






作者 | 紫气东来 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/654027980
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
要在冯·诺依曼架构的硬件中实现高性能计算,最重要的两点就是:访存和计算。这两点分别对应着 IO bound 和 compute bound ,硬件系统的内存体系深刻影响着这两点。因此要实现软件层面的高性能计算,必须要对内存体系有深刻的理解。本篇主要讨论GPU的内存体系,并在此基础上进行CUDA的编程实践。
一、GPU的内存体系
内存的访问和管理编程语言的重要组成部分,也是实现高性能计算的重要环节。CUDA 内存模型结合了主机和设备的内存系统,具有完整的层次结构,并可以显式地进行控制和优化。
1.1 各级内存及其特点
下图展示了CUDA 内存模型的层次结构,每一种都有不同的作用域、生命周期以及缓存行为,接下来将逐一介绍:
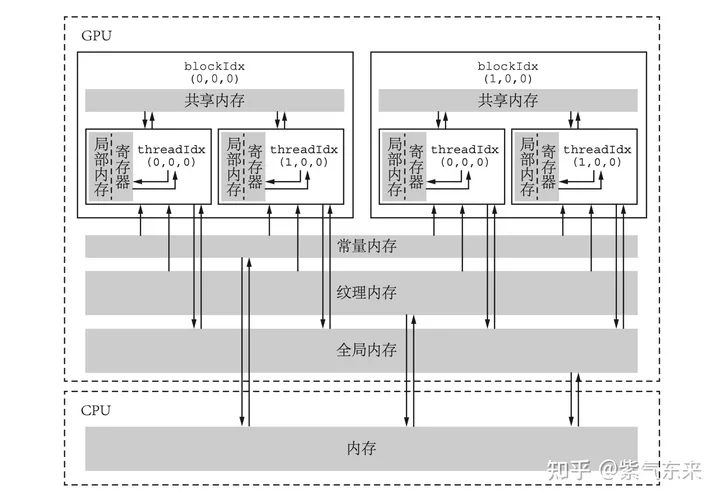
全局内存(global memory)
全局内存是GPU中最大、延迟最高、最长使用的内存,通常说的“显存”中的大部分都是全局内存。全局内存的声明可以在任何SM设备上被访问到,并且贯穿应用程序的整个生命周期。
全局内存的主要角色是为核函数提供数据,并在主机与设备及设备与设备之间传递数据。可以用 cudaMemcpy函数将主机的数据复制到全局内存,或者反过来。如将中 M 字节的数据从主机复制到设备,操作如下:
cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice);全局内存变量可以被静态声明和动态声明, 如 静态全局内存变量由以下方式在任何函数外部定义 :
__device__ T x; // 单个变量
__device__ T y[N]; // 固定长度的数组后续将会重点研究如何优化全局内存访问,以及如何提高全局内存的数据吞吐率。
常量内存(constant memory)
常量内存是指存储在片下存储的设备内存上,但是通过特殊的常量内存缓存(constant cache)进行缓存读取,常量内存为只读内存。常量内存数量有限,一共仅有 64 KB,由于有缓存,常量内存的访问速度比全局内存高,但得到高访问速度的前提是一个线程束中的线程(一个线程块中相邻的 32 个线程)要读取相同的常量内存数据。
一个使用常量内存的方法是在核函数外面用 __constant__ 定义变量,并用 API 函数 cudaMemcpyToSymbol 将数据从主机端复制到设备的常量内存后 供核函数使用。
纹理内存(texture memory)和表面内存(surface memory)
纹理内存和表面内存类似于常量内存,也是一 种具有缓存的全局内存,有相同的可见范围和生命周期,而且一般仅可读(表面内存也可 写)。不同的是,纹理内存和表面内存容量更大,而且使用方式和常量内存也不一样。
寄存器(register)
寄存器是线程能独立访问的资源,它所在的位置与局部内存不一样,是在片上(on chip)的存储,用来存储一些线程的暂存数据。寄存器的速度是访问中最快的,但是它的容量较小。
在核函数中定义的不加任何限定符的变量一般来说就存放于寄存器(register)中。各种内建变量,如 gridDim、blockDim、blockIdx、 threadIdx 及 warpSize 都保存在特殊的寄存器中,以便高效访问。在上期求和的例子中:
const int n = blockDim.x * blockIdx.x + threadIdx.x;
c[n] = a[n] + b[n];中的 n 就是一个寄存器变量。寄存器变量仅仅被一个线程可见。也就是说,每一个线程都有一个变量 n 的副本。虽然在核函数的代码中用了这同一个变量名,但是不同的线程中该寄存器变量的值是可以不 同的。每个线程都只能对它的副本进行读写。寄存器的生命周期也与所属线程的生命周期 一致,从定义它开始,到线程消失时结束。
局部内存(local memory)
局部内存和寄存器几乎一 样,核函数中定义的不加任何限定符的变量有可能在寄存器中,也有可能在局部内存中。寄存器中放不下的变量,以及索引值不能在编译时就确定的数组,都有可能放在局部内存中。
虽然局部内存在用法上类似于寄存器,但从硬件来看,局部内存只是全局内存的一部 分。所以,局部内存的延迟也很高。每个线程最多能使用高达 512 KB 的局部内存,但使用 过多会降低程序的性能。
共享内存(shared memory)
共享内存和寄存器类似,存在于芯片 上,具有仅次于寄存器的读写速度,数量也有限。一个使用共享内存的变量可以 __shared__ 修饰符来定义。
不同于寄存器的是,共享内存对整个线程块可见,其生命周期也与整个线程块一致。也 就是说,每个线程块拥有一个共享内存变量的副本。共享内存变量的值在不同的线程块中 可以不同。一个线程块中的所有线程都可以访问该线程块的共享内存变量副本,但是不能 访问其他线程块的共享内存变量副本。共享内存的主要作用是减少对全局内存的访问,或 者改善对全局内存的访问模式。
以上内存的主要特点如下表所示:

L1和L2 缓存
每个 SM 都有一个 L1 缓存,所有 SM 共享一个 L2 缓存。L1 和 L2 缓存都被用来存储局部内存和全局内存中的数据,也包括寄存器中溢出的部分,以减少延时。
从物理结构上来说,在最新的GPU架构中,L1 缓存、纹理缓存及共享内存三者是统一的。但从编程的角度来看,共享 内存是可编程的缓存(共享内存的使用完全由用户操控),而 L1 和 L2 缓存是不可编程的缓存(用户最多能引导编译器做一些选择)。
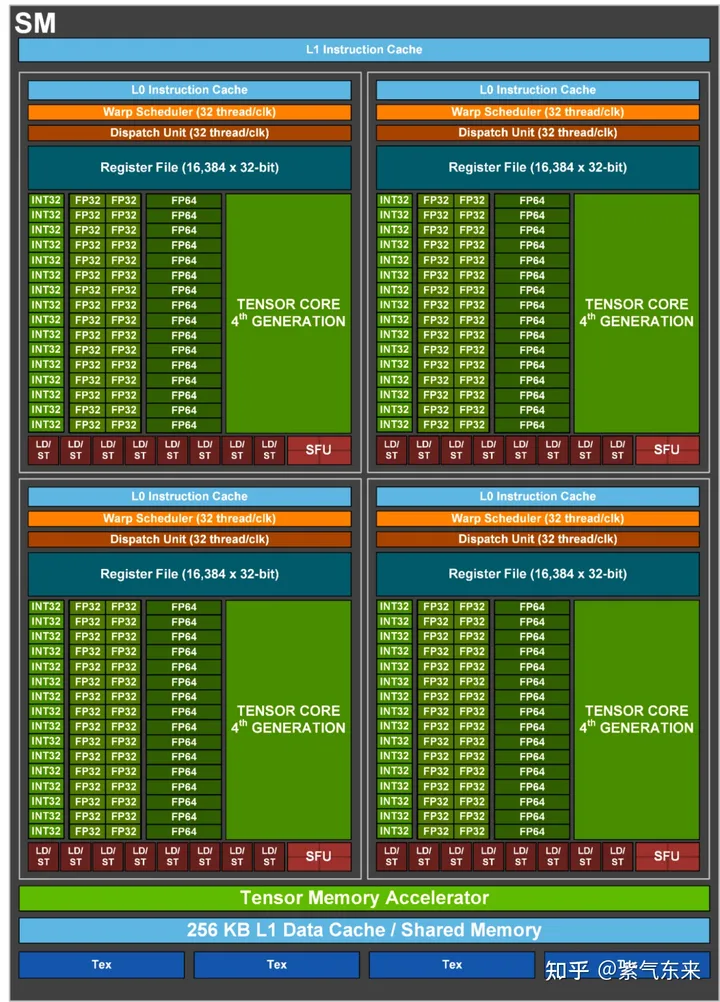
1.2 SM 构成及典型GPU的对比
一个 GPU 是由多个 SM 构成的。一个 SM 包含如下资源:
一定数量的寄存器。
一定数量的共享内存。
常量内存的缓存。
纹理和表面内存的缓存。
L1缓存。
线程束调度器(warp scheduler) 。
执行核心,包括:
若干整型数运算的核心(INT32) 。
若干单精度浮点数运算的核心(FP32) 。
若干双精度浮点数运算的核心(FP64) 。
若干单精度浮点数超越函数(transcendental functions)的特殊函数单元(Special Function Units,SFUs)。
若干混合精度的张量核心(tensor cores)
下图是 H100 的 SM 结构图,可以按图索骥找到上述的对应部分
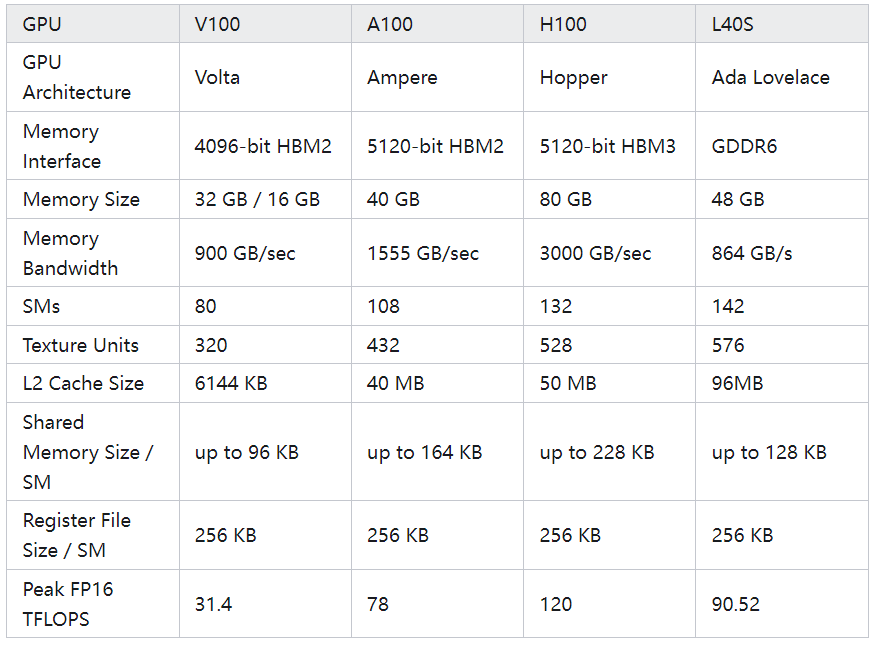
为了更好理解内存体系与性能的关系,下表列举了当前几款主流的GPU产品的数据
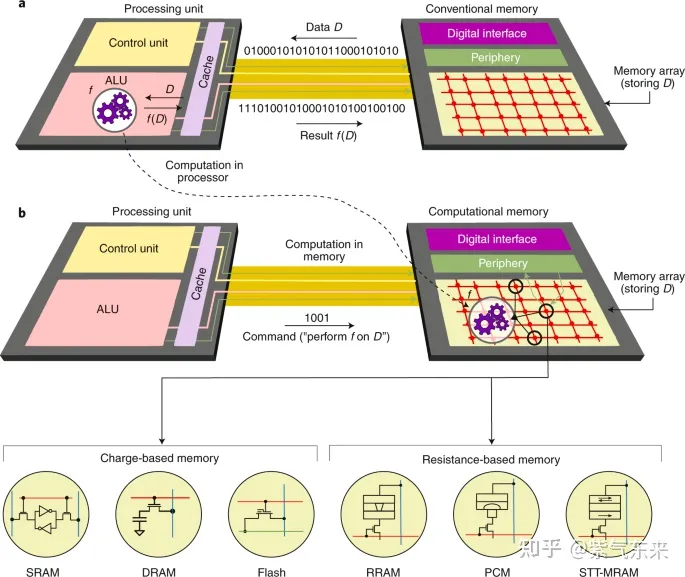
1.3 GPU 之外:近存计算与存算一体
在GPU的层次结构之外,为了降低访存成本,获得更高的性能,近存计算与存算一体逐渐成为热门的方向。
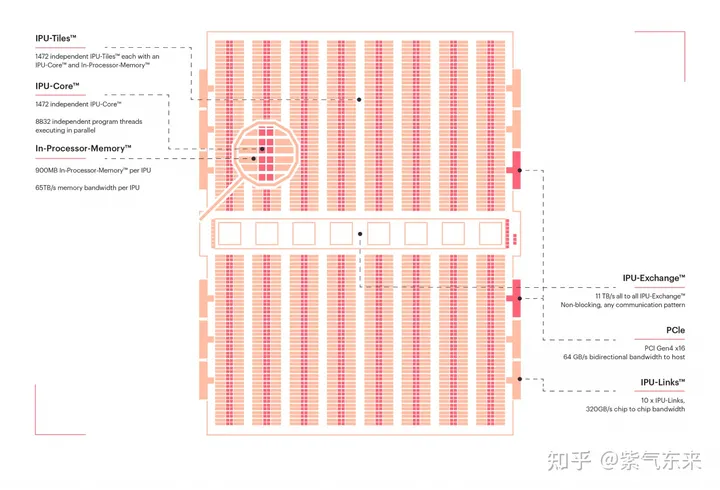
近存计算: 以 Graphcore IPU 为例
IPU芯片没有高速的片外存储,而是把存储放到了片上。整个芯片由1472个核心组成,称作Tile。每个Tile由独立的计算单元和存储单元组成,整个片上存储是分布式的。每个Tile中有624KB的SRAM,因此整个芯片的存储大小为624KB * 1472 = 900MB。
IPU芯片采用纯分布式的架构,每个Tile有自己的存储和计算资源,采用MIMD的计算架构(与NVIDIA CUDA的SIMT不同),每个Tile可以独立地执行不同的指令,可以独立地访存。Tile和Tile之间的memory不能共享访问,只能访问自己Tile内部的memory,叫做 local memory。因此整个芯片的访存带宽 = Tile 访存带宽 * Tile数量。
存算一体: 以 后摩智能 H30 为例
存算一体或者存内计算的核心思想是,通过对存储器单元本身进行算法嵌入,使得计算可以在存储器单元内完成。
鸿途™H30包含多个存算单元,既能存储数据也能处理数据,打破传统芯片性能瓶颈并提升能效比,物理算力可达到256TOPS,实现大算力、低功耗、低成本。
二、通过规约(Reduction)操作理解GPU内存体系
reduce 算法可以描述为
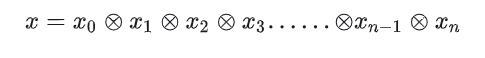

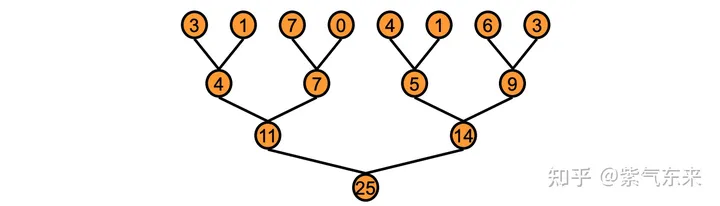
在GPU中,reduce采用了一种树形的计算方式,例如下面的求和问题:
由于GPU没有针对global数据的同步操作,只能针对block的数据进行同步。所以,一般而言将reduce分为两个阶段,其示意图如下:
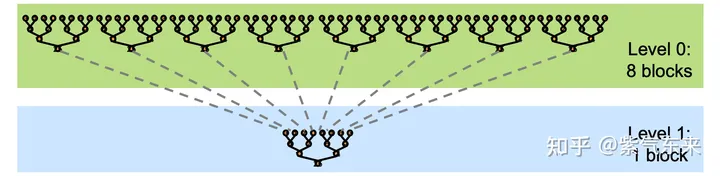
假设给定一个长度为N的数组,需要计算该数组的所有元素之和。首先需要将数组分为m个小份。而后,在第一阶段中,开启m个block计算出m个小份的reduce值。最后,在第二阶段中,使用一个block将m个小份再次进行reduce,得到最终的结果。
以下实验代码开源在:ifromeast/cuda_learning: learning how CUDA works (github.com)
2.1 仅使用全局内存实现规约
对于数组归约的并行计算问题,要从一个数组出发,最终得到一个数。所以,必须使用某种迭代方案。假如数组元素个数是 2 的整数次方,可以将数组后半部分的各个元素与前半部分对应的数组元素相加。如果重复此过程,最后得到的第 一个数组元素就是最初的数组中各个元素的和。这就是所谓的折半归约(binary reduction) 法。
其实现如以下代码所示:
void __global__ reduce_global(real *d_x, real *d_y)
{
const int tid = threadIdx.x;
real *x = d_x + blockDim.x * blockIdx.x;
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
if (tid < offset)
{
x[tid] += x[tid + offset];
}
__syncthreads();
}
if (tid == 0)
{
d_y[blockIdx.x] = x[0];
}
}其中有以下几点需要注意:
同步函数
__syncthreads是为了保证一个线程块中的所有线程(或者说所有线程束)在执行该语句后面的语句之 前都完全执行了该语句前面的语句。将(动态)数组 d_x 中第
blockDimx.x * blockIdx.x个元素的地址赋给指针x,该句等价于real *x = &d_x[blockDim.x * blockIdx.x];for 循环内在各个线程块内对其中的数据独立地进行归约,同一个线程块内的线程按照代码出现的顺序执行指令 。不同线程块之间由于处理的数据不同,因此不需要同步。
在 offset 的计算过程中使用了位操作,对于2的幂而言,这样做更加高效。
该核函数仅仅将一个长度为的数组 d_x 归约到一个长度为/128的数组 d_y 。
因为 global 修饰符的限制,d_y 和 x 均是全局内存的变量。
2.2 使用共享内存实现规约
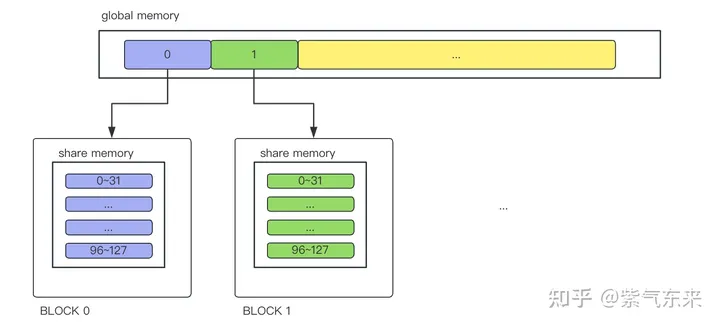
由于全局内存访问速度最低,因此性能较低,本节将使用 对整个线程块可见的共享内存来实现同样的规约操作。使用 __shared__ 修饰共享内存变量 s_y,同时其长度等于线程块大小。然后将全局内存中的数据复制到共享内存中,每个线程块都有一个共享内存变量的副本。
具体实现如下所示, 当 blockIdx.x 等于 0 时,将全局内存中第 0 到第 blockDim.x - 1 个数组元素复制给 第 0 个线程块的共享内存变量副本,以此类推。
const int tid = threadIdx.x;
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
__shared__ real s_y[128];
s_y[tid] = (idx < N) ? d_x[idx] : 0.0;
__syncthreads();上述过程可表示如下,需要说明的是,GPU需要分配两种资源,一个是存储资源,一个是计算资源。计算资源其实是根据thread数量来确定的,一个block中分配128个thread线程,32个线程为一组(即一个 warp),绑定在一个SIMD单元。所以128个线程可以简单地理解为分配了4组SIMD单元。
在核函数中对共享内存访问的次数越多,则由使用共享内存带来的加速效果越明显。在我们的数组归约问题中,使用共享内存相对于仅使用全局内存还有两个好处: 一个是不再要求全局内存数组的长度 N 是线程块大小的整数倍,另一个是在规约的过程中不会改变全局内存数组中的数据(在仅使用全局内存时,数组 d_x 中的部分元素被改变)。这两点在实际的应用中往往都是很重要的。
2.3 使用动态共享内存实现规约
在上边使用共享内存数组时,指定了一个固定的长度(128) ,使这个长度与核函数的执行配置参数 block_size (也就是核函数中的 blockDim.x)是一样的。这种静态的方式可能会导致错误的发生,因此有必要使用动态操作。
将静态共享内存改成动态共享内存,只需要做以下两处修改:
在调用核函数的执行配置中写下第三个参数:
<<<grid_size, block_size, sizeof(real) * block_size>>>前两个参数分别是网格大小和线程块大小,第三个参数就是核函数中每个线程块需要 定义的动态共享内存的字节数, 其默认值为零。
要使用动态共享内存,还需要改变核函数中共享内存变量的声明方式
extern __shared__ real s_y[];它与之前静态共享内存的声明方式 有两点不同:第一,必须加上限定词 extern; 第二,不能指定数组大小。
种方式都完成后,我们可以编译运行代码
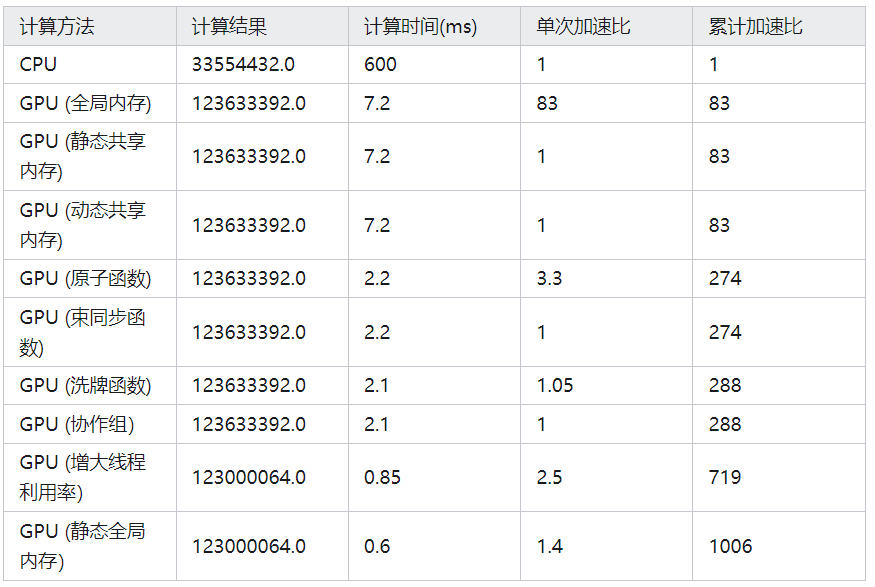
nvcc reduce_gpu.cu -o reduce通过计时函数可以看到,每种方法的完整计算总时间都在 7.5 ms 左右。
然后通过 nvprof 命令查看GPU各部分的耗时
nvprof ./reduce结果如下,由于该例子中不存在对内存的频繁读写,因此以上几种方式的性能差别不大
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 98.25% 30.8438s 300 102.81ms 80.686ms 259.15ms [CUDA memcpy HtoD]
0.44% 137.86ms 100 1.3786ms 1.3756ms 1.3822ms reduce_global(float*, float*)
0.44% 137.66ms 300 458.85us 343.93us 863.09us [CUDA memcpy DtoH]
0.43% 136.51ms 100 1.3651ms 1.3647ms 1.3666ms reduce_shared(float*, float*)
0.43% 136.50ms 100 1.3650ms 1.3647ms 1.3664ms reduce_dynamic(float*, float*)如果要放大访存速度的差别,可以使用双精度,编译方式如下:
nvcc reduce_gpu.cu -DUSE_DP -o reduce_dp此时可以看到全局内存的性能出现了明显下降:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 98.65% 60.8587s 300 202.86ms 189.54ms 304.60ms [CUDA memcpy HtoD]
0.65% 398.54ms 300 1.3285ms 1.2460ms 2.9135ms [CUDA memcpy DtoH]
0.26% 157.32ms 100 1.5732ms 1.5677ms 1.5803ms reduce_global(double*, double*)
0.22% 137.32ms 100 1.3732ms 1.3716ms 1.3746ms reduce_shared(double*, double*)
0.22% 137.31ms 100 1.3731ms 1.3714ms 1.3750ms reduce_dynamic(double*, double*)2.4 规约的其他优化方法
2.4.1 使用原子函数
在前边几个版本的数组归约函数中,核函数并没有做全部的计算,而只是将一个长 一些的数组 d_x 变成了一个短一些的数组 d_y,后者中的每个元素为前者中若干元素的和。在调用核函数之后,将短一些的数组复制到主机,然后在主机中完成了余下的求和。所有这些操作所用时间约为 7.5 ms (单精度的情形),而在 GPU 中实际计算的时间仅为 1.4ms 左右。
如果能在 GPU 中计算出 最终结果,则有望显著地减少整体的计算时间,提升程序性能。有两种方法能够在 GPU 中 得到最终结果,一是用另一个核函数将较短的数组进一步归约,得到最终的结果(一个数值); 二是在先前的核函数的末尾利用原子函数进行归约,直接得到最终结果。本节讨论原子函数的方法。
在前述的几种方式中,核函数最后执行的都是
if (tid == 0)
{
d_y[bid] = s_y[0];
}即 将每一个线程块中归约的结果从共享内存 s_y[0] 复制到全局内 存 d_y[bid]。为了将不同线程块的部分和 s_y[0] 累加起来,存放到一个全局内存地址,我 们尝试将上述代码改写如下:
if (tid == 0) {
d_y[0] += s_y[0];
}问题是该语句在每一个线程块的第 0 号线程都会被执行, 但是它们执行的次序是不确定的。在每一个线程中,该语句其实可以分解为两个操作:首 先从 d_y[0] 中取数据并与 s_y[0] 相加,然后将结果写入 d_y[0]。不管次序如何,只有当 一个线程的“读-写”操作不被其他线程干扰时,才能得到正确的结果。如果一个线程还未 将结果写入 d_y[0],另一个线程就读取了 d_y[0],那么这两个线程读取的 d_y[0] 就是一 样的,这必将导致错误的结果。
要得到所有线程块中 的 s_y[0] 的和,必须使用原子函数,其用法如下 :
if (tid == 0)
{
atomicAdd(d_y, s_y[0]);
}原子函数 atomicAdd(address, val) 的第一个参数是待累加变量的地址 address,第二个 参数是累加的值 val。该函数的作用是将地址 address 中的旧值 old 读出,计算 old + val, 然后将计算的值存入地址 address。这些操作在一次原子事务(atomic transaction)中完成, 不会被别的线程中的原子操作所干扰。原子函数不能保证各个线程的执行具有特定的次序, 但是能够保证每个线程的操作一气呵成,不被其他线程干扰,所以能够保证得到正确的结果。
使用原子函数后总时间变为 2.8 ms,相比于之前的方式,性能提升接近3倍,GPU中操作耗时如下:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 66.95% 194.36ms 100 1.9436ms 1.8185ms 2.0081ms reduce(float const *, float*, int)
33.00% 95.797ms 101 948.48us 1.4400us 95.642ms [CUDA memcpy HtoD]
0.05% 133.09us 100 1.3300us 1.2160us 2.6560us [CUDA memcpy DtoH]GPU中计算耗时从1.4ms增加到1.8ms,这是由于d_y也在GPU中计算导致的,另外比较明显的是由于从GPU输出结果的数量变少,DevicetoHost 的时间占比大幅缩减。
2.4.2 使用线程束函数与协作组
线程束(warp) 是 SM 中基本的执行单元。一个线程束由32个连续线程组成,这些线程按照单指令多线程(SIMT)方式执行(即所有线程执行相同指令,每个线程在私有数据上操作)。这样如果在条件语句中,同一线程束中的线程执行不同的指令,就会发生线程束分化(warp divergence) ,导致性能出现明显下降。
在归约问题中,当所涉及的线程都在一个线程束内时,可以将线程块同步函 数 __syncthreads 换成一个更加廉价的线程束同步函数 __syncwarp。
for (int offset = blockDim.x >> 1; offset >= 32; offset >>= 1)
{
if (tid < offset)
{
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
for (int offset = 16; offset > 0; offset >>= 1)
{
if (tid < offset)
{
s_y[tid] += s_y[tid + offset];
}
__syncwarp();
}当 offset >= 32 时,我们在每一次折半求和后使用线程块同步函 数 __syncthreads; 当 offset <= 16 时,我们在每一次折半求和后使用束内同步函数 __syncwarp。
另外还可以利用线程束洗牌函数进行归约计算,函数 __shfl_down_sync 的作用是将高线程号的数据平移到低线程号中去,这正是归约问题中需要的操作
for (int offset = 16; offset > 0; offset >>= 1)
{
y += __shfl_down_sync(FULL_MASK, y, offset);
}相比之前的版本,有两处不同。第一,在进行线程束内的循环之前,将共享内存中的数据复制到了寄存器。在线程束内使用洗牌函数进行规约时,不再需要明显地使用共享内存。因为寄存器一般来说比共享内存更高效,所以能用寄存器就当然用寄存器 了。第二,去掉了束同步函数,这是因为洗牌函数能够自动处理同步与读-写竞争问题。
协作组(cooperative groups)可以看作是线程块和线程束同步机制的推广,它提供了更为灵活的线程协作方式,包括线程块内部的同步与协作、线程块之间的(网格级的)同步与协作及设备之间的同步与协作。
使用协作组的功能时需要在相关源文件包含如下头文件 ,并导入命名空间:
#include <cooperative_groups.h>
using namespace cooperative_groups;可以用函数 tiled_partition 将一个线程块划分为若干片(tile),每一片构成一个 新的线程组。目前仅仅可以将片的大小设置为 2 的正整数次方且不大于 32,也就是 2、 4、8、16 和 32 。例如,如下语句通过函 数 tiled_partition 将一个线程块分割为我们熟知的线程束:
thread_group g32 = tiled_partition(this_thread_block(), 32);同时线程块片类型中也有洗牌函数,可以利用线程块片来进行数组归约的计算。
real y = s_y[tid];
thread_block_tile<32> g = tiled_partition<32>(this_thread_block());
for (int i = g.size() >> 1; i > 0; i >>= 1)
{
y += g.shfl_down(y, i);
}这3种方式的性能如下所示,性能相比之前的方式都有所提高:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 29.49% 190.45ms 100 1.9045ms 1.8181ms 2.0072ms reduce_syncwarp(float const *, float*, int)
27.84% 179.82ms 100 1.7982ms 1.7960ms 1.8183ms reduce_shfl(float const *, float*, int)
27.82% 179.65ms 100 1.7965ms 1.7957ms 1.7976ms reduce_cp(float const *, float*, int)
14.80% 95.571ms 301 317.51us 1.4390us 95.122ms [CUDA memcpy HtoD]
0.06% 384.69us 300 1.2820us 1.2150us 1.7920us [CUDA memcpy DtoH]2.4.3 进一步分析和优化
在前边的例子中, 我们都使用大小为 128 的线程块,所以当 offset 等于 64 时,只用了 1/2 的线程进行计算,其余线程闲置。当 offset 等于 32 时,只用了 1/4 的线程进行计算,其余线程闲置。最终,当 offset 等于 1 时,只用了 1/128 的线程进行计算,其余线程闲置。归约过程一共用了 log2 128 = 7 步, 故归约过程中线程的平均利用率只有 (1/2 + 1/4 + ...)/7 ≈ 1/7 。
为了提高效率,可以考虑在归约之前将多个全局内存数组的数据累加到一个共享内存数组的一个元素中。用一个寄存器变量 y,用来在循环 体中对读取的全局内存数据进行累加, 在规约之前,必须将寄存器中的数据复制到共享内存。
real y = 0.0;
const int stride = blockDim.x * gridDim.x;
for (int n = bid * blockDim.x + tid; n < N; n += stride)
{
y += d_x[n];
}
s_y[tid] = y;
__syncthreads();另外还需要一个调用该核函数的包装函数,以返回最终的计算结果。这里,将GRID_SIZE取为10240,将BLOCK_SIZE取为128。在第10行,调用核函数将长一些的数 组 d_x 归约到短一些的数组 d_y 时,我们使用执行配置 <<<GRID_SIZE, BLOCK_SIZE>>>。当 数据量为 N = 100000000 时,在归约前每个线程将先累加几十个数据。再次调用同一 个核函数将数组 d_y 归约到最终结果(我们就将它保存在 d_y[0])时,仅使用一个线程块,但将线程块大小设置为所允许的最大值,即 1024。
real reduce(const real *d_x)
{
const int ymem = sizeof(real) * GRID_SIZE;
const int smem = sizeof(real) * BLOCK_SIZE;
real h_y[1] = {0};
real *d_y;
CHECK(cudaMalloc(&d_y, ymem));
reduce_cp<<<GRID_SIZE, BLOCK_SIZE, smem>>>(d_x, d_y, N);
reduce_cp<<<1, 1024, sizeof(real) * 1024>>>(d_y, d_y, GRID_SIZE);
CHECK(cudaMemcpy(h_y, d_y, sizeof(real), cudaMemcpyDeviceToHost));
CHECK(cudaFree(d_y));
return h_y[0];
}完整计算时间只需要0.85ms, GPU上核函数的计算时间更是极大缩减。
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 62.32% 95.388ms 1 95.388ms 95.388ms 95.388ms [CUDA memcpy HtoD]
37.59% 57.529ms 200 287.64us 6.4000us 572.79us reduce_cp(float const *, float*, int)
0.09% 135.46us 100 1.3540us 1.3110us 2.5600us [CUDA memcpy DtoH]在上面的包装函数 reduce 中,需要为数组 d_y 分配与释放设备内存。实际上,设备内存的分配与释放是比较耗时的。一种优化方案是使用静态全局内存代替这里的动态全局内存,因为静态内存是编译期间就会分配好的,不会在运行程序时反复地分配,故比动态内存分配高效很多。
利用函数 cudaGetSymbolAddress 将该指针与静态全局变量 static_y 联系起来,更新 reduce 包装函数如下:
__device__ real static_y[GRID_SIZE];
real reduce(const real *d_x)
{
real *d_y;
CHECK(cudaGetSymbolAddress((void**)&d_y, static_y));
const int smem = sizeof(real) * BLOCK_SIZE;
reduce_cp<<<GRID_SIZE, BLOCK_SIZE, smem>>>(d_x, d_y, N);
reduce_cp<<<1, 1024, sizeof(real) * 1024>>>(d_y, d_y, GRID_SIZE);
real h_y[1] = {0};
CHECK(cudaMemcpy(h_y, d_y, sizeof(real), cudaMemcpyDeviceToHost));
// CHECK(cudaMemcpyFromSymbol(h_y, static_y, sizeof(real)); // also ok
return h_y[0];
}计算时间从 0.85ms 缩短到了 0.6 ms。
总结一下以上各种方法的结果及性能:
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!
自动驾驶感知:目标检测、语义分割、BEV感知、毫米波雷达视觉融合、激光视觉融合、车道线检测、目标跟踪、Occupancy、深度估计、transformer、大模型、在线地图、点云处理、模型部署、CUDA加速等技术交流群;
多传感器标定:相机在线/离线标定、Lidar-Camera标定、Camera-Radar标定、Camera-IMU标定、多传感器时空同步等技术交流群;
多传感器融合:多传感器后融合技术交流群;
规划控制与预测:规划控制、轨迹预测、避障等技术交流群;
定位建图:视觉SLAM、激光SLAM、多传感器融合SLAM等技术交流群;
三维视觉:三维重建、NeRF、3D Gaussian Splatting技术交流群;
自动驾驶仿真:Carla仿真、Autoware仿真等技术交流群;
自动驾驶开发:自动驾驶开发、ROS等技术交流群;
其它方向:自动标注与数据闭环、产品经理、硬件选型、求职面试、自动驾驶测试等技术交流群;
扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】硬件专场
















 5828
5828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









