1.网络优化方式
- 增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度的消失,训练困难的问题。
- 增加网络的宽度width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。(即增加卷积核的个数,特征矩阵的channels)
- 增加输入网络的图像分辨率能够潜在的获得更高细粒度的特征模板,但对于非常高的输入分辨率、准确率的增益也会减小,并且大分辨率图像会增加计算量。
- 同时增加网络的深度depth、宽度width和图像的分辨率回达到最好的效果。

2.EfficientNet网络架构
 EfficientNet_B0网络
EfficientNet_B0网络
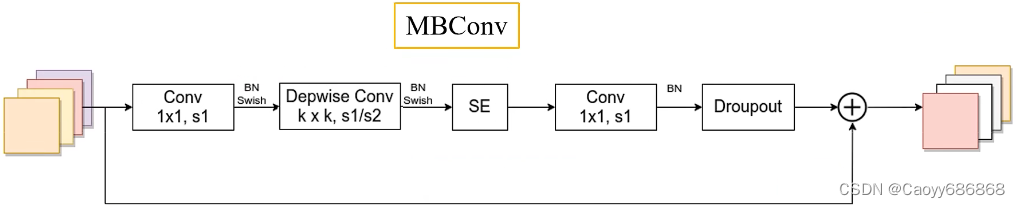

3.网络构建
import math
import copy
from functools import partial
from collections import OrderedDict
from typing import Optional, Callable
import torch
import torch.nn as nn
from torch import Tensor
from torch.nn import functional as F
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
This function is taken from the rwightman.
It can be seen here:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py#L140
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class ConvBNActivation(nn.Sequential):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU # alias Swish (torch>=1.7)
super(ConvBNActivation, self).__init__(nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())
class SqueezeExcitation(nn.Module):
def __init__(self,
input_c: int, # block input channel
expand_c: int, # block expand channel
squeeze_factor: int = 4):
super(SqueezeExcitation, self).__init__()
squeeze_c = input_c // squeeze_factor
self.fc1 = nn.Conv2d(expand_c, squeeze_c, 1)
self.ac1 = nn.SiLU() # alias Swish
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1)
self.ac2 = nn.Sigmoid()
def forward(self, x: Tensor) -> Tensor:
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale * x
class InvertedResidualConfig:
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate
def __init__(self,
kernel: int, # 3 or 5
input_c: int,
out_c: int,
expanded_ratio: int, # 1 or 6
stride: int, # 1 or 2
use_se: bool, # True
drop_rate: float,
index: str, # 1a, 2a, 2b, ...
width_coefficient: float):
self.input_c = self.adjust_channels(input_c, width_coefficient)
self.kernel = kernel
self.expanded_c = self.input_c * expanded_ratio
self.out_c = self.adjust_channels(out_c, width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod
def adjust_channels(channels: int, width_coefficient: float):
return _make_divisible(channels * width_coefficient, 8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf: InvertedResidualConfig,
norm_layer: Callable[..., nn.Module]):
super(InvertedResidual, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.use_res_connect = (cnf.stride == 1 and cnf.input_c == cnf.out_c)
layers = OrderedDict()
activation_layer = nn.SiLU # alias Swish
# expand
if cnf.expanded_c != cnf.input_c:
layers.update({"expand_conv": ConvBNActivation(cnf.input_c,
cnf.expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)})
# depthwise
layers.update({"dwconv": ConvBNActivation(cnf.expanded_c,
cnf.expanded_c,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)})
if cnf.use_se:
layers.update({"se": SqueezeExcitation(cnf.input_c,
cnf.expanded_c)})
# project
layers.update({"project_conv": ConvBNActivation(cnf.expanded_c,
cnf.out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity)})
self.block = nn.Sequential(layers)
self.out_channels = cnf.out_c
self.is_strided = cnf.stride > 1
# 只有在使用shortcut连接时才使用dropout层
if self.use_res_connect and cnf.drop_rate > 0:
self.dropout = DropPath(cnf.drop_rate)
else:
self.dropout = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
result = self.dropout(result)
if self.use_res_connect:
result += x
return result
class EfficientNet(nn.Module):
def __init__(self,
width_coefficient: float,
depth_coefficient: float,
num_classes: int = 1000,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None
):
super(EfficientNet, self).__init__()
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate, repeats
default_cnf = [[3, 32, 16, 1, 1, True, drop_connect_rate, 1],
[3, 16, 24, 6, 2, True, drop_connect_rate, 2],
[5, 24, 40, 6, 2, True, drop_connect_rate, 2],
[3, 40, 80, 6, 2, True, drop_connect_rate, 3],
[5, 80, 112, 6, 1, True, drop_connect_rate, 3],
[5, 112, 192, 6, 2, True, drop_connect_rate, 4],
[3, 192, 320, 6, 1, True, drop_connect_rate, 1]]
def round_repeats(repeats):
"""Round number of repeats based on depth multiplier."""
return int(math.ceil(depth_coefficient * repeats))
if block is None:
block = InvertedResidual
if norm_layer is None:
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
adjust_channels = partial(InvertedResidualConfig.adjust_channels,
width_coefficient=width_coefficient)
# build inverted_residual_setting
bneck_conf = partial(InvertedResidualConfig,
width_coefficient=width_coefficient)
b = 0
num_blocks = float(sum(round_repeats(i[-1]) for i in default_cnf))
inverted_residual_setting = []
for stage, args in enumerate(default_cnf):
cnf = copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))):
if i > 0:
# strides equal 1 except first cnf
cnf[-3] = 1 # strides
cnf[1] = cnf[2] # input_channel equal output_channel
cnf[-1] = args[-2] * b / num_blocks # update dropout ratio
index = str(stage + 1) + chr(i + 97) # 1a, 2a, 2b, ...
inverted_residual_setting.append(bneck_conf(*cnf, index))
b += 1
# create layers
layers = OrderedDict()
# first conv
layers.update({"stem_conv": ConvBNActivation(in_planes=3,
out_planes=adjust_channels(32),
kernel_size=3,
stride=2,
norm_layer=norm_layer)})
# building inverted residual blocks
for cnf in inverted_residual_setting:
layers.update({cnf.index: block(cnf, norm_layer)})
# build top
last_conv_input_c = inverted_residual_setting[-1].out_c
last_conv_output_c = adjust_channels(1280)
layers.update({"top": ConvBNActivation(in_planes=last_conv_input_c,
out_planes=last_conv_output_c,
kernel_size=1,
norm_layer=norm_layer)})
self.features = nn.Sequential(layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
classifier = []
if dropout_rate > 0:
classifier.append(nn.Dropout(p=dropout_rate, inplace=True))
classifier.append(nn.Linear(last_conv_output_c, num_classes))
self.classifier = nn.Sequential(*classifier)
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def _forward_impl(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
def efficientnet_b0(num_classes=1000):
# input image size 224x224
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.0,
dropout_rate=0.2,
num_classes=num_classes)
def efficientnet_b1(num_classes=1000):
# input image size 240x240
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.1,
dropout_rate=0.2,
num_classes=num_classes)
def efficientnet_b2(num_classes=1000):
# input image size 260x260
return EfficientNet(width_coefficient=1.1,
depth_coefficient=1.2,
dropout_rate=0.3,
num_classes=num_classes)
def efficientnet_b3(num_classes=1000):
# input image size 300x300
return EfficientNet(width_coefficient=1.2,
depth_coefficient=1.4,
dropout_rate=0.3,
num_classes=num_classes)
def efficientnet_b4(num_classes=1000):
# input image size 380x380
return EfficientNet(width_coefficient=1.4,
depth_coefficient=1.8,
dropout_rate=0.4,
num_classes=num_classes)
def efficientnet_b5(num_classes=1000):
# input image size 456x456
return EfficientNet(width_coefficient=1.6,
depth_coefficient=2.2,
dropout_rate=0.4,
num_classes=num_classes)
def efficientnet_b6(num_classes=1000):
# input image size 528x528
return EfficientNet(width_coefficient=1.8,
depth_coefficient=2.6,
dropout_rate=0.5,
num_classes=num_classes)
def efficientnet_b7(num_classes=1000):
# input image size 600x600
return EfficientNet(width_coefficient=2.0,
depth_coefficient=3.1,
dropout_rate=0.5,
num_classes=num_classes)
4.网络训练
import os
import math
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torch.optim.lr_scheduler as lr_scheduler
from model import efficientnet_b0 as create_model
from my_dataset import MyDataSet
from utils import read_split_data, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer = SummaryWriter()
if os.path.exists("./weights") is False:
os.makedirs("./weights")
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
img_size = {"B0": 224,
"B1": 240,
"B2": 260,
"B3": 300,
"B4": 380,
"B5": 456,
"B6": 528,
"B7": 600}
num_model = "B0"
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size[num_model]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(img_size[num_model]),
transforms.CenterCrop(img_size[num_model]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
# 如果存在预训练权重则载入
model = create_model(num_classes=args.num_classes).to(device)
if args.weights != "":
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
print(model.load_state_dict(load_weights_dict, strict=False))
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
# 是否冻结权重
if args.freeze_layers:
for name, para in model.named_parameters():
# 除最后一个卷积层和全连接层外,其他权重全部冻结
if ("features.top" not in name) and ("classifier" not in name):
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=1E-4)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
for epoch in range(args.epochs):
# train
mean_loss = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
scheduler.step()
# validate
acc = evaluate(model=model,
data_loader=val_loader,
device=device)
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--lrf', type=float, default=0.01)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="./data/flower_photos")
# download model weights
# 链接: https://pan.baidu.com/s/1ouX0UmjCsmSx3ZrqXbowjw 密码: 090i
parser.add_argument('--weights', type=str, default='./efficientnetb0.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args(args=[])
main(opt)
5.网络效果验证
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import efficientnet_b0 as create_model
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_size = {"B0": 224,
"B1": 240,
"B2": 260,
"B3": 300,
"B4": 380,
"B5": 456,
"B6": 528,
"B7": 600}
num_model = "B0"
data_transform = transforms.Compose(
[transforms.Resize(img_size[num_model]),
transforms.CenterCrop(img_size[num_model]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "./tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = create_model(num_classes=5).to(device)
# load model weights
model_weight_path = "./weights/model-0.pth"
model.load_state_dict(torch.load(model_weight_path, map_location=device))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict[i].numpy()))
plt.show()
if __name__ == '__main__':
main()

























 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











