







目标:实现两个长向量的加法;
代码规范:在主机代码的每一段中,给那些只由主机处理的变量名字加上前缀h_,给主要设备处理的变量名加上前缀d_;
使用CPU代码的版本
void vecAdd(float* h_A, float* h_B, float* h_C, int n) {
for (int i = 0; i < n; i++) {
h_C[i] = h_A[i] + h_B[i];
}
}
void init(float* ptr, int size, float val) {
for (int i = 0; i < size; i++) {
ptr[i] = val;
}
}
int main() {
const int N = 32;
float h_A[N];
float h_B[N];
float h_C[N];
init(h_A, N, 1.0f);
init(h_B, N, 2.0f);
vecAdd(h_A, h_B, h_C, N);
return 0;
}vecAdd使用一个CPU线程,将N个位置遍历一遍,同一个位置的h_A和h_B的元素相加赋值给h_C。
使用GPU代码的版本
如果使用GPU计算该怎么呢?并行执行向量加法的简单方法是修改vecAdd函数,将计算移到CUDA设备上。参考下面这篇文章,实现一个__global__向量加法;
CMAKE实现CUDA代码编写_bleedingfight的博客-CSDN博客环境说明CUDA:cuda-11driver:460.67os:5.10.18-1-MANJAROCMAKE:3.19.5目录结构如下:├── CMakeLists.txt├── include│ └── sumMatrix.h├── main.cu└── src ├── CMakeLists.txt └── sumMatrix.cu2 directories, 5 filescuda函数这里为了简便,CUDA实现的是一个二维矩阵加法,头文件(incluhttps://blog.csdn.net/bleedingfight/article/details/115751865 使用N个线程,每个线程计算出一个index,将index位置的h_A和h_B的元素相加赋值给index位置的h_C。

项目结构如下:
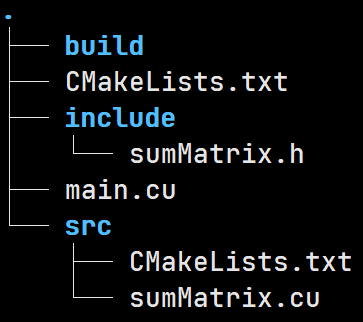
项目根目录下的CMakeLists.txt内容如下:
cmake_minimum_required(VERSION 3.14)
if(CUDA_ENABLED)
enable_language(CUDA)
endif()
# 设置cuda架构,设置两个arch,机器的显卡需要什么arch,需要查表;
set(CMAKE_CUDA_ARCHITECTURES 52 80)
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda")
set(CMAKE_CUDA_COMPILER "${CUDA_TOOLKIT_ROOT_DIR}/bin/nvcc")
set(CUDA_LIB_DIR "${CUDA_TOOLKIT_ROOT_DIR}/lib64")
set(CUDA_INCLUDE "${CUDA_TOOLKIT_ROOT_DIR}/include")
project(matrix_demo LANGUAGES CXX CUDA)
# 编译库所在路径
add_subdirectory(src)
# 调用函数需要的头文件
include_directories(include)
# 编译成可执行程序;
add_executable(main main.cu)
# 链接编译后生成的库
target_link_libraries(main matrix)main.cu
#include <cstdlib>
#include "sumMatrix.h"
#include <stdio.h>
void initData(float *f, int size, float value) {
for (int i = 0; i < size; i++)
f[i] = value;
}
void print(float *a, int n) {
for (int i = 0; i < n; i++)
printf("%.1f,", *(a + i));
printf("\n");
}
int main() {
int nx = 32;
int ny = 32;
int nxy = nx * ny;
int nBytes = nxy * sizeof(float);
float *h_a, *h_b, *h_c;
h_a = (float *)malloc(nBytes);
h_b = (float *)malloc(nBytes);
h_c = (float *)malloc(nBytes);
initData(h_a, nx, 1.0f);
initData(h_b, ny, 2.0f);
memset(h_c, 0, nBytes);
float *d_a, *d_b;
cudaMalloc((void **)&d_a, nBytes);
cudaMalloc((void **)&d_b, nBytes);
cudaMemcpy(d_a, h_a, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, nBytes, cudaMemcpyHostToDevice);
int dimx = 32;
int dimy = 32;
dim3 block(dimx, 1);
dim3 grid(1);
print(h_a, nx);
print(h_b, ny);
sumMatrix<<<grid, block>>>(d_a, d_b, nx, ny);
cudaMemcpy(h_c, d_a, nBytes, cudaMemcpyDeviceToHost);
print(h_c, nx);
cudaFree(d_a);
cudaFree(d_b);
free(h_a);
free(h_b);
free(h_c);
}这里使用包含一个线程块(block)的网格(grid),grid内的block包含了一维的线程,线程个数为32;
dim3 block(32,1,1);
dim3 grid(1,1,1);
sumMatrix<<<grid,block>>>(d_a, d_b, nx, ny); 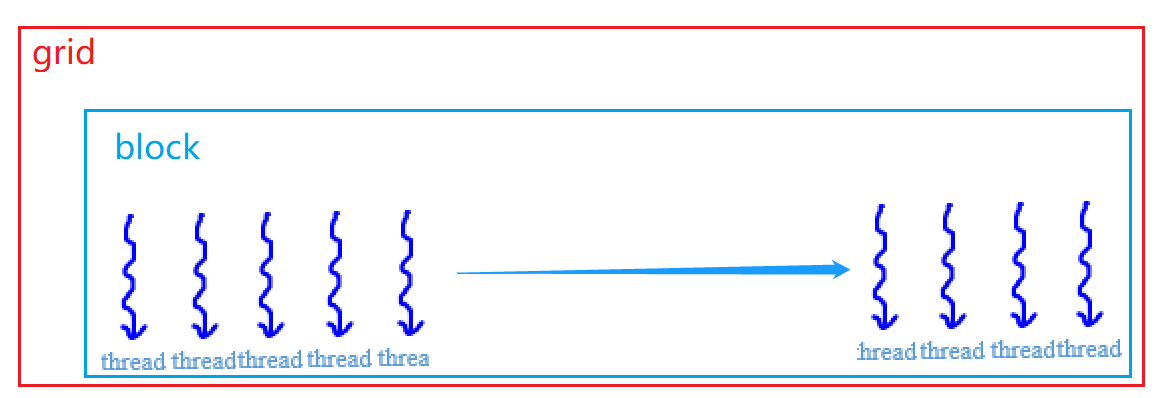
block内的thread编号从0到31;
CUDA内的grid、block和thread的关系可以参考下面的博文:
【CUDA】grid、block、thread的关系及thread索引的计算_hujingshuang的博客-CSDN博客_cuda gridCUDA中grid、block、thread的关系及thread索引的计算https://blog.csdn.net/hujingshuang/article/details/53097222 一个__global__函数对应了一个线程grid,grid内的block结构和block内的thread结构就是dims3所展示的内容;可以根据这些信息计算到每个方法所在的线程位置;
sumMatrix库下的CMakeLists.txt内容如下:
# 包含需要使用的头文件目录;
include_directories(${CMAKE_SOURCE_DIR}/include)
# 将文件目录“${CMAKE_SOURCE_DIR}/src/”下的所有cu文件名汇总到CUDA_SRC列表中;
file(GLOB CUDA_SRC ${CMAKE_SOURCE_DIR}/src/*.cu)
# 将CUDA_SRC列表对应的文件编译成动态库库;
add_library(matrix ${CUDA_SRC})sumMatrix.h
#ifndef SUM_MATRIX_CU_H
#define SUM_MATRIX_CU_H
#include <cuda_runtime.h>
__global__ void sumMatrix(float *a, float *b, int nx, int ny);
#endifsumMatrix.cu
#include "sumMatrix.h"
__global__ void sumMatrix(float *a, float *b, int nx, int ny) {
int index = threadIdx.x;
if (index < nx && index < ny)
a[index] = a[index] + b[index];
}更为复杂的index的计算,例如下图
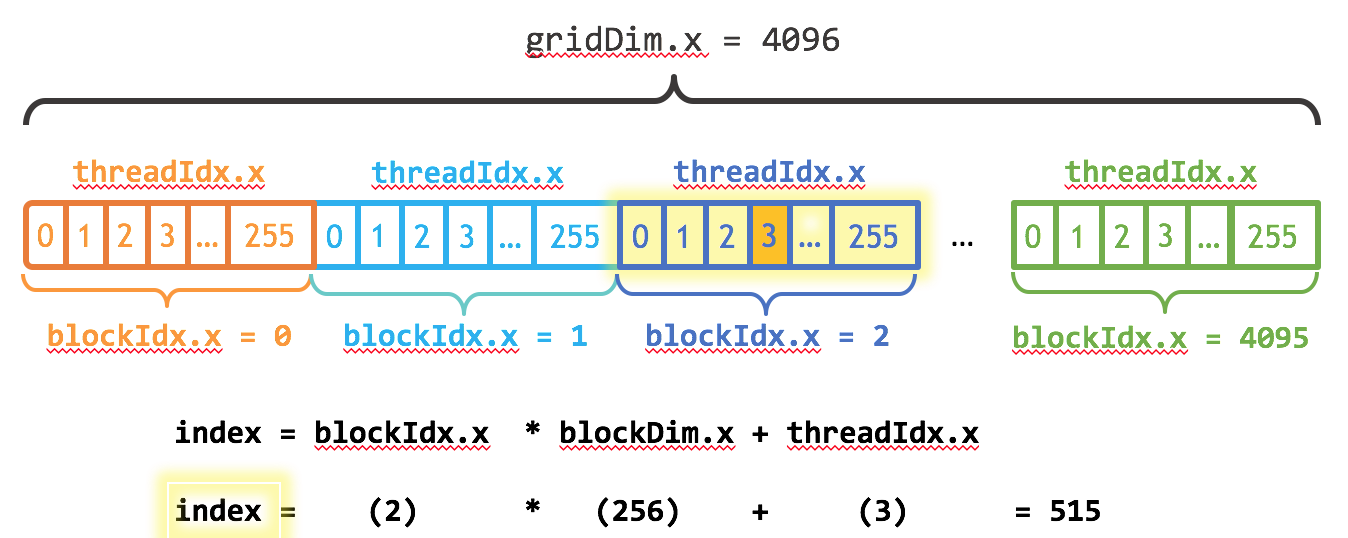
上图展示了一个包含一维block的grid结构,以及计算第三个block和该block内的第四个线程的序号;其实跟二维数组中第三行第四列的原始在数组中的偏移量的计算是一样的;
在build文件夹内,执行cmake ../;
root@ubuntu:/home/tmp_man/code/cuda_demo/build# cmake ../
-- The CXX compiler identification is GNU 7.5.0
-- The CUDA compiler identification is NVIDIA 11.2.142
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Detecting CUDA compiler ABI info
-- Detecting CUDA compiler ABI info - done
-- Check for working CUDA compiler: /usr/local/cuda/bin/nvcc - skipped
-- Detecting CUDA compile features
-- Detecting CUDA compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: /home/tmp_man/code/cuda_demo/build
在build文件夹内,执行make;
root@ubuntu:/home/tmp_man/code/cuda_demo/build# make
[ 25%] Building CUDA object src/CMakeFiles/matrix.dir/sumMatrix.cu.o
[ 50%] Linking CUDA static library libmatrix.a
[ 50%] Built target matrix
[ 75%] Building CUDA object CMakeFiles/main.dir/main.cu.o
[100%] Linking CUDA executable main
[100%] Built target main
执行编译后的main,./main,结果如下:

第一行为h_a内容;第二行为h_b,第三行为h_a+h_b的结果h_c;
















 1097
1097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











