









引言
前几天有刷到一个提问:爬虫学了几个月了却还是不敢上手去接单,爬虫接单靠不靠谱?有些新手心里会犯嘀咕,怕不小心就踩了红线。作为过来人也接过不少单,来浅聊一下我的经验。
这篇所说的经验总结可能更适合爬虫新手,爬虫大佬可以忽略。
目录
一、Python爬虫学到怎么样可以接单?
1、基础简单回顾
想要上手爬虫,基本知识和工具的熟练使用是必须要具备的;
首先Python的一些语言基础肯定要有,爬虫大部分是用python写的,基本的语法、数据结构、函数等要熟练。
比如:
-
List dict:用来序列化你爬的东西
-
切片:用来对爬取的内容进行分割、生成
-
条件判断(if等):用来解决爬虫过程中哪些要哪些不要的问题
-
循环和迭代(for while):用来循环、重复爬虫动作
-
文件读写操作:用来读取参数、保存趴下来的内容等
其次Python爬虫主要用到的库就是request库,这个库是必须要学习的,获取到的数据还需要你自行处理,通过数据筛选规则,正则表达式等等技术进行筛选。
还有就是知道如何应付反爬;现在很多网站都开发了属于自己的反爬机制,所以一些常见的反爬措施是需要学习掌握的,否则无法顺利爬取到想要的数据。
需要补充学习的部分:
-
大致了解网络协议:HTTP/HTTPS 协议、tcp-ip协议;
-
了解HTML 、CSS、等前端基础;
-
理解网站的POST GET的一些相关概念,JS的一些基本内容,方便理解动态网页。
总结一下:
想要自己写一个Python爬虫程序,必须学会Python基础,包括环境安装、基础语法、字典、正则匹配、还有一些数据处理技术等等。
其次就是模拟请求的库request以及解析库的使用,还有一些反爬技术和前端基础。
2、爬虫的工作流程
简记为“爬虫四部曲”
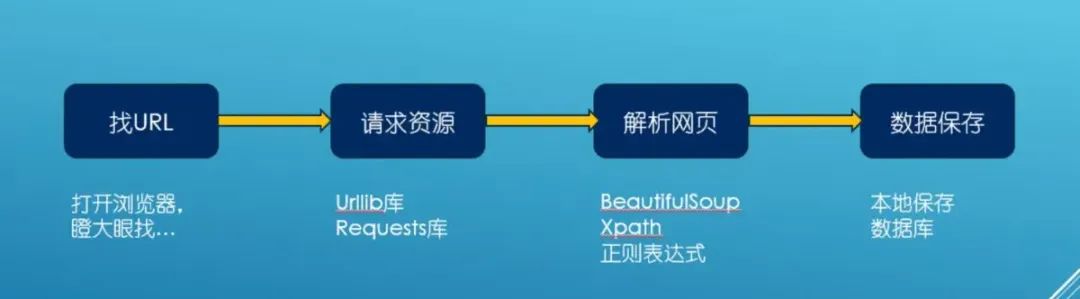
① 发起请求
使用http库向目标站点发起请求,即发送一个Request;
Request包含:请求头、请求体等;
如果只进行基本的爬虫网页抓取,urllib库足够用,Requests使用起来更简洁,自带json解析器,应付大多数的静态网页爬取问题不大。
涉及到动态网页抓取的话就要用到Selenium了,通常配合PhantomJS使用,,Selenium+PhantomJS可以抓取那些使用JS加载数据的网页。
② 获取响应内容
如果服务器能正常响应,则会得到一个Response;
Response包含:html、json、图片、视频等;
③ 解析内容
解析html数据:正则表达式、第三方解析库如Beautifulsoup、pyquery等;
解析json数据:json模块
解析二进制数据:以b的方式写入文件
个人一般情况下会用bs4,bs4无法满足就用正则。
正则一般用来满足特殊需求、以及提取其他解析器提取不到的数据,re速度比较快,但是写正则比较麻烦。
前端基础比较扎实的,用pyquery是最方便的,当然了,自己哪个用着方便就用哪个,无需纠结。
④ 保存数据
需要用到数据库;
小规模数据:可以使用txt文件、json文件、csv文件等方式来保存文件;
大规模数据:就需要使用mysql、mongodb、redis等数据库;
这步比较简单,掌握主流的数据库使用就差不多了。
【----相关技术讨论,Python 爬虫入门基础教程+安装工具 >点击此处< 获取!----】
二、关于爬虫可爬与不可爬的问题
其实我们生活中几乎每天都在爬虫应用,如百度,你在百度中搜索到的内容几乎都是爬虫采集下来的,(百度自营的产品除外,如百度知道、百科等)。
网络爬虫作为一门技术,技术本身是不违法的。
但是!记住重点!也不是网站的所有内容想爬就爬!随便你爬的!

以下情况需要注意,爬虫有可能违法:
1.爬虫程序规避网站经营者设置的反爬虫措施或者破解服务器防抓取措施,也就是非法获取相关信息。
2.爬取网上公开信息不犯法,但如果大量开启爬虫导致对方服务器崩溃,这属于暴力攻击的范畴了,肯定不可以的。
3.爬虫采集的信息属于公民个人信息,不能涉及到个人的隐私问题,如果涉及了并通过非法途径收益了,那肯定是违法行为咯。
当采集的站点有声明禁止爬虫采集或者转载商业化时:

淘宝网的法律声明
这么明显的提示了应该不会有人想不开吧!
当网站声明了Robots 协议:
是一种存放于网站根目录下的 ASCII 编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。
Robots 协议就是告诉爬虫,哪些信息是可以爬取,哪些信息不能被爬取,严格按照 Robots 协议爬取网站相关信息一般不会出现太大问题。
如何查看采集的内容是否有Robots 协议?
方法很简单,你想查看的话就在IE上打http://你的网址/robots.txt,站长工具也可以。
比如淘宝的robots协议
协议里最常出现的英文是Allow和Disallow,Allow代表可以被访问,Disallow代表禁止被访问。
所以在接单的时候保持适当的严谨是有必要的,哪些单子能接,哪些不能接自己心里得有个判断和分寸。
不要为一些明显是做灰黑产的人或者公司写代码,最好的避免违法的办法就是明显觉得不太好的事情就不要去碰,不要抱侥幸心理!!!

【----相关技术讨论,Python 爬虫入门基础教程+安装工具 >点击此处< 获取!----】
三、如何接单
1、怎么接单?
一般而言,对于刚刚开始接单的人而言,很难接到大单,基本上都是一些比较小的单。
但是没有关系啊,正好可以练手!
这些小单是可以提供一个很好的锻炼以及实践的机会,所以不要害怕接。
接单新手基本上接的都是网络爬虫、数据分析等这类的单,当然也可能有一些自动化运维之类的,但是都比较少。
个人做的话不太建议去抢一些几千元一个的项目,难度比较大,交付时间又紧,有些还是团对作战在抢单,这类单子要做的话难度高。
一般我们向甲方提供爬虫、数据分析、数据清洗这样的服务。
一开始也不要想着一口塞进个包子,慢慢来,等到技术提升之后可以去接一些开发之类的活,像APP开发、小程序开发都是几千的单子。
通过接单平台赚外快是个直接快速的方法,不同的任务需求难度不同,报酬在一两百、几千上万都有,具体能赚多少,看自己的技术水平。
接单报价方式:
简单公式:项目工时*日薪+紧急程度+报价
小tip:记得留个bug,防止不给尾款;
2、整理的一些接单平台:
①程序员客栈
程序员客栈中国非常领先的自由工作平台,支持按需雇佣,工作模式非常多,感兴趣的大家可以尝试一下。
程序员,产品经理,设计师等互联网相关人员,都能在上面找到适合自己的项目。支持自由、远程和兼职工作,还可以按需雇佣,工作模式非常多 。
②码市
互联网软件外包服务平台,适合专门为开发者而提供的平台,接单方式是企业发布项目招募报名参与,企业方筛选合作项目分阶段结算。
③猪八戒网
找兼职的地方,主要是入门级项目,不适合专业程序员,上面各类需求发布都有不限于软件开发行业,更适合新手。
④开源众包
开源中国的众包平台,主要是以众包为主。
⑥猿急送
追求高质量的雇主和工程师,汇聚了知名互联网公司的技术、设计、产品大牛,通过实际坐班、远程等方式,一对一为创业公司解决问题,提高创业效率。
⑦英选
虽然是外部平台,当他们还是针对外部项目的一些长期令人诟病的问题进行了一些优化。
⑧开发邦
服务范围明确,IT开发项目垂直度高,能吸引到一部分需求明确的客户。
⑨人人开发
基于可视化快速开发平台 - 捷得(Joget)/捷得云(Joget Cloud)(PaaS),集众多开发者资源,为企业提供企业管理软件服务。
现在爬虫接单的范围比较广,外包平台有很多,有兴趣的可以去尝试一下,新手接单多留个心眼。
如果你的工作薪资不高或者还没找到工作,都可以通过一些平台接一些兼职,既能提高收入又能锻炼提升自己的技术。
用技术增加收入,用收入保证生活,用生活享受人生!
3、什么单不接?
接单的时候自己掂量一下,有的单不建议接,因为可能对你没有太大的好处。
①加急单不接!
程序在写的时候你也不会清楚会遇到什么样的问题,可能你需要调试好久,调试也需要不少时间,最后做出来客户会不会满意也是个未知数,因此不建议接急单。
②不给定金的单不接!
定金很重要,一般会要10%左右的总金额最为定金吧,可能因人而异,但是建议是需要给定金的。
③私人单尽量少接!
因为风险大,正规平台的单相对安全一些,也不是说完全不要接,熟人介绍的有保障的还是可以接,只是说要谨慎,一般陌生私人的单我是不接的。
④不接繁杂的单!
有些单看上去很简单,但实际上要操作的东西很多,这样的单很耗时间,但是又不会有太多的报酬,比较浪费时间。就是钱少事多,这样的单一定要了解清楚再接。
4、注意事项
-
文明爬虫,不做违法的爬虫!(重点)
-
接单时谨慎,避免被骗!(重点)
-
价钱一定要事先谈好(搞清楚客户所说的价格是税后价格还是税前价格),然后再开始做;
-
没有金刚钻,就别揽瓷器活,接单一定要在自己能力范围内接;
-
在边学边接单的时候,要注意时间,不能按时完工的单还是不要接;
-
需求和要求一定要在做之前跟客户沟通好,了解清楚之后再做;
-
对于大项目,可以请求客户先付一部分押金,时间最好跟客户沟通一下留有时间余地,程序修改也很费时间。
-
如果客户让你报价,要适当合理的综合考虑代码复杂程度、完成所需要的时间等等多种因素;
-
好好检查你自己的代码和一些操作的算法实现的过程是不是完全正确的,千万不要犯低级的错误,否则会影响顾客对你的评价的。
【----相关技术讨论,Python 爬虫入门基础教程+安装工具 >点击此处< 获取!----】
四、总结
学习Python爬虫并准备接单是一个从理论到实践、从基础到深入的过程。很多人在学习了几个月后可能会感到有些迷茫或不自信,担心自己的技能不足以应对实际项目。以下是一些过来人的经验总结,希望能帮助你更好地迈出接单这一步:
1、巩固基础知识:
-
确保你对Python语言本身有扎实的理解,包括语法、数据结构、函数、类等。
-
深入理解网络请求与响应原理,熟悉HTTP/HTTPS协议。
-
掌握HTML、CSS、JavaScript的基础知识,以便更好地解析网页。
2、加强爬虫技能:
-
熟练使用requests、urllib等库进行网络请求。
-
掌握BeautifulSoup、lxml等库进行网页内容解析。
-
了解并实践Scrapy等高级爬虫框架,它们能大幅提升开发效率和项目可维护性。
-
学习并掌握反爬虫技术的应对策略,如设置请求头、代理IP、使用Selenium进行动态渲染页面的爬取等。
3、模拟真实项目练习:
-
找一些开源的爬虫项目或者自己设定目标网站进行实战练习。
-
尝试处理复杂的网页结构、JavaScript渲染的数据、登录验证等难题。
-
编写日志记录、异常处理、数据存储等辅助功能,提升项目的健壮性和可用性。
4、学习法律与道德:
-
在接单前,务必了解并遵守相关法律法规,特别是关于数据抓取、隐私保护等方面的规定。
-
明确目标网站的robots.txt文件内容,尊重网站的爬虫协议。
-
避免抓取敏感或非法信息,保持职业道德。
5、构建作品集:
-
将你完成的爬虫项目整理成作品集,展示你的技术实力和项目经验。
-
如果有条件,可以将项目部署到线上,并提供访问链接或演示视频。
6、积极寻求机会:
-
在GitHub、Gitee等平台上发布你的项目,吸引潜在客户的注意。
-
加入相关的技术社群或论坛,与同行交流学习,寻找合作机会。
-
通过社交媒体、个人博客等方式宣传自己的技能和服务。
7、合理定价与谈判:
-
根据项目的复杂程度、所需时间、你的技术水平等因素合理定价。
-
在与客户沟通时,明确项目需求、交付时间、付款方式等细节,避免后期纠纷。
8、保持学习与进步:
-
爬虫技术日新月异,保持对新技术、新工具的关注和学习。
-
参与开源项目、阅读技术文章、参加线上/线下课程等,不断提升自己的技能水平。
记住,迈出第一步总是最难的。只要你勇于尝试、不断学习、积累经验,你一定能够在Python爬虫领域取得成功!
五、关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。
当能够独立完成项目,技能与市场需求匹配时,即可考虑通过副业接单来应用所学并赚取外快。
持续学习,保持与行业同步是关键。
读者福利:对Python感兴趣的童鞋,为此我专门给大家准备好了Python全套的学习资料

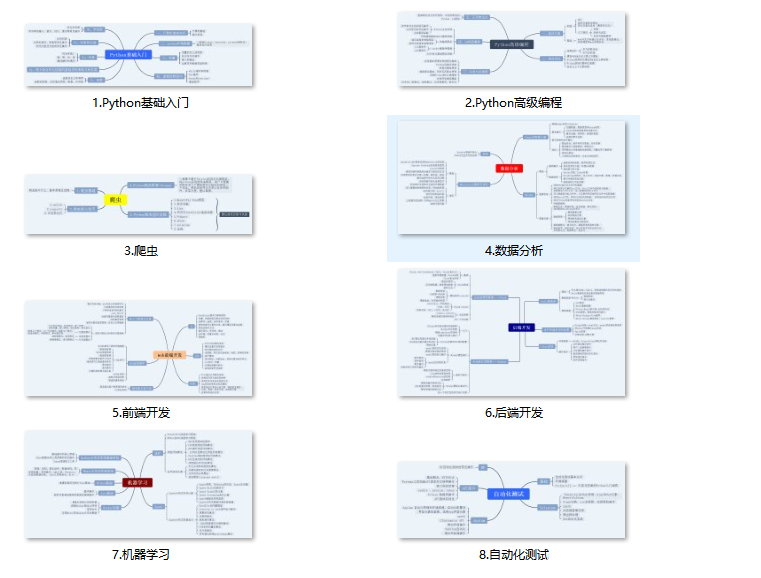
Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
视频教程
大信息时代,传统媒体远不如视频教程那么生动活泼,一份零基础到精通的全流程视频教程分享给大家
实战项目案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
副业兼职路线

















 2131
2131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









