






目录
前言
随着人工智能的发展,作为人工智能中的一个基础且重要的分支——机器学习也是愈发吸引大家来了解以及学习,那么在学习机器学习前,我们需要先来了解一下什么是机器学习,以及机器学习中涉及了哪些内容。
一、机器学习是什么?
机器学习(Machine Learning,ML) 是人工智能(AI)领域的一个分支,致力于通过让计算机系统从数据中自动学习,并根据学到的知识做出决策、预测或发现模式。与传统编程不同,在机器学习中,计算机不需要依赖显式编写的程序指令,而是通过从数据中获取经验,不断改进其行为。
换种说法,我们人类在经过一些事情以及做一些事情后会总结规律以及经验,以后遇到类似的事情可以用相关经验或者规律来解决事情以及问题;机器学习也类似,我们让计算机系统“学习”从数据中提取规律,并使用这些规律来解决问题。它不依赖于传统的手工编程过程,而是通过“训练”算法使计算机自己学习如何做出决策或预测。
二、机器学习的基本类型
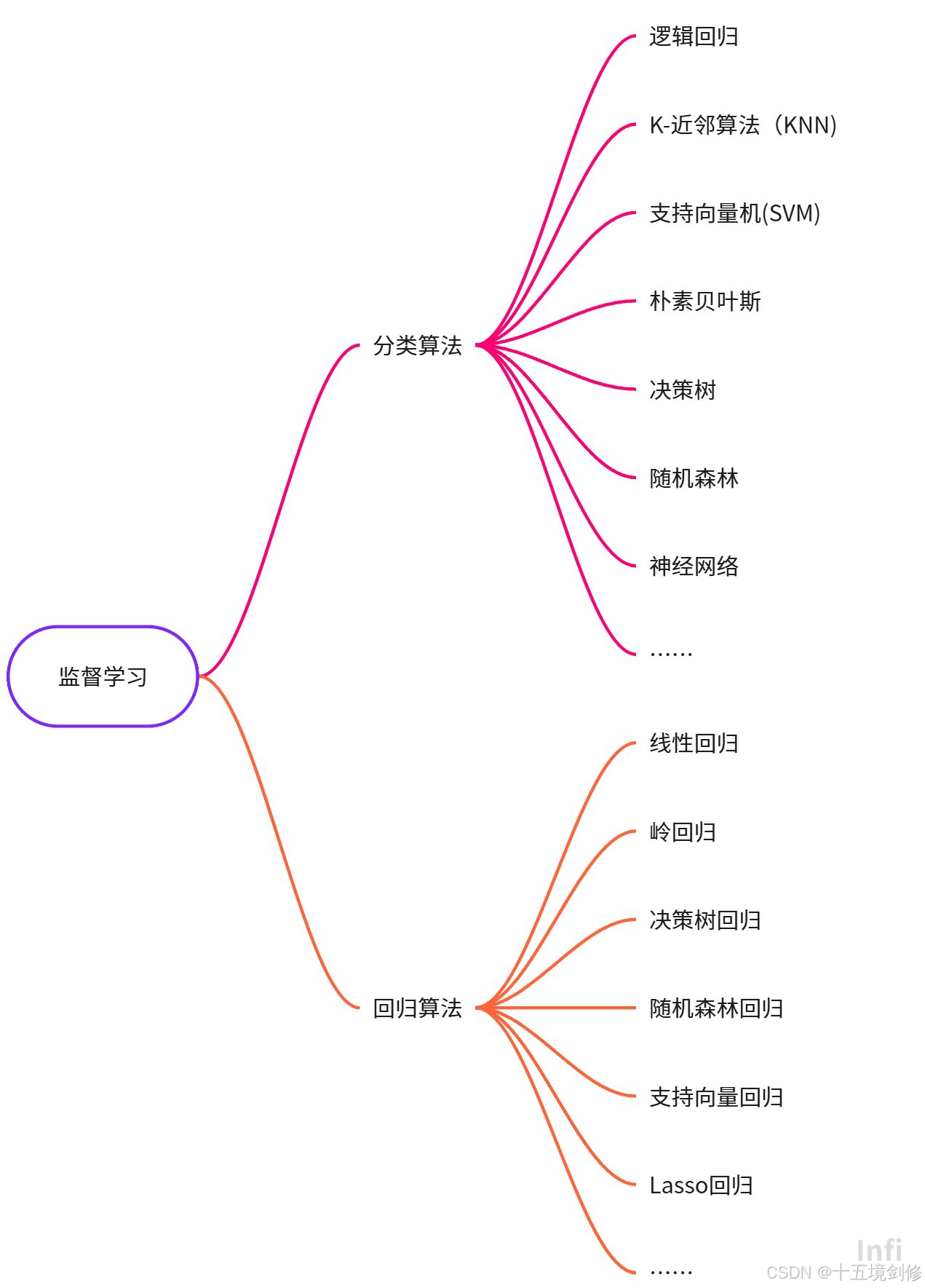
1.监督学习
数据集包含输入(特征)以及对应的标签(也就是目标值),监督学习的目标就是通过学习输入和输出之间的映射关系,来预测新的输入数据的输出值。
它的特点是使用标注数据集(每个输入样本都有对应的输出标签)来训练模型。通过学习输入数据和输出标签之间的关系,模型能够做出对新数据的预测。
特点:
-
输入数据是有标签的,每个训练样本都对应一个目标值(标签)。
-
目标是通过输入数据和输出标签的关系来进行学习,使模型能够对新的数据进行预测。
应用场景:
-
分类问题:例如垃圾邮件分类(判断一封邮件是否是垃圾邮件),图像分类(识别图像中的对象)。
-
回归问题:例如预测房价、预测股市价格、温度预测等。
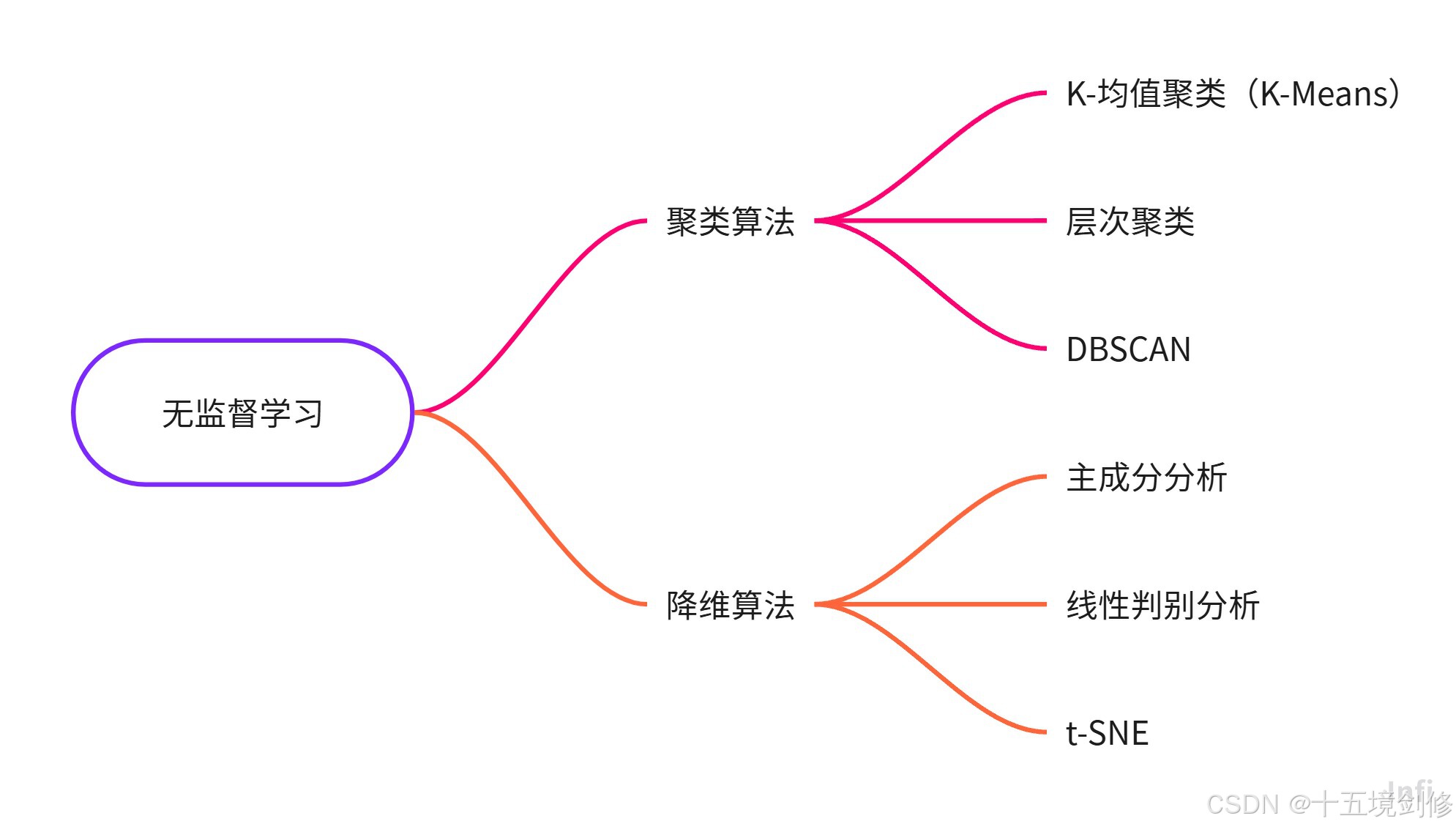
2.无监督学习
无监督学习的目标是从没有标签的数据中发现潜在的结构、规律或模式。与监督学习不同,无监督学习中的数据没有目标标签,模型只能依赖数据的特征来进行学习。
特点:
-
输入数据没有标签,目标是通过分析数据的内部结构或关系来发现数据中的模式或规律。
-
任务通常是对数据进行聚类或降维等操作。
应用场景:
-
聚类问题:例如市场细分(将消费者分为不同的群体),客户行为分析。
-
降维问题:例如特征压缩、数据可视化,将高维数据映射到低维空间。
3.半监督学习
半监督学习介于监督学习和无监督学习之间,使用的数据集包含少量的标注数据和大量的未标注数据。由于标注数据的获取通常代价较高,半监督学习通过利用未标注数据来提高模型性能,尤其是在标注数据稀缺的情况下。
特点:
-
数据集包含少量标注数据和大量未标注数据。
-
模型在标注数据和未标注数据的帮助下进行训练,通常能比完全无监督学习得到更好的效果。
应用场景:
-
图像分类、文本分类等任务,特别是在标签获取困难或成本较高的领域。
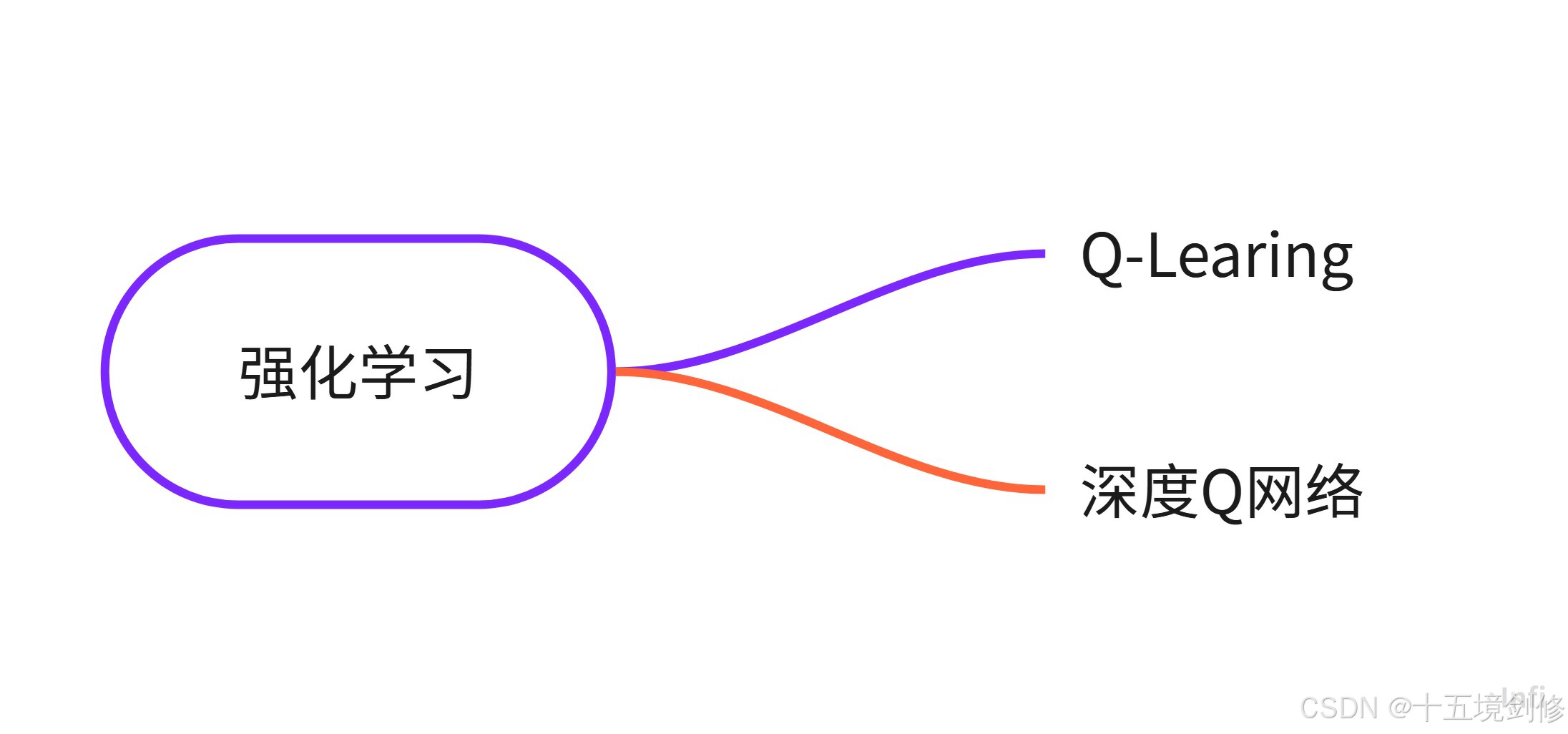
4. 强化学习
这里的强化学习了解即可,初学者接触很少很少。
强化学习与监督学习和无监督学习不同,它并不依赖于静态数据集,而是通过智能体与环境的交互来学习。智能体通过不断试探,采取不同的动作,并根据环境给予的奖励或惩罚来调整自己的行为策略,以实现最大化长期奖励的目标。
特点:
-
学习过程是通过与环境的互动进行的,智能体通过动作改变环境状态,获得反馈(奖励或惩罚)。
-
强化学习的目标是寻找一个最优策略,以便在未来的任务中做出最优决策。
应用场景:
-
游戏:例如AlphaGo、Dota 2中的AI,智能体通过不断尝试和优化策略来打败人类玩家。
-
自动驾驶:自动驾驶汽车通过与环境的交互(如路况、交通信号等)来学习如何开车。
-
机器人控制:机器人通过强化学习来完成任务,如物体抓取、路径规划等。
三、机器学习的工作流程
这里只提一下大致流程,想要了解详细流程的,大伙可以网上查找,挺多资料的。
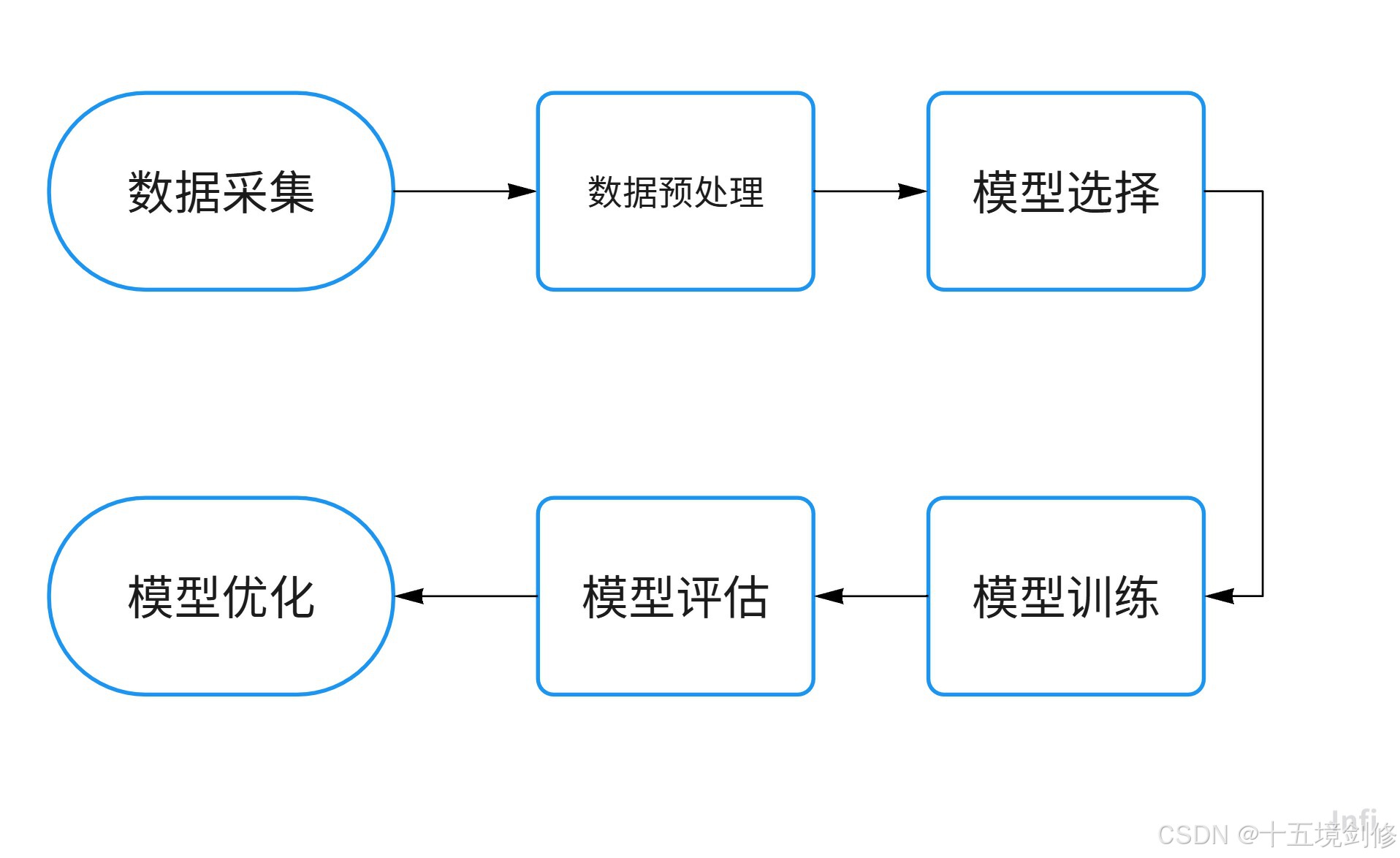
四、常见的机器学习算法
这里只列举常见的一些算法,有兴趣的伙计可以去搜索更深入的
五、机器学习的评价指标
机器学习的评价指标是用于评估模型的性能,选择合适的指标对于不同任务至关重要;就像有时候解决同一个方法可以用很多种方法,用最适合的一种能更好地解决问题。
在机器学习中,评价模型的性能是一个重要的步骤,常用的评估指标包括:
-
回归问题:
-
均方误差(MSE):
-
R²评分(决定系数):
-
-
分类问题:
-
精度
-
精确率
-
召回率
-
F1分数
-
六、机器学习中的过拟合与欠拟合
这里只简单说一下机器学习中模型会出现的两种问题以及他的表现。
-
过拟合:模型过于复杂,完美地拟合了训练数据,但对新数据的泛化能力差。
-
欠拟合:模型过于简单,无法捕捉数据中的复杂模式,导致训练误差和测试误差都较高。
七、机器学习的应用
机器学习在各个领域都有广泛应用,它的应用主要集中在自动化、预测、优化和智能化等领域,包括但不限于:
-
自然语言处理(NLP):如文本分类、情感分析、机器翻译等。
-
计算机视觉:如人脸识别、目标检测、图像分类等。
-
金融领域:如信用评分、股票预测、欺诈检测等。
-
推荐系统:如个性化推荐、广告推荐等。
-
医疗健康:如疾病预测、医学影像分析等。
-
自动驾驶:利用强化学习进行路径规划和决策。
八、学习机器学习的资源
网上关于机器学习的资料非常丰富,感兴趣的伙计可以多去搜索查找,我后面也会是不是更新一下关于机器学习的内容(纯纯做记录,个人的一些理解,如果出现与各位大佬不一样的理解或者我有错误的地方,欢迎探讨和指正!)
下面是推荐的一些机器学习资源:
github上一位大佬总结的:

















 3740
3740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









