleneck层的变分编码器-解码器来实现 PV-to-BEV 转换
VPN[2]:用全连接网络来让network自己学习如何进行视角的变换
PON[3]:用特征金字塔提取多分辨率特征,然后沿高度轴折叠特征,并使用MLP沿深度轴展开实现视图转换
IPM[4]:用地面是平面的假设进行逆透视变换。由于地面存在起伏,所以该假设在部分场景不成立。
GKT[5]:每个BEV query通过相机内外参获取各个视角对应图像坐标(u,v),提取附近的Kh×Kw核区域的特征。
MLP Fully Connect Layer和Cross Attention的显著差别在于作用于输入量X的系数W:**全联接层的W,一旦训练结束后在Inference阶段是固定不变的;而Cross Attention的Transformer的系数W,是输入量X和索引量的函数,在Inference阶段会根据输入量X和索引量的不同发生改变。从这个角度来讲,使用Cross Attention来进行空间变换可能使模型获得更强的表达能力。
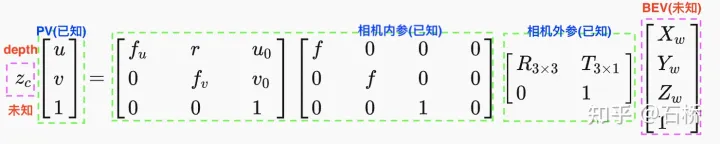
如上述等式所示,PV和BEV的坐标是可以相互转换的,但是目前深度z和BEV坐标都是未知的。我们如果想获取到BEV下的特征坐标有2种方式:方式1(2d->3D)是从PV估计深度Z,有了深度然后变换BEV坐标;方式2(3D->2D)是直接估计BEV坐标,有了BEV坐标自然知道深度,从而关联到PV坐标。
这里主要汇总介绍以下2类:
通过显式深度估计后,采用相机内、外参进行显式的PV2BEV视角变换,代表是:LLS。
通过self attention获取BEV query,然后对图像特征做cross attention,实现PV2BEV获取BEV特征。
早期的attention不需要依赖内外参,但是这种方式效率太低。鉴于相机的标定误差所导致的结果偏移是可估量和防范的,所以后续基本都会使用相机内外参来加速计算。下面是2021-2022年BEV发展的流程图:
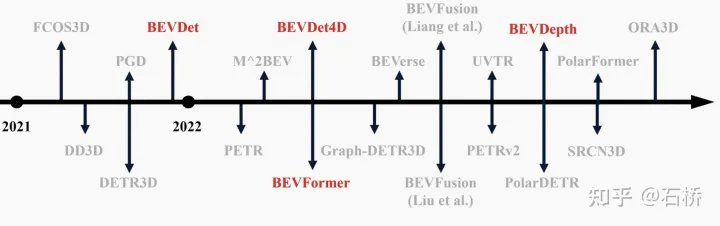
LSS架构[6]
论文代码解读[7]
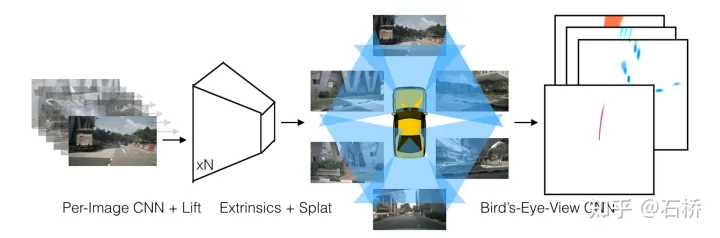
特征提取:图像
Lift:提取pv图像特征,在特征图相素射线上取D个深度值形成视锥点云,对每个视锥点估计C个特征的分布概率.
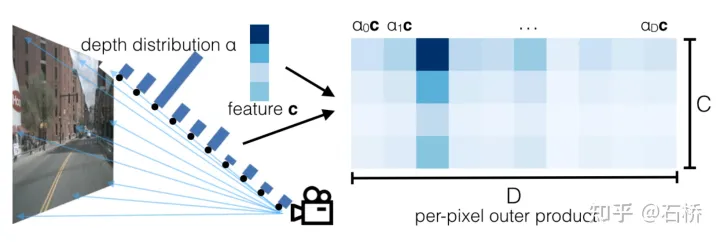
Splat:用内外参把所有视锥点投影到BEV网格中,对每个栅格中多个视锥点进行sum-pooling形成BEV特征图;
Shoot:用task head处理BEV特征图,实现端到端的运动规划。(BEV最初就是为了规控。)

BEVDet[8]
论文 代码 解读
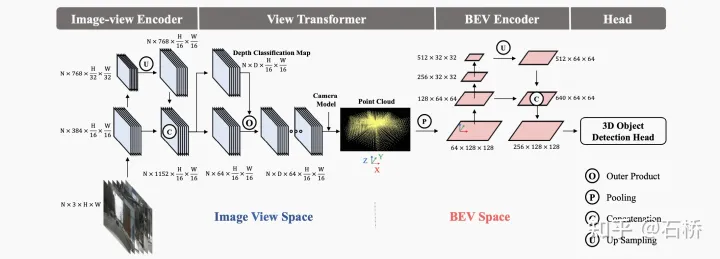
特征提取:图像(改进LSS架构)
图像特征提取:对输入图像做翻转、裁剪、旋转等数据增强,然后用resnet提取特征。
视角转换器:对输入的特征图执行数据增强逆操作,从而保持图像特征在BEV空间上的一致性
BEV特征提取:采用resnet,提取的BEV特征也做数据增强,同时对不同类别的物体在相同的尺度下做NMS操作。
BEVDet4D
论文代码解读[9]
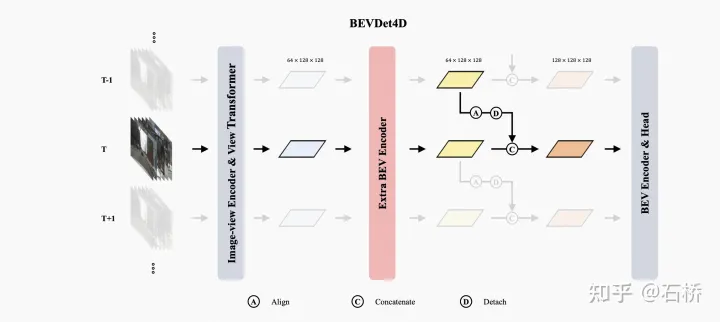
特征提取:图像(改进基于LSS架构的BEVDet)
融合时序特征:将历史帧BEV特征坐标,用位姿差T变换到当前帧BEV下,与当前帧相同位置BEV特征concate。
BEVDepth[10]
论文代码解读[11]
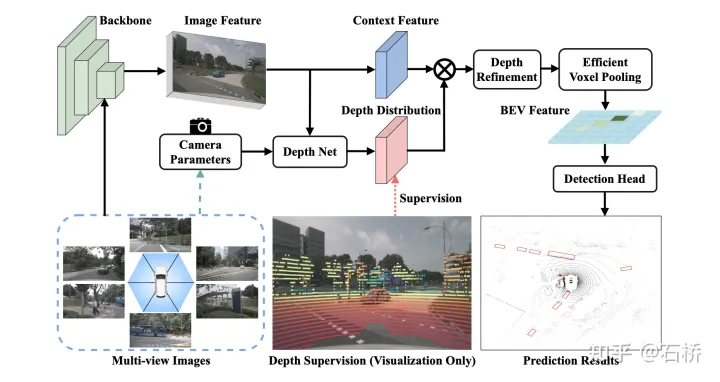
特征提取:图像(改进LLS架构)
Depth 监督:backbone提取特征输出给DepthNet估计每个特征点的深度d,相比于LLS的无深度监督训练, DepthNet的训练过程中显性的采用点云深度做监督;
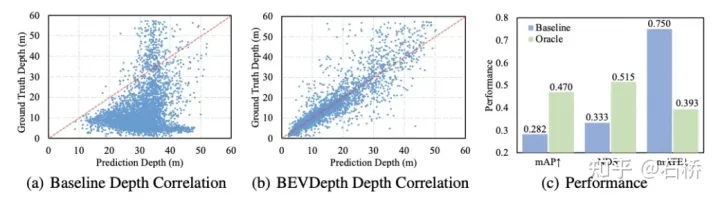
Depth Correction:为了解决相机内外参不准导致的,深度监督gt与特征错匹配,堆叠3个Residual Blocks,降低特征尺寸来增大感受野,然后在它的后面再接上Deformable Conv(DCN)模块,通过增大感受野,无法对齐的深度真值也能参与准确对齐正确位置上特征的计算。
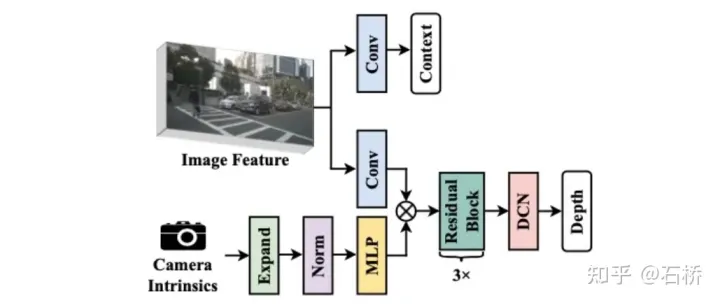
Camera-aware Depth Prediction:先用MLP把相机内参扩展到feature的维度,然后用它们对图像特征进行重新加权(re-weight),这一步使用Squeeze-and-Excitation模块,最后把相机外参和内参串联让DepthNet感知到在自车坐标系中的空间位置.
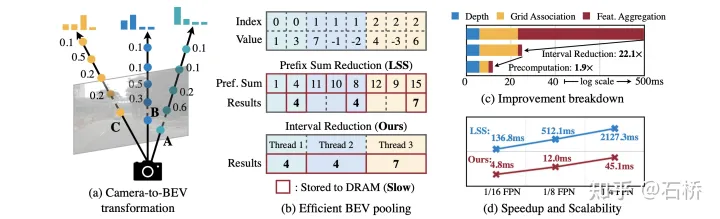
Efficient Voxel Pooling:为视锥的每个特征点分配一个CUDA thread,它的作用是把特征值加到相应的BEV网格中,利用了GPU计算的并行化完成稠密特征点的池化过程。
Multi-frame Fusion:将T-1时刻的视锥点变换对齐到T时刻,然后voxel pooling生成BEV,并合并成新BEV特征
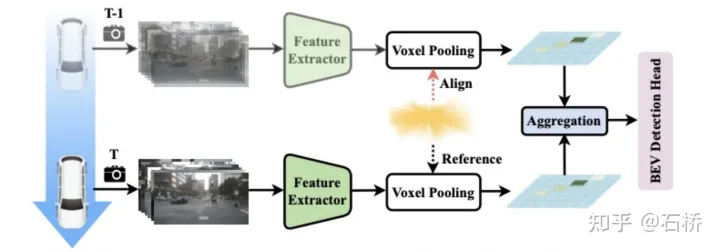
3D Detection head:把LSS中的分割head替换成了3D目标检测的CenterPoint Head,预测目标class、3D box的offset以及其它属性。
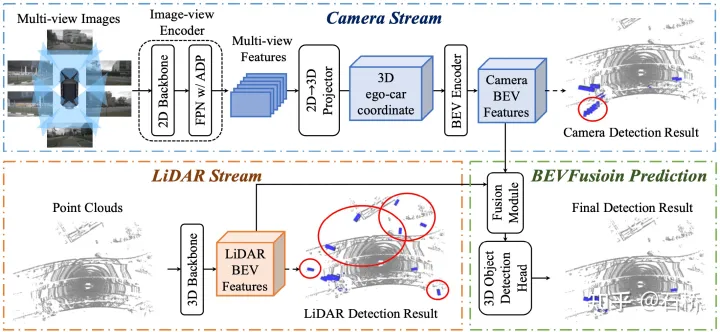
BEVFusion(Mit)[12]
资料:代码论文解读
BEVFusion(Mit)效果
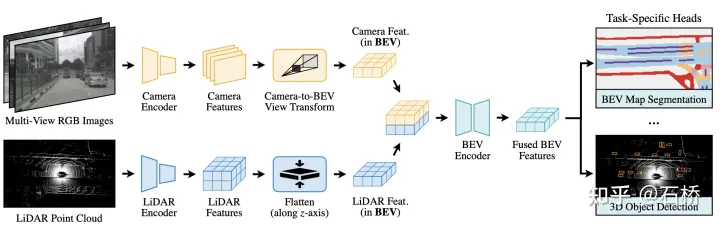
特征提取:(改进LSS架构)
图像:采用加速的LLS,会预先计算每个像素点的3D坐标和BEV网格索引,同时实现了一个直接在BEV网格上并行化的专用GPU内核:为每一个GPU线程计算间隔和并返回结果。
点云:对激光特征进行Flatten获取BEV特征。
融合:由于视觉的深度转换器的深度不准确,用带有残差的卷积去处理融合的BEV特征,来补偿未对齐特征。
BEVFusion(北大)[13]
资料:代码论文解读
特征提取:(改进LSS架构)
图像:改进了LSS,将2Dbackbone替换为Dual-Swin-Tiny,接FPN提取多尺度特征,ADP来对齐多尺度特征。通过图像的深度估计进行特征2d->3d的变换获取特征YYZC,然后用S2C将4D特征降维为3D特征YY*(ZC)。
点云:采用常用的PointPillars、CenterPoint、TransFusion来降低Z维度生成BEV特征。
融合:通过一个通道注意模块来选择重要的融合特征。做法如下:通过3* 3卷积对concate的lidar和camera特征缩减通道与lidar保持一致,然后通过全局平均池化和1*1卷积处理后送给sigmoid,最后与特征做channel-wise Multiply.

检测头:采用了流行的anchor-base、anchor-free、transform head,验证特征提取框架对于检测头的泛化性。
DETR3D[14]
论文 代码 解读
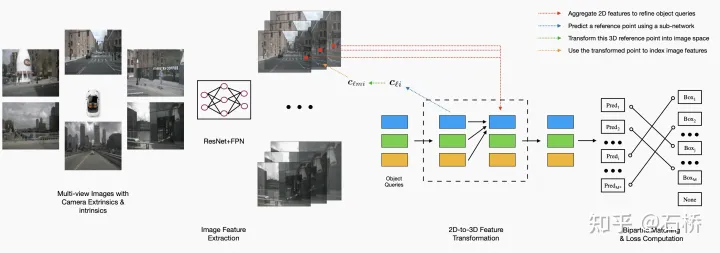
特征提取:图像(基于transformer框架)
Encoder:用ResNet+4层FPN提取特征。
Decoder:对预设的object query用一个全连接网络预测在BEV空间中的3D reference point(x,y,z,),经过sigmoid归一化后表示在空间中的相对位置;用6层transformer decoder layer,在每层layer之中,所有的object query之间做self-attention,再和图像特征之间做cross-attention:将每个query对应的3D reference point通过相机的内参外参投影到图片坐标,利用线性插值来采样对应的multi-scale image features,之后再用sampled image features去更新object queries。经过attention更新后的object query通过两个MLP网络来分别预测对应物体的class和bounding box的参数。为了让网络更好的学习,我们每次都预测bounding box的中心坐标相对于reference points的offset(x,y,z)来更新reference points的坐标。每层更新的object queries和reference points作为下一层decoder layer的输入,再次进行计算更新,总共迭代6次。
Loss:所有object queries预测出来的检测框和所有的ground-truth bounding box之间利用匈牙利算法进行二分图匹配,找到使得loss最小的最优匹配,并计算classification focal loss和L1 regression loss。
PETR[15]
论文代码解读[16]
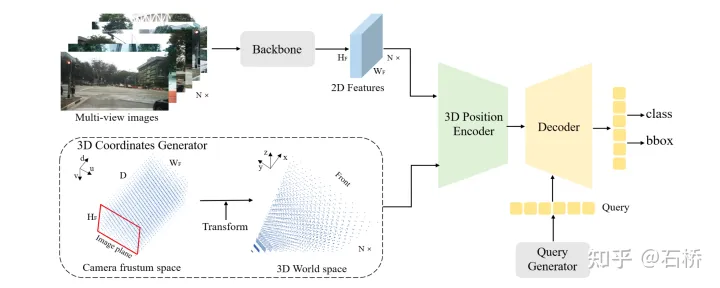
特征提取:图像(基于transformer框架)
3D position embedding:获取视锥体3d点云后,独立的进行位置编码,然后与2d特征进行concate。把DETR3D中cross attention的多视角投影过程用事先计算好的3D positional encoding取代,与query相加后也可以为2D点提供3D信息,因为只要外参不变,每次投影过程其实是相同的,没必要每个iteration都重复计算,大大提高了效率。[17]

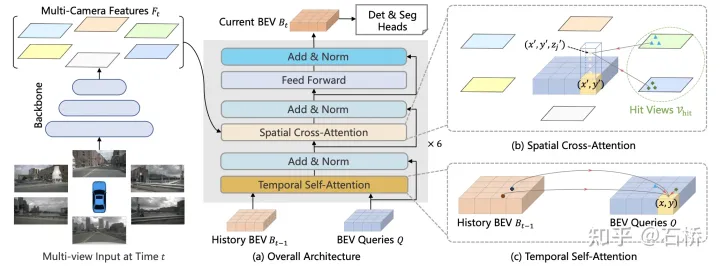
BEVFormer[18]
代码论文解读[19]作者开讲[20]一文读懂[21]
意义:引入时序信息之后,基于纯视觉的模型真正能够预测物体的移动速度,且方便的用于规控。
特征提取:图像(基于transformer)
2d backbone:两种,采用来自FCOS3D训练得到的ResNet101-DCN;采用来自DD3D训练得到的VoVnet-99。
3D query生成:每个BEV位置采样了4个高度得到3D reference points(-5m到3m,每2米采样一个点)
spatial cross-attention:将BEV query进行变换为xyz的3d点,通过相机内外参获取多视角pv坐标,以这些uv点作为中心进行特征采样,加权融合为BEV特征;

temporal self-attention:先将t-1时刻BEV特征用ego-motion变换到t时刻,在t时刻的xy query附近采样变换后t-1时刻的BEV特征与t时刻的BEV特征聚合,二者的权重通过attention weights来平衡。如上图最右侧(b)(c)。
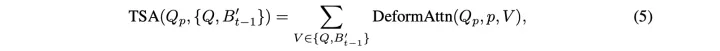
SCA和TSA过程重复6次,确保时空特征能够相互促进,进行更精准的特征融合.
PolarDETR[22]
论文代码解读
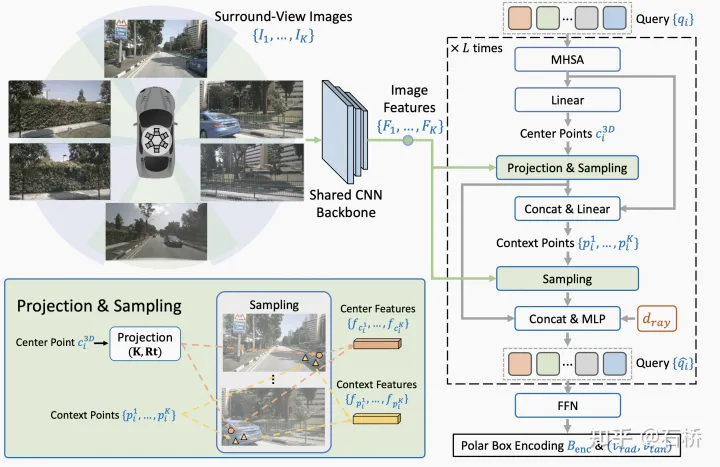
特征提取:图像(基于transformer)
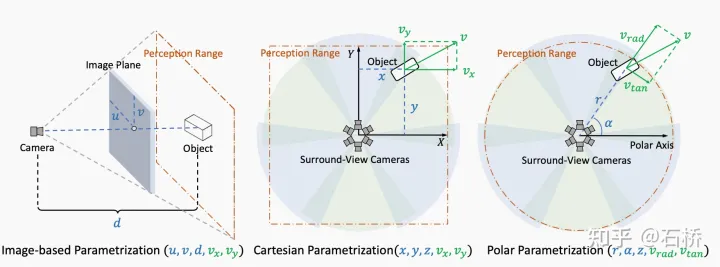
坐标系:bev参考从笛卡尔坐标系转换到了极坐标系.优点:两个目标距自车距离相等,就将被同等对待。
特征融合:融合的是代表目标的object query,而不是代表bev feature的bev query.
PETRv2[23]
论文 代码 解读
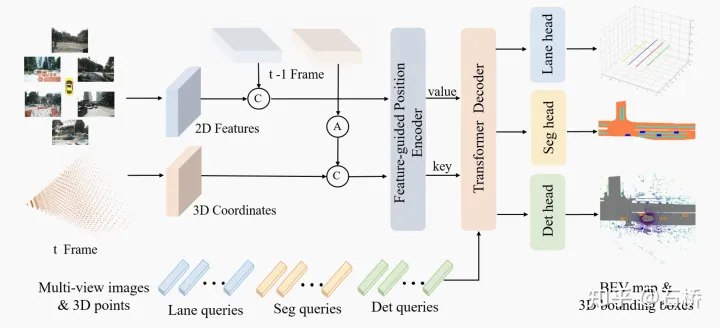
特征提取:
时序融合:通过变换前序帧外参的方式,将前序帧的相机视角变成当前帧的虚拟视角。
BEVFormerV2[24]

资料:论文解读[25]
特征提取:图像
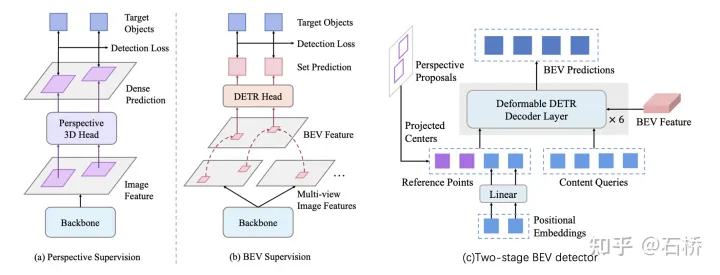
image backbone:没有使用任何自动驾驶数据集或其他深度估计数据集进行预训练过的modern backbone.
perspective 3D detection head:在BEVFormer中是监督BEV特征训练的,现在将真值监督前推到BEV变换器之前,直接监督backbone 2d特征的训练,通过在backbone上添加FCOS3D\DD3D等透视检测头,避免BEV变换导致的失真促进backbone针对3D检测任务的适应性,生成的proposals经过后处理还用于生成objectory query.
spatial encoder:与BEVFormer保持一致.
temporal encoder:与BEVDet4D相似,同时输入多帧,做好alignment以后concate起来,只是BEVDet4D不是基于transformer的融合方式,是通过输入bev encoder,也就是CNN网络来进行融合,而bevformer v2是经过residual block(残差连接块),也就是resnet的基本组成部分,进行降维,即将多帧信息融合为单帧,再进行后续操作.[26]
BEV detection head:修改Deformable DETR构建了Two-stage BEV Decoder 如图(c),采用Content queries(生成sampling offsets和attention weight的query features的可学习embedding)和混合参考点(一个线性层从可学习positional embedding集合预测得到的参考点结合proposals投影点生成的参考点)作为输入的object query.
Uniformer[27]
论文代码解读[28]
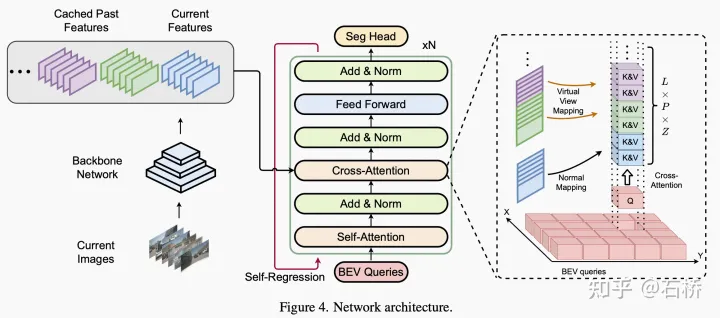
特征提取:图像(基于transformer)
时序融合:区别与BEVFormer的迭代融合前一帧,Uniformer采用将历史帧直接变换到当前帧时刻,形成虚拟视角,将所有的历史图像一起提取BEV特征。(BEVFormer在迭代融合的过程中,可能由于融合区域重叠过小而损失历史帧信息。)

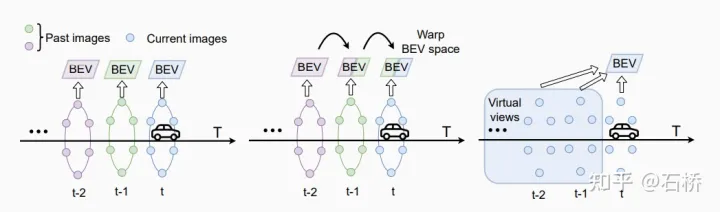
自动驾驶:BEV在线建图
最近一年,包括华为、小鹏、毫末等在内的车企越来越多的提及重感知轻地图的自动驾驶落地方案。造成这种现象的原因猜测是:国内头部图商的高精地图覆盖范围和更新频率难以适应车企落地自动驾驶的进度。比如:在一些二线、绝大多数的三、四、五线城市是没有普及高精地图的;即使在一、二线城市,要对高精地图做到月级别的更新,即使付出极大的成本代价也不一定能完成,所以车企落地自动驾驶就必须面临地图的现实性变化。一定程度上解决上述问题的方案就是:重感知,在车端实时在线构建地图。
车道的实时建图上游依赖于BEV感知方案,在此基础上还需要解决地图要素之间的拓扑关联,为了解决这个问题提出了polyline替代raster的地图表示方案,优缺点如下:
地图表示方案:raster->polyline[29]
raster的缺点:
在预测的栅格化地图中很难确保空间一致性,附近的像素可能有矛盾的语义类别或几何形状。
二维栅格化地图与大多数自动驾驶系统不兼容,因为这些系统在轨迹预测和规划中需要使用实例级别的二维/三维矢量地图。
polyline的优点:
利用顶点来约束几何形状,可以轻松的表示高精度地图中的几何元素,顶点的顺序可以编码地图元素方向。
已被下游的自动驾驶模块(轨迹预测)作为地图特征广泛使用。
下面简单介绍几种基于BEV的车端实时建图方案:
HDMapNet[30]
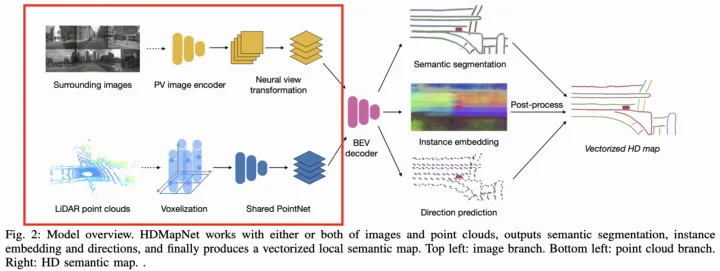
论文代码
地图表示方案:raster
特征提取:
点云:dynamic voxelization->PointPillar->PointNet->CNNs
图像:提取2d特征->MLP学PV到camera top-down映射->用外参转换到BEV(重叠栅格取特征均值)
要素检测:
BEV空间是一个带有特征的栅格图,然后利用全卷积网络(FCN)去生成语义图、实例图和方向图.
拓扑构建:
采用传统算法DBSCAN去聚类实例,通过NMS去重,然后基于方向图pixel的方向来构建矢量。
VectorMapNet[31]
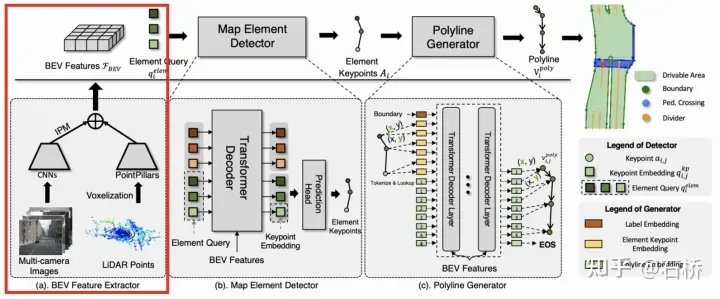
资料:代码论文解读[32]
局限:尽管我们的方法可以在单个帧中生成连贯且复杂的几何图形,但不能保证时序一致的预测。
地图表示方案:polyline
特征提取:
点云:dynamic voxelization->PointPillar
图像:用ResNet提取PV特征,通过IPM+地面高度插值(-1m,0m,1m,2m) concate的方式实现PV2BEV转换。
融合:点云、图像特征concate后+2层的卷积网络生成BEV特征
要素检测:
采用transformer decoder和一个预测头,通过二分图匹配损失进行训练,避免类似NMS的后处理步骤。
transformer decoder:每个元素query由k个关键点组成,将元素query拉伸成一个序列输入给transformer decoder,decoder的Cross-attention采用bev feature作为key和value,使用deformable attention,每个query在 BEV 特征中都有一个 2D 位置,以在预测的关键点和 BEV 空间之间建立一一对应关系并加速训练收敛。
预测头:一个回归分支和一个分类分支。回归分支:对于每个地图元素,回归分支通过共享的MLP从关键点embedding预测每个关键点的坐标。分类分支:concat单个地图元素的关键点embeddings,并通过线性投影层预测类别标签。每个关键点有两个learnable embeddings:位置embedding + 归属embedding。
拓扑构建
将每个地图元素关键点集的x、y坐标、类别进行序列化,作为Transformer解码器的query输入,然后将一系列顶点token迭代地输入到Transformer解码器中,并和BEV特征做cross-attention,通过线性投影层迭代地将这些query解码为顶点坐标值。每个步骤都会预测下一个顶点坐标的分布参数,并预测End of Sequence token (EOS) 来终止序列生成。
采用自回归网络将要素的Polyline建模成条件联合概率分布,并转换成一系列的顶点坐标的条件分布乘积:
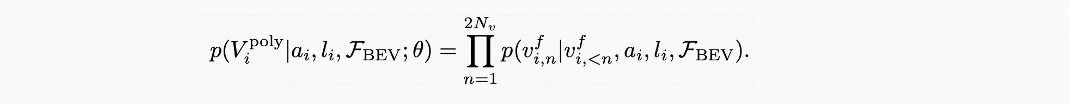
SuperFusion[33]
资料:代码论文解读[34]
地图表示方案:raster
特征提取:
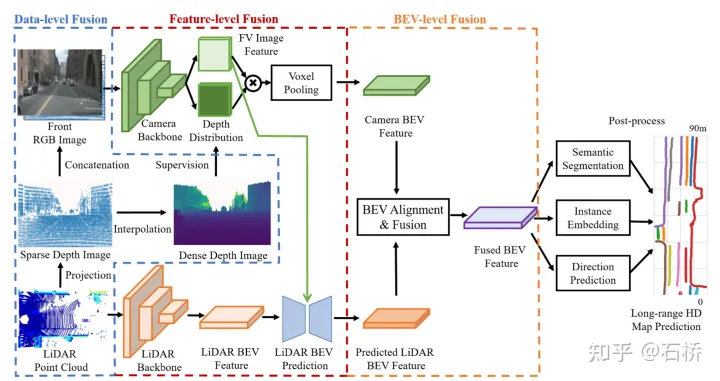
图像:将点云投影到图像平面为视觉RGB赋值深度,分别提取图像特征和估计深度分布,将深度图分布和图像特征外积得到视椎体特征,再通过voxel pooling方式生成BEV特征。(lidar深度图插值监督深度分布估计)
点云:dynamic voxelization->PointPillar,同VectorMapNet.
特征融合[35]:
Data-level:点云sparse深度图和图像concatenate,并用dense深度图进行监督训练
Feature-level:在长距离上,将FV图像特征作为K和V,将点云的BEV特征作为Q去和图像特征做cross-attention得到新的BEV特征,并经过一系列卷积操作得到最终的点云BEV
BEV-level:将图像和点云BEV特征先concat后学习flow field,然后将该flow field用于图像BEV特征的warp(根据每个点的flow field进行双线性插值),从而生成对齐后的图像BEV特征
要素检测:(同HDMapNet)
BEV空间是一个带有特征的栅格图,然后利用全卷积网络(FCN)去生成语义图、实例图和方向图.
拓扑构建:(同HDMapNet)
采用传统算法DBSCAN去聚类实例,通过NMS去重,然后基于方向图pixel的方向来构建矢量。
MapTR[36]
资料:代码论文译文作者开讲[37]
局限:目前只处理单帧数据,同VectorMapNet不能保证时序的多帧视频图像,能够有一致的预测。
地图表示方案:polyline
特征提取:
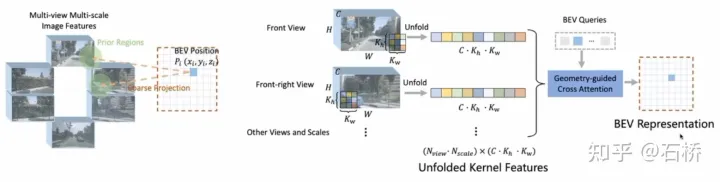
图像:采用GKT实现PV2BEV转换。对于BEV Query取地面高度组成点(x,y,z),通过相机内外参获取对应各个视角图像坐标(u,v),并且提取附近的Kh×Kw核区域的特征,然后做Cross-Attention得到BEV特征。
要素检测&拓扑构建:
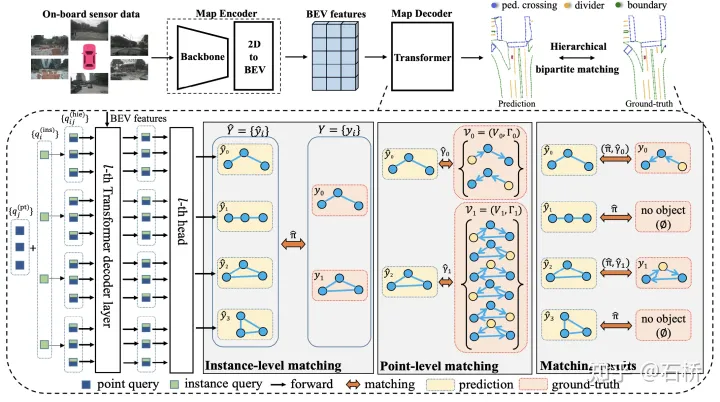
采用point query + instance query融合后与BEV特征cross-attention,并且 query之间进行实例内和实例间的交互,在计算loss的过程中采用point match和instance match来获取真值与预测的关联关系。分层级query迭代地更新,最终输出地图要素的语义类别和节点位置。
MapTR引入分层级匹配机制进行标签分配。实例级匹配:在预测的地图要素和真实的地图要素之间找到最优的一一对应关系 π ,匹配的依据为地图要素之间的类别相关性和位置相关性。节点级匹配:对于每一个地图要素,从等效排列集合中找到最优的排列γ,使得预测的节点和真实的节点一一对应且点对之间的距离之和最小。
损失函数:根据分层级匹配的结果,损失函数由classification loss,point2point loss和edge direction loss组成:Classification loss根据实例级匹配的结果对地图要素的类别预测进行约束,Point2point loss根据节点级匹配的结果,对匹配的点对之间的位置关系进行约束,Edge direction loss对预测的edge和真实的edge的方向一致性进行约束。
小结:
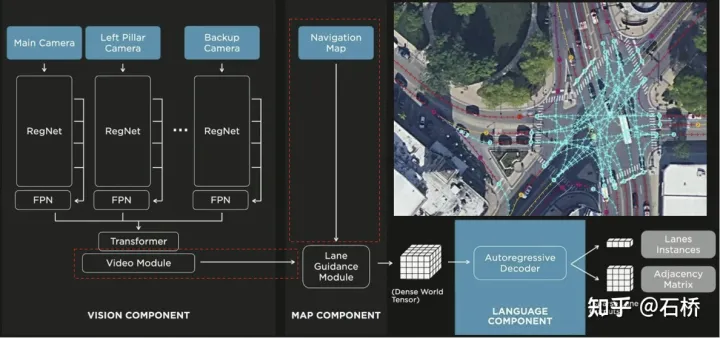
在BEV感知中,通过时序融合可以弥补单帧感知的局限性,增加感受野,改善目标检测帧间跳变和目标遮挡问题,更加准确地判断目标运动速度,是提高感知算法准确性和连续性的关键。但是上述的车端建图方案多是单帧建图,不能保证时序的多帧视频图像能够有一致的预测。上述的论文中也都提到了后续的研究方向就是时序融合建图,所以这种情况可能会在2023年得到解决。
可以看到上述建图方案的展示视频没有过多展示在道路分离合并、匝道等拓扑复杂场景的建图效果,这点和tesla展示的在线建图还是有差距,拓扑构建的难点在于道路的虚拟拓扑区域,而不在于实物拓扑区域。从tesla的输入数据是video module的时序融合特征和导航地图来看,后续导航地图也可能加入到融合中。
终局猜想:车端实时创建车道拓扑地图,在没有地图的区域提供规划决策使用,同时将拓扑信息回传;在有地图的区域,检测到更新变化实时融合,并回传云端校验。这样就同时解决了地图缺失和鲜度两个关键问题。
车厂建图:图商的商业理念是每个车厂负担起高速30w是可以的,但负担起全国上千万公里的更新维护从商业逻辑上讲就是浪费的,必然不可持续,而且从车厂的能力上来说也不是每家都能做到的;车厂认为自动驾驶目前还处在成长的过程中,(1)未来地图的模式必然与当前的高精地图不同,需要存储的可能包括感知、规划、决策、行为等信息,图已经不在拘泥于现有的维度。(2)地图作为一个与自动驾驶体验直接相关、过程中需要不断迭代完善的要素,在当前情况下必然是掌握在自己手中更有利自动驾驶技术的快速迭代和落地,进而形成完整的技术生态循环。(3)对于L3以上的自动驾驶,车厂云端的服务是必须要有的,那么一些数据回传也是必然,所以成本上采集、处理、回传、存储等都还是付出的,后续的地图要素更新优化、相应的人工作业成本会随着数据量的增多而稳定下来,不会随规模持续增长,而且成本是可以通过体验的提升转移给消费者的。这是个开放的问题还没有答案,最终可能是共存的,当然也很可能是Tier1接手。
注:
本文参考文章、博客、视频都有详细的链接,部分内容是引用,如发现未添加明确引用,敬请指出。
由于本人水平有限,如有不详细或错误的可以查证指出,谢谢。
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









