






作者 | AI 引擎 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
导读
本文作者提出了MTMamba,一种新型的多任务架构,具有基于Mamba的解码器,在多任务场景理解中表现出卓越的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

多任务密集场景理解,它学习一个用于多个密集预测任务的模型,具有广泛的应用场景。建模长距离依赖和增强跨任务交互对于多任务密集预测至关重要。
在本文中,作者提出了MTMamba,一个基于Mamba的新型多任务场景理解架构。它包含两种核心块:自任务Mamba(STM)块和跨任务Mamba(CTM)块。STM通过利用Mamba处理长距离依赖,而CTM显式地建模任务交互以促进跨任务的信息交换。在NYUDv2和PASCAL-Context数据集上的实验表明,MTMamba在基于Transformer和基于CNN的方法上取得了优越的性能。
特别值得一提的是,在PASCAL-Context数据集上,MTMamba在语义分割、人体解析和物体边界检测任务上分别比之前最佳方法提高了+2.08、+5.01和+4.90。
代码可在https://github.com/EnVision-Research/MTMamba。
1 Introduction
多任务密集场景理解是计算机视觉中的一个重要问题[36],并在各种实际应用中具有广泛用途,如自动驾驶[20, 23]、医疗保健[19]和机器人技术[48]。它旨在训练一个模型,能够同时处理多个密集预测任务,如语义分割、单目深度估计、表面法线估计和目标边界检测。
普遍的多任务架构遵循编码器-解码器框架,包括一个用于特征提取的任务共享编码器和用于预测的任务特定解码器[36]。这个框架非常通用,许多变体[42, 43, 37, 46]被提出以改进其在多任务场景理解中的性能。一种有前景的方法是关注解码器的方法[36],其目标是通过精心设计的融合模块增强任务特定解码器中的跨任务交互。例如,源自卷积神经网络(CNN)的PAD-Net[42]和MTI-Net[37]在解码器中引入了多模态蒸馏模块,以促进不同任务之间的信息融合,性能优于编码器-解码器框架。由于卷积操作主要关注局部特征[2],最近的方法[43, 46]提出了基于Transformer的解码器以及基于注意力的融合模块。这些方法利用注意力机制捕捉全局上下文信息,性能优于基于CNN的方法。先前的工作表明,增强跨任务相关性以及建模长距离空间关系对于多任务密集预测至关重要。
最近,源自状态空间模型(SSMs)[14, 15]的Mamba[13]这种新型架构,在包括语言建模[12, 13, 39]、图推理[1, 38]、医学图像分析[30, 41]和点云分析[49, 22]在内的各个领域,展示了比Transformer模型更好的长距离依赖建模能力和性能。然而,所有这些工作都关注单一任务学习,而如何采用Mamba进行多任务训练仍有待研究。此外,如何在Mamba中实现跨任务相关性,对于多任务场景理解是至关重要的,这尚未被探索。
为了填补这些空白,在本文中,作者提出了MTMamba,一种新型的多任务架构,具有基于Mamba的解码器,在多任务场景理解中表现出卓越的性能。整体框架如图1所示。MTMamba是一个关注解码器的方法,包括两种核心块:自任务Mamba(STM)块和跨任务Mamba(CTM)块,如图2所示。具体来说,受Mamba启发的STM能够有效地捕捉全局上下文信息。CTM被设计用来通过促进不同任务之间的知识交换,增强每个任务的特征。因此,通过在解码器中STM和CTM块的协作,MTMamba不仅增强了跨任务交互,而且有效地处理了长距离依赖。
作者在两个标准的 multi-task 密集预测基准数据集 NYUDv2[35] 和 PASCAL-Context[6] 上评估了MTMamba。定量结果表明,MTMamba在多任务密集预测上大大超过了基于CNN和Transformer的方法。特别是,在PASCAL-Context数据集上,MTMamba在语义分割、人体解析和目标边界检测任务上分别比之前最佳的性能提高了+2.08、+5.01和+4.90。定性研究表明,MTMamba比最先进的基于Transformer的方法生成了更好的视觉效果,具有更准确的细节。
作者的主要贡献总结如下:
作者提出了MTMamba,一种新型的多任务架构,用于多任务场景理解。它包含一个基于Mamba的新型解码器,有效地建模长距离空间关系并实现跨任务相关性;
作者设计了一种新型的CTM块,以增强多任务密集预测中的跨任务交互;
在两个基准数据集上的实验证明了MTMamba在多任务密集预测上优于先前的基于CNN和Transformer的方法;
定性评估显示,MTMamba捕捉到了具有判别性的特征并生成了精确的预测。
2 Related Works
Multi-Task Learning
多任务学习(MTL)是一种学习范式,旨在在单个模型中同时学习多个任务[50]。最近的多任务学习研究主要关注多目标优化和网络架构设计。在多任务密集场景理解中,现有的大部分工作集中在设计架构[36],尤其是设计解码器中的特定模块以实现更好的跨任务交互。例如,基于CNN,Xu等人[42]引入了PAD-Net,在解码器中结合了一个有效的多模态蒸馏模块,以促进不同任务之间的信息融合。MTI-Net[37]是一个复杂的多尺度和多任务CNN架构,具有跨不同特征尺度的信息蒸馏。由于卷积操作主要捕捉局部特征[2],最近的方法[43, 46]利用注意力机制来捕捉全局上下文,并为多任务场景理解开发基于Transformer的解码器。例如,Ye和Xu[46]引入了InvPT,这是一个基于Transformer的多任务架构,使用有效的UPT-Transformer块在不同特征尺度上进行多任务特征交互。MQTransformer[43]设计了一个跨任务 Query 注意力模块,以在解码器中实现有效的任务关联和信息交换。
先前的工作表明,长距离依赖建模和增强跨任务相关性对于多任务密集预测至关重要。与现有方法不同,作者提出了一种源自Mamba的新型多任务架构,以更好地捕捉全局信息并促进跨任务交互。
State Space Models
状态空间模型(SSM)是对动态系统的数学表示,它通过隐藏状态来建模输入输出关系。SSM具有普遍性,在强化学习[16]、计算神经科学[10]和线性动态系统[18]等广泛的应用中取得了巨大成功。最近,SSM被提出作为建模长距离依赖的替代网络架构。与旨在捕捉局部依赖的基于CNN的网络[17, 21]相比,SSM对长序列更为强大;与需要序列长度的二次复杂度的基于Transformer的网络[8, 40]相比,SSM在计算和内存效率方面更高。
最近提出了许多不同的结构来提高SSM的表达能力和效率。Gu等人[14]提出结构化状态空间模型(S4)以提高计算效率,其中状态矩阵是低秩矩阵和正常矩阵的和。许多后续工作试图提高S4的有效性。例如,Fu等人[11]设计了一个新的SSM层H3,以缩小SSM和Transformer在语言建模中的性能差距。Mehta等人[32]引入了一种使用门控单元的门控状态空间层,以提高表达能力。
最近,Gu & Dao[13]进一步提出了Mamba,其核心操作为S6,这是S4的输入相关选择机制,它实现了序列长度的线性扩展,并在各种基准测试中展示了超越Transformers的优越性能。Mamba已成功应用于图像分类[53, 27]、图像分割[41]和图预测[38]。与它们在单任务设置中使用Mamba不同,作者考虑了一个更具挑战性的多任务设置,并提出了新的自任务和跨任务Mamba模块来捕捉任务内和任务间的依赖。
3 Methodology
在本节中,作者首先在3.1节介绍了状态空间模型和Mamba的背景知识。然后在3.2节介绍了所提出的多任务Mamba(MTMamba)的整体架构。随后,作者详细探讨了MTMamba的每个部分,包括3.3节中的编码器,3.4节中基于Mamba的解码器以及3.5节中的输出头。
Preliminaries
状态空间模型(SSMs)[13, 14, 15]起源于线性系统理论 , 它通过一个隐藏状态 , 将输入序列 映射到输出序列 , 通过以下线性常微分方程:

其中 是状态矩阵, 是输入矩阵, 是输出矩阵, 是跳跃连接。方程(1)定义了隐藏状态 的演变, 而方程(2)确定输出是由隐藏状态 的线性变换和从 的跳跃连接组成。在本文的其余部分, 为了解释起见, 省略了 (即 )。
由于连续时间系统不适合数字计算机和通常为离散的实际世界数据, 引入了一个离散化过程来近似它到一个离散时间系统。令 为一个离散时间步长。方程(1)和(2)离散化为

其中 , 以及
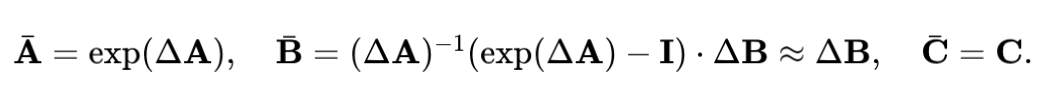
在S4 [14]中, 是通过梯度下降学习的可训练参数, 并且不显式依赖于输入序列, 这导致了对上下文信息提取的弱化。为了克服这一点, Mamba [13] 提出了 S6, 它引入了一个依赖于输入的选择机制, 允许系统根据输入序列选择相关信息。这是通过将 B、C 和 作为输入 的函数来实现的。更正式地说, 给定一个输入序列 , 其中 是批大小, 是序列长度, 是特征维度, 输入相关参数 计算如下:

其中 是一个可学习的参数, SoftPlus( 是SoftPlus函数, Linear 是线性层。 是一个像在 中那样的可训练参数。计算出 后, 通过方程(5)进行离散化,然后输出序列 通过方程(3)和(4)计算得出。
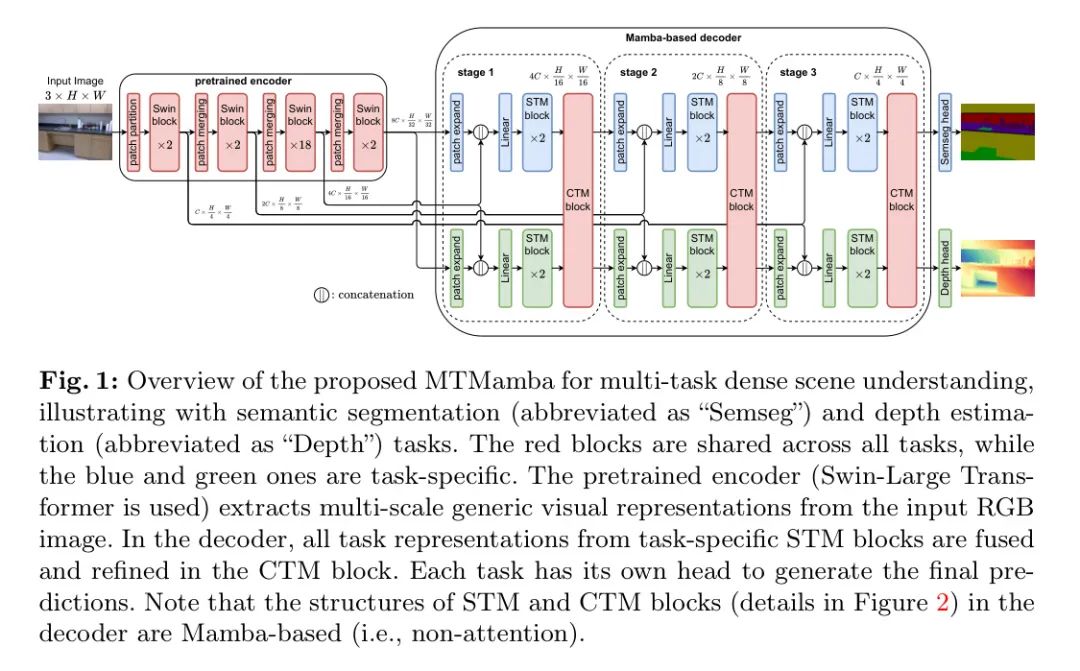
Overall Architecture
MTMamba的概览如图1所示。它包含三个组件:一个现成的编码器,一个基于Mamba的解码器,以及特定任务的 Head 。
具体来说,编码器在所有任务中共享,负责从输入图像中提取多尺度的通用视觉表示。解码器由三个阶段组成。每个阶段都包含特定任务的STM块,以捕捉每个任务的长距离空间关系,以及一个共享的CTM块,通过跨任务交换知识来增强每个任务的特征。最后,使用一个输出 Head 来生成每个任务的最终预测。以下作者介绍每个部分的细节。
Encoder
作者以Swin Transformer [28]为例。考虑一个输入的RGB图像 , 其中 和 分别是图像的高度和宽度。编码器使用一个 Patch 分割模块将输入图像分割成非重叠的 Patch 。每个 Patch 被视为一个标记(token), 其特征表示是对原始RGB像素值的拼接。在实验中,作者使用标准的 Patch 大小 。因此, 每个 Patch 的特征维度是 。在 Patch 分割之后, 一个线性层被用于将原始标记投影到一个 维度的特征嵌入。经过转换后的 Patch 标记顺序地通过多个Swin Transformer块和 Patch 合并层, 它们共同生成层次化的特征表示。具体来说, Patch 合并层[28]用于将空间维度(即 和 )下采样2倍, 并将特征维度(即 C) 扩展2倍, 而Swin Transformer块专注于学习和精炼特征表示。正式地, 经过编码器前向传播后, 作者得到四个阶段的输出:

其中 和 的大小分别为 和 。
Mamba-based Decoder
将SSMs扩展到2D图像中. 与1D语言序列不同,2D空间信息在视觉任务中至关重要。因此,第3.1节中引入的SSMs不能直接应用于2D图像。受到[27]的启发,作者引入了2D选择扫描(SS2D)操作来解决这个问题。该方法包括沿着四个方向扩展图像块,生成四个独特的特征序列。然后,每个特征序列被送入一个SSM(如S6)。最后,处理过的特征被组合起来构建全面的2D特征图。正式地, 给定输入特征 的输出特征 计算为
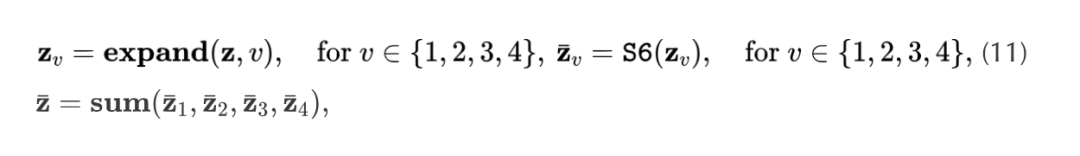
其中 是四个不同的扫描方向, expand 是沿着方向 扩展2D特征图 是第3.1节中引入的S6操作, 而 是逐元素的加法操作。
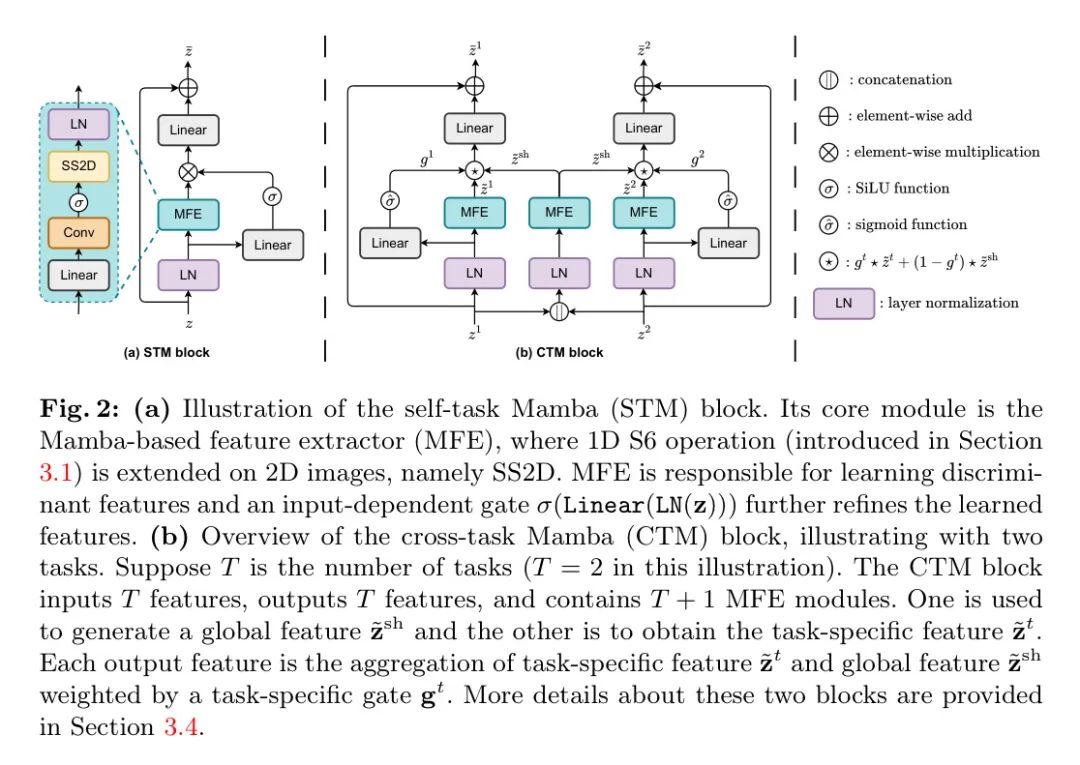
基于Mamba的特征提取器(MFE). 作者引入了一个基于Mamba的特征提取器来学习2D图像的表示。它是所提出基于Mamba的解码器中的一个关键模块。如图2(a)所示, 受到[13]的启发, MFE由一个线性层用于通过可控扩展因子 扩展特征维度, 一个带有激活函数的卷积层用于提取局部特征, 一个SS2D操作用于建模长距离依赖, 以及一个层归一化来规范化学习到的特征。更正式地说, 给定输入特征 , MFE的输出 计算为

其中 是层归一化, 是激活函数, 在作者的实验中使用 函数, 是卷积操作。
自任务Mamba(STM)块。作者基于MFE引入了一个自任务Mamba块,用于学习基于特定任务的特征, 如图2(a)所示。受到[13]的启发, 作者使用一个输入依赖的门来自适应地选择从 MFE中学到的有用表示。之后, 使用线性层减少在MFE中扩展的特征维度。具体来说, 对于输入特征 , STM块中的计算如下:

其中 是逐元素乘法。
跨任务玛玛(CTM)块尽管STM块可以有效学习每个单独任务的表征, 但它缺乏任务间的连接以共享对MTL性能至关重要的信息。为了解决这个问题, 作者设计了一个新颖的跨任务玛玛块 (如图2(b)所示), 通过修改STM块以实现不同任务间的知识交换。具体来说, 给定所有任务的特征 , 其中 是任务的数量, 作者首先将所有任务特征进行拼接, 然后通过MFE学习一个全局表征 。每个任务也通过其自己的MFE学习相应的特征 。然后, 作者使用一个输入依赖的门来聚合任务特定表征 和全局表征 。因此, 每个任务自适应地融合全局表征和其特征。正式地, CTM块的前向过程如下:

其中公式部分按照要求保持原始输出。
其中 concat 是拼接操作, 是激活函数, 与STM块中使用的SiLU不同, 作者使用更适合生成门控因子 的sigmoid函数,如公式(23)所示。
阶段设计。如图1所示, 基于Mamba的解码器包含三个阶段。每个阶段都有类似的设计, 包括 Patch 扩展层、STM块和CTM块。Patch 扩展层用于将特征分辨率上采样2倍, 并将特征维度减少2倍。对于每个任务, 其特征将通过一个 Patch 扩展层进行扩展, 并通过跳跃连接与编码器中的多尺度特征融合, 以补充因下采样而造成的空间信息损失。然后, 使用线性层减少特征维度, 两个STM块负责学习任务特定的表示。最后, 应用CTM块通过跨任务的知识交换来增强每个任务的特征。除了CTM块, 其他模块是特定于任务的。更正式地说, -阶段 的前向过程可以表示为

其中 , PatchExpand 是 Patch 扩展层, 和 分别是STM块和CTM块。
Output Head
在从解码器获取每个任务的特征后, 每个任务都有自己的输出头以生成其最终预测。受 的启发, 每个输出头包含一个 Patch 扩展层和一个线性层, 这非常轻量级。具体来说, 对于解码器输出的第 个任务特征 , 其大小为 , Patch 扩展层执行 上采样以将特征图的分辨率恢复到输入分辨率 , 然后使用线性层输出最终的像素级预测。
4 Experiments
在本节中,作者进行了大量的实验来证明所提出的MTMamba在多任务密集场景理解中的有效性。
Experimental Setups
数据集。继[43, 46]之后,作者在带有多任务标签的两个广泛使用的基准数据集上进行了实验:NYUDv2 [35] 和 PASCAL-Context [6]。NYUDv2 数据集包含了各种室内场景,分别有795和654张RGB图像用于训练和测试。它包括四个任务:40类语义分割(Semseg)、单目深度估计(Depth)、表面法线估计(Normal)和物体边界检测(Boundary)。PASCAL-Context 数据集源自 PASCAL 数据集 [9],包括室内和室外场景,并提供像素级的标签,用于诸如语义分割、人体解析(Parsing)和物体边界检测等任务,以及由 [31] 生成的表面法线估计和显著性检测任务的附加标签。它包含4,998张训练图像和5,105张测试图像。
实现细节。作者使用在 ImageNet-22K 数据集 [7] 上预训练的 Swin-Large Transformer [28] 作为编码器。所有模型均以 8 的批量大小训练 50,000 次迭代。采用 AdamW 优化器 [29], 学习率为 , 权重衰减为 。在训练过程中使用多项式学习率调度器。MFE 中的扩展因子 设置为2。继[46]之后, 作者将 NYUDv2 和 PASCAL-Context 的输入图像分别调整为 和 , 并使用相同的数据增强, 包括随机颜色抖动、随机裁剪、随机缩放和随机水平翻转。作者使用 损失进行深度估计和表面法线估计任务, 对于其他任务则使用交叉摘损失。
评估指标。继[46]之后, 作者对语义分割和人体解析任务使用平均交并比 (mloU), 单目深度估计任务使用均方根误差(RMSE), 表面法线估计任务使用平均误差(mErr),显著性检测任务使用最大 F-measure (maxF) , 物体边界检测任务使用最优数据集尺度 F-measure (odsF) 。此外, 作者使用平均相对多任务学习性能 (在 [36] 中定义)作为整体性能指标。
Comparison with State-of-the-art Methods
作者对比了所提出的MTMamba方法与两类多任务学习(MTL)方法:基于卷积神经网络(CNN)的方法,包括Cross-Stitch ,PAP ,PSD ,PAD-Net ,MTI-Net ,ATRC [3]和ASTMT ,以及基于Transformer的方法,即InvPT [46]和MQTransformer [43]。
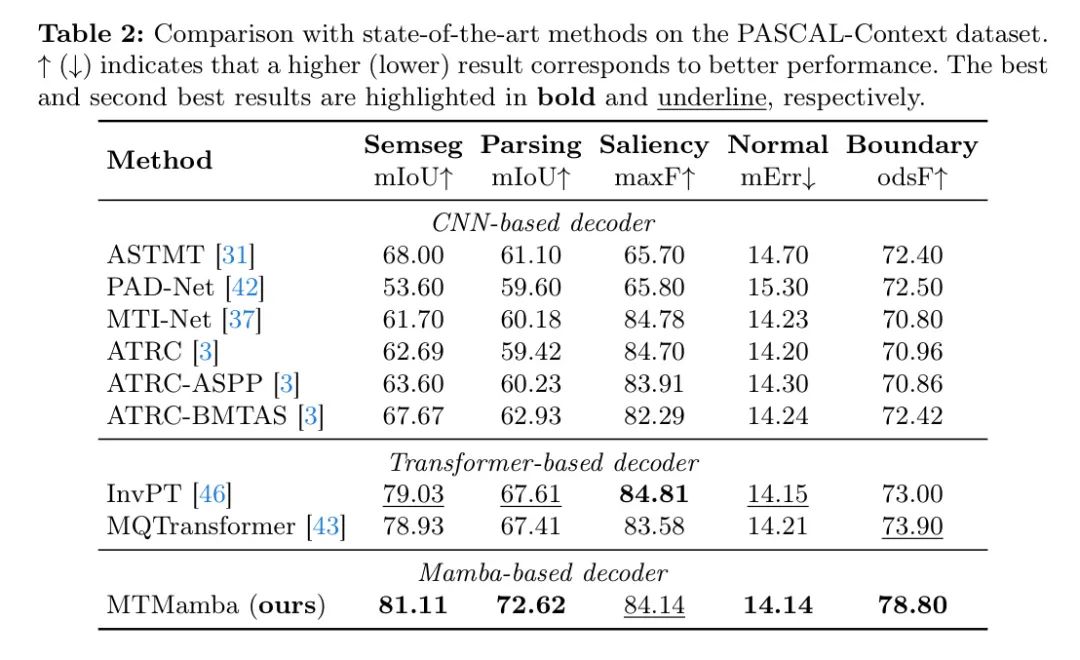
表1展示了在NYUDv2数据集上的对比结果。可以看出,提出的MTMamba方法在所有四个任务上均表现出色。例如,在语义分割任务上的性能显著优于基于Transformer的方法(即InvPT和MQTransformer),分别提高了+2.26和+0.98,这证明了MTMamba的有效性。与InvPT的定性比较展示在图5中,可以看出MTMamba生成了更准确的预测。

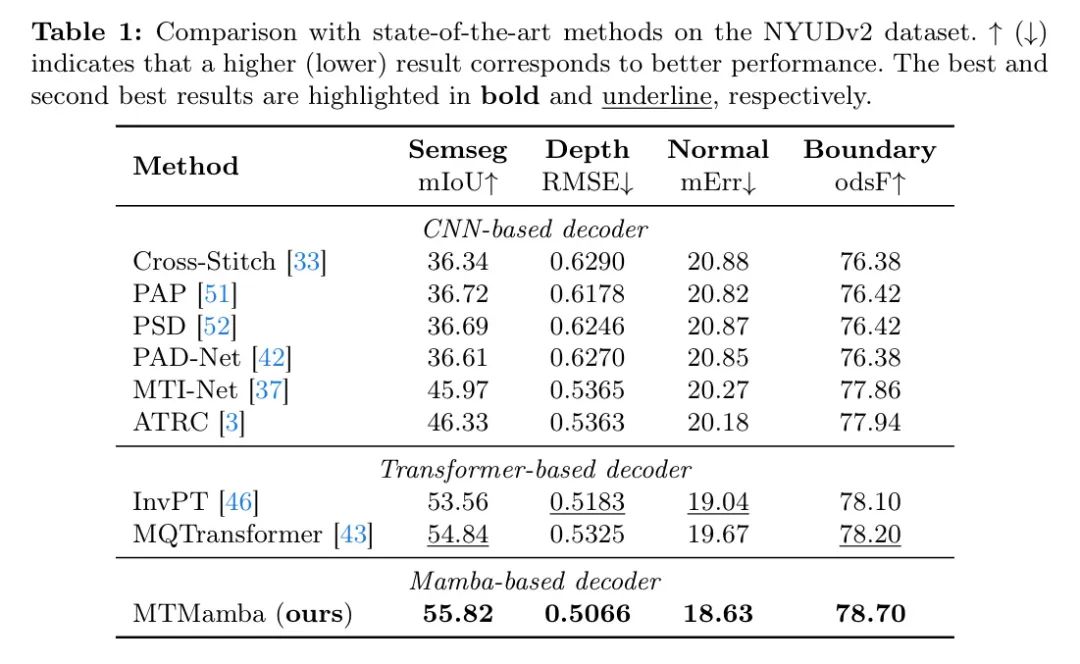
表2提供了在PASCAL-Context数据集上的对比结果。这些结果显示了所提出的MTMamba方法的明显优势。特别是,MTMamba在语义分割、人体解析和目标边界检测任务上分别显著提高了先前的最佳性能+2.08,+5.01和+4.90,再次证明了MTMamba的有效性。同时,与InvPT的定性比较展示在图4中,显示MTMamba提供了更精确的预测和细节。

Model Analysis
STM和CTM块的有效性。所提出的MTMamba包含两种核心块:STM和CTM块。作者在NYUDv2数据集上进行实验,研究在每个解码阶段使用Swin-Large Transformer编码器的每个块的有效性。结果如表3所示。"Swin only"(分别是"STM only")表示每个任务只使用每个解码阶段中的两个特定的Swin Transformer(分别是STM)块。"Single-task"是"Swin only"的单任务对应物,表示每个任务都有其特定任务的模型。"STM+CTM"是MTMamba的默认方法,即与"STM only"相比,在每个解码阶段添加了一个共享的CTM块。

根据表3,"STM only"在很大程度上超过了"Swin only",这表明STM块比Swin Transformer块更有效。此外,"STM only"的参数数量和FLOPs比"Swin only"少,这显示了STM块的效率。与"STM only"相比,"STM+CTM"表现更好,证实了CTM块的益处。此外,默认配置(即"STM+CTM")在所有任务上的表现显著优于"Single-task",这证明了MTMamba的有效性。MFE模块的有效性。如图2所示,MFE模块基于SSM,并且是STM和CTM块的核心。作者通过在NYUDv2数据集上用注意力模块替换MTMamba中的所有MFE模块来进行实验。如表4所示,MFE比注意力更有效且高效。
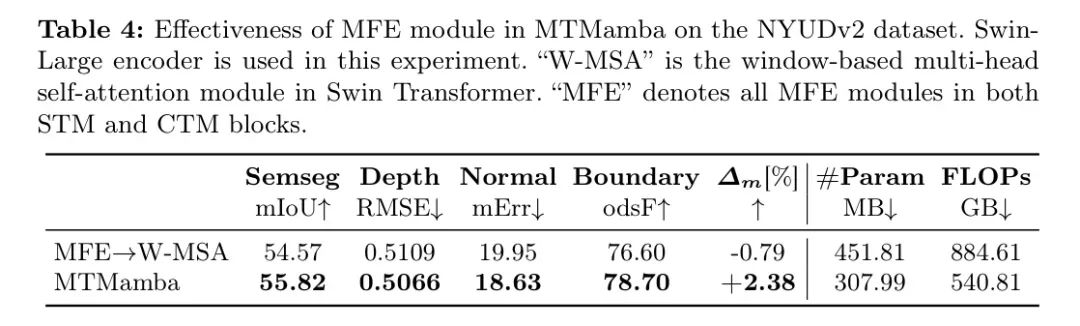
表4:MTMamba中MFE模块在NYUDv2数据集上的有效性。本实验使用了Swin-Large编码器。"W-MSA"是Swin Transformer中的基于窗口的多头自注意力模块。"MFE"表示STM和CTM块中的所有MFE模块。
线性门的有效性。如图2所示,在STM和CTM块中,作者使用一个输入依赖的门来自适应地从MFE模块中选择有用的表示。线性层是门函数的一个简单但有效的选项。作者通过在NYUDv2数据集上用基于注意力的门替换MTMamba中的所有线性门来进行实验。如表5所示,线性门(即MTMamba)在方面与注意力门表现相当,而线性门更高效。

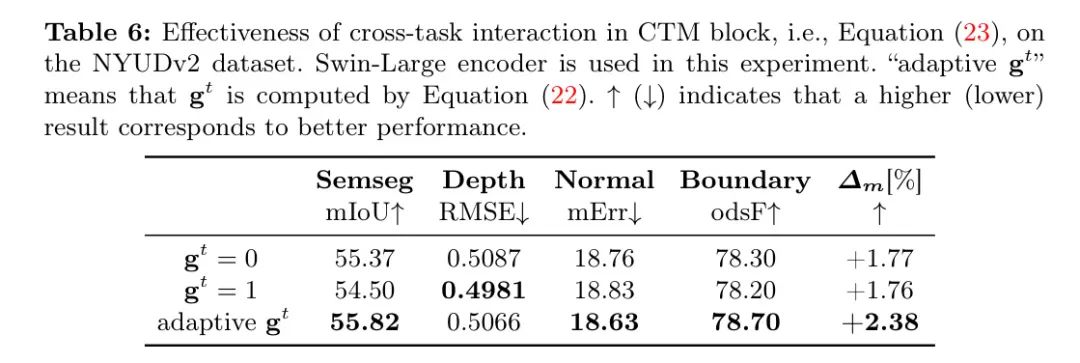
CTM块中跨任务交互的有效性。CTM块的核心是跨任务交互, 即方程(23),作者通过一个特定任务的门 将特定任务表示 和共享表示 融合在一起。在这个实验中, 作者通过将其与 和 的情况进行比较来研究其有效性。实验是在NYUDv2数据集上使用SwinLarge Transformer编码器进行的。结果如表6所示。可以看出, 使用特定的 (即 的情况)或共享的 (即 的情况)会降低性能, 这表明自适应融合更好。
不同编码器的性能。在这个实验中,作者研究在NYUDv2数据集上,提出MTMamba与不同规模的Swin Transformer编码器的性能。结果如表7所示。可以看出,随着模型容量的增加,所有任务的表现相应地更好。

Qualitative Evaluations
在本研究中,作者提出了MTMamba,一个具有基于Mamba解码器的新型多任务架构,用于多任务密集场景理解。通过两个新型块(STM和CTM块),MTMamba能够有效地建模长距离依赖并实现跨任务交互。在两个基准数据集上的实验表明,所提出的MTMamba比先前的基于CNN和基于Transformer的方法取得了更好的性能。
图3展示了在语义分割任务中,所提出的MTMamba与基于 Transformer 的方法InvPT [46]在最终解码器特征上的比较。如图所示,作者的方法高度激活了具有上下文和语义信息的区域,这意味着它

参考
[1].MTMamba: Enhancing Multi-Task Dense Scene Understanding by Mamba-Based Decoders.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵
















 1493
1493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









