










文章目录
GPU的问题
nvcc -v和nvidia-smi显示版本不一致
linux下
由于GPU和CPU版本安装区别很大,所以这里要先搞清楚自己服务器的GPU情况。
其实安装的是PaddlePaddle的镜像,paddleocr并没有官方镜像,去docker hub上也有,但是吧,还是想要官方的
- 查看cudnn版本,
nvidia-smi
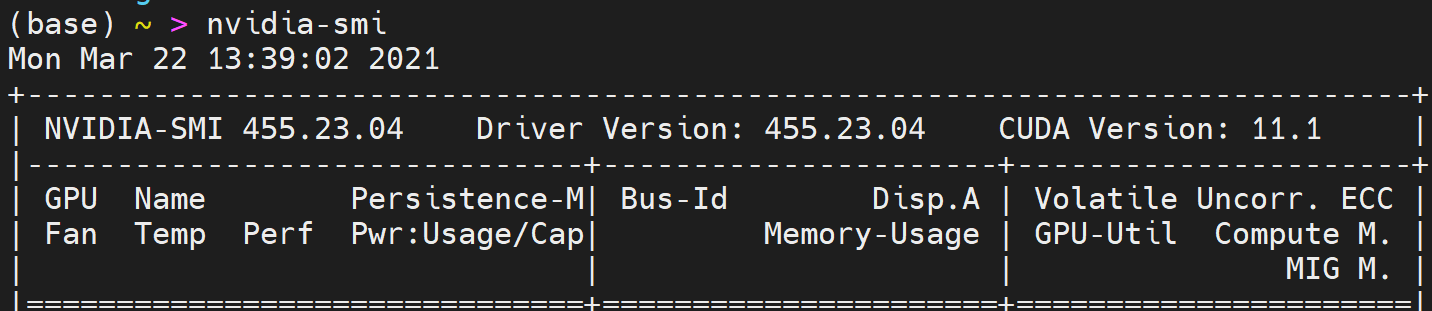
或者可以使用(nvidia-smi安装好了,表示cuda和cudnn已经安装了 )
nvcc -V
# 如果报找不到该路径或文件,则表示nvcc没有安装,
# 可以安装 安装好之后再输入就可以了
sudo apt install nvidia-cuda-toolkit
但是显示
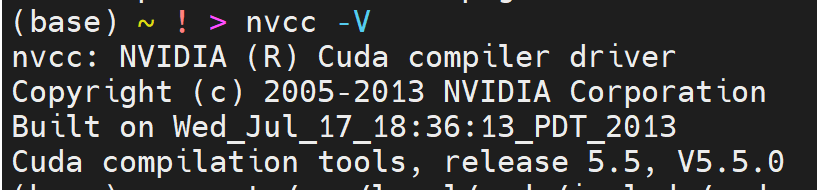
版本很低。。与nvidia-sim版本显示不一致,
按照网上的一些方式去查看,

发现我这个nvcc文件的位置似乎和其他博客的不太一样,难受
参考:
这个博客写的很清楚了
windows下查看
查看nvcc(正常,因为我记得我安装的是11):
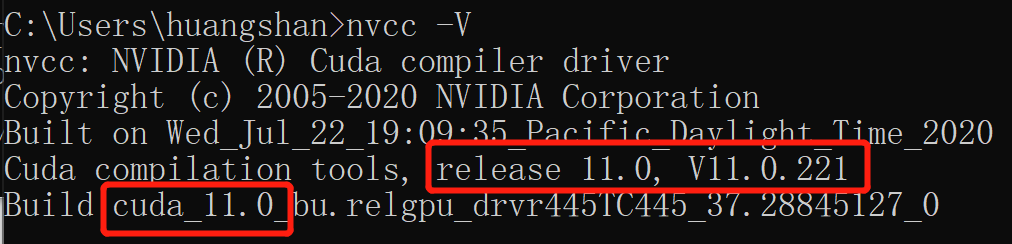
查看nvidia-smi,
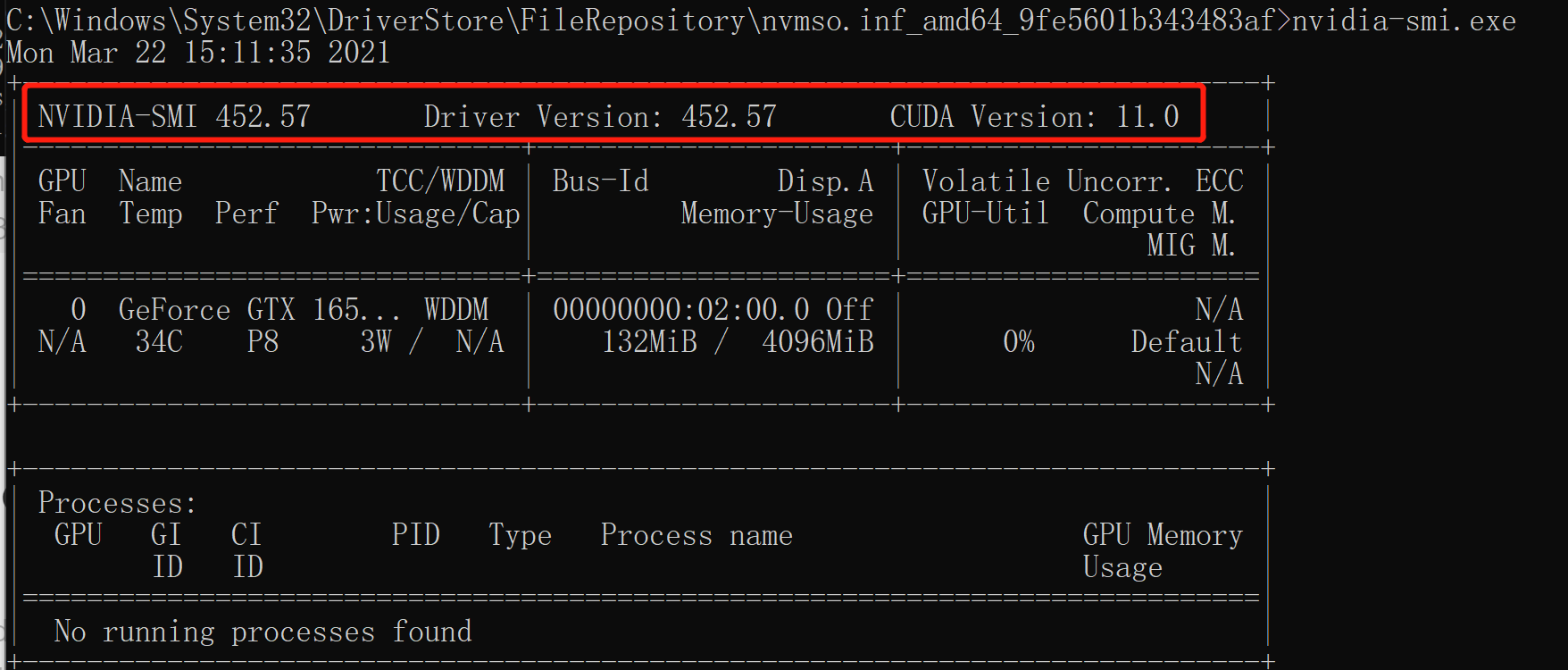
所以我本机的电脑安装是正确的,服务器不是自己安装的,需要解决一下问题。
使用paddlepaddle的镜像
如果想使用paddleocr的镜像,也可以,但是既然官网给出的是使用paddlepaddle的镜像,之后再进行paddleocr的安装,我觉得还是按照官网的来。
参考:快速安装
Docker 19.03,增加了对–gpus选项的支持,想在docker里面读取nvidia显卡再也不需要额外的安装nvidia-docker了——源自在docker19中使用GPU
使用nvidia-docker进行GPU使用
- 看了一下paddlepaddle官方的安装文档:开始使用
- 注意:官网是提供了Docker安装方式的(不推荐使用这种方式,因为使用的是nvidia-docker)
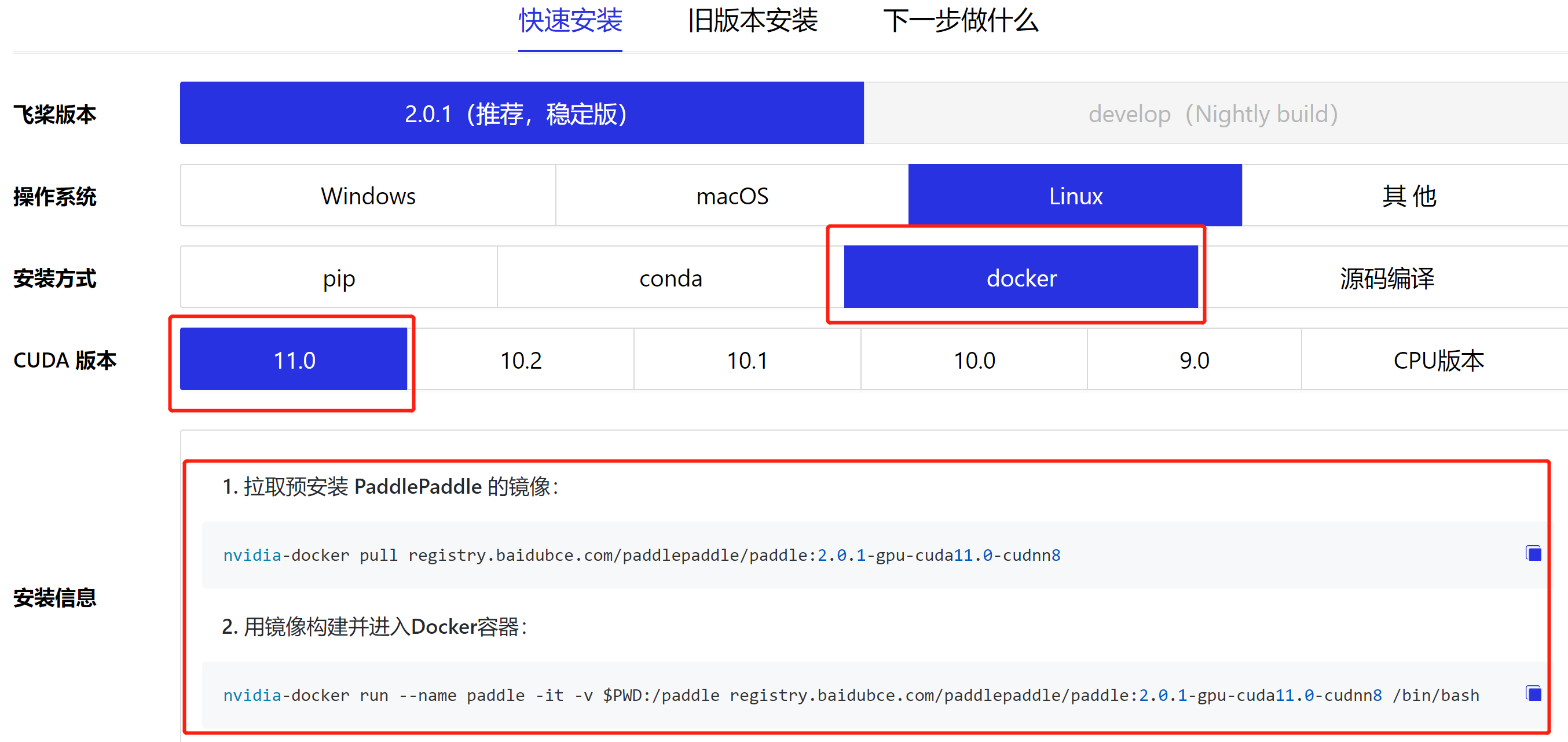
# 拉取预安装 PaddlePaddle 的镜像: nvidia-docker pull registry.baidubce.com/paddlepaddle/paddle:2.0.1-gpu-cuda11.0-cudnn8 # 用镜像构建并进入Docker容器: nvidia-docker run --name paddle -it -v $PWD:/paddle registry.baidubce.com/paddlepaddle/paddle:2.0.1-gpu-cuda11.0-cudnn8 /bin/bash
不使用nvidia-docker进行GPU使用
- 另外,在paddleocr英文版的快速安装说明里,找到了PaddlePaddle的docker hub中的主页:https://hub.docker.com/r/paddlepaddle/paddle/tags/?page=1&ordering=last_updated,
- 可以在这里看到PaddlePaddle最新的镜像:
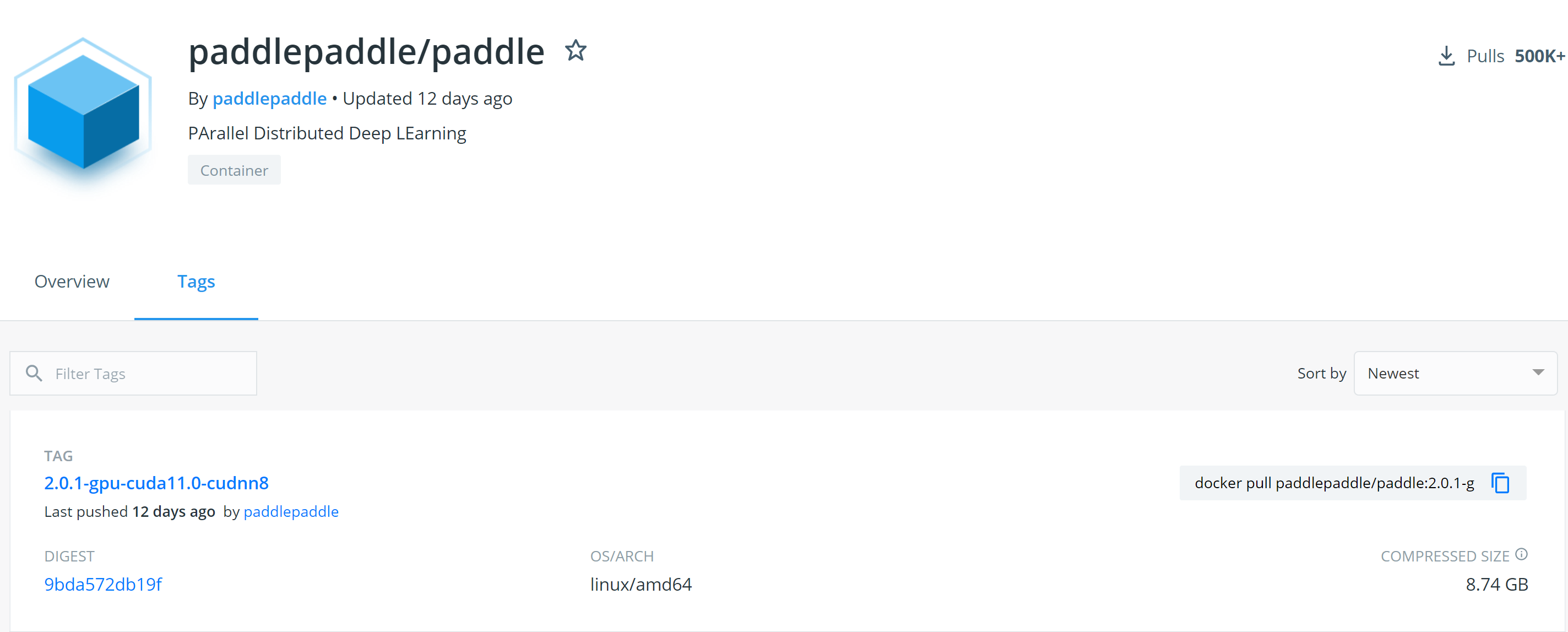
镜像很大,压缩后都有8.74GB,服务器上之前有人pull过PaddlePaddle以前的版本,解压完差不多有27G,巨大!

不过这个比较旧了,用新的试试看好了。# pull最新版本的镜像 docker pull paddlepaddle/paddle:2.0.1-gpu-cuda11.0-cudnn8
要等它分析一会,如果下载速度慢的话,可以考虑修改docker源。下载完后可以看到:
docker images
# 加上-a可以看到连镜像名字都是none的镜像
docker images -a

疑问:确实是两个同名的镜像,但是tag没有变成一个latest,一个none。。。应该没什么问题???那个教程说的不是非常严谨,
通常有两种方式来对镜像打标签:使用docker tag命令或者是在执行docker build的时候用-t来传递参数。在这两种情况下,参数的形式通常是repository_name:tag_name,例如:docker tag myrepo:mytag。如果这个资源库被上传到了Docker Hub,资源库的名字会加上一个由Docker Hub用户名和斜线组成的前缀,例如:amouat/myrepo:mytag。
如果没有添加tag部分的参数,例如:docker tag myrepo:1.0 myrepo,Docker会自动的给它latest标签。前面这些内容或许你已经熟知,其实它也就这点内容,并没有什么神奇的地方。
不能因为镜像的标签是latest就认为这是资源库中最新的镜像。只有这个资源库的拥有者约定这样,拥有latest标签的镜像才一定是最新的镜像。
如果确实在意这个标签,可以参考:
stack overflow-How to create named and latest tag in Docker?
来进行修改。
修改docker镜像源
参考:
# 首先要确定配置docker源的文件位置,就是下面这个位置
cat /etc/docker/daemon.json
# 把下面这些填到对应位置就可以了
"https://registry.docker-cn.com",
"https://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com",
"https://cr.console.aliyun.com/",
"https://docker.mirrors.ustc.edu.cn"
最后效果类似:
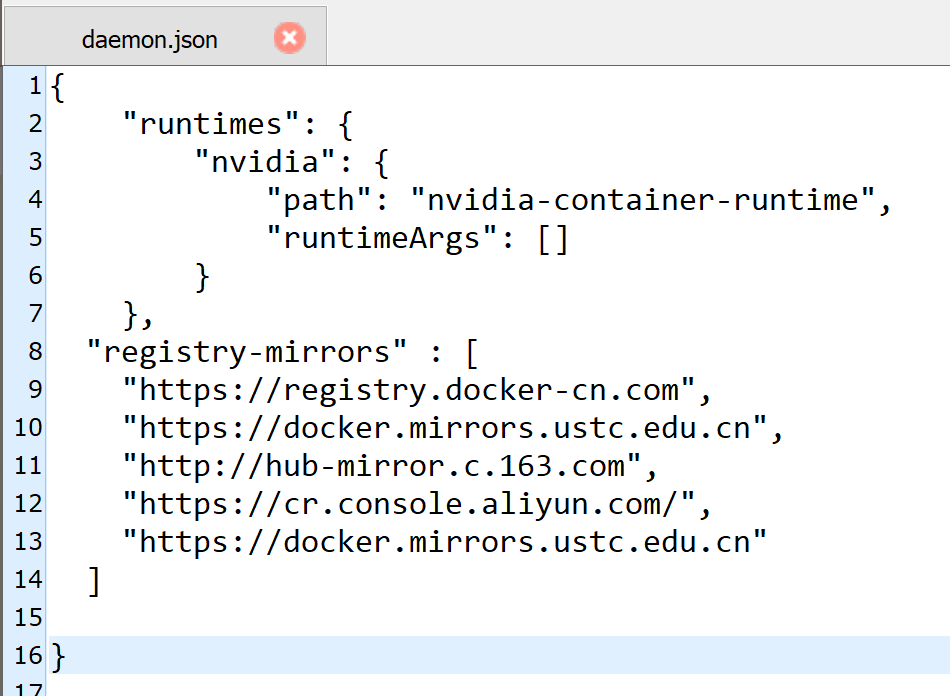
搞完之后要重启docker:
sudo service docker restart
# 查看镜像源信息
docker info|grep Mirrors -A 1
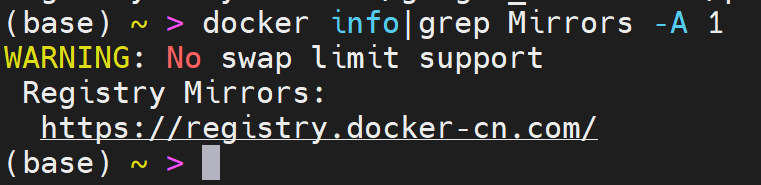
就很棒!
docker镜像更新
关于docker镜像的更新,可以参考:
- 手动更新(如果只有几个镜像的话):如何更新docker镜像
- 利用工具去进行自动更新:Watchtower – 自动更新 Docker 镜像与容器
在服务器上部署 Docker 容器有一种在手机上装 APP 的感觉,但 Docker 容器并不会像手机 APP 那样会自动更新,而如果我们需要更新容器一般需要以下三个步骤:
停止并删除容器:docker rm -f <CONTAINER>
更新镜像:docker pull <IMAGE>
启动容器:docker run <ARG> … <IMAGE>
如果部署了大量的容器需要更新使用这种传统的方式工作量是巨大的。
镜像搞定之后的其他步骤
启动容器
搞好镜像之后就要写那个运行镜像生成容器的语句,比较麻烦,给个示例(可以参考我另一个博客:
利用docker在linux服务器上部署tensorflow、pytorch等环境中):
# 最好是把这个命令写成一个.sh脚本文件,方便启动容器
docker run -it -d --gpus "device=3" --ipc=host -p 10035:22 -v /ws/huangshan:/ws --name "OCR" paddlepaddle/paddle:2.0.1-gpu-cuda11.0-cudnn8 bash -c "/etc/rc.local; /bin/bash"
假设保存成了paddle_container.sh,
# 使用如下语句运行
bash paddle_container.sh

由于加入了-d参数,所以容器在后台运行。可以使用
docker container ls
# 查看现在的容器列表

可以看到,刚刚创立的容器信息。(容器ID是缩写)
进入和退出一个已经启动的容器,可以使用
# ctrl+P+Q可退出docker 容器
exit # 容器环境中,使用这个也可以退出容器,回到linux命令行环境
# 重新进入docker 容器使用如下命令
docker container exec -it OCR /bin/bash

进入容器之后,可以看到,根目录下以及有了一个ws目录,与刚刚创建容器时的保持一致,容器的ws目录下的内容与本机映射的ws目录下的内容一模一样。
题外话
这个文章写的不对:
PaddleOCR安装、部署、测试
我有个非常弱智的问题,为什么安装了paddlepaddle的镜像之后我还要再pip安装paddlepaddle?
在镜像中可以查看一下一些包的情况
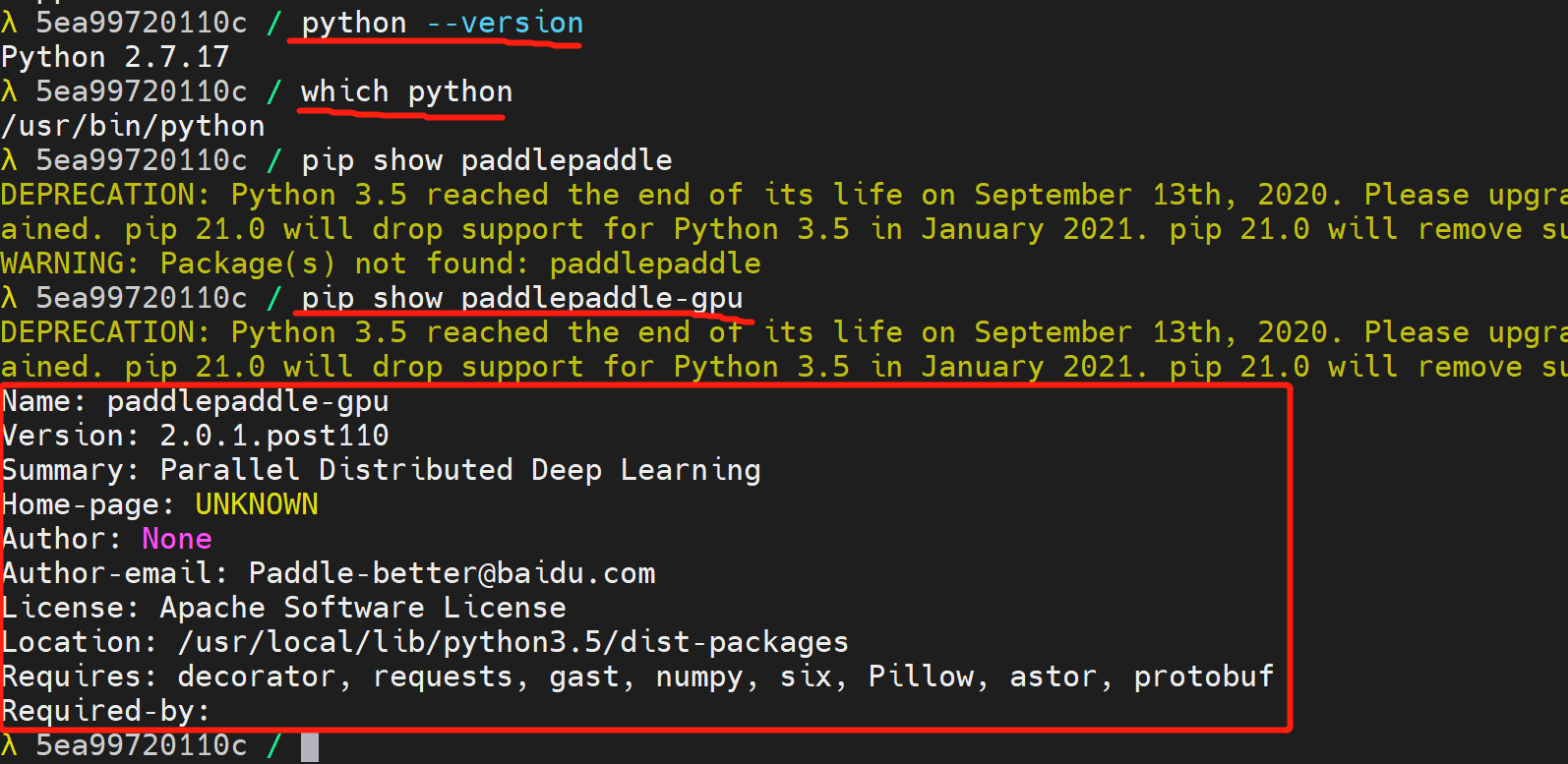
其实安装镜像之后,就已经配套有了基本的python环境,包括paddlepaddle-gpu了。
git clone paddleocr
接下来就是常规的安装过程了,这部分出错可以参考另一个博客:docker的git无法访问github但是可以访问gitee
pip install requirements
真的感觉每走一步都有个坑,真的是艰难。。。
cd PaddleOCR
pip3 install -r requirements.txt
运行pip安装必要包的时候报错,说python3.5找不到这些包了。郁闷,paddlepaddle镜像是python3.5的?

这个镜像配置似乎也有点乱,使用which python可以看到,python的位置在/usr/bin/python
打开/usr/bin这个目录看看,真的是牛逼他妈给牛逼开门,牛逼到家了,😎
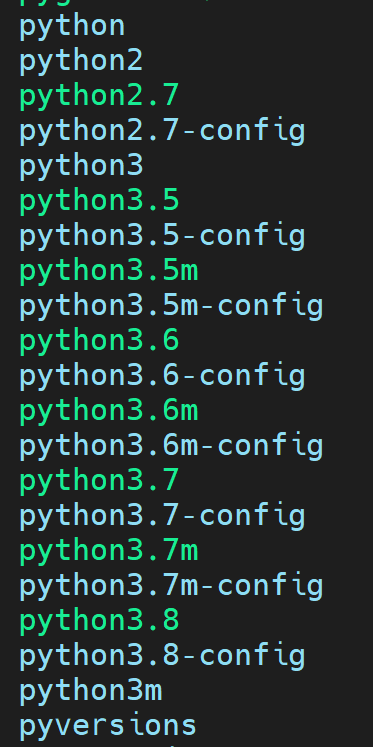
所以上面的命令应该改成
pip3.7 install -r requirements.txt
# 因为paddleocr的建议是python3.7
就好起来了,开心(但是感觉安装了一大坨的样子)
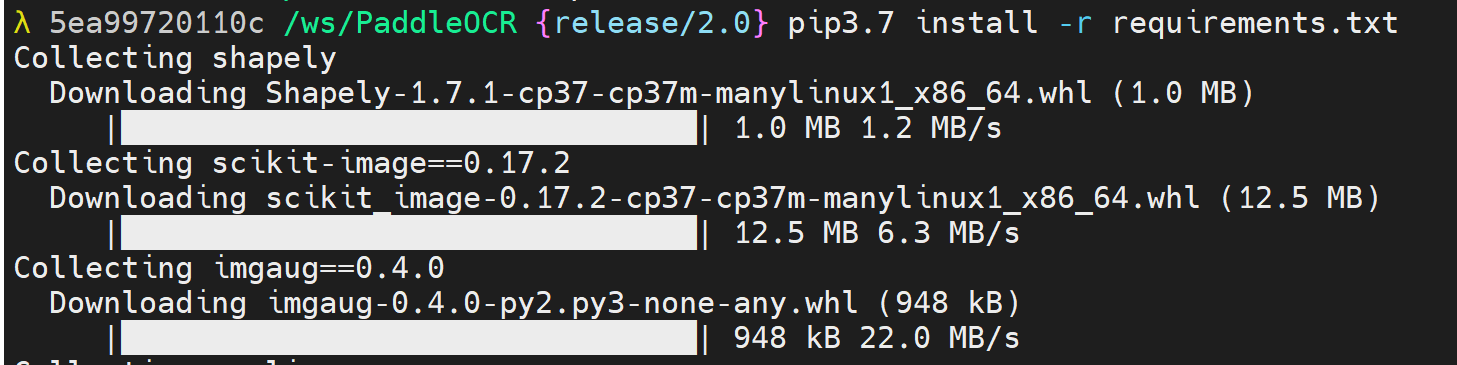
下载速度很快,但是。。。额,一共有这些包
shapely
scikit-image==0.17.2
imgaug==0.4.0
pyclipper
lmdb
opencv-python==4.2.0.32
tqdm
numpy
visualdl
python-Levenshtein
但是这个过程很慢

这里看到一个东西,存储目录。虽然不幸最后再构建这个shellcheck-py出错了 Failed to build shellcheck-py,而且我没有找到解决方案。
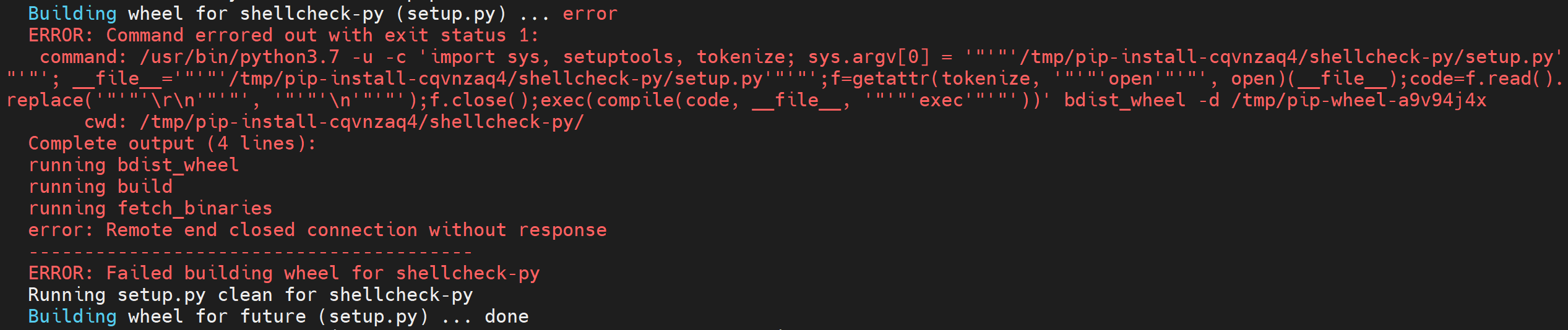
看报错信息似乎还是网络的问题,算了,再次pip install requirements的时候看到显示shellcheck-py这个包已经安装好了,那就这样吧。
中文OCR模型快速使用
环境配好了,然后就是快速应用的问题了。可以参考paddleocr文档:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/doc/doc_ch/quickstart.md
这里为了方便编程,直接使用sublime text3配套插件SFTP来进行运行命令。大概就是这个样子:
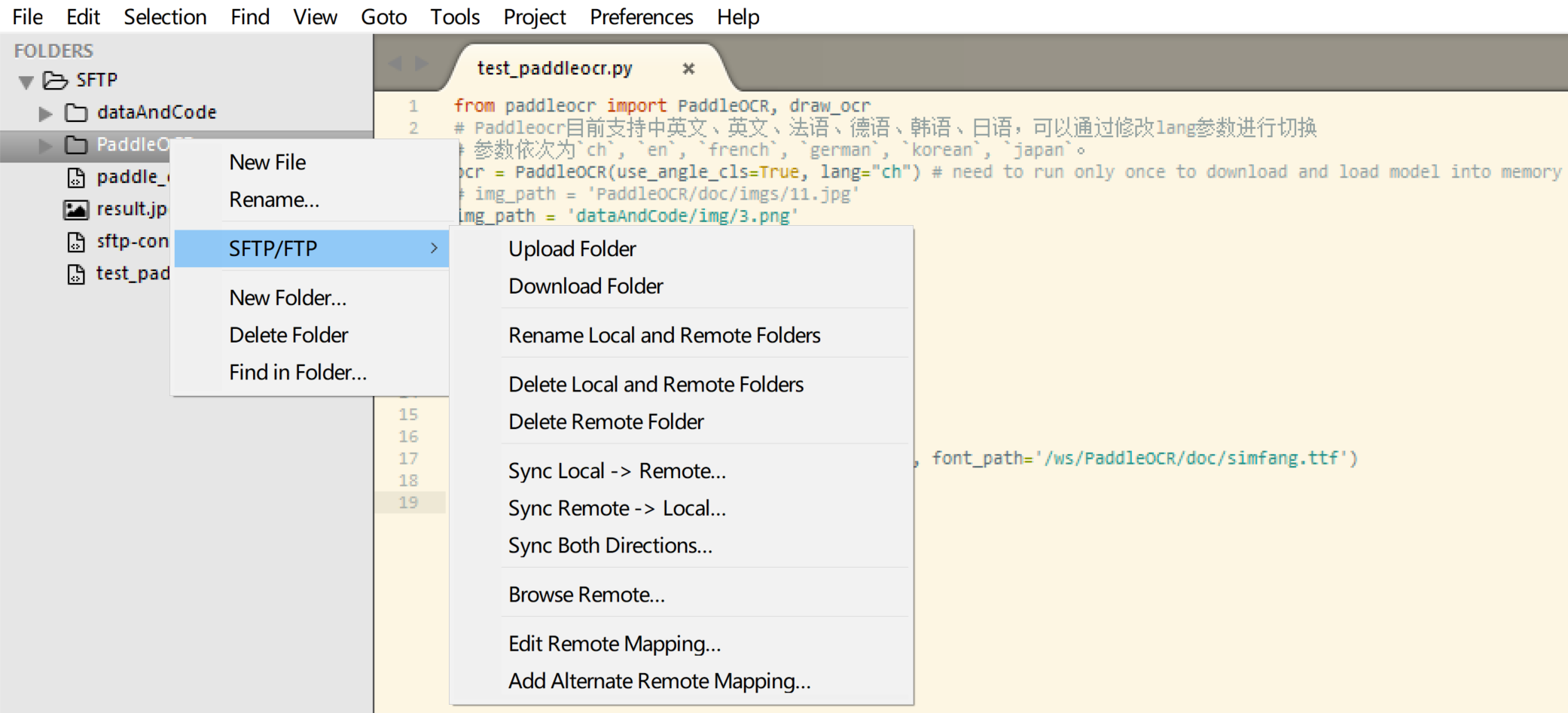
这样就可以快速在本地和服务器端同步代码,方便操作。
使用paddleocr.wheel来进行快速使用
参考:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/doc/doc_ch/whl.md
需要切换到对应的镜像环境中,
pip3.7 install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
执行的代码其实就是这样
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = 'PaddleOCR/doc/imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/simfang.ttf')
# 注意 这个字体文件似乎在我git的repo里没有,需要自己放一个中文字体,不然结果图片中无法显示中文
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
其实可以看出来,运行的时候会下载预训练的模型,同时,看起来简单的直接调用接口其实背后配置了大量的参数。
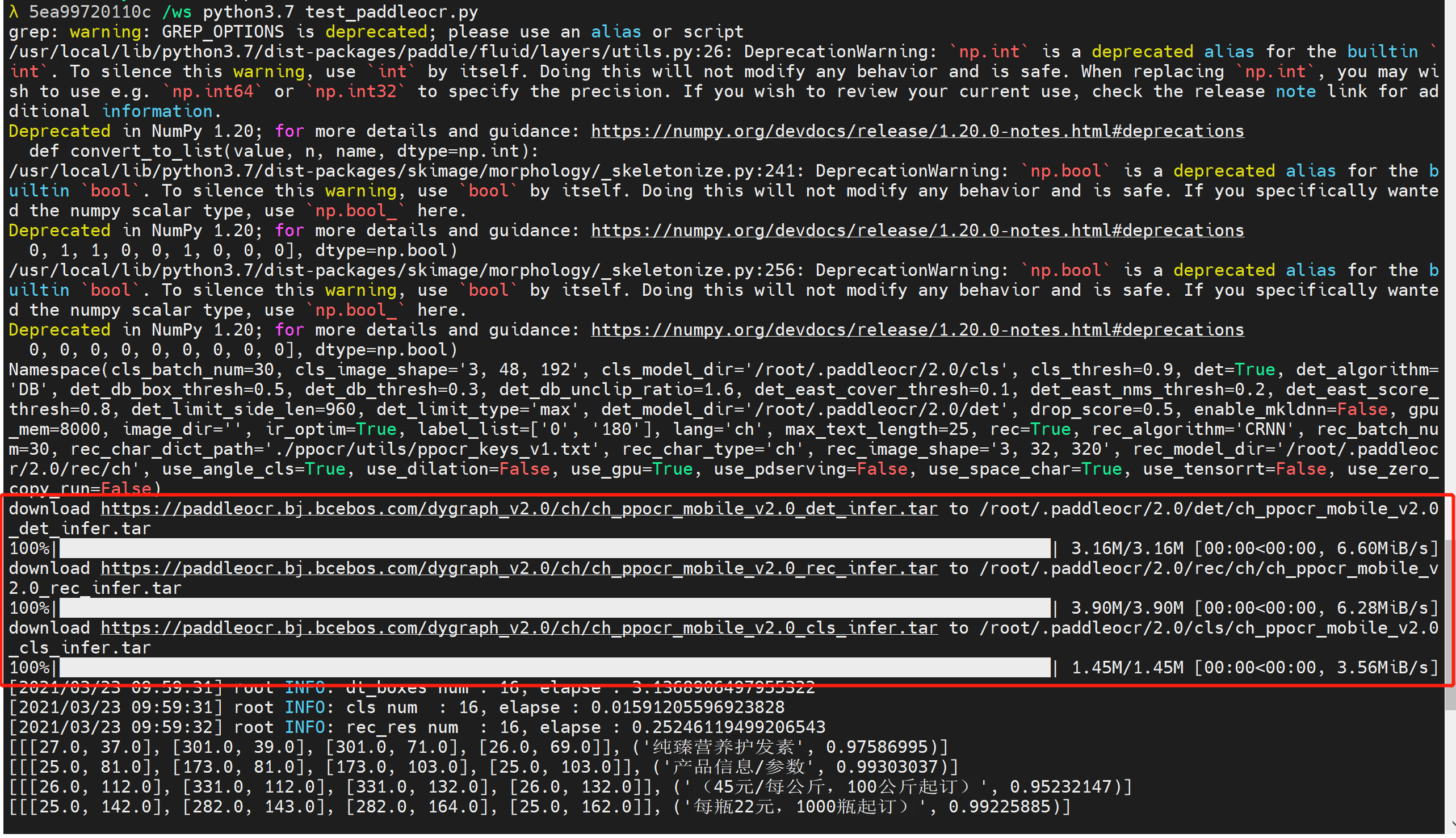
可用模型的说明文档:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.0/doc/doc_ch/algorithm_overview.md















 8281
8281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











