








🌻个人主页:相洋同学
🥇学习在于行动、总结和坚持,共勉!
目录
#学习笔记#
线性回归模型是机器学习的入门经典模型
多元线性回归模型的原理是什么,今天来梳理一下,文章末尾复现sklearn中的LinearRegression
1.引入
在简单线性回归中,我们用一个特征值来拟合目标值,然而现实中的数据通常是比较复杂的,自变量也很可能不止一个。例如,影响房屋价格不止房屋面积一个因素,可能还有距离地铁的距离,距市中心距离,房屋数量,房屋所在层数等诸多因素。
但这些因素对房屋价格影响的程度(权重)是不同的。例如,房屋所在层数对房屋价格的影响就远不及房屋面积,因此我们可以为每个特征指定不同的权重。
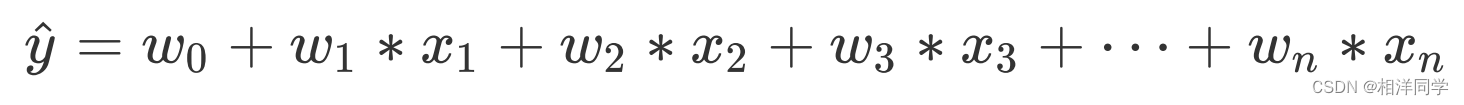
:第i个输入特征
:第i个特征权重(影响力度)
特征的个数。
:预测值(房屋价格)
2.向量表示
我们也可以使用向量的表示方式,设与
为两个向量:
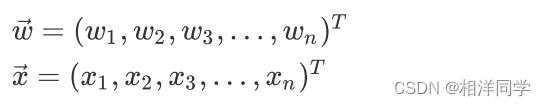
则回归方程可表示为:
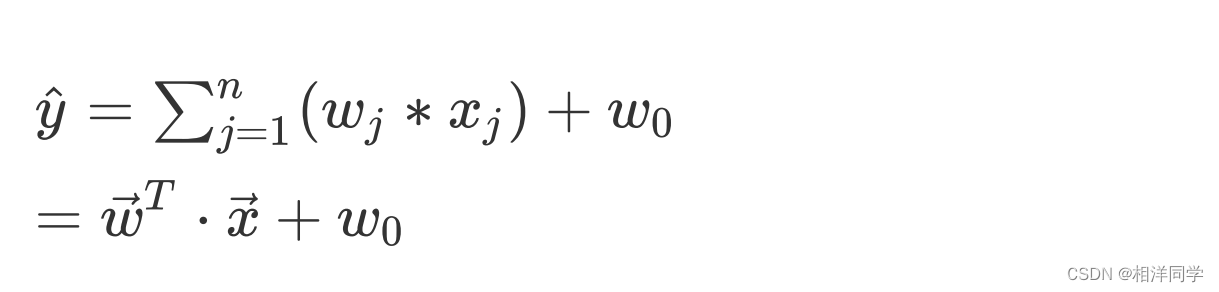
我们可以进一步简化,为向量与
各加入一个分量
与
,并令
=1
于是向量与
就会变成:
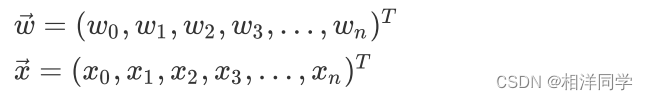
这样,就可以表示为:
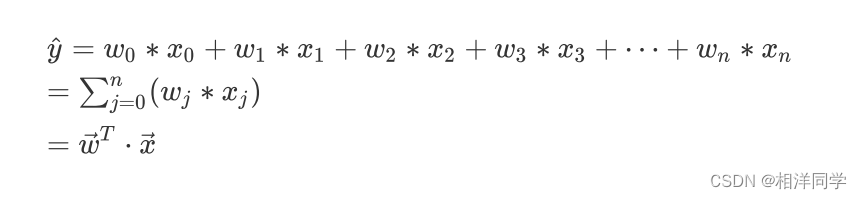
这样做是为了将偏置也纳入矩阵中以便于我们进行计算。
在简单线性回归中我们是对误差ypre-y进行了平方,然后分别对w0和w1求偏导,以求出loss损失函数的极值点,也就是驻点。从而求出了对应的w0和w1。
多元回归中同样如此,只不过是对矩阵进行操作
3.参数估计
3.1误差分布
下面我们看一下线性回归模型中的误差,线性回归中的自变量与因变量是存在线性关系的,然而这种线性关系不是严格的函数映射关系,但是我们构建的模型是严格的函数映射关系,因此,对于每个样本来说,我们拟合的结果会与真实值之间存在一定的误差,我们可以将误差表示为:

代表第i个样本真实值与预测值之间的误差(残差)
对线性回归而言,具有一个前提假设服从均值为0,方差为
的正态分布,容易理解,我们的预测的的残差较小的较多,较大的较少。
根据正态分布的概率密度函数:
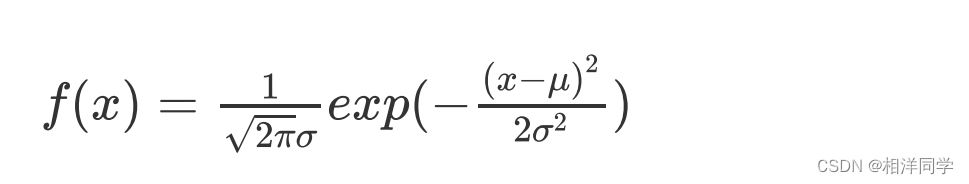
则误差的分布为:
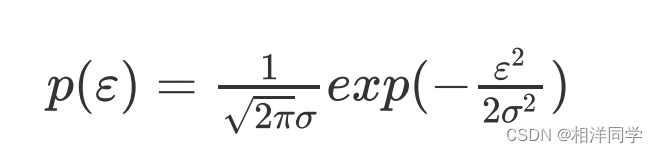
因此对于每一个样本的误差,其概率值为:
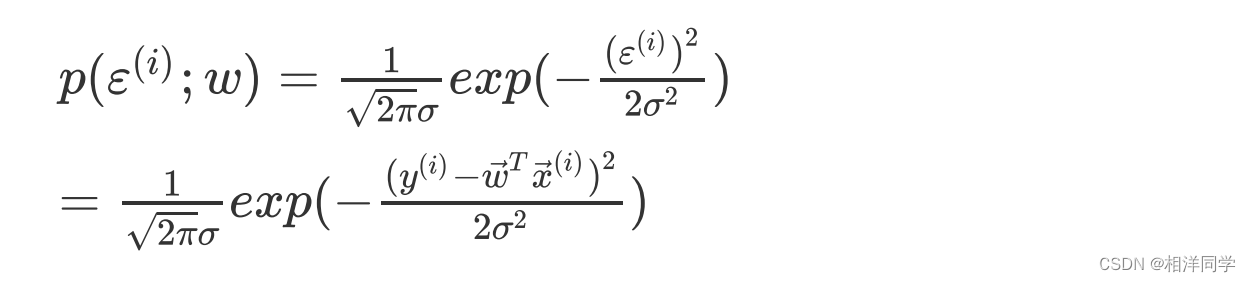
3.2极大似然估计
简单来说极大似然估计是在已知一些观测数据的情况下,我们应该选择使这些观测数据出现概率最大的参数。换句话说,就是在所有可能的参数选择中,找到一个最能“解释”已观察到的数据的参数。
根据该原则,我们让所有误差出现的联合概率最大,这样参数w的值就是我们要求解的值
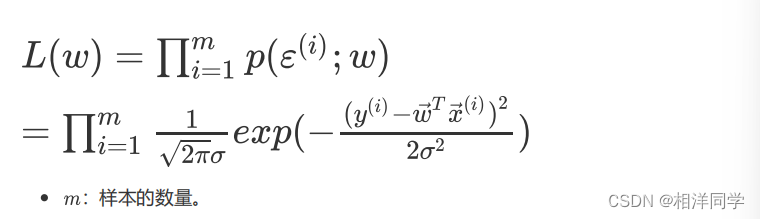
3.3 对数似然函数
不过,累计乘积方式并不利于我们求解,我们这里可以使用对数似然函数,也就是在似然函数上取对数操作,这样就可以将累计乘积的方式转化为累计求和的形式啦
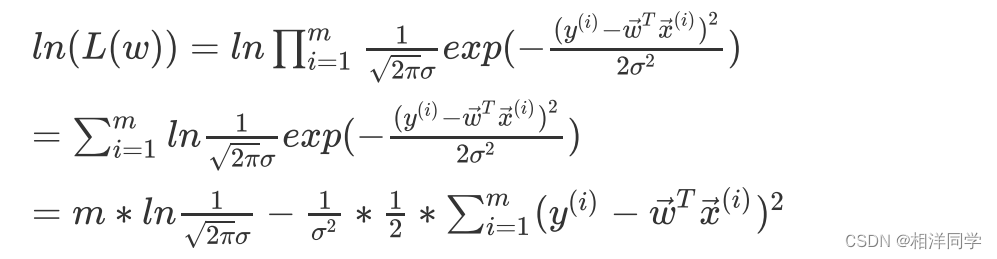
有的同学可能会有疑问
我们原本的目的是要求的令似然函数最大时,参数w的值
然而我们对似然函数取对数时,得到的
似乎会将原似然函数改变
这样我们对似然函数取得的极大值还会与原来的似然函数计算的
相同吗?
我们不妨用程序来验证这一点
x = np.linspace(-3,3,200)
# 原函数
y = 0.5 * x **2 +1
# 对数函数
lny = np.log(y)
plt.plot(x,y,label = '原函数')
plt.plot(x,lny,label = '对数函数')
plt.legend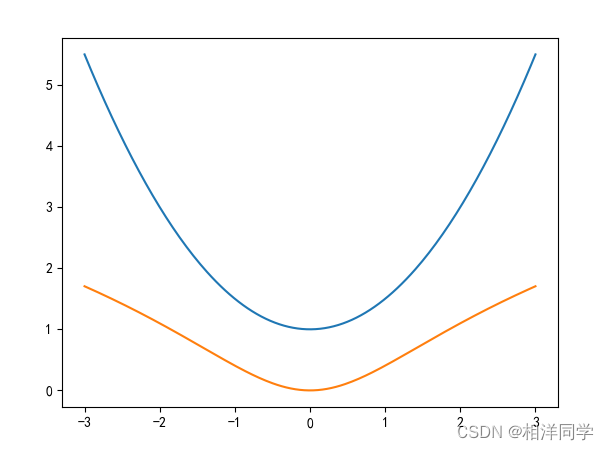
通过观察图像我们发现,加上ln的函数极值点并没有受到影响,所以对我们的参数的求解也不会有影响。
至此,我们通过极大似然参数估计的当时也验证了我们要求的目标和损失函数相同。
3.4 损失函数
在上式中,常数忽略,我们只需让后半部分的值最小即可,因此后半部分:
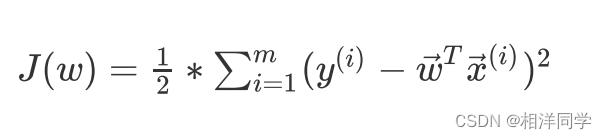
该函数是二次函数,显然具有唯一极小值
3.5损失函数向量化表示

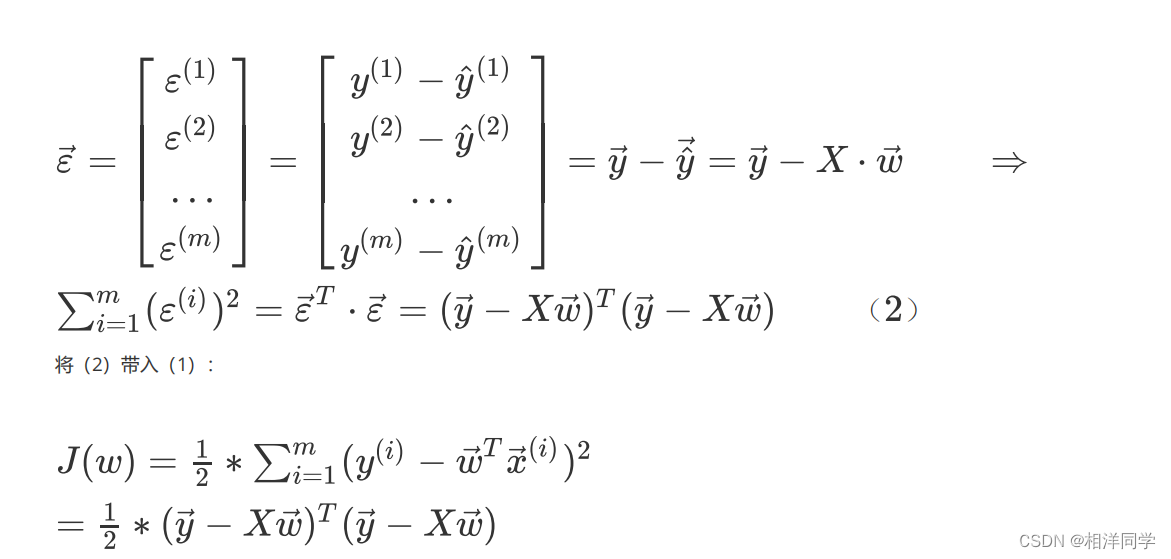
3.6 损失函数求导
我们要求损失函数的最小值,只需要对向量进行求导,令倒数为0,此时的
就是最佳解。
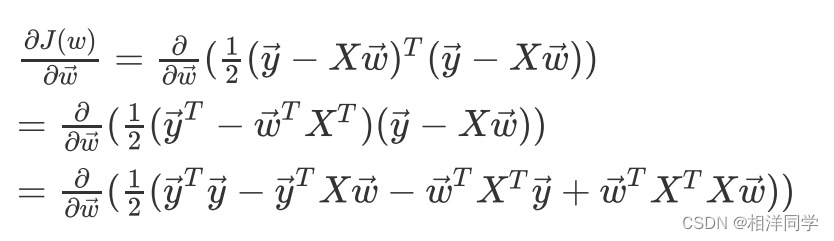
3.7 损失函数化简
根据矩阵与向量的求导公式,有:
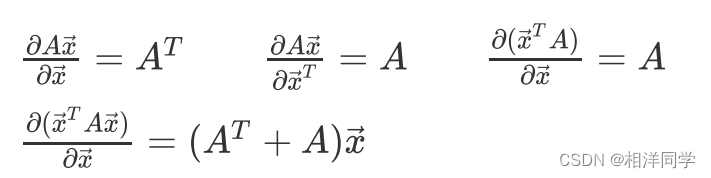 特别的,如果
特别的,如果(A为对称矩阵),则:
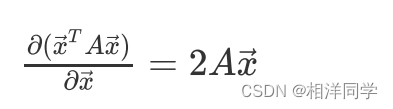
因此:
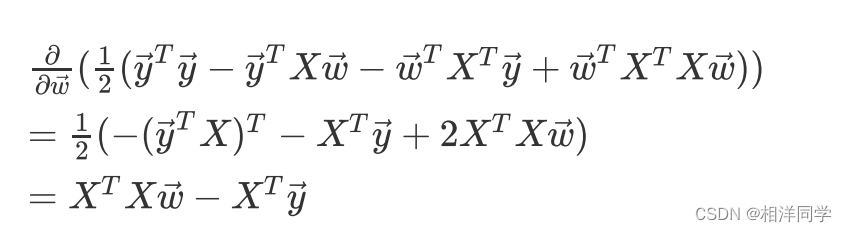 令导函数的值为0,则:
令导函数的值为0,则:
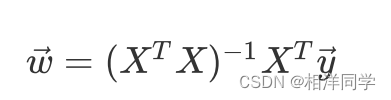
矩阵必须是可逆的
假设X为训练集的特征,y为训练集的目标值
根据以上推导,我们把结果拿来套用就可以很容易的计算得到
代码如下:
# 创建一个元素都为1的矩阵,并与x拼起来,因为需要加上常数w0
one = np.ones(shape = (len(X),1))
X = np.concatenate([one,X],axis=1)
# np.linalg.inv求矩阵的逆
w = np.linalg.inv(X.T.dot(X)).dot(X.T).dot(y)
w4 复现多元线性回归类
下面,我们自己来复现一个能够实现多元线性回归的类(参考sklearn中的LinearRegression)
这个类满足一下条件:
- 具有fit方法,训练模型
- 具有predict方法,预测未知数据
- 具有coef_属性,返回所有权重(不包括偏置
)
- 具有intercept_属性,返回偏置b(
代码如下:
import numpy as np
from matplotlib import pyplot
class LinearRegression:
def __init__(self):
self.w = None
self.coef_ = None
self.intercept_ = None
# fit方法训练模型
def fit(self, X_train, y_train):
'''
:param X_train: 训练数据集
:param y_train: 训练数据集的标签
:return: None
'''
one = np.ones(shape=(len(X_train), 1))
X_train = np.concatenate([one, X_train], axis=1)
# np.linalg.inv求矩阵的逆
w = np.linalg.inv(X_train.T.dot(X_train)).dot(X_train.T).dot(y_train)
self.w = w
self.coef_ = w[1:]
self.intercept_ = w[0]
# predict方法预测
def predict(self, X_test):
'''
:param X_test: 测试数据集
:return: 预测结果
'''
one = np.ones(shape=(len(X_test), 1))
X_test = np.concatenate([one, X_test], axis=1)
y_pred = X_test.dot((self.w).T)
return y_pred
# 生成训练数据
x0 = [1, 2, 3, 4, 5, 6, 7, 8, 9,10]
x1 = [1, 3, 3, 8, 5, 6, 0, 8, 9,8]
X = np.array([[x0[i], x1[i]] for i in range(len(x0))])
y = np.zeros(len(x0))
for i in range(len(x0)):
y[i] = 2 * x0[i] + 3 * x1[i] + 4
X_train = X[:8]
y_train = y[:8]
X_test = X[8:]
y_test = y[8:]
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
print(f'model.coef_:{model.coef_}')
print(f'model.intercept_:{model.intercept_}')
# 模型预测
y_pred = model.predict(X_test)
print(f'y_pred:{y_pred}')输出结果:
model.coef_:[2. 3.]
model.intercept_:3.9999999999999964
y_pred:[49. 48.]可以看到,成功预测!
补充:
如果出现以下报错,代表尝试求逆的矩阵是奇异的(或称为非满秩矩阵)
numpy.linalg.LinAlgError: Singular matrix两种可能
-
数据列线性相关:如果你的数据集中的某些特征是其他特征的线性组合,那么这些列之间的线性相关性会导致矩阵不可逆。
-
重复数据:如果训练数据中有重复的行,这也会导致矩阵奇异。
这个报错是我将两行特征写成一样时出现的错误,实际上在使用机器学习进行实践时,两个线性相关列没有必要同时存在,例如年薪和平均月薪。在未来实践中这是值得注意的
今天的分享就到这里,学习重在总结和坚持,共勉!
















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









