






编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【3D目标检测】技术交流群
后台回复【3D检测综述】获取最新基于点云/BEV/图像的3D检测综述!
导读
随着深度学习技术的快速发展,数据驱动的方法已成为计算机视觉领域的核心。在过去的十年里,随着 ImageNet 诞生之后,计算机视觉领域见证了 “从数据中学习” 的范式的兴盛。在 ImageNet 上进行预训练,然后迁移到下游的视觉任务,都能显著提升模型性能,并且已经成为 2D 图像领域的标准化方式。
然而,由于真实世界 3D 数据(通常以点云或者 mesh 的形式)的扫描和标注非常繁琐,现有的 3D 数据集要么是合成的,要么与 ImageNet 的规模相去甚远。因此,与 2D 视觉领域不同,在 3D 领域,大多数方法都直接在特定数据集上进行训练和评估,以解决特定的 3D 视觉任务(例如,使用合成的物体或者 ShapeNet 进行新视角合成,使用 ModelNet 和 ScanObjectNN 进行物体分类,使用 KITTI 和 ScanNet 进行场景理解)。
两个关键的问题是:(1)在 3D 视觉领域,尚无一个通用数据集,可以与 2D 领域的 ImageNet 相媲美。(2)这样一个数据集能给 3D 社区带来什么好处还不为人所知。
为了解决这些问题,港中大(深圳)的研究团队提出了 MVImgNet 和 MVPNet 数据集。MVImgNet 包含超过 21 万个视频的 650 万帧图像,涵盖了 238 个类别的真实世界物体。MVPNet 包含超过 8 万个,涵盖了 150 个类别的真实物体点云,并为每个点云提供了类别标签。目前数据集已经在项目主页公开,欢迎大家一起探索!

论文地址:https://arxiv.org/abs/2303.06042
项目主页:https://gaplab.cuhk.edu.cn/projects/MVImgNet/
GitHub 地址:https://github.com/GAP-LAB-CUHK-SZ/MVImgNet
数据集属性
MVImgNet 包含由智能手机拍摄的 219,188 个真实物体视频。通过对每个视频进行物体分割、COLMAP SfM 重建以及稠密重建,得到了物体掩码、相机参数和点云数据等标注。表 1 展示了 MVImgNet 中数据的统计信息。
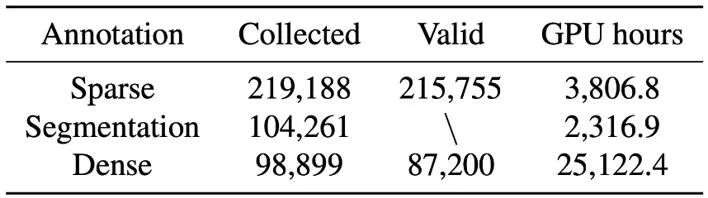
表 1. MVImgNet 数据统计
与 ImageNet 中的类别大多是植物和动物(以自然为中心)不同,MVImgNet 包含了 238 个日常生活中常见的物体类别(以人为中心),并且其中有 65 个类别与 ImageNet 重叠。图 1&2 展示了 MVImgNet 的类别目录及数据样例。
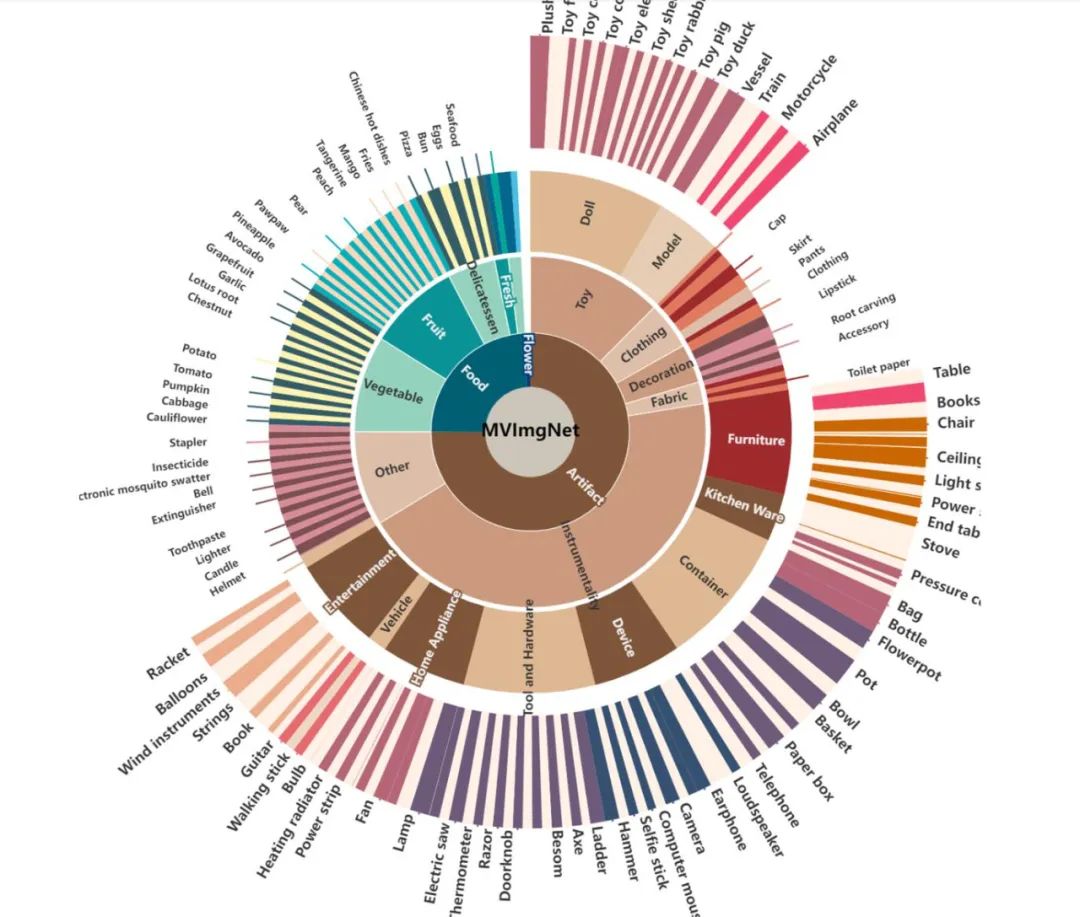
图 1. MVImgNet 类别目录

图 2. MVImgNet 中的多视角图片示例
对 MVImgNet 中的稠密重建结果,研究团队进行了进一步的数据清洗(例如移除掉噪音过大、过于稀疏的点云),得到了一个包含 150 类、87,200 个真实物体点云的大规模点云数据集 ——MVPNet。图 3 展示了 MVPNet 中丰富的真实物体点云。

图 3. MVPNet 中的真实点云示例
MVImgNet 能做什么?
下游任务一:3D 重建
研究团队探索了 MVImgNet 对 NeRF 重建以及 MVS 的帮助:通过在 MVImgNet 上训练 NeRF,提升了 generalized NeRF 的泛化能力;通过在 MVImgNet 上预训练自监督 MVS 方法,并将预训练模型迁移到 DTU 数据集上,获得了不错迁移性能。下表展示了直接在 DTU 数据集上训练的模型与用 MVImgNet 预训练模型微调的量化对比结果:
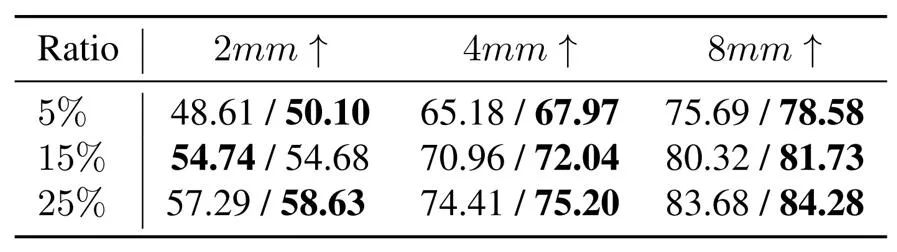
表 2. 直接训练 / MVImgNet 预训练模型微调的数值结果

在 MVImgNet 上预训练的 NeRF 拥有更好的泛化能力
下游任务二:视角一致的图像理解
尽管人类能够从不同视角理解一个物体,但深度学习模型并不能鲁棒地做到这一点。为此,研究团队在图像分类、自监督对比学习以及显著性物体检测等任务上做了探索实验,验证了得益于数据的多视角特性,在 MVImgNet 上预训练的模型获得了很好的视角一致性。
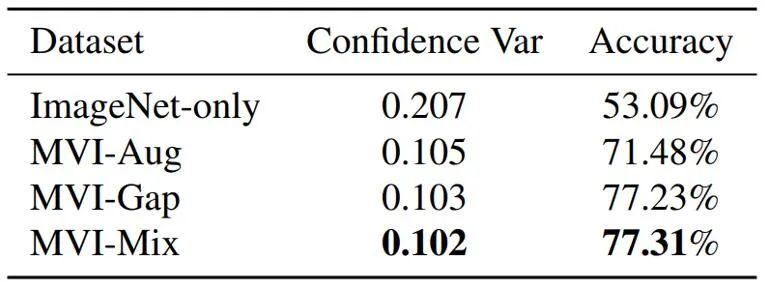
把 MVImgNet 加入训练提升了分类模型的视角一致性

在 MVImgNet 上预训练的模型,能提高模型对不同视角的鲁棒性
MVPNet 能做什么?
在 MVPNet 数据集上,研究团队探索了其对点云分类及自监督点云预训练的帮助。通过在 MVPNet 上预训练点云分类模型,在 ScanObjectNN 数据集上表现出了很好的迁移性能。而在 MVPNet 上预训练的 PointMAE(一种点云自监督学习方法)也超越了当前的 SOTA 方法。
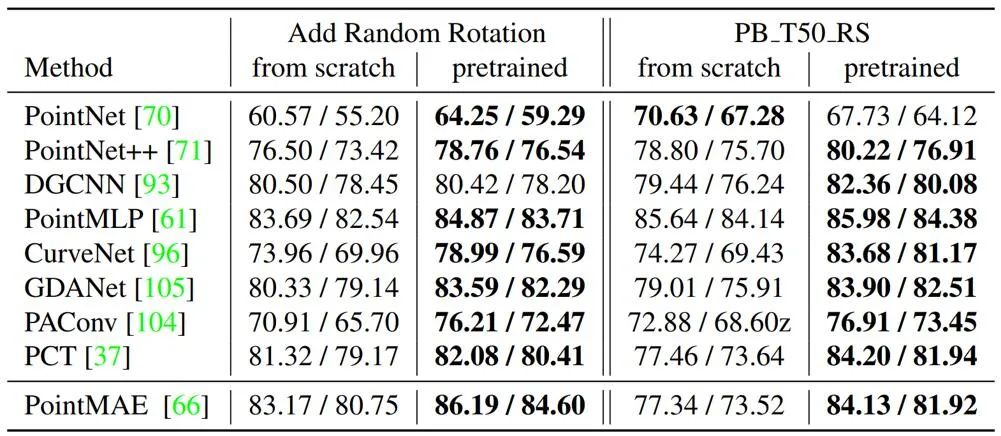
在 MVPNet 上预训练的模型,展现出了很好的迁移性能
MVPNet Benchmark Challenge
在 MVPNet 的基础上,研究团队还提出了一个全新的真实物体点云分类基准测试。研究团队构建了一个包含 64000 点云的训练集以及 16000 点云的测试集。相比于 ScanObjectNN,MVPNet 的点云数量更多,分类难度更大,也更贴近于真实场景。
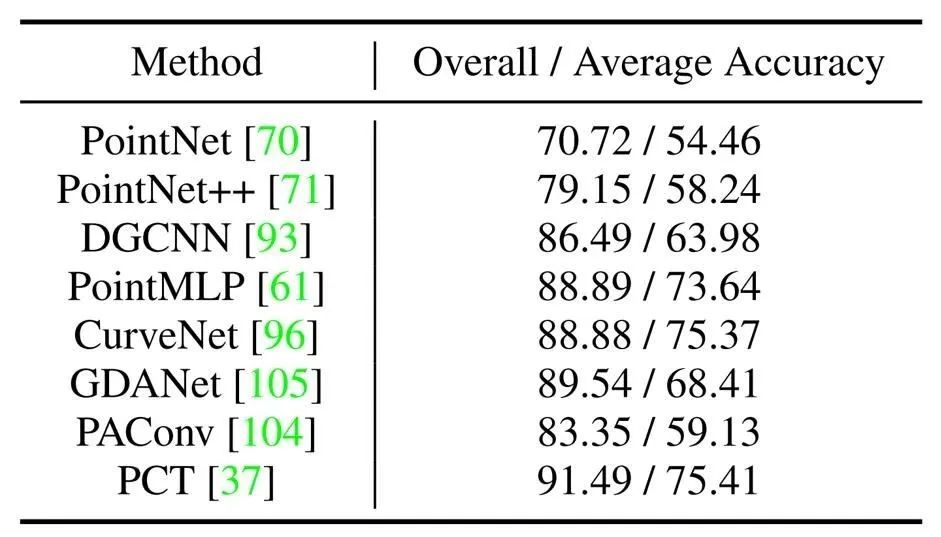
主流方法在 MVPNet Benchmark 上的数值结果
展望
我们相信 MVImgNet 将会为整个计算机视觉社区带来很多诸多可能性与挑战,期待与大家共同探索!
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 135
135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









