






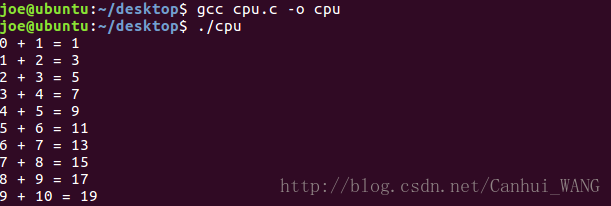
1. CPU端(程序:cpu.c)
#include <stdio.h>
#define N 10
void add(int *a, int *b, int *c){
int tid = 0;
while(tid < N){
c[tid] = a[tid] + b[tid];
tid++;
}
}
int main(){
int a[N], b[N], c[N];
for(int i=0; i<N; i++){
a[i] = i;
b[i] = i+1;
}
add(a, b, c);
for(int i=0; i<N; i++){
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
return 0;
}
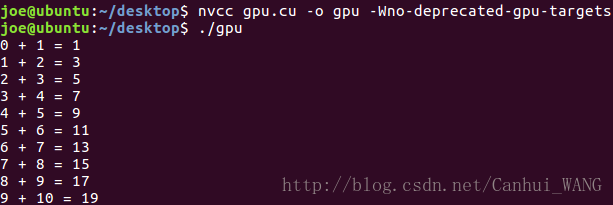
2. GPU端(程序:gpu.cu)
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#define N 10
__global__ void add(int *a, int *b, int *c){
int tid = blockIdx.x;
if(tid < N){
c[tid] = a[tid] + b[tid];
}
}
int main(){
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_a, N*sizeof(int));
cudaMalloc((void**)&dev_b, N*sizeof(int));
cudaMalloc((void**)&dev_c, N*sizeof(int));
for(int i=0; i<N; i++){
a[i] = i;
b[i] = i+1;
}
cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice);
add<<<N, 1>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost);
for(int i=0; i<N; i++){
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
return 0;
}
Reference
Sanders J, Kandrot E. Cuda by Example: An Introduction to General-Purpose GPU Programming[J]. 2010, 11(4):387-415.














 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









