






Multimodal Transformer for Unaligned Multimodal Language Sequences
Tsai Y H H, Bai S, Liang P P, et al. Multimodal transformer for unaligned multimodal language sequences[C]//Proceedings of the conference. Association for Computational Linguistics. Meeting. NIH Public Access, 2019, 2019: 6558.
解决问题:
1.不同模态序列的可变采样率而导致的固有数据不对齐(对齐问题)
2.跨模态元素之间的长期依赖关系。(如图所示,传统的多模态融合利用的是Word-level alignment,而本文采用Crossmodel attention来捕获长距离依赖关系。)

一.背景
如图1所示,人类语言通常是多模态的,包括视觉,语音以及文本三个模态,而每个模态又包含很多不同信息,比如文本模态包括基本的语言符号、句法和语言动作等, 语音模态包括语音、语调以及声音表达等,视觉模态包括姿态特征、身体语言、眼神以及面部表达等信息 。
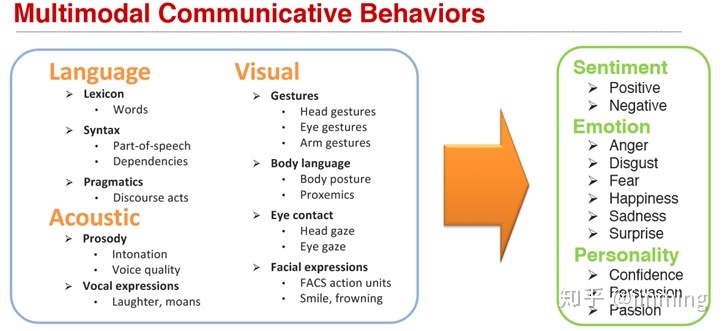
多个模态信息之间是相互补充的,同时多个模态的信息之间也存在冗余,图中的例子做出了很好的说明。

二.模型描述
本文要构建多个模态间的交互信息,而时间序列长度又不同,采用Crosss-modal Transformer的结构来构建不同模态之间的关系,下图为模型总览图。

其中L(language),V(video),A(audio),首先将上述三类特征输入的卷积层,提取不同模态的特征,然后通过Crosss-modal Transformer提高跨潜在模态适应性(we hypothesize a good way to fuse crossmodal information is providing a latent adaptation across modalities)。每一个Crosss-modal Transformer的block的输入都是两个模态,其过程如下图所示:

由模态Y适应X时,把X的特征通过LN扩展为Q,Y为K和V,该操作类似于传统的Transformer,但把输入换掉,这里在特征输入前还引入了位置信息得到Z(常规操作不是重点。)

最后把三个 Crosss-modal Transformer的结果输入常规Transformer后concat,然后softmax出结果。
本文重点在多模态特征融合上,实验部分做的做的很好,可以阅读原文。
最后只能说Transformer YYDS!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!














 947
947











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









