






作者 | 科技猛兽 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
导读
本文提出 AnyGPT,一种 any-to-any 的多模态大语言模型。采用离散的表征统一处理语音、文本、图像和音乐等多种不同模态信号。文章构建了一个多模态,以文本为中心的数据集 AnyInstruct-108k。该数据集利用生成模型合成,是一个大规模多模态指令数据集。
本文目录
1 AnyGPT:序列建模的统一多模态 LLM
(来自复旦大学,上海 AI Lab)
1 AnyGPT 论文解读
1.1 从多模态输入文本输出,到多模态输入多模态输出
1.2 AnyGPT 多模态分词器
1.3 AnyGPT 基座模型
1.4 AnyGPT 生成过程
1.5 AnyGPT 数据集
1.6 实验结果
太长不看版
AnyGPT 是一种 any-to-any 的多模态大语言模型,它可以处理多种模态数据,包括语音、文本、图像和音乐。不同于之前的多模态大模型的点是 AnyGPT 使用了 LLM 的架构和范式。但是与 LLM 不同的是,AnyGPT 把不同模态的数据作了一些恰当的预处理,从而使得这些数据都能使用 LLM 来建模。
同时,为了训练这种 any-to-any 的多模态大语言模型,作者构建了一个多模态数据集,是第一个大规模多模态指令数据集。
本文做了什么工作
1 提出 AnyGPT,一种 any-to-any 的多模态大语言模型。采用离散的表征统一处理语音、文本、图像和音乐等多种不同模态信号。
实现方案:使用多模态分词器 (tokenizer),将原始的多模态数据,比如图像和语音,压缩成离散语义 token 的序列。再使用多模态解分词器 (de-tokenizer),将离散语义 token 的序列转换回原始模态数据。离散表征的好处是能够过滤掉高频的,特定于模态的感知信息,同时保留基本的低频语义信息。架构层面,继承现有的 LLM 架构,无需任何修改。同时允许直接应用现有的 LLM 工具,从而提高训练和推理的效率。
2 构建了一个多模态,以文本为中心的数据集 AnyInstruct-108k。该数据集利用生成模型合成,是一个大规模多模态指令数据集。
实现方案:该数据集包含 108k 个多轮对话样本,这些样本复杂交织了各种模态,从而使 AnyGPT 模型能够处理多模态输入和输出的任意组合。
3 非常有趣的一点:证明了离散表征可以非常有效地使用 LLM 来统一多种模态的数据。
1 AnyGPT:序列建模的统一多模态 LLM
论文名称:AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling (Arxiv 2024.02)
论文地址:
https://arxiv.org/abs/2402.12226v2
论文主页:
https//junzhan2000.github.io/AnyGPT.github.io/
1 AnyGPT 论文解读:
1.1 从 "多模态输入文本输出",到 "多模态输入多模态输出"
LLM 在理解和生成人类语言方面表现出非凡的能力。但是,LLM 的能力仅限于针对文本的处理。而现实世界的环境本质上是多模态的:生物体通过不同的通道感知和交换信息,包括视觉、语言、声音和触觉。
因此,开发 LLM 的多模态能力,势必对 LLM 来讲是个有前途的方向。当前的方法主要是将一个多模态的编码器 (比如视觉的 ViT) 和 LLM 相结合,使其能够处理各种模态的信息,并利用 LLM 强大的文本处理能力来产生有效的输出。但是这种策略仅限于文本生成,不包括多种模态的输出。比如 Emu[1],SEED-LLaMA[2] 等等。虽然将文本与一个额外的模态对齐相对简单,但在单个框架内集成3种以上的模态,并在它们之间实现双向对齐,就是个更加困难的挑战。
1.2 AnyGPT 多模态分词器
AnyGPT 方法包含3个部分:多模态 tokenizer,LLM 架构,和多模态 de-tokenizer。tokenizer 将连续的非文本模态转换为离散的 token 序列。LLM 使用 next token prediction 的训练目标进行训练。在推理时,通过多模态 de-tokenizer 将 tokens 解码回原始模态的表征。
Image Tokenizer
图像分词器使用 SEED[3]的实现。SEED 分词器包括:ViT encoder,Causal Q-Former, VQ Codebook,multi-layer perceptron (MLP),和 UNet decoder。SEED 分词器以 224×224 RGB 图像作为输入,经过 ViT 转成 16×16 的 Patches,再经过 Causal Q-Former 把 Patch 的特征转化成 32 个 causal embeddings。另外通过一个大小为8192的 codebook 将特征转化成量化代码序列。再通过 MLP 解码成生成嵌入。最后经过 UNet decoder 变回原始图像。
Speech Tokenizer
语音分词器使用的是 SpeechTokenizer[4]的实现。SpeechTokenizer 使用8个分层量化器将单通道音频序列压缩为离散矩阵,每个量化器有 1,024 个条目,并实现了 50 Hz 的帧速率。第1个量化器层捕获语义内容,而第2层到第8层编码副语言细节。它可以将10秒的音频转换为 500×8 的矩阵,分为语义和声学 tokens。
Music Tokenizer
音乐分词器使用的是 Encodec[5]的实现。它是一种卷积自编码器。作者使用在 20k 条音乐轨道上预训练的 Encodec。本文使用的 Encodec 处理 32 kHz 单音音频,实现了 50 Hz 的帧速率。生成的嵌入使用具有4个量化器的 RVQ 进行量化,每个量化器 codebook 的大小为 2048,导致组合音乐词汇量为 8192。作者把 5s 的音乐编码成 250 latent frames,最终生成一个 250×4 的代码矩阵。
所有分词器的配置信息如图1所示,AnyGPT 的整体架构如图2所示。


1.3 AnyGPT 基座模型
词汇表
因为 AnyGPT 适配多种模态,因此扩展了词汇表。词汇表的大小是所有词汇表大小的总和: 。其中 表示第 个模态的词汇量。
基座模型
AnyGPT 使用 LLaMA-2-7B[6]作为基座模型,它在 2TB 的文本标记上进行了预训练。除了重塑 embedding matrix 和预测层外,其余语言模型保持不变。
1.4 AnyGPT 生成过程
高质量多模态数据的生成,包括高清图像和高保真音频。这是一个很有挑战性的问题,因为这些数据需要更长的位宽,导致更长的序列。但是 LLM 的计算量随着序列长度增加而指数级增加,因此需要想其他方法。
为了解决这个问题,AnyGPT 采用两阶段框架进行高保真生成,包括语义信息建模和感知信息建模。第一阶段,LLM 任务是语义级别的生成。第2阶段,非自回归模型将多模态语义标记转换为感知级别的高保真多模态内容,在性能和效率之间取得平衡。
对于图像,SEED tokens 通过扩散模型解码为高质量图像。对于语音,使用 SoundStorm[7]这个非自回归掩码语言模型,经过训练可以从语义 tokens 中生成 SpeechTokenizer 的声学 tokens。对于音乐,作者使用 Encodec tokens 过滤掉人类感知之外的高频细节,然后使用 Encodec 解码器将这些 tokens 重建为高保真音频数据。
1.5 AnyGPT 数据集
为了实现从任何模态到任何其他模态的生成,就需要有很多这些模态之间对齐的训练数据。但是这类数据非常稀缺。因此,作者构建了一个以文本为中心的双模态对齐数据集。在这个数据集中,文本作为中间对齐的媒介。通过将不同的模态与文本模态对齐,来实现在所有模态之间的相互对齐。
如下图3所示是预训练中使用的所有数据及其相应的比例,对那些数据量相对较少的模态应用过采样,以使得不同的数据类型的表征取得相对平衡。
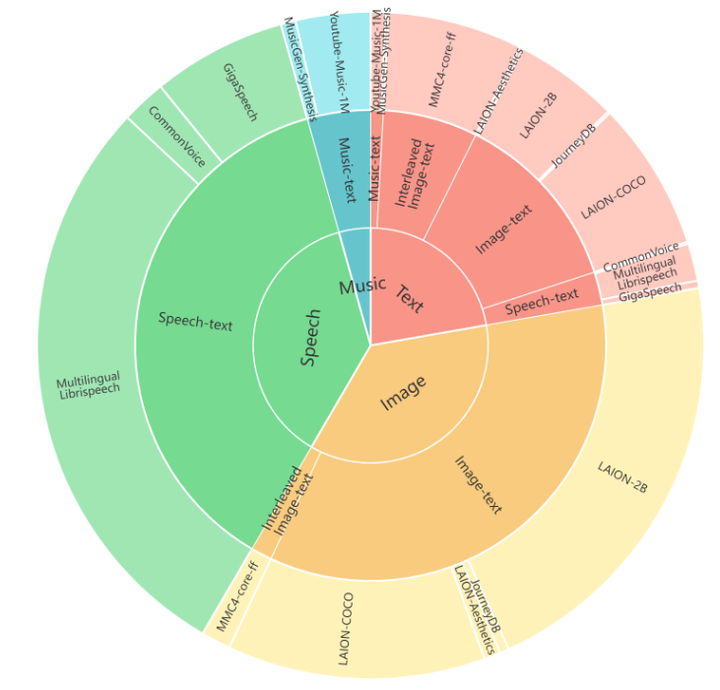
Image Text 数据集:LAION-2B,LAION-COCO,LAION-Aesthetics,JouneyDB。
Speech Text 数据集:Gigaspeech,Common Voice,Multilingual LibriSpeech (MLS)。
Music Text 数据集:从互联网上抓取超过一百万个音乐视频,使用 Spotify API 将这些视频的标题与相应的歌曲进行匹配。并使用 GPT-4 将音乐的题目、描述、关键词、播放列表名称和识别歌词等元数据简洁地总结为连贯的句子。这样就可以为大量音乐音频生成高质量的文本标题。
多模态交织的指令数据集构建过程
有效的人机交互应该允许在各种模态之下交互信息。但是现有的大规模指令数据集没有涉及两种模态以上的。因此本文构建了一个多模态交织的指令数据集。过程如下图4所示,分两个阶段完成:第1阶段生成主题、场景和文本对话,第2阶段生成最终的多模态对话。
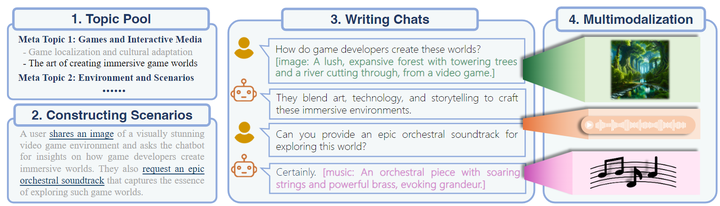
第1阶段,作者使用 GPT-4 来生成一系列基于文本的对话,分为3小步:
头脑风暴100个包含很多场景的话题,再使用 GPT-4 将这些主题扩展为20,000个特定的主题。
给 LLM Prompt,使其根据这些主题生成特定的对话场景。
利用 GPT-4 生成从场景生成多轮对话。在这些合成的对话中,图像和音乐等多模态数据通过详细的文本表示来描述。
第2阶段,作者使用高级生成模型将文本描述转换为多模态元素。
使用 OpenAI's DALL-E-3 来生成图像。
使用 MusicGen 来生成音乐。
使用 Microsoft Azure 的文本到语音 API 来生成语音。
经过过滤后,最终获得了一个包含 108k 个高质量多模态对话的数据集,具有各种多模态组合。该数据集包含大约 205k 图像、503k 语音记录和 113k 音乐轨道。
1.6 实验结果
评测方法: 多模式理解和生成任务,旨在测试预训练过程中不同模态之间的对齐。具体而言,作者测试了每个模态的文本到 和 到文本任务,其中 分别是图像、音乐和语音。
为了模拟现实世界的场景,所有评测都是在 Zero-Shot 的模式下进行的。这意味着在评测过程中不会进行任务对下游任务的微调或训练。评估结果表明,AnyGPT 作为通才多模态语言模型,在各种多模态理解和生成任务上实现了最先进的性能。
图像实验结果
图像理解实验结果如下图4所示。作者评估了 AnyGPT 在图像字幕任务上的图像理解能力。作者使用 MS-COCO 2014 字幕 Benchmark,并遵循之前的研究采用的 Karpathy 分割测试集。
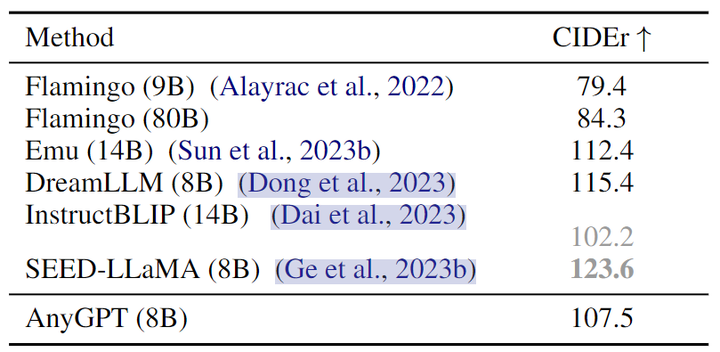
文本到图像生成任务的结果如图5所示。为了确保与之前研究的一致性,作者从 MS-COCO 的验证集里面随机选择 30 k 张图像,并使用 CLIP 得分作为评测指标。该指标基于 CLIP-ViT-L 模型,从真实图像计算生成图像与其对应的标题之间的相似度得分。

语音实验结果
作者使用自动语音识别 (Automatic Speech Recognition, ASR) 任务来评测 AnyGPT,通过在 LibriSpeech 数据集的测试干净子集上计算单词错误率 (Word Error Rate,WER)。实验结果如图6所示,作者比较的 Baseline 是 Wav2vec 2.0 以及 Whisper Large V2。

作者还在 Zero-Shot 文本到语音 (Text-to Speech, TTS) 任务上评估了 AnyGPT 的结果,数据集是 VCTK。实验结果如图7所示,作者使用说话人相似性和单词错误率 (Word Error Rate, WER) 来评测,其中 WER 专注于语音质量。

音乐实验结果
作者在 MusicCaps 基准上评估了 AnyGPT 用于音乐理解和生成任务的性能,利用 CLAP 分数作为客观指标,衡量生成的音乐和文本描述之间的相似性。实验结果如下图8所示。为了确保评测的客观,作者计算 <music, real caption> 对和 <music, generated caption> 对的 CLAP 分数进行比较。

参考
1.Generative Pretraining in Multimodality
2.Making LLaMA SEE and Draw with SEED Tokenizer
3.Planting a SEED of Vision in Large Language Model
4.SpeechTokenizer: Unified Speech Tokenizer for Speech Large Language Models
5.High Fidelity Neural Audio Compression
6.Llama 2: Open Foundation and Fine-Tuned Chat Models
7.SoundStorm: Efficient Parallel Audio Generation
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









