






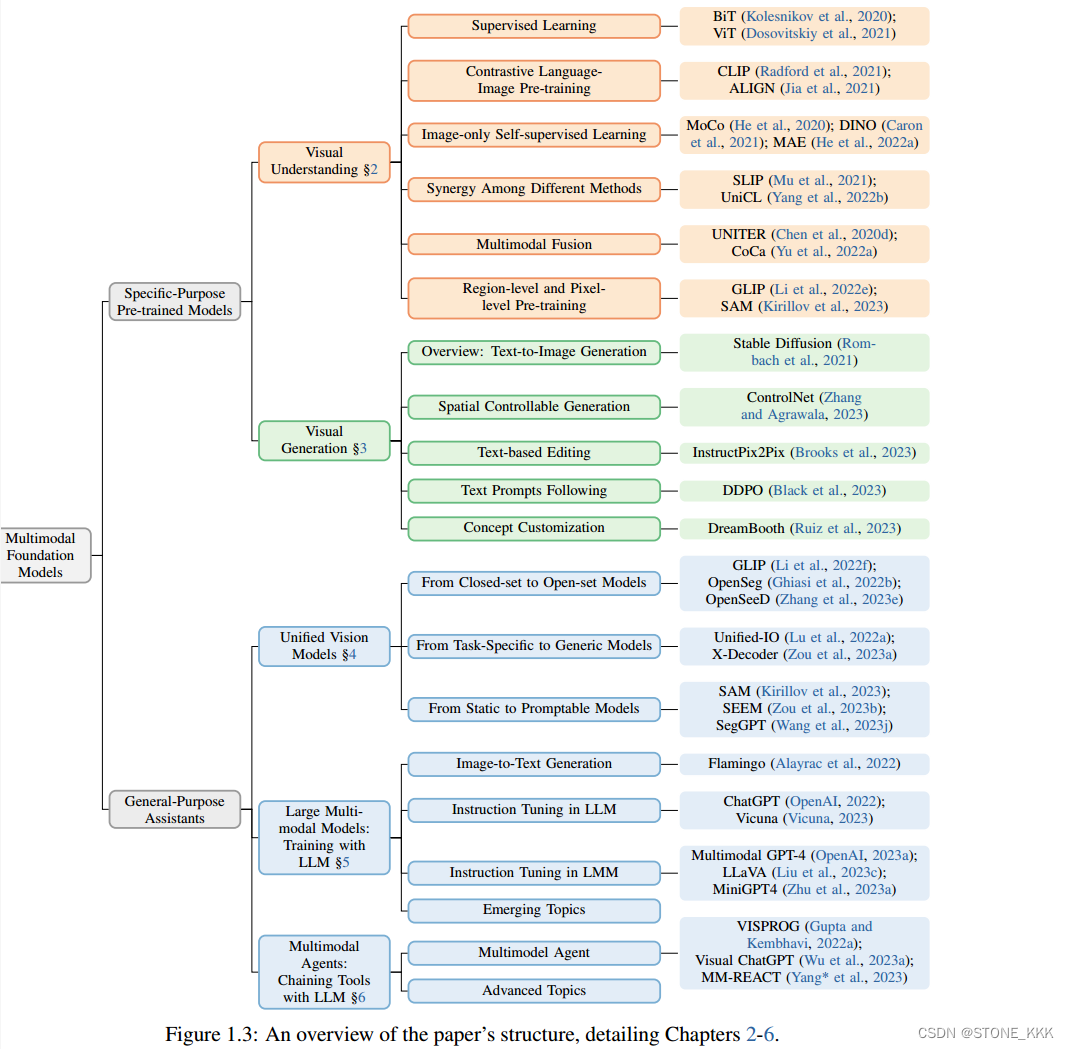
Multimodal Foundation Models:From Specialists to General-Purpose Assistants

1.介绍展示视觉,视觉语言能力的多模态基础模型分类和进化的全面调查
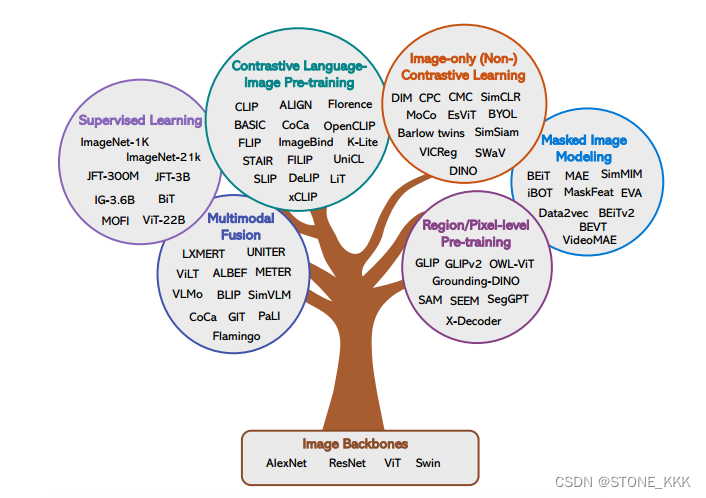
2,5个核心主题两个大类
a.为特定目的预先训练的多模态基础模型,包括两个主题——用于视觉理解的学习视觉主干方法和文本到图像的生成
b.然后,我们介绍了探索性开放研究领域的最新进展
Introduction
(i)在最初几年,针对个别数据集和任务开发特定任务模型,通常从头开始训练。
(ii)通过大规模预训练,语言模型在许多已建立的语言理解和生成任务上实现了最先进的性能,例如BERT ,RoBERTa ,T5,DeBERTa,GPT
rencent papper
1.图像理解模型
2.图像生成模型
3.视觉语言预训练模型,现有的VLP调查论文涵盖了在预训练、图像文本任务、核心视觉任务和/或视频文本任务时代之前针对特定任务VL问题的VLP方法
引言结尾文章贡献
1.对多模态模型进行全面综合的调查包括视觉表达学习和图像生成的成熟模型,
2.总结过去 受llm启发的新型主题,与大语言模型的训练和链接;
3.对于高级主题进行讨论,展示ptential of developing general-purpose assistants
1.1 Multimodal Foundation Models
基础模型:clip、dall-e在广泛的数据集上训练,可以适应广泛的下游任务,这些模型称为基础模型。

视觉理解任务、视觉生成任务、语言理解和生成通用的接口
跨模态的方法同质化和新能力的出现,从技术角度来看,是迁移学习使基础模型成为可能
跨模态方法同质化:跨模态融合的方法技术相似或相同
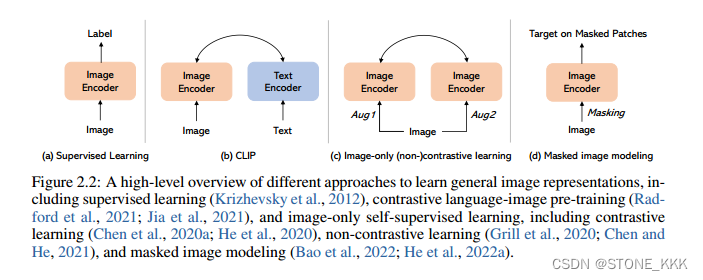
基础大模型clip、dall-e出现的原因主要是nlp领域bert等大模型泛化性很好,因此 迅速激发了cv社区对于自监督学习的兴趣,从而产生了simclr,moco,beit等模型。同一时期,预训练模型成功的将视觉语言模型提高了一个高度。
自监督学习:是无监督学习的一种,利用数据的辅助任务,来生成监督信号,
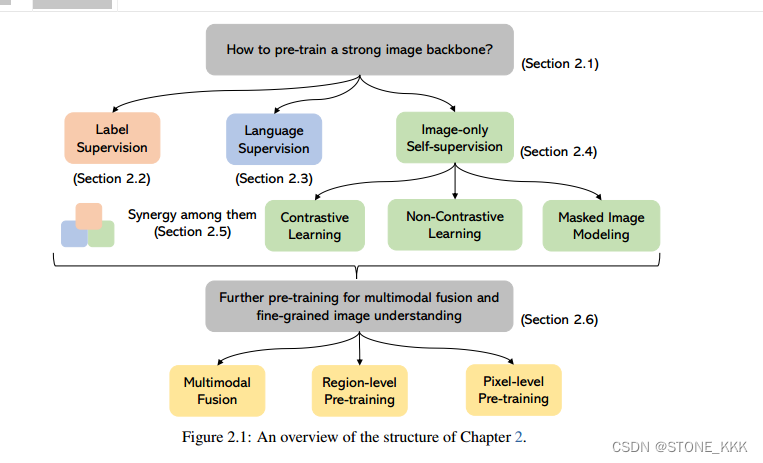
视觉理解模型
强大的视觉骨干是所有类型的计算机视觉下游任务的基础。
下游任务图像级:图像分类,检索,字幕
下游任务区域级:检测和grounding
下游任务像素级:分割
不同任务的分类
仅图像自监督:从图像本身挖掘出的监督信号,包含对比学习,非对比学习,掩码图片的模型
多模态融合,区域级或像素级的预训练:
Character2
2.2关于数据集
关于数据集如下
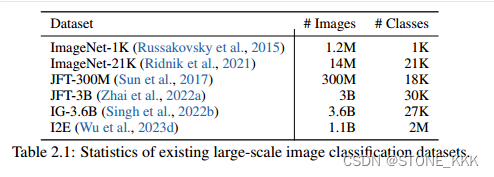
CLIP论文中提到的数据集
MS-COCO
Visual Genome
YFCC100M
WIT(WebImage Text)
前两个数据集质量非常高但是他的数据量非常少,仅有10万YFCC100M 数量大1亿 但是标注质量非常差,有人对其进行清晰了一下,但是一下子就缩水了6倍,直接到1500万张照片了。就和IMagenet了。
CLIP工作作者自己制作了一个四个亿的数据集
2.3对比语言图片预训练 Contrastive Language-Image Pre-training
2.3.1CLIP介绍
2.3.2CLIP变体(CLIP Variants)
相关图片文本对数据集百万级数据集
CC3M
CC12M
SBU
WIT
大规模图片文本数据集公开
Shutterstock
LAION-400M
COYO-700M
LAION2B 此数据集被用来研究CLIP训练的可重复缩放规律
CLIP具有代表性的作品
关于模型方面
1.FLIP也就说在图片编码阶段提出通过掩码来缩放CLIP训练,也就是说将图片打不同的patch然后随机遮掩一些patch即可提高训练效率。其次过滤掉img中包含文本区域的样本可以提高训练效率和模型鲁棒性
2.K-Lite也就说在语言编码器,提出将实体的WIki定义形式的外部知识和原始的alt-text一起进行对比训练。从经验上看,使用丰富的文本描述,可以提高CLIP性能
????????
1.外部只是WIKI定义?
2.alt-text?
3.STAIR提出将文本和图片映射到高维,稀疏的嵌入空间,目的是提高图片文本嵌入空间的可解释性,其中稀疏嵌入中的每个维度是大写字典中的一token。
图像通常是一个高维连续的特征向量
4.对比学习非常普遍,可以超越图片文本模式,ImageBind提出将六种模态的编码融合到一个公共嵌入空间中,包括图像,文本,声音,深度,热模式,imu模式。实践是使用clip的预训练模型,训练期间冻结,表明其他模态编码器被学习到与LCIP嵌入空间对其,以便模型可以应用于新的应用,如音频到图像生成 的多模态大语言模型
关于对比学习目标函数方面
单独使用对比损失是强大的,特别是当模型按比例放大时。然而,其他目标函数也可以应用。
1.Fine-grained supervision(细粒度监督):替代dot-product来计算图片文本对的相似性,这种细粒度的监督可以通过学习单词-patch对齐变得更细的粒度。代表FILIP
2.Contrastive captioner对比字幕,除了对比学习分支,CoCa使用生成损失来提高性能,这类似于许多基于融合编码器的视觉语言模型,如ALBEF ,但关键的区别在于,CoCa旨在从头开始学习更好的图像编码器。关于多模态融合的详细讨论见第2.6.1节。
3.单独使用字幕损失:如何单独使用字幕损失来预训练图像编码器?实际上,在CLIP发明之前,VirTex和ICMLM 使用单个图像字幕损失来学习编码器,但规模很小(仅限于COCO图像),性能较差。CLIP还表明,对比预训练是一个更好的选择。在SimVLM 中,作者发现学习图像编码器的竞争力不如CLIP。然而,在最近的研究Cap/CapPa 中,作者认为图像字幕也是可扩展的视觉学习者。字幕可以显示相同甚至更好的缩放行为。
4.图像预训练的Sigmoid损失:
使用简单的sigmoid损失也可以zero-shot图片分类结果
2.4纯图片自监督学习
非对比学习
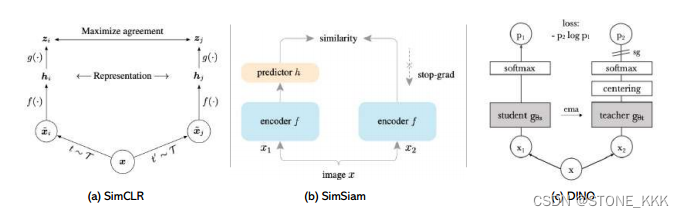
如图2.7(b)所示,在SimSiam (Chen和He, 2021)中,单个图像的两个增强视图由相同的编码器网络处理。随后,在一个视图上应用预测MLP,而在另一个视图上使用停止梯度操作。该模型的主要目标是最大化两个视图之间的相似性。值得注意的是,SimSiam既不依赖负对,也不依赖动量编码器。
DINO :
输入x图片进入两个结构完全相同,但是参数完全不同的网络(stu,teacher)
teacher的输出需要计算batch的平均值,
两个网络输出的特征向量通过temperature toftmax应用到特征维度。特征的相似性使用交叉熵损失来衡量
梯度只通过stu网络传播,教师网络不进行梯度回传,stu网络参数移动的均值来更新教师网络。
2.4.2掩码的图片模型MIM
BEiT :也就是说模仿BERT提出对图片进行掩码来预训练image transformer
Image tokenizer:对掩码的图片进行标记,目的是这些标记可以像一组二外的语言标记一样被处理。
图片标记的学习方法VQ-VAE、VQ-VAE-2、VQ-GAN、Vit-VQGAN
Mask-then-predict:
模型接受损坏的输入图像通过随机屏蔽图像补丁,然后预测被屏蔽内容的目标,正如iBOT说讨论这个训练过程可以理解为图像标记器(作为老师)和BEiT编码器(作为学生)之间的知识蒸馏,而学生只看到部分图像。
2.5不同方法之间的协同作用
clip结合有标签的监督















 4601
4601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









