







谷歌在2019年5月发表了新论文 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks ICML 2019
这篇论文主要讲述了如何利用复合系数统一缩放模型的所有维度,达到精度最高效率最高,符合系数包括w,d,r,其中,w表示网络宽度;d表示网络的深度;r表示分辨率大小.
谷歌开源了tensorflow代码(需要1.13版本及以上), 地址为:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
一. 扩增网络
文中对w,d,r三者都做了扩增,如图e.对于(224,224,3)的某层tensor来说,224*224代表分辨率r,3代表宽度w.网络层数代表深度d.

二.复合系数的数学模型
文中给出了一般卷积的数学模型如下
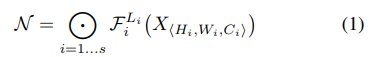
其中H,W为卷积核大小,C为通道数,X为输入tensor;
则复合系数的确定转为如下的优化问题:
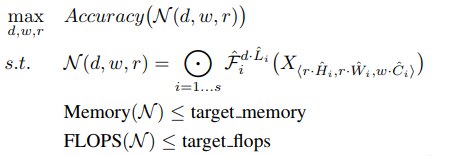
调节d,w,r使得满足内存Memory和FLOPS都小于阈值要求;
为了达到这个目标,文中提出了如下的方法:
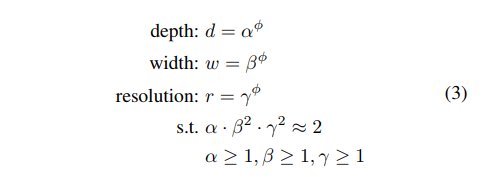
对于这个方法,可以通过以下两步来确定d,w,r参数:
第一步,固定
ϕ
\phi
ϕ=1,在Efficientnet-B0这个基线网络的基础上,计算出
α
⋅
β
2
⋅
γ
2
≈
2
\alpha\cdot\beta^2\cdot\gamma^2\approx2
α⋅β2⋅γ2≈2约束下最优的
α
β
γ
\alpha \beta \gamma
αβγ值.
第二步,固定
α
β
γ
\alpha \beta \gamma
αβγ值,对基线网络使用不同的
ϕ
\phi
ϕ值进行扩增,得到Efficientnet-B1到B7,具体参数在开源代码里.

同样,我们也可以将基线网络扩展到其他网络,使用同样的方法来放大.
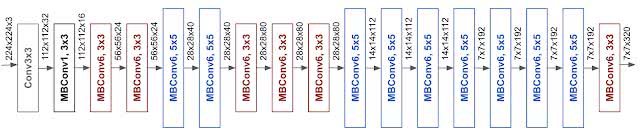
论文中基线模型使用的是 mobile inverted bottleneck convolution(MBConv),类似于 MobileNetV2 和 MnasNet,但是由于 FLOPS 预算增加,该模型较大。于是,研究人员缩放该基线模型,得到了EfficientNets模型,它的网络示意图如下:
可能会有人疑惑,为什么分辨率和宽度需要平方?我们查看网络中某个卷积层FLOPS的计算公式:
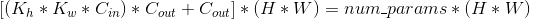
分辨率和宽度分别乘了两次,所以对应他们的约束也应该平方.
三.参数对比


第一个表格作者只给了参数量对比和FLOPs对比,第二个表格是在至强CPU上的速度对比。
为了进一步测试efficientnet性能,本人在1080ti显卡上测试了resnet152和efficientnet-b1的前向传播速度,分别为0.0466s和0.0167s,提升了2.7倍。在i7 CPU上分别是0.1130s和0.0490s,提升了2.3倍。resnet50和efficientnet-b0的速度差别不大。
由此得出结论,flops跟速度关系不大,硬件性能跟速度的关系更大。flops只有在相同硬件条件下才能提升速度,且提升有限。同准确率的其他模型的flops越大, efficientnet模型的速度提升越多。















 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









