






作者 | 自动驾驶我睡觉 编辑 | 自动驾驶我睡觉
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【占用网络】技术交流群
论文地址:https://arxiv.org/abs/2302.13130
为了实现4D占据预测,作者提出了一种新的网络架构,并使用未标注的LiDAR序列数据进行训练和测试。具体而言,他们通过查询已知传感器内外参数的4D模型,使用射线来渲染LiDAR扫描数据。这种方法使得可以在不需要标注的LiDAR序列上训练和测试4D占据预测算法,并且可以在不同的数据集、传感器和车辆之间进行点云预测算法的评估和比较。
几个重要方面也不同于常见的新颖视图合成文献:
(a)我们使用有效的前馈网络来预测时空占用量,而不是应用测试时间优化;(b)我们优化显式体积场景表示(即占用网格),而不是隐式中性场景表示;(c)我们的方法依赖于在不同场景中学习的形状和运动先验,以预测接下来会发生什么,而不是仅基于来自特定场景的样本进行重建
方法:
公式定义:
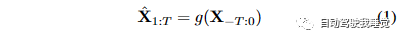
公式(1)描述了将历史点云序列作为输入,通过预测函数g来预测未来点云序列的过程。预测的结果用ˆX1:T表示。
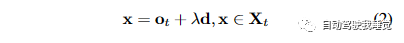
公式(2)描述了这个重新参数化的过程。通过这种方式,我们将未来LiDAR点云中的点表示为射线的形式,方便后续的处理和预测。
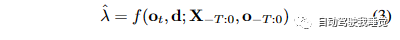
公式(3)描述了这个预测过程。通过将历史点云序列和传感器位置作为输入,我们的方法尝试预测射线将行进的距离ˆλ。
Spacetime (4D) occupancy
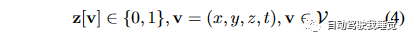
使用公式(4)来表示时空体素网格V中体素v的占据情况,它可以是占据状态(1)或空闲状态(0),z来表示真实的时空占据情况。
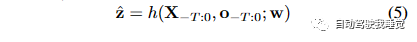
公式(5)表示通过占据预测网络h(参数化为w),给定历史点云序列X−T:0和传感器位置o−T:0,预测离散化的时空4D占据情况。这个公式描述了我们如何使用占据预测网络来进行占据预测。预测的占据情况ˆz表示预测的离散化时空体素网格V中每个体素v的占据概率。
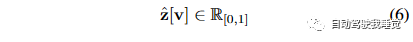
公式(6)表示预测的占据情况ˆz[v]的取值范围是[0,1],表示体素v的占据概率。这个公式描述了预测的占据情况的范围。
Depth rendering from occupancy
Depth rendering from occupancy
给定射线查询x = o + λd,目标是尽可能准确地预测停止点的位置ˆλ。为了实现这个目标,首先计算射线与占据网格的交点,通过体素遍历的方法(图4)。假设射线与一系列体素{v1 . . . vn}相交。将射线空间离散化,假设射线只能在体素边界或无穷远处停止。将体素vi的占据解释为离开体素vi−1的射线停止在体素vi的条件概率。可以写为:
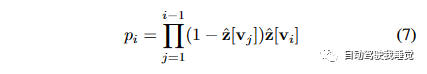
其中pi表示射线停止在体素vi的概率。公式(7)描述了如何根据体素的占据概率计算射线在体素网格中停止的概率。通过乘积运算,我们考虑了射线从起点到每个体素的路径上的占据概率,从而得到了射线停止在每个体素的概率。这个概率可以用于计算期望的停止点,从而实现深度的渲染。
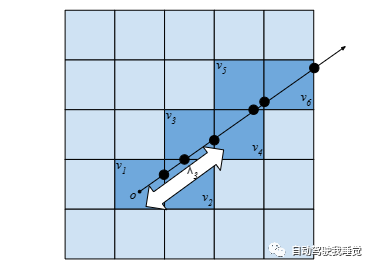
图4.展示了从预测的占用网格为给定光线渲染深度的过程。假设光线只停在体素边界,这将输出空间离散成一组离散的事件。然后,计算光线在每个边界交叉点停止的概率。最后,计算预期的停止距离。
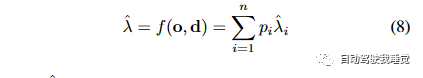
公式(8)描述了如何计算预测的停止距离。我们首先计算射线从起点到每个体素的路径上的停止距离。这些停止距离可以通过之前的公式(7)中的概率pi和体素的停止距离ˆλi计算得到。然后,我们将这些停止距离加权求和,其中权重是每个体素的停止概率pi。这样,我们就可以得到预测的停止距离ˆλ,它是射线在体素网格中停止的期望距离。
在体素网格之外停止的情况:
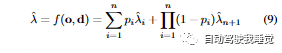
公式(9)中的λn+1表示射线停止在体素之外的情况下的停止距离。它是通过将每个体素的停止概率pi与对应的停止距离ˆλi相乘,并将结果取乘积的方式计算得到的。通过引入公式(9),我们可以考虑射线停止在体素之外的情况,从而更全面地建模射线的停止行为。这有助于提高深度预测的准确性和鲁棒性。
Loss function
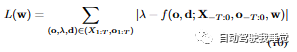
损失函数的计算是通过将预测的深度ˆλ与真实深度λ之间的差值取绝对值,并将所有样本的差值求和得到的,通过最小化损失函数,我们可以使网络学习到更准确的深度预测,从而提高占据预测的性能。
评估方式:
由于获取真实的4D占据数据非常昂贵,因此无法直接使用真实数据来评估模型的性能。因此,文章提出了一种新的评估方法,通过将未来的射线作为查询,并要求模型为每个查询提供深度估计来评估模型的性能。
评估过程如下:
使用已知的传感器内参和外参,从预测的4D占据中生成未来的点云。
将未来的射线作为查询,要求模型为每个查询提供深度估计。
将模型预测的深度估计与真实深度进行比较,评估模型的性能。
通过这种评估方法,可以将模型的性能与真实的4D占据进行比较,从而间接评估模型的准确性和鲁棒性。
实验:
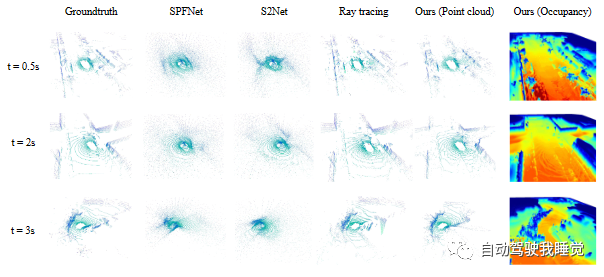
将S2Net[18]、SPFNet[19]的点云预测和nuScenes数据集上的光线追踪基线与在不同时间范围内对三个不同序列的方法进行了比较。作者的预测看起来比SOTA清晰得多。这证明了学习预测时空4D占用率的好处,其中考虑了传感器内在和外在因素。作者还在相应的未来时间戳上可视化预测的4D占用率。与简单的基于聚合的光线追踪相比,能够实现时空完整的4D场景
应用:

新颖的内在视图合成我们展示了如何在相同的学习占用网格上模拟不同的激光雷达射线模式。在这种情况下,使用nuScenes激光雷达(Velodyne HDL32E)扫描的历史激光雷达数据预测未来的占用。首先,我们展示了本机设置下渲染的点云。然后,我们展示了KITTI激光雷达的渲染点云(Velodyne HDL64E,2倍的光束)。最后,我们有Argoverse 2.0激光雷达的渲染点云(2个VLP-32C堆叠在一起)。事实上,我们可以在一种传感器捕获的数据之上预测占据率,并使用它来模拟不同传感器的未来数据,这表明预测占据率作为代表是多么通用

新颖的视点预测的未来4D占有率渲染的密集深度图。为了渲染这些深度图,我们采用了自我车的新颖未来轨迹。将相机放置在这些位置中的每一个,始终面向前方进入体素网格(显示在左侧未来点状红色轨迹中),为我们提供了一个相机坐标系,在该坐标系中,我们可以从相机中心拍摄光线到图像中的每个像素,并进一步进入4D占有率体积。每个像素代表沿其光线的预期深度。t=0处的RGB图像显示为参考,在此渲染中不使用。对于深度图,越暗表示距离较近,越亮表示距离较远
结论:
从几何占有率预测的角度来看点云预测,这是一项新兴的自我监督任务,最初设置在鸟瞰视图中,但通过这项工作扩展到全3D。我们认为这种观点的转变是必要的,原因有二。首先,这种转变有助于算法专注于世界的通用中间表示,即时空4D占有率,这对下游任务具有很大的潜力。其次,这革新了我们如何通过从不同场景元素的形状和运动的学习中分解出传感器外在因素和内在因素来制定自监督激光雷达点云预测
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码免费学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、Occupancy、多传感器融合、大模型、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)
















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









