






作者 | 一根呆毛 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/707747191
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
原文:
https://storage.googleapis.com/waymo-uploads/files/research/2024 Technical Reports/2024 WOD Motion Prediction Challenge - 1st Place - MTR v3.pdf
基于MTR++改进,前作笔记:MTR和MTR++笔记
完整论文和源码还没有公布,目前只能先看report了。
Abstract
MTR v3是在MTR++上进行改进的。主要在两个方面进行了提升:
使用了原生的lidar数据来提供更细致的语义信息
使用了更好的更具有区分度的anchor来提升model的轨迹回归能力
除了上面两点外,采用了一个简单的ensemble技巧来进一步提升最后的表现。在soft mAP上达到了SOTA。
Introduction
MTR系列采用了场景encode,和使用了intention query的多模轨迹预测decode。本文爱之前的基础上额外使用了原始lidar数据,可以更好地捕捉一些HD map cover不到的场景信息,比如植被和建筑物。但其实这些对于行人的行为有很大的影响。而之前的MTR++存在回归loss很大的问题,这是因为anchor比较稀疏。为此,更新为更好的anchor生成方式。
Method
增加了lidar的3D信息,使用一个encoder来提取feature并喂到decoder的输入中
每个agent会根据mode动态获取有价值的point feature
最后用了一个ensemble的技巧
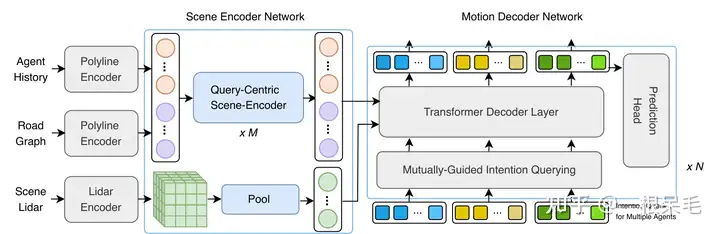
Model Design
Scene Encoder Network

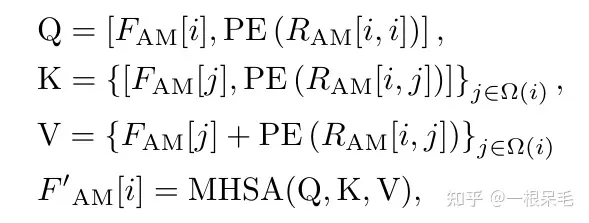


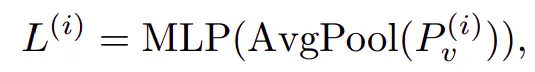
Motion Decoder Network
和MTR++一样,统计现实中的gt轨迹的最后一个点的分布,用k-means聚类后得到K个intention的点,也就是anchor。然后就可以和场景feature融合,获得intention query。再用一个Mutually-Guided Intention Querying模块来处理每个agent的多个query之间的交互(让模态分散一些)。
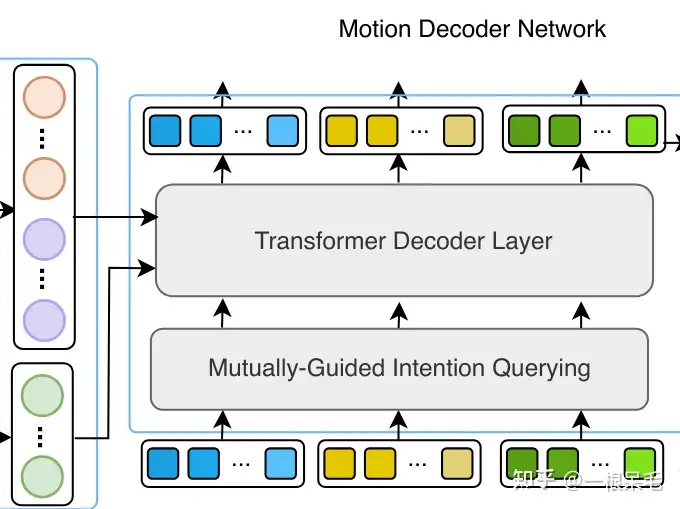
接下来就是3次cross-attention:在agent间,在地图元素间,在lidar voxel间。
并且对于每个agent还需要学习dense的预测,会结合历史以及预测的模态来学习交互,中途出一个轨迹预测用于中间的辅助监督。在每一个cross-attention decoder之后都会加几个MLP来refine query。由于需要多模预测,建模是混合高斯的。
loss的话和MTR++类似,包含了概率的分类loss,GMM的回归loss(只采用了正样本的query对应的轨迹),以及一个辅助任务的loss(详细见MTR++, 大概是用dense的预测过历史轨迹的encoder,和历史轨迹的feature concat在一起作为一个更丰富信息的feature后直接短接一个预测head,会有gt来进行一个监督,使得model中间变量也有个监督)。对于回归loss,做了一个不一样的操作,详情可以参考EDA这篇文章,大概的意思是目前主流的做法有:
anchor based:输入anchor的end point,gt轨迹直接监督最接近gt的end point对应的轨迹。
prediction based:没有具体anchor,预测出来的轨迹里挑最接近gt的进行监督。
方法1虽然一般会对anchor进行小幅度的调整,但anchor本质还是不回移动太多的,不然gt的监督就可能监督到不是gt的模态上,效果上就没有利用好regression的任务,因为并没有让end point进行自由度很高的回归。方法2就很容易出现模态塌缩的问题,因为不像方法1一样强行设置多个mode。
于是EDA就是想要结合两种做法,先是用anchor输入,允许大幅度的refine,这一步可以用gt对一开始match的anchor进行监督,但refine后会重新match,再进行refine,多来几次可以让anchor收敛到比较理想又分散的效果。
Motion-Guided Lidar Search
为了减少lidar相关计算的压力,并没有无脑使用全部的lidar点,对于关注的agent而言,用它的位置以及未来的位置在当前速度方向上的投影作为搜索lidar点的位置。找出离这些位置最近的个lidar token放入decoder中。
Model Ensemble
为了进一步提升性能,一共重复训练了个本文的model,每个agent会有6个预测,然后在用NMS来挑出最好的6个预测作为评测的轨迹。
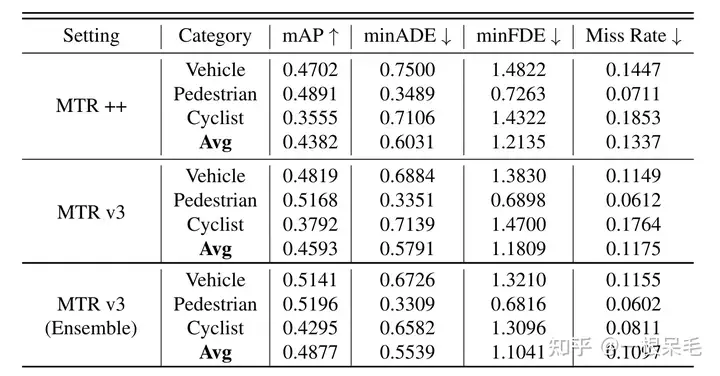
Experiments
model参数见文章。每个lidar token的范围是长1.6m,宽1.6m,高6m。NMS的阈值用2.5m. 训练时也使用了随机剪裁以及缩放来数据增强。

投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









