






作者 | Malignus 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/564565206?
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【车道线检测】技术交流群
后台回复【车道线综述】获取基于检测、分割、分类、曲线拟合等近几十篇学习论文!
最近比较新出炉的一篇基于环视车道线检测的工作~ 由华中科技大学的vision lab & 地平线共同推出的工作,由于目前本身在忙秋招的工作,所以这篇论文整体阅读的没有特别的细致。对于试验的很多ablation study内容没有过多关注,这里就简单介绍一下整篇paper的method部分啦
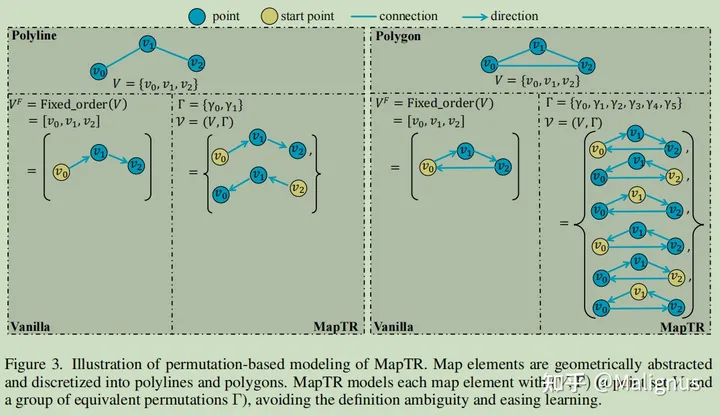
1Permutation-based modeling
整篇论文基于的前提是nuScenes数据集中,车道线的标注并未区分方向。这里也特别要提一下我自己先前混淆的内容,先前的环视车道线检测工作包括这篇中涉及的vectorized的定义,与我们数学中自带方向的矢量化定义还有差别。这里的vectorized与之相反的是rasterized,感觉更类似稀疏化表示与稠密化表示的区别,而非方向性。
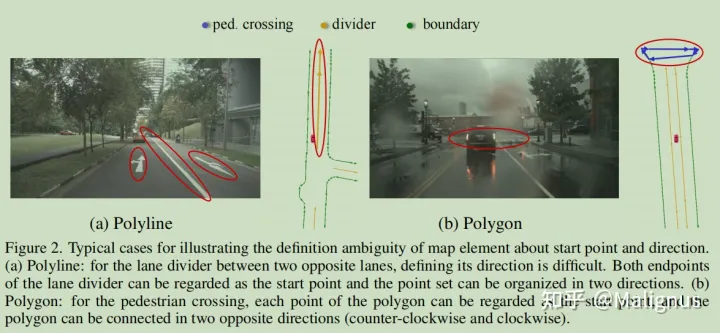
对于图左情况,人行横道采用polyline进行表征。由于polyline没有区分方向,所以起点终点不需要强调一致性,两种等价排列方式均可进行表征。
对于图右情况,人行横道采用polygon进行表征,对于一个人行横道的polygon而言,没必要在意其对应Keypoint的排列顺序。故k个点组成的polygon, 可以通过2* k种等价排列方式进行表征。
2Hierarchical matching
Symbol
N: 地图元素总数,该数量大于数据集中任意一个图片的地图元素数量,多余的空值通过padding补齐,目的是对齐GT数量,方便多Batch_size的训练和验证。
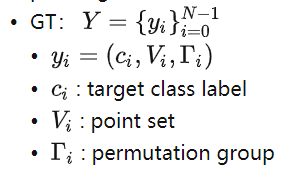

: N个元素的排列
整体的matching包括两部分:Instance-level matching和point-level matching
Instance-level Matching

用匈牙利匹配来找到最优匹配,这里的position matching cost就是point2point cost,与point-level matching的cost完全一致。
Point-level Matching
在实例匹配后,将与非空匹配的实例标注为正样本。对正样本进行点级别的匹配,匹配cost基于曼哈顿距离。
Loss
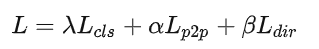
整体loss包括三方面组成,classification loss&point2point loss&direction loss
Classification Loss
基于实例级匹配的结果,每个道路元素会被分配class label,使用focal loss。
Point2point Loss
这里的loss在于限制预测点的位置,该loss定义为所有匹配的两两点间的曼哈顿距离。
Edge Direction Loss
点与点间的距离并未在边的维度上进行几何信息的约束,基于这点,作者提出对匹配的预测边和GT边的余弦相似度作为loss. 这里的边的计算,就是通过点与点的x, y差值得到。
Architecture
模型整体采用Encoder-Decoder的结构范式,具体如图所示。
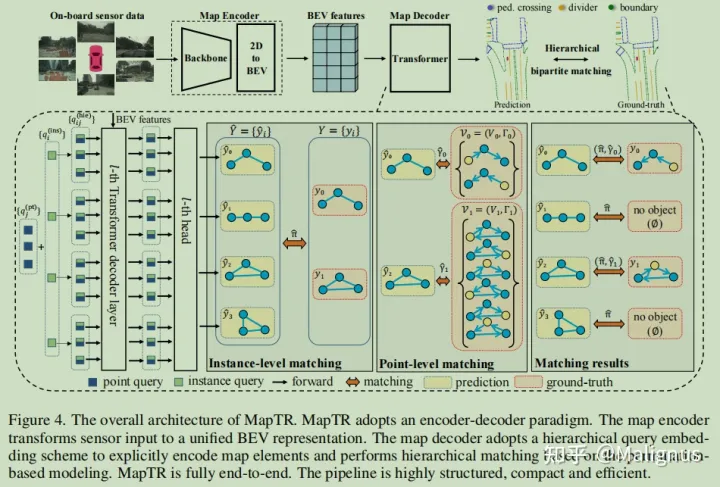
Map Encoder
模型的编码器负责从环视相机提2D features,并将特征投影至BEV下。作者这里采用的是GKT,其实与BEVFormer整体思路基本一致。其中GKT是fixed的kernel,而BEVFormer是类似于Deformable detr, 他的reference points的offset是不断学习的。
Map Decoder

The detail unknown right now
这篇论文当中当然也还是有一些细节目前还没有特别搞明白,由于代码也还没有开源,所以这里简单mark一下。
作者提到每个道路元素会用20个点来进行表征,但nuScenes中好像不是所有的数据都会用20个点来进行表征?所以是将nuScenes的每个map element都先interpolation到20还是说进行了补0之类的操作呢?
点与点的匹配这里其实是我有一点困惑的,基于我的理解,对于polyline,作者希望点的预测本身就是带顺序的,即预测map element的20个点与GT的点集匹配时,就是0-0, 1-1, ……到19-19。而作者的motivation,是认为polyline既可以从0-19,也可以是19-0,所以匹配的原则可以是从0-0, 1-1, ……到19-19,或0-19, 1-18, ……到19-0这样子?这里我也不是特别确定。不清楚我对这一段表述的理解是否准确。

视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 511
511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









