






Abstract
This article talks about how to program in CUDA.
1. ".CU" files
CUDA C code is written into a text document in your project with the ".CU" extension. The ".CU" extension tells Visual Studio that the file is to be compiled by NVCC, the CUDA compiler.
2. Headers and Libraries
You must include the "cuda.h" header and the "cudart.lib" file as well in order to call the CUDA Api functions.
3. Host, Device and Kernels
Host: This is the CPU.
Device: This is the GPU.
Kernels: This is a function called by the CPU, runs on the GPU.
4. Function Qualifiers
__global__: This means a function called by host, runs on device.
__device__: This means a function called by device, runs on device.
__host__: (or not qualifier) This means a function called by host, runs on host.
5. Device Memory Management
Data must be copied back and forth between the host and the device since the GPU cannot see the system RAM. So, you may need to know the following CUDA API functions for device memory management.
cudaMalloc(void **devPointer, size bytes): This CUDA function reserves memory in the devices on global memory.
cudaFree(void **devPointer): This CUDA function releases memory on the device previously allocated by a cudaMalloc call.
cudaMemcpy(void *des, void *src, size bytes, cudaMemcpyDeviceToHost/ cudaMemcpyHostToDevice): This CUDA function copies to and from the device and host memory.
6. Procedures
Fine, next, we are going to do the following things:
a. Create two integers. (Host)
b. Allocate device memory for these two integers. (Device)
c. Copy these two integers to the device memory. (Host)
d. Call the kernel to add these two integers together. (Device)
e. Copy the result back to the host memory. (Device)
f. Print out the result. (Host)
g. Free the device memory. (Device)
7. The CUDA codes run on the Visual Studio 2012
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
using namespace std;
__global__ void Add(int *a, int *b, int *c){
c[0] = a[0]+b[0];
}
int main(void) {
// Declare variables
int addResult;
int *devicePointerA;
int *devicePointerB;
int *devicePointerC;
//Create two integers. (Host)
int a = 5;
int b = 9;
// Allocate device memory for these two integers and their add result. (Device)
cudaMalloc(&devicePointerA, sizeof(int));
cudaMalloc(&devicePointerB, sizeof(int));
cudaMalloc(&devicePointerC, sizeof(int));
// Copy these two integers to the device memory. (Host)
cudaMemcpy(devicePointerA, &a, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(devicePointerB, &b, sizeof(int), cudaMemcpyHostToDevice);
// Call the kernel to add these two integers together. (Device)
Add<<<1, 1>>>(devicePointerA, devicePointerB, devicePointerC);
// Copy the result back to the host memory. (Device)
cudaMemcpy(&addResult, devicePointerC, sizeof(int), cudaMemcpyDeviceToHost);
// Print out the result. (Host)
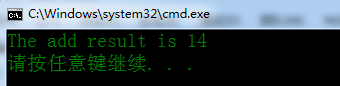
printf("The add result is %d \n", addResult);
// Free the device memory. (Device)
cudaFree(devicePointerA);
cudaFree(devicePointerB);
return 0;
}
8. The test result















 1556
1556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









