






图像
图像是人类视觉的基础,是自然景物的客观反映,是人类认识世界和人类本身的重要源泉。“图”是物体
反射或透射光的分布,“像“是人的视觉系统所接受的图在人脑中所形版的印象或认识,照片、绘画、剪
贴画、地图、书法作品、手写汉学、传真、卫星云图、影视画面、光片、脑电图、心电图等都是图
像。
一姚敏.数字图像处理:机械工业出版社,2014年。
图像起源于1826年前后法国科学家Joseph Nicephore Niepce.发明的第一张可永久保存的照片,属于模拟
图像。模拟图像又称连续图像,它通过某种物理量(如光、电等)的强弱变化来记录图像亮度信息,所以是
连续变换的。模拟信号的特点是容易受干扰,如今已经基本全面被数字图像替代。
在第一次世界大战后,1921年美国科学家发明了Bartlane System,并从伦敦传到纽约传输了第一幅数字图
像,其亮度用离散数值表示,将图片编码成5个灰度级,如下图所示,通过海底电缆进行传输。在发送端图
片被编码并使用打孔带记录,通过系统传输后在接收方使用特殊的打印机恢复成图像。

下载opencv
进入Anaconda界面
cd srcipts
pip install opencv-contrib-python
1 图像的IO操作
读取图像
使用 cv.imread() 函数读取一张图像,图片应该在工作目录中,或者应该提供完整的图像路径。
第二个参数是一个 flag,指定了应该读取图像的方式
- cv.IMREAD_COLOR:加载彩色图像,任何图像的透明度都会被忽略,它是默认标志
- cv.IMREAD_GRAYSCALE:以灰度模式加载图像
- cv.IMREAD_UNCHANGED:加载图像,包括 alpha 通道
Note
- 你可以简单地分别传递整数 1、0 或-1,而不是这三个 flag。
注意
即使图像路径错误,它也不会抛出任何错误,但是打印 img会给你None
显示图像
用 cv.imshow() 函数在窗口中显示图像,窗口自动适应图像的大小。
第一个参数是窗口名,它是一个字符串,第二个参数就是我们的图像。你可以根据需要创建任意数量的窗口,但是窗口名字要不同。
cv.imshow('image', img)
cv.waitKey(0)
cv.destroyAllWindows()
一个窗口的截图可能看起来像这样 (in Fedora-Gnome machine): 
cv.waitKey() 是一个键盘绑定函数,它的参数是以毫秒为单位的时间。该函数为任意键盘事件等待指定毫秒。如果你在这段时间内按下任意键,程序将继续。如果传的是 0,它会一直等待键盘按下。它也可以设置检测特定的击键,例如,按下键 a 等,我们将在下面讨论。
Note
- 除了绑定键盘事件,该函数还会处理许多其他 GUI 事件,因此你必须用它来实际显示图像。
cv.destroyAllWindows() 简单的销毁我们创建的所有窗口。如果你想销毁任意指定窗口,应该使用函数 cv.destroyWindow() 参数是确切的窗口名。
Note
有一种特殊情况,你可以先创建一个窗口然后加载图像到该窗口。在这种情况下,你能指定窗口是否可调整大小。它是由这个函数完成的 cv.namedWindow()。默认情况下,flag 是 cv.WINDOW_AUTOSIZE。但如果你指定了 flag 为 cv.WINDOW_NORMAL,你能调整窗口大小。当图像尺寸太大,在窗口中添加跟踪条是很有用的。
看下面的代码:
cv.namedWindow('image', cv.WINDOW_NORMAL)
cv.imshow('image',img)
cv.waitKey(0)
cv.destroyAllWindows()
保存图像
保存图像,用这个函数 cv.imwrite()。
第一个参数是文件名,第二个参数是你要保存的图像。
cv.imwrite('messigray.png',img)
将该图像用 PNG 格式保存在工作目录。
总结一下
下面的程序以灰度模式读取图像,显示图像,如果你按下 's‘ 会保存和退出图像,或者按下 ESC 退出不保存。
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg',0)
cv.imshow('image',img)
k = cv.waitKey(0)
if k == 27: # ESC 退出
cv.destroyAllWindows()
elif k == ord('s'): # 's' 保存退出
cv.imwrite('messigray.png',img)
cv.destroyAllWindows()
注意
- 如果你使用的是 64 位机器,你需要修改
k = cv.waitKey(0)像这样:k = cv.waitKey(0) & 0xFF
使用 Matplotlib
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([]) # 隐藏 X 和 Y 轴的刻度值
plt.show()
窗口的屏幕截图是这样的: 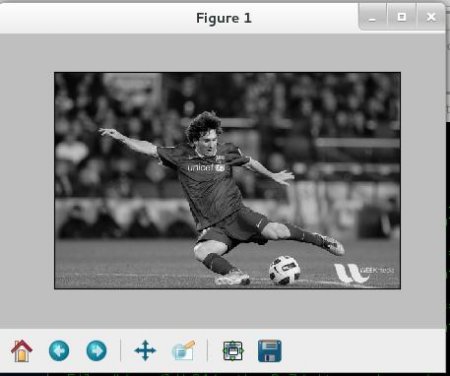
参考
Matplotlib 提供了大量的绘图选项。有关更多详情信息,请参阅 Matplotlib 文档。有一些,我们用这种方式将会知道。
注意
- 彩色图像 OpenCV 用的 BGR 模式,但是 Matplotlib 显示用的 RGB 模式。因此如果图像用 OpenCV 加载,则 Matplotlib 中彩色图像将无法正常显示。想要正常使用,需要用
imshow(img[:,:,::-1])将其翻转为RGB形式 - 要显示灰度图,要用cmap=plt.cm.gray
interpolation = 'bicubic'插值能让图像放大缩小更加光滑plt.xticks([]), plt.yticks([])隐藏 X 和 Y 轴的刻度值
绘图功能
目标
在本次会议中:
- 用 OpenCV 画不同的几何图形
- 你要学习这些函数:cv.line(), **cv.circle()** , cv.rectangle(), cv.ellipse(), cv.putText() 等。
Code
上面的这些函数,你能看到一些相同的参数:
- img:你想画的图片
- color:形状的颜色,如 BGR,它是一个元组,例如:蓝色(255,0,0)。对于灰度图,只需传一个标量值。
- thickness: 线或圆等的厚度。如果传 -1 就是像圆的闭合图形,它将填充形状。_ 默认 thickness = 1_
- lineType:线条类型,如 8 连接,抗锯齿线等。默认情况下,它是 8 连接。cv.LINE_AA 画出抗锯齿线,非常好看的曲线。
创建图像:
img = np.zeros((512,512,3),np.uint8)
待填:
画线
去画一条线,你需要传递线条的开始和结束的坐标。
cv.line(img,start.end.color.thickness)
参数:
- img:图像
- Start,end:直线的起点和终点
- color:线条的颜色
- Thickness:线条宽度
矩形
cv.rectangle(img,lefttupper,rightdown,color,thickness)
- img:要绘制矩形的图像
- Leftupper,.rightdown:矩形的左上角和右下角坐标
- color:线条的颜色
- Thickness:线条宽度
画圆
cv.circle(img,centerpoint,r,color,thickness)
参数:
- img:图像
- Centerpoint,r:圆心和半径
- color:线条的颜色
- thickness:线条宽度,为-1时生成闭合图案(圆形)并填充颜色
画椭圆
画一个椭圆,你需要传好几个参数。一个参数是圆心位置 (x,y)。下个参数是轴的长度 (长轴长度,短轴长度)。角度是椭圆在你逆时针方向的旋转角度。startAngle 和 endAngle 表示从长轴顺时针方向测量的椭圆弧的起点和终点。如整圆就传 0 和 360。更多细节请看 cv.ellipse() 的文档。下面是在这个图像中间画的一个半椭圆例子。
cv.ellipse(img,(256,256),(100,50),0,0,180,255,-1)
画多边形
画多边形,首先你需要顶点的做坐标。将这些点组成一个形状为 ROWSx1x2 的数组,ROWS 是顶点数,它应该是 int32 类型。这里我们绘制一个顶点是黄色的小多边形。
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
pts = pts.reshape((-1,1,2))
cv.polylines(img,[pts],True,(0,255,255))
Note
- 如果地三个是 False,你将获得所有点的折线,而不是一个闭合形状。
- cv.polylines() 能画很多线条。只需创建你想绘制所有线条的列表,然后将其传给这个函数。所有线条都将单独绘制。绘制一组线条比调用 cv.line() 好很多,快很多。
给图像加文字
cv.putText(img,text,station,font,fontsize,color,thickness,cv.LINE_AA)
参数:
- text:你想写的文字数据。
- station:想写的位置坐标 (如 左下角开始)。
- font:字体类型 (支持的字体,查看 cv.putText() 文档)
- fontsize:字体大小
- 常规的如颜色,粗细,线型等。为了更好看,线型使用 lintType = cv.LINE_AA
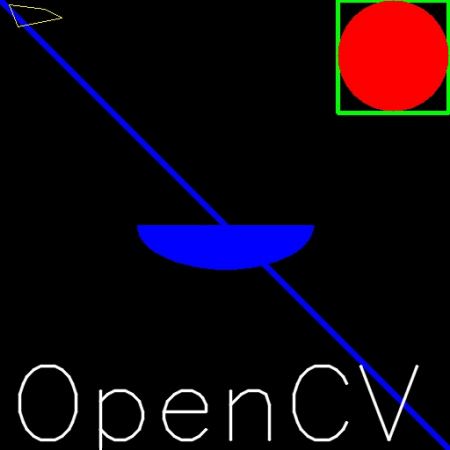
我们将在图像上写一个白色的 OpenCV 。
结果
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 1创建一个空白的图像
img np.zeros((512,512,3),np.uint8)
# 2绘制图形
cv.line(img,(0,0),(511,511),(255,0,0),5)
cv.rectang1e(img,(384,0),(510,128),(0,255,0),3)
cv.circle(img,(447,63),63,(0,0,255),-1)
font cv.FONT_HERSHEY_SIMPLEX
cv.putText(img,'OpenCV',(10,500),font,4,(255,255,255),2,Cv.LINE_AA)
# 3图像展示
plt.imshow(img [,:-1])
plt.title('匹配结果'),plt.xticks([]),plt.yticks([])
plt.show()
图像基础操作
目标
学习:
- 访问像素值并修改它们
- 访问像素属性
- 设置感兴趣区域(ROI)
- 拆分和合并图像
本节中的几乎所有操作都主要与 Numpy 有关而非 OpenCV。熟悉 Numpy 后才能使用 OpenCV 编写更好的优化后代码。
(由于大多数代码都是单行的,所以示例将在 Python 终端中显示)
访问和修改像素值
先来理解图像与一般的矩阵或张量的不同之处(不考虑图像的格式,元数据等信息)。首先,一张图像有自己的属性:宽,高,通道数。其中宽和高是我们肉眼可见的属性,而通道数则是图像能呈现色彩的属性。我们都知道,光学三原色是红色,绿色和蓝色,这三种颜色的混合可以形成任意的颜色。常见的图像的像素通道也是对应的R,G,B三个通道,在OpenCV中,每个通道的取值范围为0~255。(注:还有RGBA,YCrCb,HSV等其他图像通道表示方法)。即,一般彩色图像读进内存之后是一个h * w * c的矩阵,其中h为图像高(相当于矩阵的行),w为图像宽(相当于矩阵列),c为通道数。
下面我们先加载一副彩色图像,更准确地说,是一副黄色图像,如图所示。

黄色为绿色和红色的混合。所以,该图像的所有像素值都应为R=255,G=255,B=0。
import numpy as np
import CV2
img = CV2.imread("img/yellow.jpg")
h,w,c = img.shape
#图像大小为128*128*3
print(h,w,c)
128 128 3
从上面的代码中可以看到,您可以通过行和列坐标访问像素值。注意,对于常见的RGB 图像,OpenCV的imread函数返回的是一个蓝色(Blue)值、绿色(Green)值、红色(Red)值的数组,维度大小为3。而对于灰度图像,仅返回相应的灰度值。
img[100,100]
#OpenCV的读取顺序为B,G,R,由于图像所有像素为黄色,因此,G=255,R=255
array([ 0, 255, 255], dtype=uint8)
# 仅访问蓝色通道的像素
blue = img[100,100,0]
print(blue)
0
你也可以使用同样的方法来修改像素值。
img[100,100] = [255,255,255]
print(img[100,100])
[255 255 255]
警告
Numpy 是一个用于快速阵列计算的优化库。因此,简单地访问每个像素值并修改其值将非常缓慢,并不鼓励这样做。
注意 上述方法通常用于选择数组的某个区域,比如前 5 行和后 3 列。对于单个像素的访问,可以选择使用 Numpy 数组方法中的 array.item()和 array.itemset(),注意它们的返回值是一个标量。如果需要访问所有的 G、R、B 的值,则需要所有像素分别调用 array.item()。
更好的访问和编辑像素的方法:
#访问 红色通道 的值
img.item(10,10,2)
59
#修改 红色通道 的值
img.itemset((10,10,2),100)
img.item(10,10,2)
100
访问图像属性
图像属性包括行数,列数和通道数,图像数据类型,像素数等。
图像的形状。它返回一组由图像的行、列和通道组成的元组(如果图像是彩色的):
print(img.shape)
(128,128,3)
注意 如果图像是灰度图像,则返回的元组仅包含行数和列数,因此它是检查加载的图像是灰度图还是彩色图的一种很好的方法。
总像素数:
print(img.size)
562248
图像数据类型:
print(img.dtype)
UINT8
注意 img.dtype 在调试时非常重要,因为 OpenCV-Python 代码中的大量错误由无效的数据类型引起。
图像中的感兴趣区域
有时您将不得不处理某些图像区域。对于图像中的眼部检测,在整个图像上进行第一次面部检测。当获得面部后,我们单独选择面部区域并在其内部搜索眼部而不是搜索整个原始图像。它提高了准确性(因为眼睛总是在脸上:D)和性能(因为我们在一个小区域搜索)。
使用 Numpy 索引再次获得 ROI(感兴趣区域)。在这里,我选择球并将其到图像中的另一个区域:
ball = img[280:340,330:390]
img[273:333,100:160]
查看以下结果:

拆分和合并图像通道
拆分和合并图像通道
b,g,r = CV.spilt(img)# 拆分
img = CV.merge((b,g,r))# 合并
或者使用numpy.array的切片方法
b = img[:,:,0]
假设您要将所有红色像素设置为零,则无需先拆分通道。Numpy 索引更快:
img[:,:,2] = 0
警告
CV.spilt()是一项代价高昂的操作(就时间而言)。所以只在你需要时再这样做,否则使用 Numpy 索引。
制作图像边界(填充)
如果要在图像周围创建边框,比如相框,可以使用 CV.copyMakeBorder()。但它有更多卷积运算,零填充等应用。该函数采用以下参数:
-
src-输入的图像
-
top,bottom,left,right-上下左右四个方向上的边界拓宽的值
-
borderType-定义要添加的边框类型的标志。它可以是以下类型:
- CV.BORDER_CONSTANT- 添加一个恒定的彩色边框。该值应作为下一个参数value给出。
- CV.BORDER_REFLECT-边框将是边框元素的镜像反射,如下所示:fedcba|abcdefgh|hgfedcb
- CV.BORDER_REFLECT_101或者 CV.BORDER_DEFAULT-与上面相同,但略有改动,如下所示: gfedcb | abcdefgh | gfedcba
- CV.BORDER_REPLICATE -最后一个元素被,如下所示: aaaaaa | abcdefgh | hhhhhhh
- CV.BORDER_WRAP-不好解释,它看起来像这样: cdefgh | abcdefgh | abcdefg
-
value- 如果边框类型为CV.BORDER_CONSTANT,则这个值即为要设置的边框颜色
色彩空间的改变
OpenCV中有150多种颜色空间转换方法。最广泛使用的转换方法有两种,BGR→Gray和BGR←→HSV。
cv.cvtColor(input_image,flag)
参数:
- input_image:进行颜色空间转换的图像
- flag:转换类型
- cV.COLOR_BGR2GRAY BGR+Gray
- CV.COLOR_BGR2HSV:BGR-HSV
总结
1.图像IO操作的API:
- cv.imread():读取图像
- cv.imshow():显示图像
- cv.imwrite():保存图像
2.在图像上绘制几何图像
- cv.line():绘制直线
- cv.circle():绘制圆
- cv.rectangle():绘制矩形
- cv.putText():在图像上添加文字
3.直接使用行列索引获取图像中的像素并进行修改
img[200,200] = (255,255,255)
4.图像的属性
形状:img.shape
图像大小:img.size
数据类型:img.dtype
5.拆分通道: cv.split()
通道合并:cv.merge()
6.色彩空间的改变:
cv.cvtColor(input_image,flag)
图像的算术运算
图像加法
您可以通过 OpenCV 函数,cv.add()或简单地通过 numpy 操作将两个图像相加,res = img1 + img2。两个图像应该具有相同的深度和类型,或者第二个图像可以是像素值,比如(255,255,255),白色值。
注意 OpenCV 相加操作和 Numpy 相加操作之间存在差异。OpenCV 添加是饱和操作,而 Numpy 添加是模运算。要注意的是,两种加法对于结果溢出的数据,会通过某种方法使其在限定的数据范围内。
参考:
x = np.uint8([250])
y = np.uint8([10])
print(cv.add(x,y)) #250 + 10 =260 => 255
[[255]]
print(x + y)
[4]
在将两个图象相加时会发现 OpenCV 函数能够提供更好的结果,所以尽可能地选择 OpenCV 函数。
注意:
-
numpy加法会使得两图像灰度值取模,比如250+10=260 =>260 % 255 == 4
-
两个图片大小必须相同,可以使用resize将大小改成相同。
图像混合
这也是将图像相加,但是对图像赋予不同的权重,从而给出混合感或透明感。图像按以下等式添加:
g
(
x
)
=
(
z
−
a
)
f
0
(
x
)
+
a
f
1
(
x
)
g(x)=(z-a)f0(x)+af1(x)
g(x)=(z−a)f0(x)+af1(x)
通过在(0,1)之间改变(0 -> 1)的值, 可以用来对两幅图像或两段视频产生时间上的 画面叠化 (cross-dissolve)效果,就像在幻灯片放映和电影制作中那样
在这里,我拍了两张图片将它们混合在一起。第一图像的权重为 0.7,第二图像的权重为 0.3。cv.addWeighted()在图像上应用以下等式。
img1= cv.imread('ml.png')
img2= cv.imread('opencv-logo.png')
dst = cv.addWeighted(img1,0.7,img2,0.3,0)
cv.imshow('dst',dst)
cv.waitKey(0)
cv.destroyAllWindows()
观察以下结果:

注意:
- 两个图片大小必须相同,可以使用resize将大小改成相同。
按位操作
这包括按位 AND,OR,NOT 和 XOR 运算。它们在提取图像的某一部分(我们将在后面的章节中看到)、定义和使用非矩形 ROI 等方面非常有用。下面我们将看到如何更改图像的特定区域的示例:
假如我想加一个OpenCV的 logo在一个图像上,如果只是简单的将两张图像想加,则会改变叠加处的颜色。如果进行上面所说的混叠操作,则会得到一个有透明效应的结果,但我希望得到一个不透明的logo。如果logo是一个矩形logo,那可以用上节所讲的ROI来做。但是OpenCV的logo是不规则形状的,所以用下面的bitwise操作来进行。
#加载两张图片
img1 = cv.imread('messi5.jpg')
img2 = cv.imread('opencv-logo-white.png')
#我想在左上角放置一个logo,所以我创建了一个 ROI,并且这个ROI的宽和高为我想放置的logo的宽和高
rows,cols,channels = img2.shape
roi = img1 [0:rows,0:cols]
#现在创建一个logo的掩码,通过对logo图像进行阈值,并对阈值结果并创建其反转掩码
img2gray = cv.cvtColor(img2,cv.COLOR_BGR2GRAY)
ret,mask = cv.threshold(img2gray,10,255,cv.THRESH_BINARY)
mask_inv = cv.bitwise_not(mask)
#现在使 ROI 中的徽标区域变黑
img1_bg = cv.bitwise_and(roi,roi,mask = mask_inv)
#仅从徽标图像中获取徽标区域。
img2_fg = cv.bitwise_and(img2,img2,mask = mask)
#在 ROI 中放置徽标并修改主图像
dst = cv.add(img1_bg,img2_fg)
img1 [0:rows,0:cols] = dst
cv.imshow('res',img1)
cv.waitKey(0)
cv.destroyAllWindows()
请参阅下面的结果。左图显示了我们创建的蒙版。右图显示最终结果。为了加深理解,请在上面的代码中显示所有中间图像,尤其是 img1_bg 和 img2_fg。
图像处理
几何变换
变换
OpenCV 提供了两个转换函数,cv.warpAffine 和 cv.warpPerspective,可以进行各种转换。 cv.warpAffine 采用 2x3 变换矩阵,而 cv.warpPerspective 采用 3x3 变换矩阵作为输入。
缩放
缩放是调整图片的大小。
API
cv2.resize(src,dsize,fx=0,fy=0,interpolation=cv2.INTER_LINEAR)
参数:
- src: 输入图像
- dsize: 绝对尺寸,直接指定调整后图像的大小
- fx,fy: 相对尺寸,将dsize设置为None,然后将fx和fy设置为比例因子即可
- interpolation: 插值方法,
插值方法:Cv2.INTER LINEAR
双线性插值法
Cv2.INTER NEAREST
最近邻插值
Cv2.INTER AREA
像素区域重采样(默认)
Cv2.INTER_CUBIC
双三次插值
| 插值 | 含义 |
|---|---|
| Cv2.INTER_LINEAR | 双线性插值法 |
| Cv2.INTER_NEAREST | 最近邻插值 |
| Cv2.INTER_AREA | 像素区域重采样(默认) |
| Cv2.INTER_CUBIC | 双三次插值 |
OpenCV 使用 cv.resize() 函数进行调整。可以手动指定图像的大小,也可以指定比例因子。可以使用不同的插值方法。对于下采样(图像上缩小),最合适的插值方法是 cv.INTER_AREA 对于上采样(放大),最好的方法是 cv.INTER_CUBIC (速度较慢)和 cv.INTER_LINEAR (速度较快)。默认情况下,所使用的插值方法都是 cv.INTER_AREA 。你可以使用如下方法调整输入图片大小:
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg')
res = cv.resize(img,None,fx=2, fy=2, interpolation = cv.INTER_CUBIC)
#OR
height, width = img.shape[:2]
res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
平移变换
API:
cv.warpAffine(img,M,dsize)
参数:
- img:输入图像
- M:2*3移动矩阵
平移变换是物体位置的移动。对于(x,y)处的像素点,要把它移动到(x+tx,y+ty)
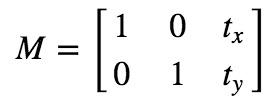
您可以将变换矩阵存为 np.float32 类型的 numpy 数组,并将其作为 cv.warpAffine 的第二个参数。请参见以下转换(100,50)的示例:
import numpy as np
import cv2 as cv
img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv.warpAffine(img,M,(cols,rows))
cv.imshow('img',dst)
cv.waitKey(0)
cv.destroyAllWindows()
注意
cv.warpAffine 函数的第三个参数是输出图像的大小,其形式应为(宽度、高度)。记住宽度=列数,高度=行数。
结果:

在书写矩阵时需要扩展画面的,res2= cv.warpAffine(kids,M,(2*cols,2*rows))
结果为
旋转
图像旋转的方式为:

假设图像逆时针旋转θ,则更具坐标转换可得旋转转换为:

其中:

带入上面的公式中,有:

也可以写成:

同时我们要修正原点的位置,因为原图像中的坐标原点在图像的左上角,经过旋转后图像的大小会有所变化,原点也需要修正。
假设在旋转的时候是以旋转中心为坐标原点的,旋转结束后还需要将坐标原点移到图像左上角,也就是还要进行一次变换。


存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
API:
cv2.getRotationMatrix2D(center,angle,scale)
参数:
- center:旋转中心
- angle:旋转角度
- scale:缩放比例
返回:- M:旋转矩阵
调用cv.warpAffine:完成图像的旋转
- M:旋转矩阵
请查看下面的示例,它将图像相对于中心旋转 90 度,而不进行任何缩放。
img = cv.imread('messi5.jpg',0)
rows,cols = img.shape
# cols-1 and rows-1 are the coordinate limits.
M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)
dst = cv.warpAffine(img,M,(cols,rows))
结果:

仿射变换
在仿射变换中,原始图像中的所有平行线在输出图像中仍然是平行的。为了找到变换矩阵,我们需要从输入图像中取三个点及其在输出图像中的对应位置。然后 cv.getAffineTransform 将创建一个 2x3 矩阵,该矩阵将传递给 cv.warpAffine 。
查看下面的示例,并注意我选择的点(用绿色标记):
img = cv.imread('drawing.png')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
dst = cv.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
结果:
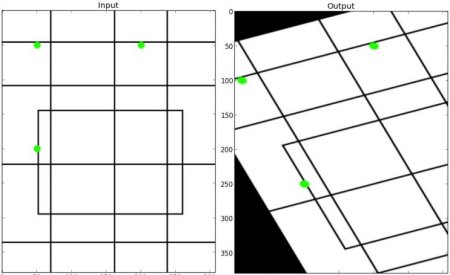
透视变换
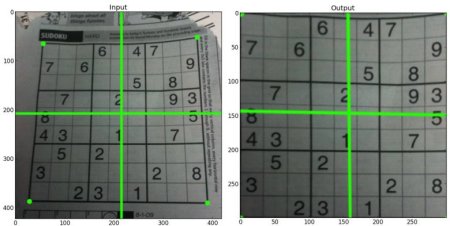
对透视转换,你需要一个 3x3 变换矩阵。即使在转换之后,直线也将保持直线。要找到这个变换矩阵,需要输入图像上的 4 个点和输出图像上的相应点。在这四点中,任意三点不应该共线。然后通过 cv.getPerspectiveTransform 找到变换矩阵。然后对这个 3x3 变换矩阵使用 cv.warpPerspective。
请看代码:
img = cv.imread('sudoku.png')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv.getPerspectiveTransform(pts1,pts2)
dst = cv.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
结果:















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









