







前言
在软件开发中,错误码是一种重要的信息传递方式,对于开发者和用户都具有重要的意义。一般情况下,系统出现故障,由运维在狂轰滥炸的报警信息中找到关键错误信息和研发人员进行沟通,再查看代码逻辑理清问题根源,最后解决问题,在定位错误过程中不仅效率低,沟通成本也高。
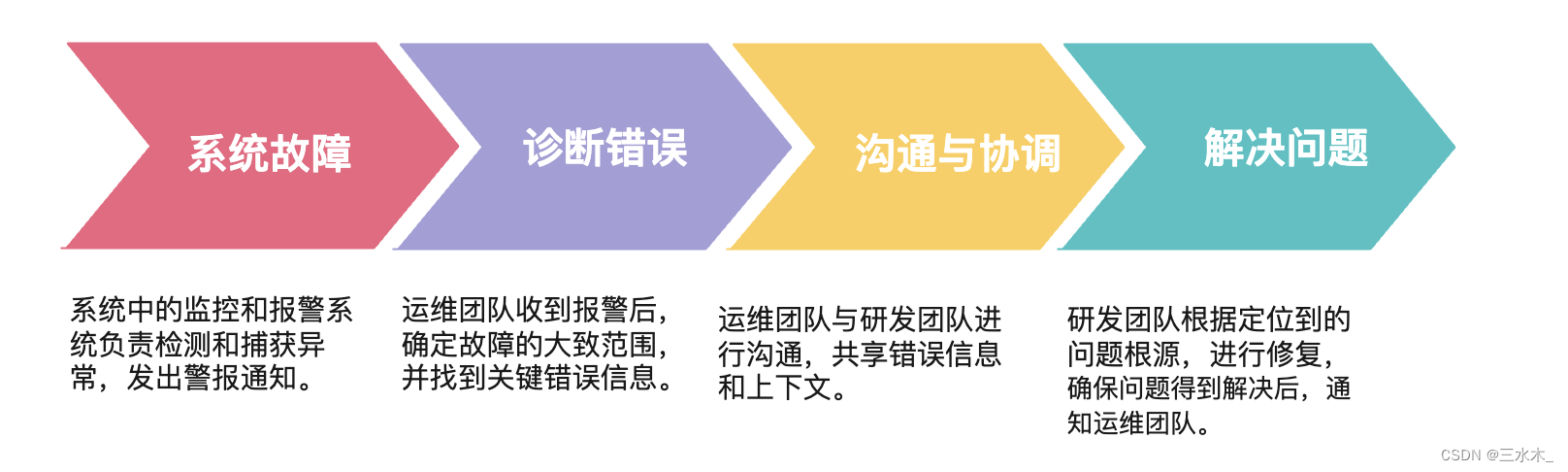
由此可见,良好的错误处理实践是非常重要的,重要性有以下几点:
- 稳定与可靠性:良好的错误处理能够使程序更加稳定,防止未处理的错误导致程序崩溃。
- 可维护性:易于理解和维护的错误处理代码可以减少 bug 的产生,提高代码的可读性。
- 用户体验:通过合适的错误信息反馈给用户,可以提升用户体验。
- 监控与调试:规范的错误处理有助于系统的监控和调试,帮助开发者快速定位并解决问题。
接下来,让我们一起看看 go 语言中的错误码处理实践到底是怎么样的。
错误处理
在 Go 语言中,错误处理与传统的 try/catch 方法有所不同。Go的错误不包含堆栈跟踪,并且不像其他语言那样使用异常。相反,在Go中,将错误视为值,函数通常返回一个值和一个错误。通过检查错误值是否为nil,可以轻松确定函数是否成功执行,这也是唯一的错误处理方法。这种显式的错误处理方式有助于编写清晰、健壮的代码,并鼓励开发者正确处理可能发生的错误。
1. New error
首先是最基础的,Go 语言通过内置的 error 接口来处理错误,该接口定义如下:
type error interface {
Error() string
}这意味着任何实现了 Error() 方法的类型都可以作为错误类型。在 Go 中,通常使用 errors 包的 New 函数来创建简单的错误:
func divide(a, b int) (int, error) {
if b == 0 {
return 0, errors.New("division by zero")
}
return a / b, nil
}需要注意的是查看源码我们可以发现,errors 库中的 errorString 结构体实现了 error 接口,并且 New 一个 error 的时候会返回一个结构体的指针。
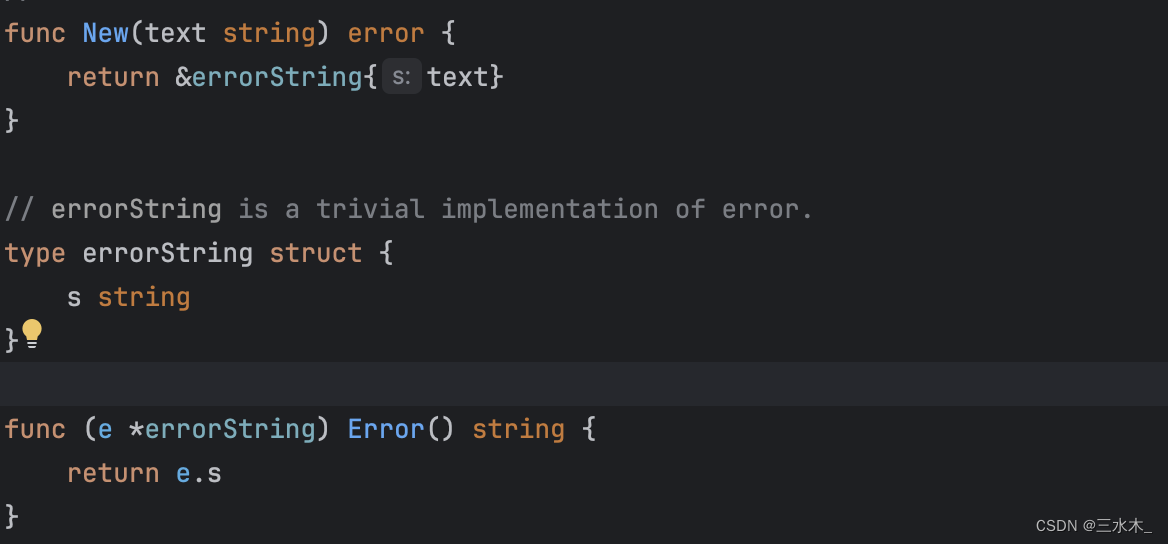
为什么会返回指针呢?让我们看一个自定义 New 示例:
func New(s string) error {
return errorString{text: s}
}
var err1 = New("test")
var err2 = errors.New("test")
func main() {
if err1 == New("test") {
fmt.Println("err string") // 会输出
}
if err2 == errors.New("test") {
fmt.Println("err string") // 不会输出
}
}可以发现,两个 == 判断结果并不相同,这是因为程序在对比结构体时,会逐一对比结构体中的各个字段,如果它们相同,就会返回 true。但是在对比指针时,系统会判断两个指针的地址是否一致。
以上是最基础的创建错误方式,既没有错误的上下文信息也没有堆栈信息,接下来让我们看一下 Golang 中还有哪些错误类型让我们来使用。
2. 错误类型
(1)Sentinel Error 哨兵错误
Sentinel Error 是一种常见的错误处理方式,其核心思想是定义一组特殊的错误值,用于表示在程序执行过程中可能遇到的特定情况。这些错误值通常是在包级别或全局范围内定义的,以确保在整个代码库中具有一致的含义。
让我们先看一个示例:
var ErrFileNotFound = errors.New("file not found")
var ErrPermissionDenied = errors.New("permission denied")
func ReadFile(filename string) ([]byte, error) {
if fileNotFound {
return nil, ErrFileNotFound
}
// 权限被拒绝
if permissionDenied {
return nil, ErrPermissionDenied
}
// 文件读取成功
return data, nil
}在上述示例中,ErrFileNotFound 和 ErrPermissionDenied 就是两个哨兵错误,用于表示文件不存在和权限被拒绝的情况。在调用 ReadFile 函数时,通过检查返回的错误是否等于这些预定义的哨兵错误,可以直观地判断出发生了什么错误。
Sentinel Error 的优点是提供了一种直观的错误处理方式,通过对比错误值是否等于预定义的哨兵值,可以快速判断错误类型,并且预定义的哨兵值通常具有自说明性,能够清晰地表达特定错误条件,提高了代码的可读性。
但是这种方式并不被推荐,因为调用方必须使用 == 将结果和预定义的值进行比较,当想要提供更多的上下文时,比如使用 fmt.Errorf ,这就出现了一个问题,因为返回的是一个不同的错误破坏了相等性检查。
更多,如果你的公共函数返回特定值的错误,那么这个值必须是公共的,增加了 API 的暴露面积。
除此之外,导致了两个包之间的源代码依赖关系。例如,检查错误是否等于 io.EOF 时,代码中必须导入 io 包。这样的依赖关系可能导致耦合,出现循环依赖。
(2)自定义类型
上述的哨兵错误无法携带上下文信息,使用自定义的错误类型可以包装底层错误携带更多的上下文信息。
让我们看一下底层的 os.PathError 是怎么做的
type PathError struct {
Op string
Path string
Err error
}
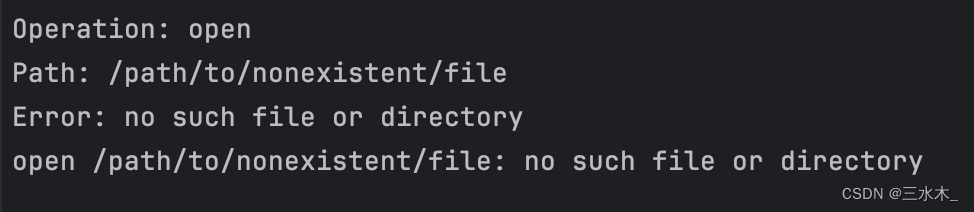
_, err := os.Open("/path/to/nonexistent/file")
if err != nil {
if pErr, ok := err.(*os.PathError); ok {
fmt.Printf("Operation: %s\n", pErr.Op)
fmt.Printf("Path: %s\n", pErr.Path)
fmt.Printf("Error: %v\n", pErr.Err)
} else {
fmt.Println("Non-path error:", err)
}
}运行结果如下图所示:它提供了底层执行了什么操作、哪个路径出了什么问题以及错误消息。
这种方式相对于哨兵来说,虽然能够携带更多的上下文信息,但是同样需要调用者进行类型断言,存在强耦合。
(3)不透明错误
不透明错误(Opaque Errors)是指一种错误处理风格,它不对外暴露底层的错误信息,函数在出现错误时只返回错误,而不假设其内容。这使得调用者只关心操作的成功或失败,而无需关注错误的具体原因。
当然不是所有时候都不关心错误出现的具体原因,当调用方需要调查错误的错误的性质的时候,我们可以断言错误是否出现了特定的行为,而不是断言错误的类型,如下所示:
type temporary interface {
Temporary() bool
}
func IsTemporary(err error) bool {
te, ok := err.(temporary)
return ok && te.Temporary()
}在上述示例中,可以通过调用 IsTemporary 来判断错误是否是临时性的,从而进行更多处理。
3. 错误处理
以上的三种类型都没有很好的解决错误的上下文信息和判断错误的具体类型的需求,接下来让我们先看看一些小的错误处理优化技巧
(1)消除错误
技巧之尽早返回错误
func readFile(filename string) ([]byte, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
if err == nil {
//不推荐
}
}技巧之消除错误处理
func AuthenticateRequest(r *http.Request) error {
err := authenticate(r.User)
if err != nil {
return err
}
return nil
//return authenticate(r.User)
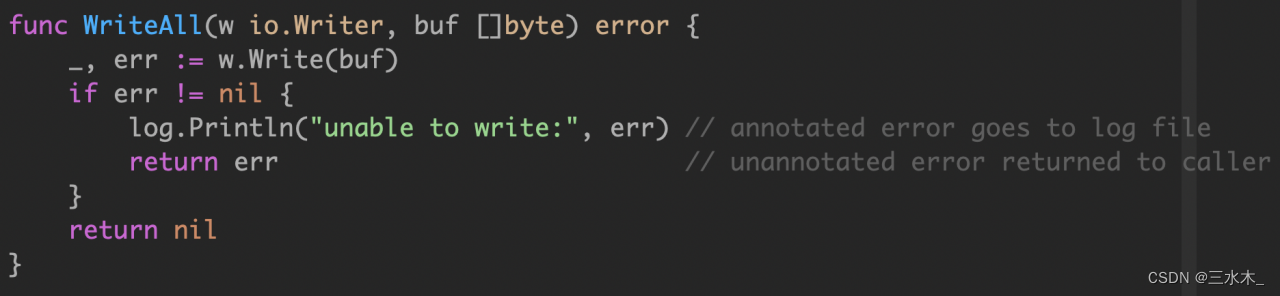
}技巧之将错误细节隐藏和重复的错误暂存
type errWriter struct {
w io.Writer
err error
}
func (ew *errWriter) write(buf []byte) {
if ew.err != nil {
return
}
_, ew.err = ew.w.Write(buf)
}
// 使用时
ew := &errWriter{w: fd}
ew.write(p0[a:b])
ew.write(p1[c:d])
ew.write(p2[e:f])
// and so on
if ew.err != nil {
return ew.err
}技巧之拒绝双重处理和到处打日志
如果在 w.Write 过程中发生了一个错误,那么一行代码将被写入日志文件中,记录错误发生的文件和行,并且错误也会返回给调用者,调用者可能会记录并返回它,一直返回到程序的顶部。
打日志原则:
- 错误要被日志记录。
- 应用程序处理错误,保证100%完整性。(写了一半的数据打日志,不报错❌)
- 之后不再报告当前错误。
(2)err 如何 wrap 和处理
errors.Wrap 用于将一个错误包装在另一个错误中,并添加额外的上下文信息。这使得在错误链中保留原始错误,同时提供更多的描述性上下文。
让我们为报错的 error 添加上堆栈信息:
//readFile 函数
file, err := openFile()
if err != nil {
return nil, errors.Wrap(err, "openFile 函数出错")
}通过errors.Is 函数进行递归检查错误链中是否包含ErrFileNotFound类型的错误,并在程序入口处打印堆栈信息:
Unwrap函数每次只会返回错误链中的一层,即被嵌套的最外层的错误
// 使用 Is 比较包装类型需要实现 Unwrap 方法
func (e *FoundFile) Unwrap() error {
return e.Err
}
_, err := readFile()
if errors.Is(err, ErrFileNotFound) {
fmt.Printf("%+v", err)
}模拟出错情况:可以发现带上了堆栈和具体的文件地址信息,大大方便了调试
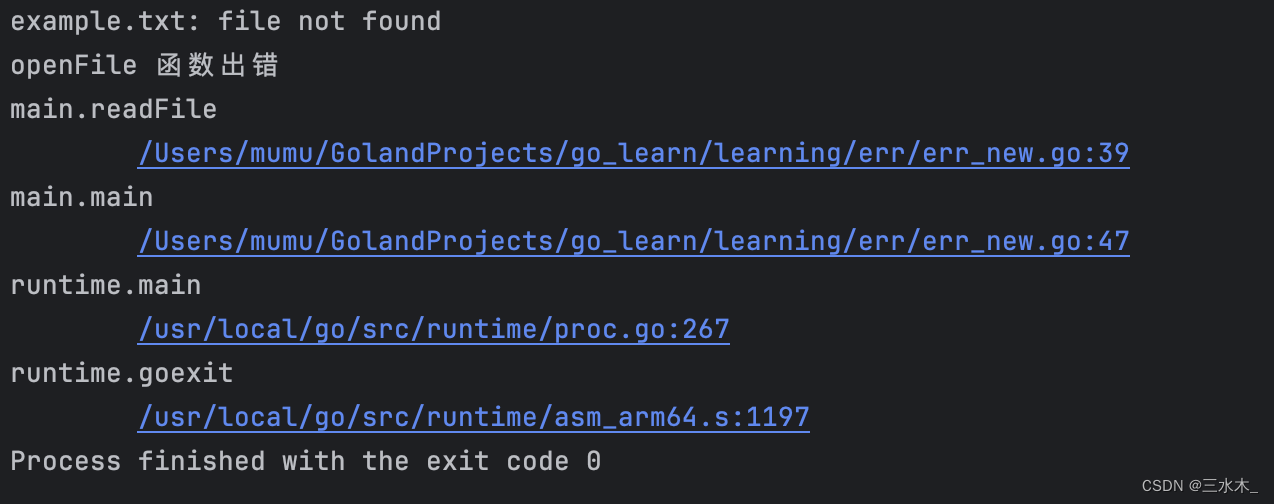
这种错误链的创建对于在代码中传递错误时非常有用。当一个错误经过多个函数传递时,每个函数都有机会为错误添加一些关键的上下文信息,而不丢失原始错误的相关信息。
(3)用 %w 包装错误
如前所述,使用fmt.Errorf函数向错误添加附加信息存在着改变原错误地址,无法进行后续的类型断言的问题。
if err != nil {
return fmt.Errorf("file path: %v %v", filePath, err)
}改进后的代码使用 fmt.Errorf 将错误包装起来,并通过 %w 标志表示将之前定义的错误包装进来。这样不仅可以在错误链中传递更多的上下文信息,也方便后续使用 Is 和 As 函数进行类型断言处理。
if err != nil {
return nil, fmt.Errorf("%v %w",filePath,err)
}需要注意的是通过这种方式包装的错误并不包含堆栈信息
if errors.Is(err, ErrFileNotFound) {
fmt.Printf("%+v", err)
}同理,旧的代码中,如果有对 error 进行类型断言的转换,就要用As函数代替
当错误嵌套了好几层可以通过
As函数进行类型断言,通过遍历 err 嵌套链,从里面找到类型符合的 error,然后把这个 error 赋予 target ,从而检查错误类型,并执行相应的处理逻辑。这使得我们能够更灵活地对不同类型的错误做出不同的响应。
// if e,ok := err.(*FoundFile);ok&&e.Err == ErrFileNotFound
var e *FoundFile
if errors.As(err,&e){
//...
}错误串联
以上通过 Wrap 包装错误堆栈信息成功解决了在单体系统中定位错误的问题,但是在实际生产中错误的发生可能涉及多个服务之间的交互,而定位问题的根本原因通常需要在整个分布式链路上进行跟踪。
假设我们现在有一个 http 服务通过 gRPC 调用获取文件服务:
请求 --> http服务 --> 调用gRPC --> 接受gRPC请求 --> 调用getFile
当出现失败情况,我们虽然在各个服务处记录了错误信息,但是在众多日志中我们并不知道某个出错请求对应的错误是哪些,需要我们按图索骥在众多的打点日志中找到出错请求的日志并逐一排查,还是很麻烦。
那么能不能把这些零散的错误串联起来,形成完整的错误链呢?
这里我们可以借助链路追踪技术,通过 TraceID(唯一标识了整个请求链路) 和 UID (用户的唯一标识符用于追踪一个用户的操作)的串联,实现在分布式系统中对问题请求产生的错误进行追踪和定位。
错误串联的简易流程如下:
- 在请求中添加 TraceID 和 UID:在请求的 Header 中添加 TraceID 和 UID 的信息。当一个请求进入系统时,第一个服务生成一个唯一的 TraceID,并将其添加到请求的 Header 中。
- 各个服务记录 TraceID 和 UID:每个服务在接收到请求时,都需要将请求中的 TraceID 和 UID 记录下来。
- 错误信息携带 TraceID 和 UID:当一个服务发生错误时,将错误信息中携带 TraceID 和 UID。这样,当排查错误时,就可以根据 TraceID 定位到整个链路,进而查看该用户的请求流转过程。
- 错误日志集中存储:将各个服务的错误日志集中存储,可以选择使用专门的日志存储服务或日志集中平台。通过 TraceID 和 UID,可以在错误日志中方便地筛选和定位问题。
通过以上的链路追踪方式,我们可以看到报错信息的完整流程,通过用户的 uid 找到出错请求的 traceId 即可找到关键的错误信息。
SOP 生成
通过上面的错误处理和错误串联成功记录了一个完整的错误链,排查起来已经比较高效。
但是找到错误信息后进一步还需要和研发人员沟通和定位错误的代码位置,查看究竟发生了什么,弄清楚根因后修复代码或是进行其他的必要操作,其中不免有许多重复发生过的问题。
这一来一回还是降低了效率,那么我们能不能让非系统错误止步于运维,一键反馈解决方案呢?
这时我们可以让错误码落实于文档,维护一个错误码、错误信息、错误的代码地址、解决方案的详细说明,但是通过人工维护的缺点也不少:
- 自己写文档,代码和文档不一致
- 有错误码找不到代码对应地方
- 有错误码不知道是哪个版本的代码
- 错误码在代码里还有没有使用,错误码越变越多,错误码腐化,没用的错误码应该随版本下线
- 错误码的 SOP,国际化问题
这里的 Standard Operating Procedure(SOP)手册是指系统的错误处理文档,它包含了关于错误码、错误信息、解决方案等的详细说明。编写和维护 SOP 手册有助于团队协同工作,提高开发效率。
所以为了一步到位,更好地管理和记录错误码,达到一键定位错误地址反馈解决方案的目的,我们可以通过使用 抽象语法树 分析代码找出错误码地址和解释,结合 GitLab CI 的自动化流程,实现代码与错误码文档的完美同步,解决传统方式中的种种痛点。
生成 SOP 手册的流程如下图所示:
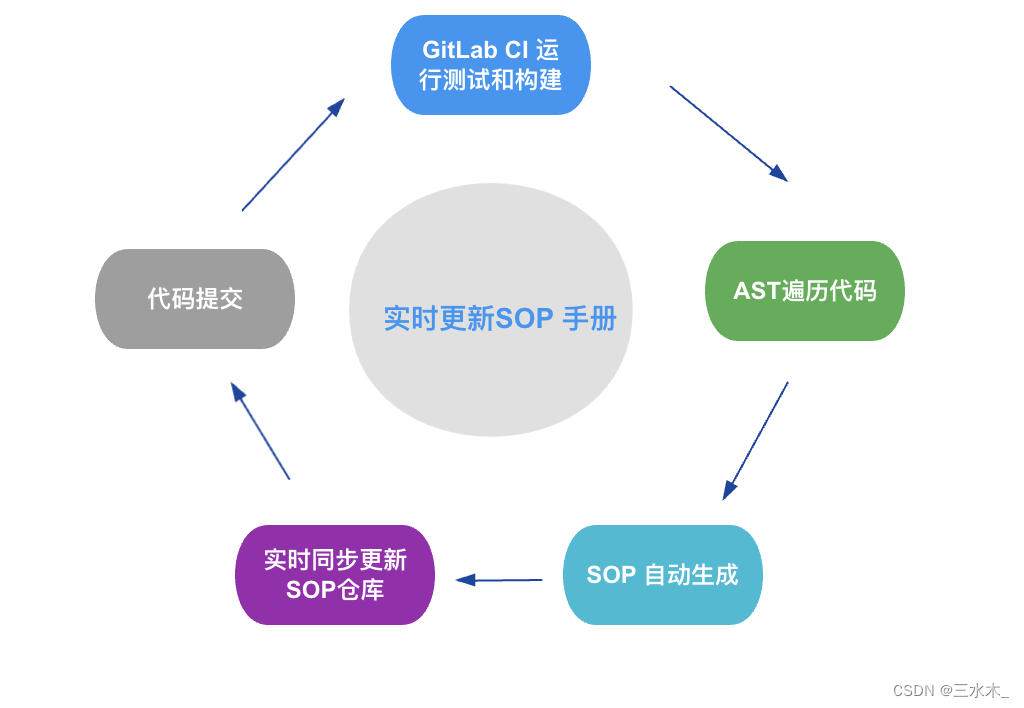
通过以上步骤生成 SOP 手册:

小结
在以上内容中,我们深入探讨了错误处理的各种方法和最佳实践。通过记录堆栈信息、串联错误以及记录请求的服务信息,我们全面介绍了错误从产生到解决的整个生命周期。
其中,我们提到了在错误处理中采用不同的技术,如 Sentinel Errors、自定义错误结构等,以及通过 TraceID 和 UID 实现的链路追踪,为错误的排查提供了便利。我们还展示了如何通过自动化 CI 流程来更新 SOP手册,使开发团队能够及时获取到最新的错误处理信息。这样的流程不仅提高了团队的协作效率,还为错误处理提供了规范的操作手册。
总体而言,通过这篇博客,我们全面剖析了错误处理的方方面面,建立起了健壮的错误处理机制,提升了系统的稳定性和可维护性。希望这些实践经验能够为开发者在实际项目中的错误处理工作提供有益的指导。

















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









