







 本文深入探讨了图数据库在金融反欺诈分析中的应用,包括识别共享个人身份信息的客户群体、使用社区检测算法(如弱连接组件)识别欺诈模式,以及通过度中心性计算欺诈分数。此外,还介绍了如何使用GDS库进行图数据科学操作,如节点相似度计算和交易网络可视化,以提高欺诈检测的准确性。
本文深入探讨了图数据库在金融反欺诈分析中的应用,包括识别共享个人身份信息的客户群体、使用社区检测算法(如弱连接组件)识别欺诈模式,以及通过度中心性计算欺诈分数。此外,还介绍了如何使用GDS库进行图数据科学操作,如节点相似度计算和交易网络可视化,以提高欺诈检测的准确性。
文章目录
0 示例图数据库说明
0.0 大纲
首先要了解这个数据库的模式,边和关系等的规定。

其实对应于github中fraud-detection/documentation/fraud-detection.neo4j-browser-guide这个项目,但是格式像html又不是html,所以只能使用这个desktop打开。

谷歌翻译:
- 示例GDS工作流演示了图形数据科学在金融领域的应用。本浏览器指南包含密码代码片段和每张幻灯片中的简要说明,以帮助进行实践练习。
- 我们将使用GDS库让您了解第一方和合成身份欺诈检测和调查中的一些场景。
- 本播放指南中有四个模块
- 问题定义
- 初步数据分析
- 第一方欺诈
- 第二方欺诈
自己打开看看,这里只摘录我认为有用的部分
想要进一步了解,可以参考博客:Simulating Mobile Money Fraud 🤑 (PaySim pt.1),对图数据库不是很熟悉的,可以参考我对这篇博客的翻译,链接在这里
0.1 概念说明
这些都是外国金融机构反欺诈的说法,和国内银行反欺诈还是很不同的。
first-party fraud
- 所谓的first-party fraud是指欺诈主体就是犯罪分子自己,没有第三方受害者,犯罪分子会用虚假的信息来伪装成好人然后获取信用。在美国,曾经很常用的一种first-party fraud手段是虚假信息养号。
- 美国的银行调用传统征信机构数据时,如果能发现某个人的信用记录,那就会默认这个人存在。犯罪分子会利用这一点,先制造多个假的名字和身份去申请信用贷款或成为主账号的授权用户,初期他们很可能会被拒绝,但这些假的身份信息已经被记录在案,而且他的信用等级也有可能会随着时间的推移而逐渐好转。接下来,他可能会去申请一些小额的次级信贷,比如抵押300美元,获得500美元的贷款,如果他表现良好,信用等级会进一步提高。在把账号逐渐养肥了以后,这些犯罪分子会申请高额度的贷款然后跑路。
Second-party fraud
- 一个人故意将他们的身份或个人信息提供给另一个人以进行欺诈或代表他们实施欺诈。
third-party fraud
- third-party fraud是指犯罪分子将自己伪装成别人来欺诈,也就是盗用别人的信用身份。
- 在国外最猖獗的一种欺诈方式是交易欺诈,比如说信用卡盗用。国外的信用卡非常普及,犯罪分子可能会利用黑客技术去盗用信息复制卡片,然后刷卡跑路。这种诈骗的危险性很高,如果你不在交易当时就阻止他,之后就很难追回被欺诈的钱款。这种欺诈在国内也有过相关的记录,但数量比较少。
参考:
1 初步数据分析
这个图数据库是基于Paysim数据集,这是一个合成的模拟交易数据集。主要分析以下内容:
- Database Schema:数据库模式,
CALL db.schema.visualization(); - Stats:统计数据,
CALL apoc.meta.stats(); - Node Labels:节点标签
- Relationship Types:关系类型
- Nodes & Relationship Properties:节点和关系属性
- Transaction Types:交易类型
1.1 查看数据库模式
neo4j$ CALL db.schema.visualization();
neo4j$ :dbs
# 列出当前用户可以使用的所有数据库
neo4j$ :use neo4j
# 使用neo4j作为目标数据库
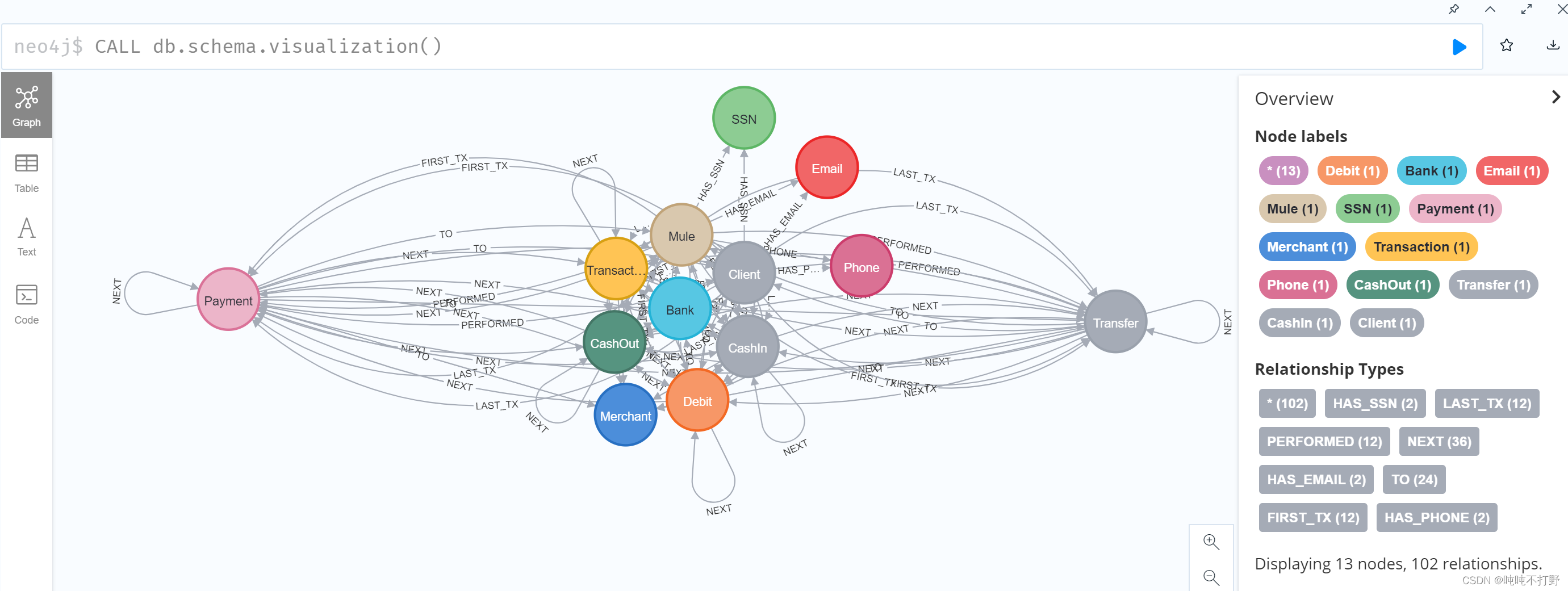
就可以看到这个数据集模式的情况了,主要就是节点和关系,还可以拉大点看。
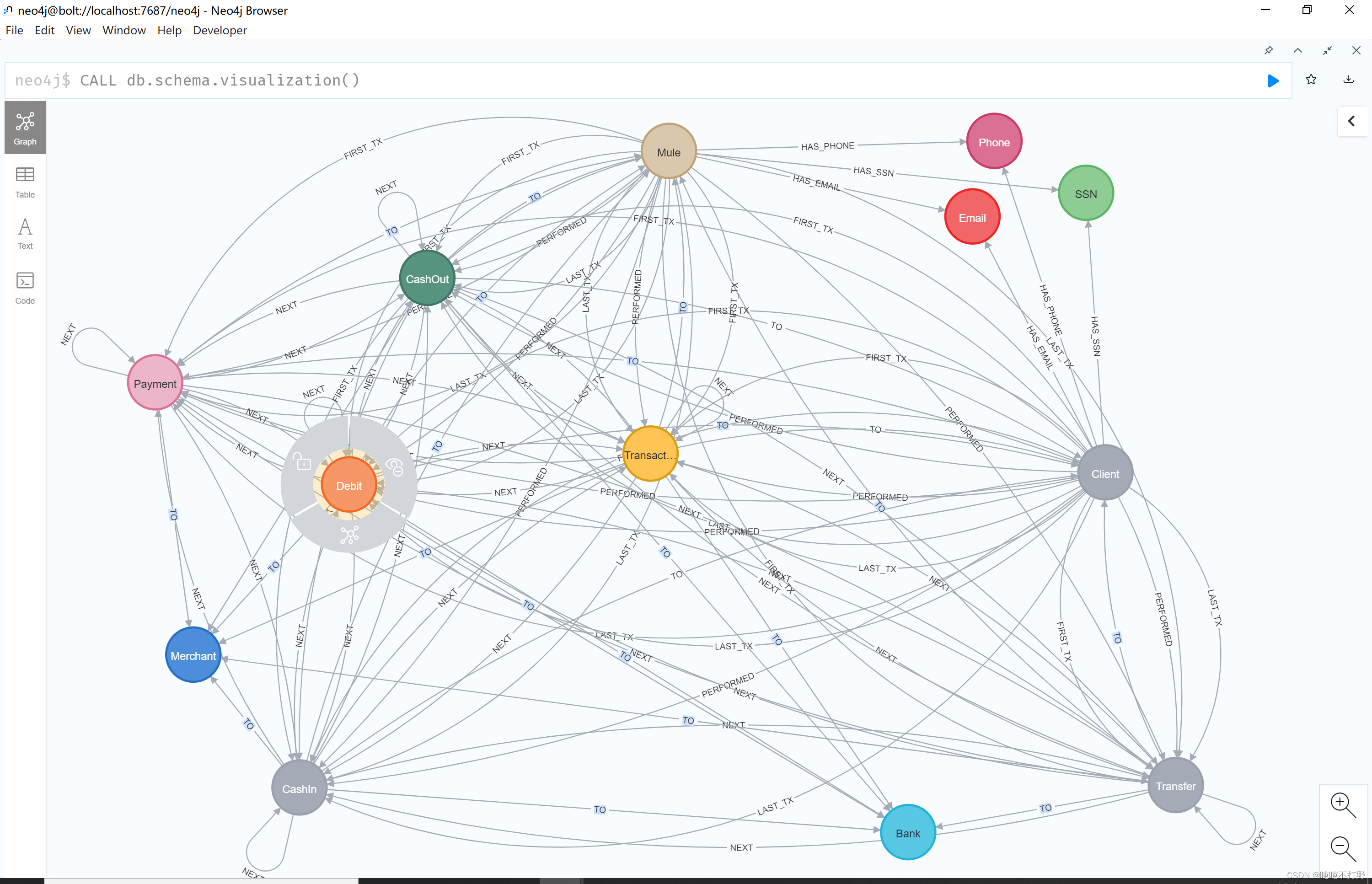
这个可视化挺好的。
1.2 统计数据
注意,想要运行以下还有APOC的语句,必须先安装APOC插件
neo4j$ CALL apoc.meta.stats();
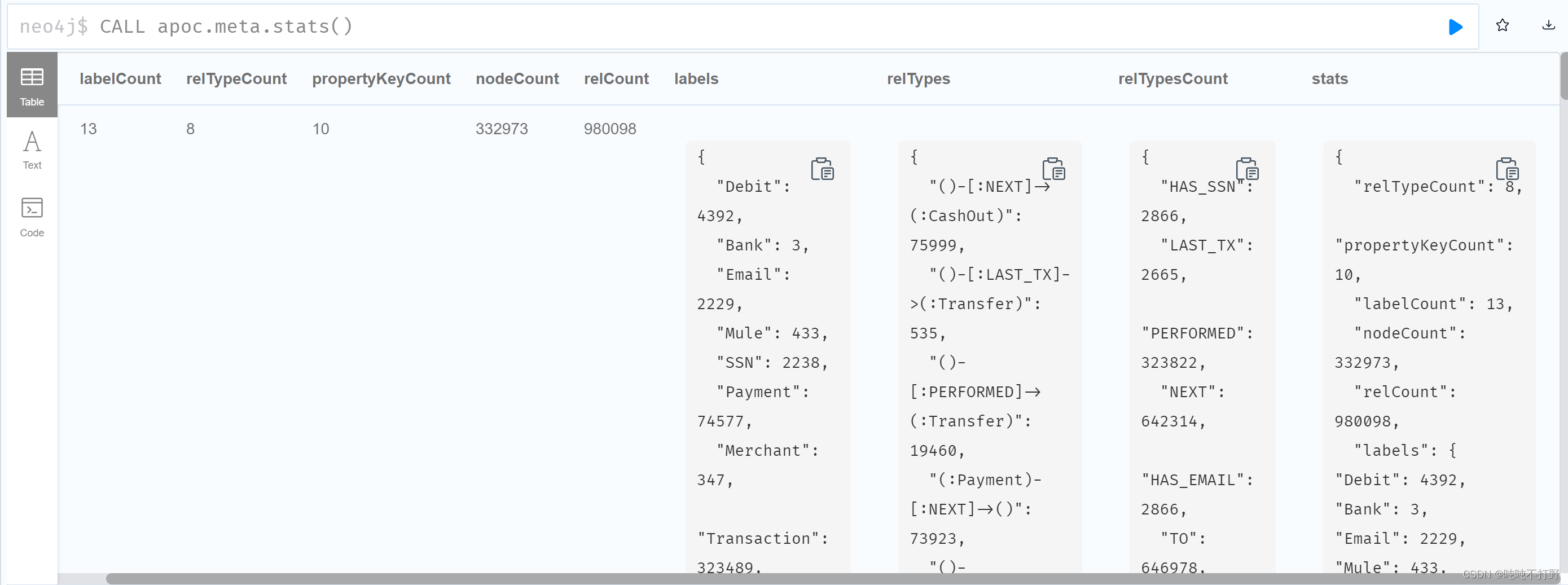
这个输出的分析结果,就类似pandas的df.description()的感觉,就是数据统计。。
1.3. 节点标签
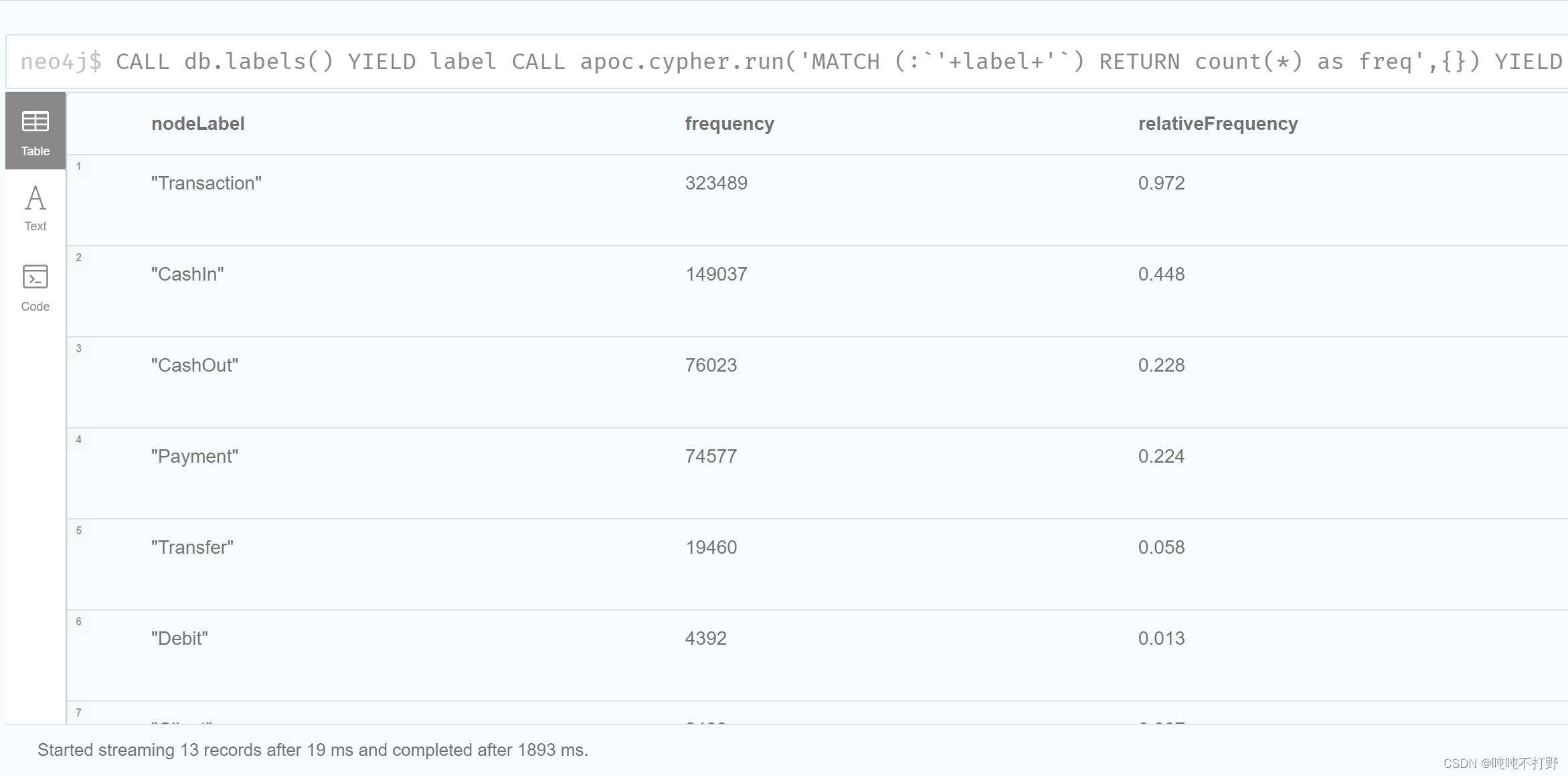
列出所有节点标签和相应的频率。是通过迭代数据库中的所有节点标签并计算频率和相对频率来完成的。
CALL db.labels() YIELD label
CALL apoc.cypher.run('MATCH (:`'+label+'`) RETURN count(*) as freq',{})
YIELD value
WITH label,value.freq AS freq
CALL apoc.meta.stats() YIELD nodeCount
WITH *,3 AS presicion
WITH *,10^presicion AS factor,toFloat(freq)/toFloat(nodeCount) AS relFreq
RETURN label AS nodeLabel, freq AS frequency,round(relFreq*factor)/factor AS relativeFrequency
ORDER BY freq DESC
1.4.关系类型
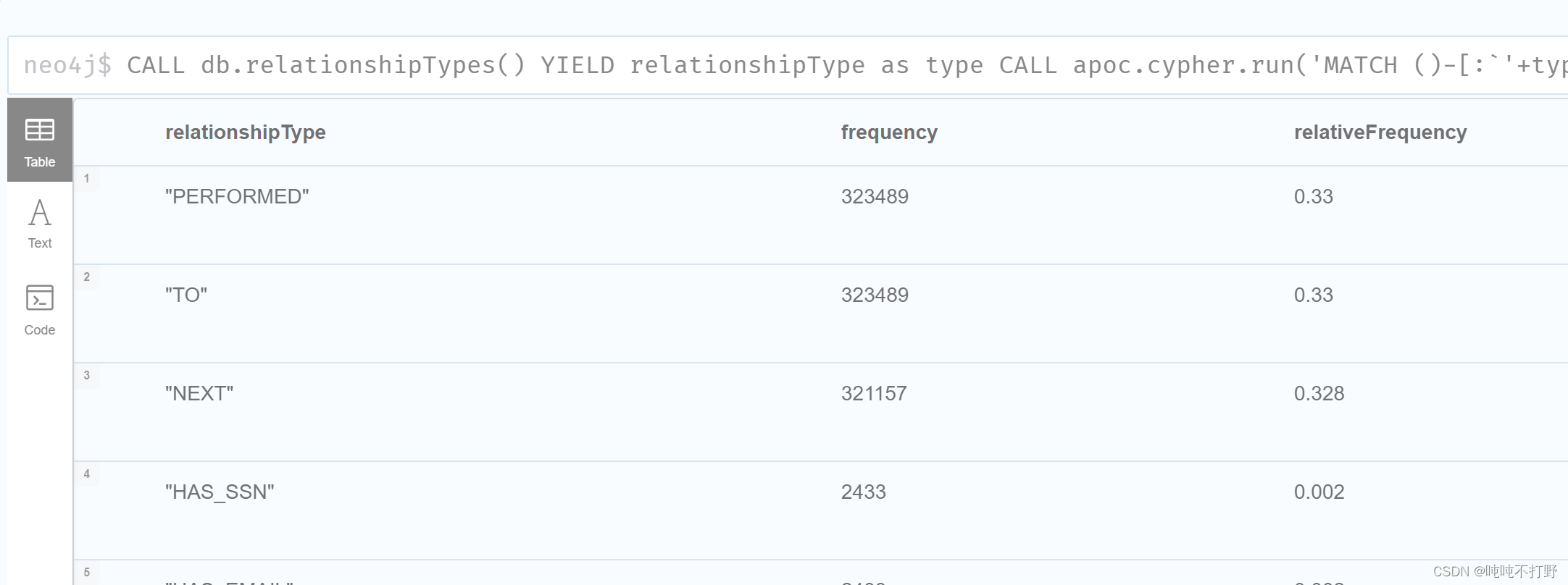
列出所有的关系类型和对应的频率。 这是通过迭代数据库中的所有关系类型并计算频率和相对频率来完成的。
CALL db.relationshipTypes() YIELD relationshipType as type
CALL apoc.cypher.run('MATCH ()-[:`'+type+'`]->() RETURN count(*) as freq',{})
YIELD value
WITH type AS relationshipType, value.freq AS freq
CALL apoc.meta.stats() YIELD relCount
WITH *,3 AS presicion
WITH *, 10^presicion AS factor,toFloat(freq)/toFloat(relCount) as relFreq
RETURN relationshipType, freq AS frequency,round(relFreq*factor)/factor AS relativeFrequency
ORDER BY freq DESC;
1.5.节点和关系属性
列出所有的节点和关系属性
CALL apoc.meta.data() YIELD label,property,type,elementType
WHERE type<>'RELATIONSHIP'
RETURN elementType,label,property,type
ORDER BY elementType,label,property;

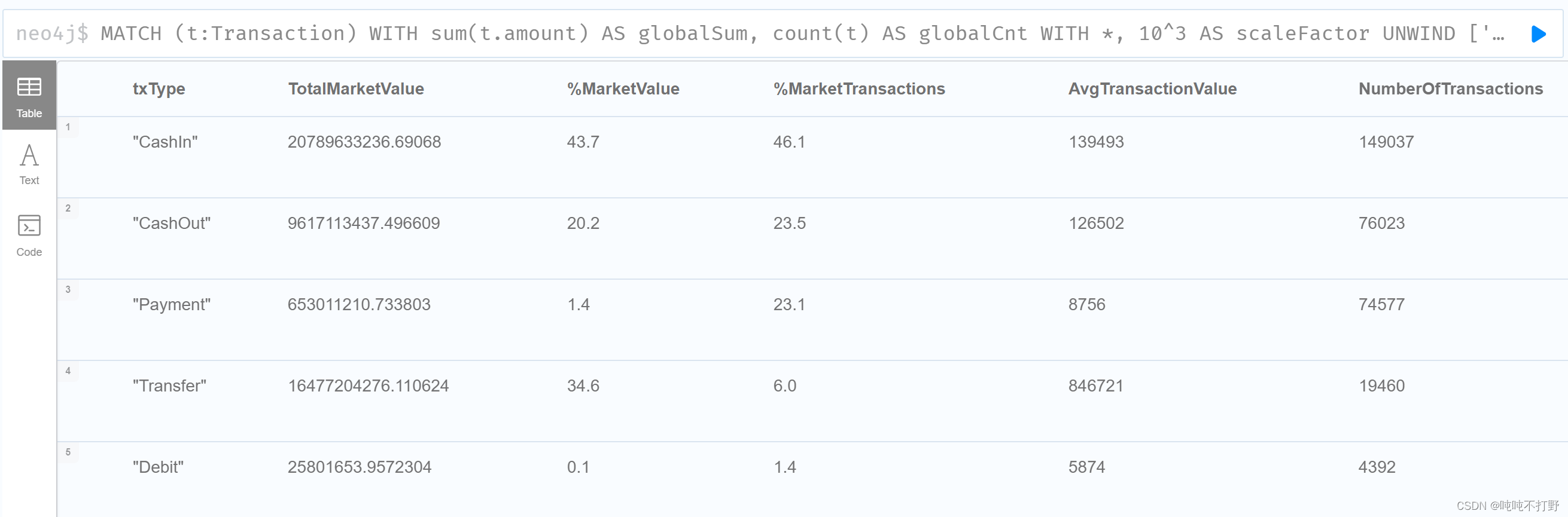
1.6.交易(事务)类型
该数据库中有五种类型的事务。 通过迭代所有交易类型的所有交易,列出所有交易类型和相应的指标,如总市值、相对市值、交易数量等。
MATCH (t:Transaction)
WITH sum(t.amount) AS globalSum, count(t) AS globalCnt
WITH *, 10^3 AS scaleFactor
UNWIND ['CashIn', 'CashOut', 'Payment', 'Debit', 'Transfer'] AS txType
CALL apoc.cypher.run('MATCH (t:' + txType + ')
RETURN sum(t.amount) as txAmount, count(t) AS txCnt', {})
YIELD value
RETURN txType,value.txAmount AS TotalMarketValue,
100*round(scaleFactor*(toFloat(value.txAmount)/toFloat(globalSum)))
/scaleFactor AS `%MarketValue`,
100*round(scaleFactor*(toFloat(value.txCnt)/toFloat(globalCnt)))
/scaleFactor AS `%MarketTransactions`,
toInteger(toFloat(value.txAmount)/toFloat(value.txCnt)) AS AvgTransactionValue,
value.txCnt AS NumberOfTransactions
ORDER BY `%MarketTransactions` DESC;
1.7 总结
至此,探索了 PaySim 数据集并收集了一些统计数据:
数据库架构和大小
节点标签和关系类型分布
节点和关系属性
交易类型分布
2 first-party fraud
2.0 包含内容
所以接下来会基于这个数据集进行以下内容的发现:
- 识别共享个人身份信息 (PII) 的客户
- 使用社区检测算法(弱连接组件)识别共享 PII 的客户端集群
- 使用成对相似性算法(节点相似性)基于共享标识符在集群内寻找相似的客户端
- 使用中心性算法(度中心性)为集群中的客户计算和分配欺诈分数
- 使用指定的欺诈分数将客户标记为潜在欺诈者
2.1 识别共享个人身份信息的客户
PII(personally identifiable information)
主要通过判断两个客户/信用卡的邮箱,手机号码以及身份证号,三者里是不是有一个相同,有就说明是一个人。
科普
SSN英文全称Social Security number,即社会保障号码,是美国联邦政府发给本国公民、永久居民或临时(工作)居民的一组九位数字号码。简单来说美国的SSN就相当于中国身份证的一种,但在美国这张小小的纸片却作用非凡
2.1.1 找到共享PII的客户
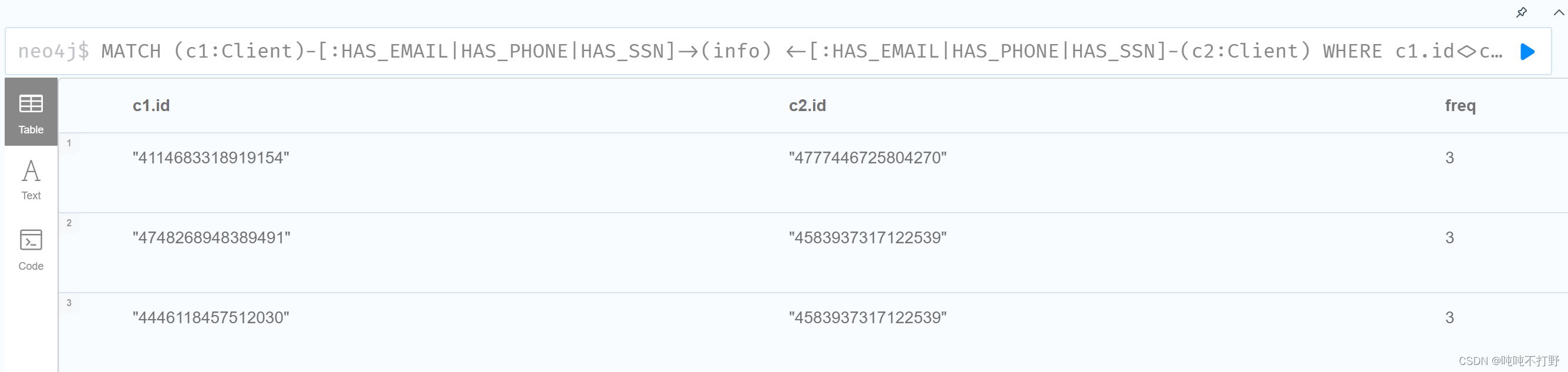
首先需要找到这些共享身份信息的客户
# 找到身份信息相同的 客户对
MATCH (c1:Client)-[:HAS_EMAIL|HAS_PHONE|HAS_SSN]->(info)
<-[:HAS_EMAIL|HAS_PHONE|HAS_SSN]-(c2:Client)
WHERE c1.id<>c2.id
RETURN c1.id,c2.id,count(*) AS freq ORDER BY freq DESC;
执行结果如下:
# 有共享身份信息的 客户的数量
MATCH (c1:Client)-[:HAS_EMAIL|HAS_PHONE|HAS_SSN]->(info)
<-[:HAS_EMAIL|HAS_PHONE|HAS_SSN]-(c2:Client)
WHERE c1.id<>c2.id
RETURN count(DISTINCT c1.id) AS freq;
执行结果如下:
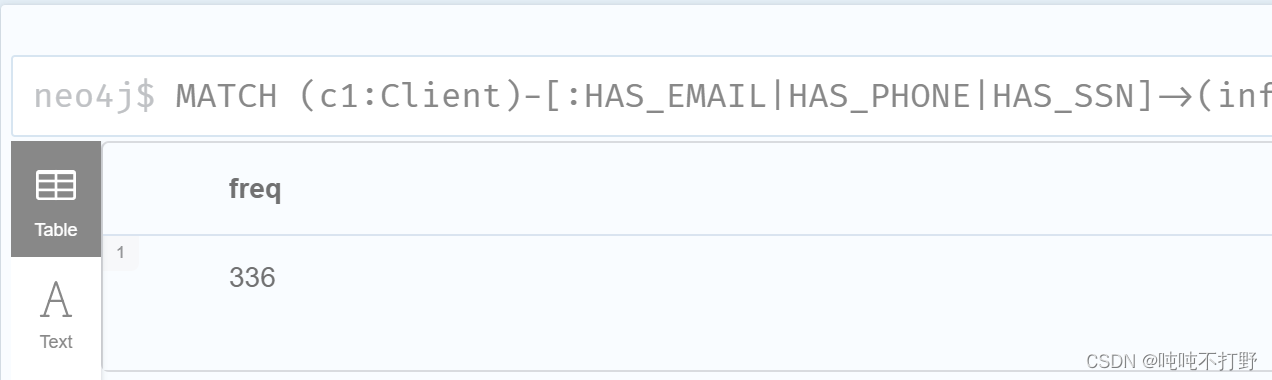
2.1.2 创建新的关系连接
然后对这些共享身份信息的客户新建一个关系(连接),同时对这个连接添加一个共享身份信息的个数的属性
MATCH (c1:Client)-[:HAS_EMAIL|HAS_PHONE|HAS_SSN]->(info)
<-[:HAS_EMAIL|HAS_PHONE|HAS_SSN]-(c2:Client)
WHERE c1.id<>c2.id
WITH c1, c2, count(*) as cnt
# 这句就是加了一个连接,同时给了个属性
MERGE (c1) - [:SHARED_IDENTIFIERS {count: cnt}] - (c2);
# 可视化刚刚创建的连接,一定要先执行上句,不然这句看不到东西
MATCH p = (c:Client) - [s:SHARED_IDENTIFIERS] - () WHERE s.count >= 2 RETURN p limit 25;
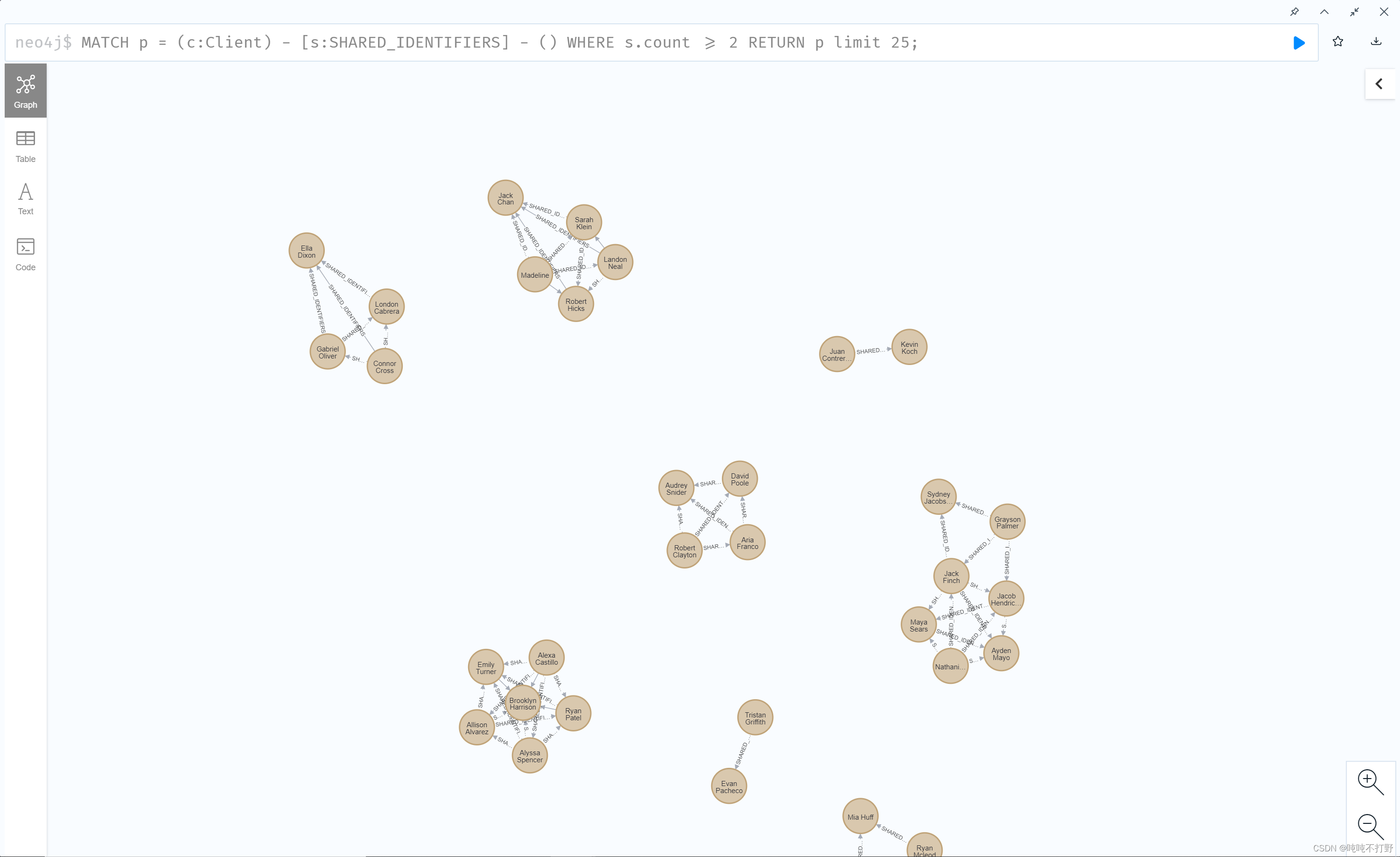
放大其中的几个,其实可以看出

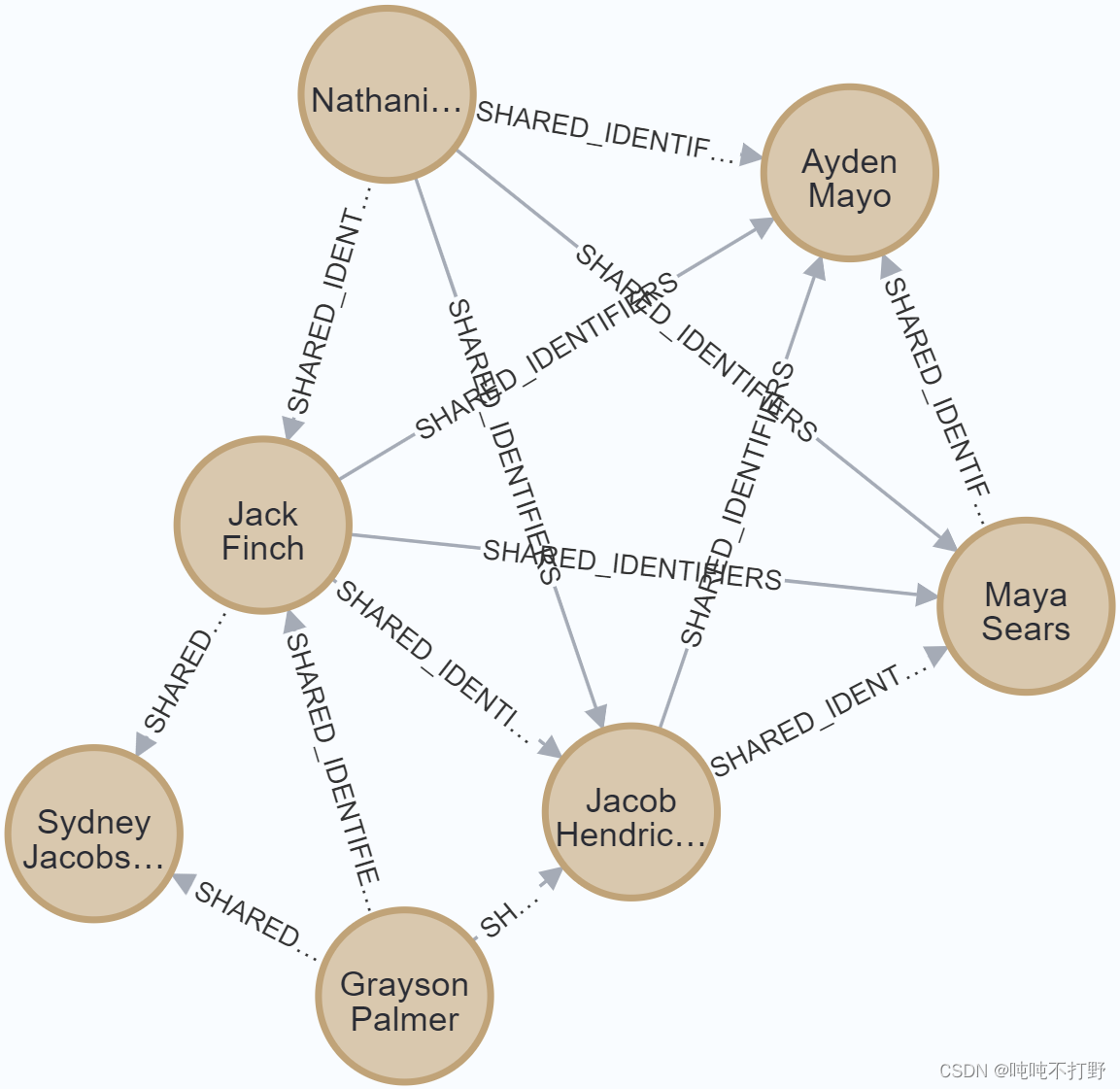
判断条件是邮箱、手机号、SNN号有一个相同就可以。好像也有点道理,这么判断。
2.2 使用社区检测算法识别共享 PII 的客户群
- 使用neo4j中的GDS库中自带的社区检测算法,来识别共享身份信息的客户群(其实上面画出来的一小群也可以认为是一个客户群)。
- 使用弱连通组件(Weakly Connected Components)来发现相连节点的群组, 在同一个集合中的点构成一个连通组件。WCC通常在分析的早期使用,用来理解图的结构。
- 下面的练习,会将图变成适合于WCC处理的形状,使用图的catalog函数来将图加载到内存中,进而执行图算法。
关于GDS,如果没有安装可以参考本文章第三部分的说明。下面的内容基本都依赖于GDS中带有的算法。需要提前安装
2.2.0. 确定使用图中哪部分数据
- 在执行算法之前,第一步是要考虑输入图的形状。然后,需要reshape图使得其满足算法的要求,这样才能得到有意义的结果。
- 使用社区发现算法来发现用户社区/簇/集群
- 社区检测算法要求输入是单部图(节点都是一个类型,节点之间的关系也都是一个关系)。因此,我们需要把图映射到内存中,同时只需要使用图中的client节点和与这些节点相连的关系。
- 关于图的操作和映射相关的操作的目录,参考:Graph Catalog
2.2.1. 容量估计
- 在创建图之前,最好先检查运行一下内存评估(创建这样的图需要使用多少内存),确保有足够的内存可以创建一个内存中的图。
- 关于内存评估,还可以参考neo4j文档:Estimating memory requirements for graphs
CALL gds.graph.create.cypher.estimate( 'MATCH (c:Client) RETURN id(c) AS id', 'MATCH (c1:Client)-[r:SHARED_IDENTIFIERS]-(c2:Client) WHERE c1.id<>c2.id RETURN id(c1) AS source,id(c2) AS target,r.count AS weight') YIELD requiredMemory,nodeCount,relationshipCount;
- 另外,也可以列出早就已经加载到内存中的图的列表,及时把不用的图移除。
CALL gds.graph.list(); # 从内存中移除一个名为XXX的图 CALL gds.graph.drop('name-of-your-graph');
2.2.2. 图映射
- 从原始图映射,获得wcc算法需要的那部分,主要是client节点及和这个节点有关的连接。
- 使用原生映射从原始图获取要输入WCC算法的单部图,这里使用
WCC作为演示wcc算法的映射后的图的名称 - 关于naive projection,可以参考neo4j文档:Creating graphs
CALL gds.graph.create('WCC', 'Client', { SHARED_IDENTIFIERS:{ type: 'SHARED_IDENTIFIERS', properties: { count: { property: 'count' } } } } ) YIELD graphName,nodeCount,relationshipCount,createMillis;
2.2.3. 预先检查
- 运行算法之前评估一下,算法运行这个图需要的内存(刚刚是单纯的图数据的内存,这里考虑的是算法运行这个图需要的全部的内存,算法+每次计算从图中拿的数据)
- 关于内存估计,可以看neo4j文档:1. Estimating memory requirements for algorithms
CALL gds.wcc.stream.estimate('WCC');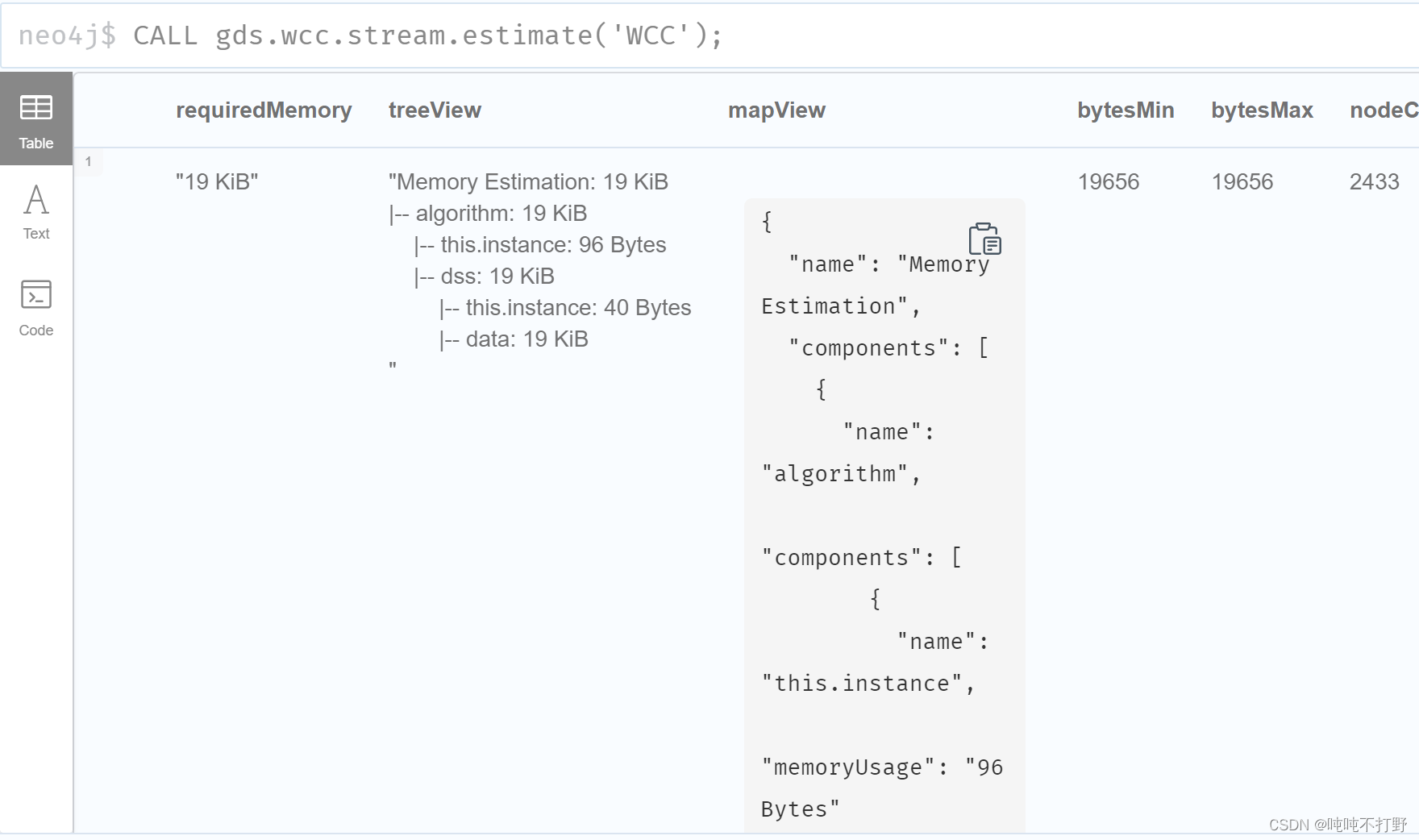
- 先观察统计信息,以判断结果是否有意义是一个好习惯。比如:如果图中没有关系,那么最后找到的簇/集群的数量就等于节点的数量。如果每个节点都是向量的,那么就会产生一个很大的簇。如果是这样的图,那么运行WCC是没有意义的。
CALL gds.wcc.stats('WCC');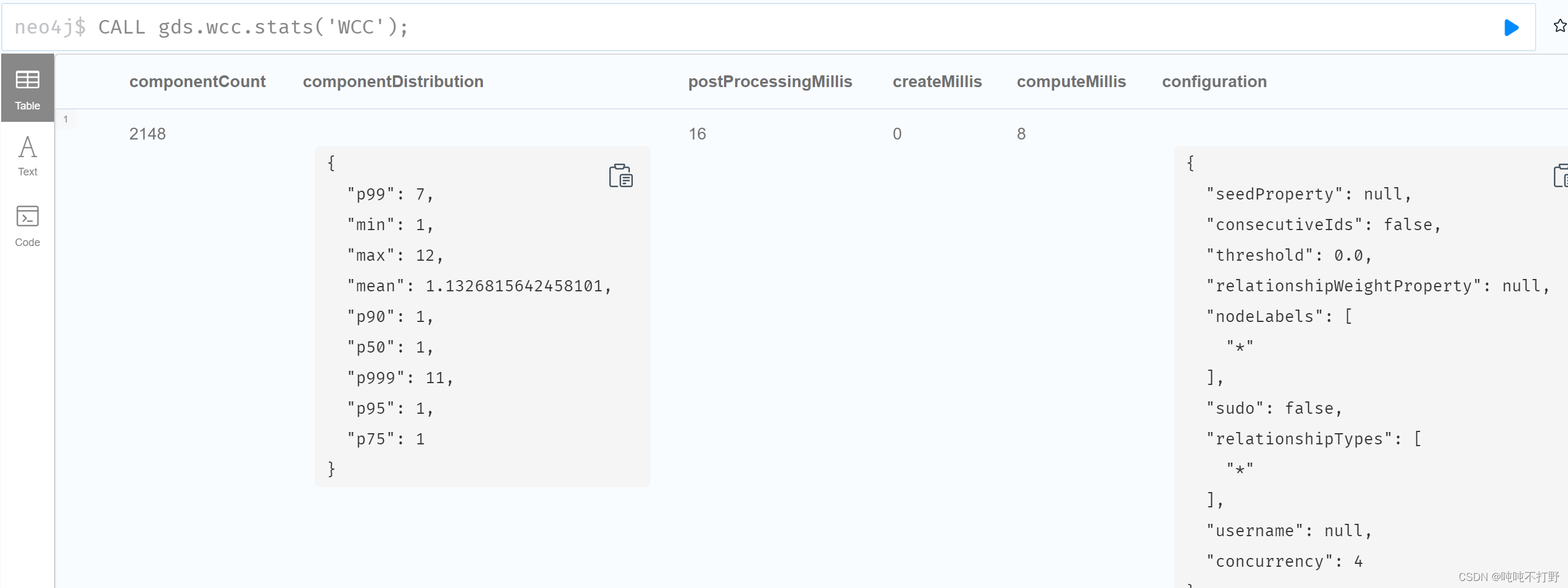
- 关于这个统计信息的说明,参考:3.3. Stats
- 其中,这些指标需要理解一下,根据相似度算法在知识图谱中的实现和NEO4J-相似度算法05-重叠相似度算法应用场景简介,这些其实都属于相似度算法里的指标,neo4j的文档在Overlap Similarity,详细信息写在3.3 相似度算法评估指标
举几个例子说一下,都代表什么意义
- min:计算出的相似度的最小值
- max:计算出的相似度的最大值
这里的相似度指的是两个集合的重叠相似度,所以这个stats其实已经跑了一遍结果,然后对结果进行了统计。
这个
stats是wcc算法的一个方法,点击这里,主要作用就是返回计算的数量或者百分比这类的统计信息。使用 stats 模式时,算法的直接结果不可用。 此模式构成了 mutate 和 write 执行模式的基础,但不会尝试在任何地方进行任何修改或更新。
所以这个模式比较特殊,相当于预先跑一遍,有问题就提前发现,不用等到后面正式跑的时候才发现问题。
2.2.4. (stream 流模式)运行WCC算法
图数据准备好,检查过图数据的统计信息,以及图数据和算法的内存,准备工作结束,才能开始运行。。。
Stream mode(流模式),详细说明在这里
- 执行WCC算法,stream的结果返回到浏览器中
- 结果不会被写到数据库中
(流模式将算法计算的结果作为 Cypher 结果行返回。 这类似于标准 Cypher 读取查询的操作方式。
返回的数据可以是节点 ID 和节点的计算值(例如 Page Rank 分数或 WCC componentId),或者两个节点 ID 和节点对的计算值(例如节点相似度相似度分数)。
如果图很大,流模式计算的结果也会很大。 在 Cypher 查询中使用 ORDER BY 和 LIMIT 子句可能有助于支持“top N”样式的用例。)
CALL gds.wcc.stream('WCC')
YIELD componentId,nodeId
# 产生组件ID,nodeID
WITH componentId AS cluster,gds.util.asNode(nodeId) AS client
# 组件ID(弱连通图)作为集群/簇 nodeID对应的就是clint的编号
WITH cluster,collect(client.id) AS clients
WITH *,size(clients) AS clusterSize
WHERE clusterSize>1
# 对簇/集群数量>1的 进行返回
RETURN cluster,clusterSize,clients
ORDER by clusterSize DESC;
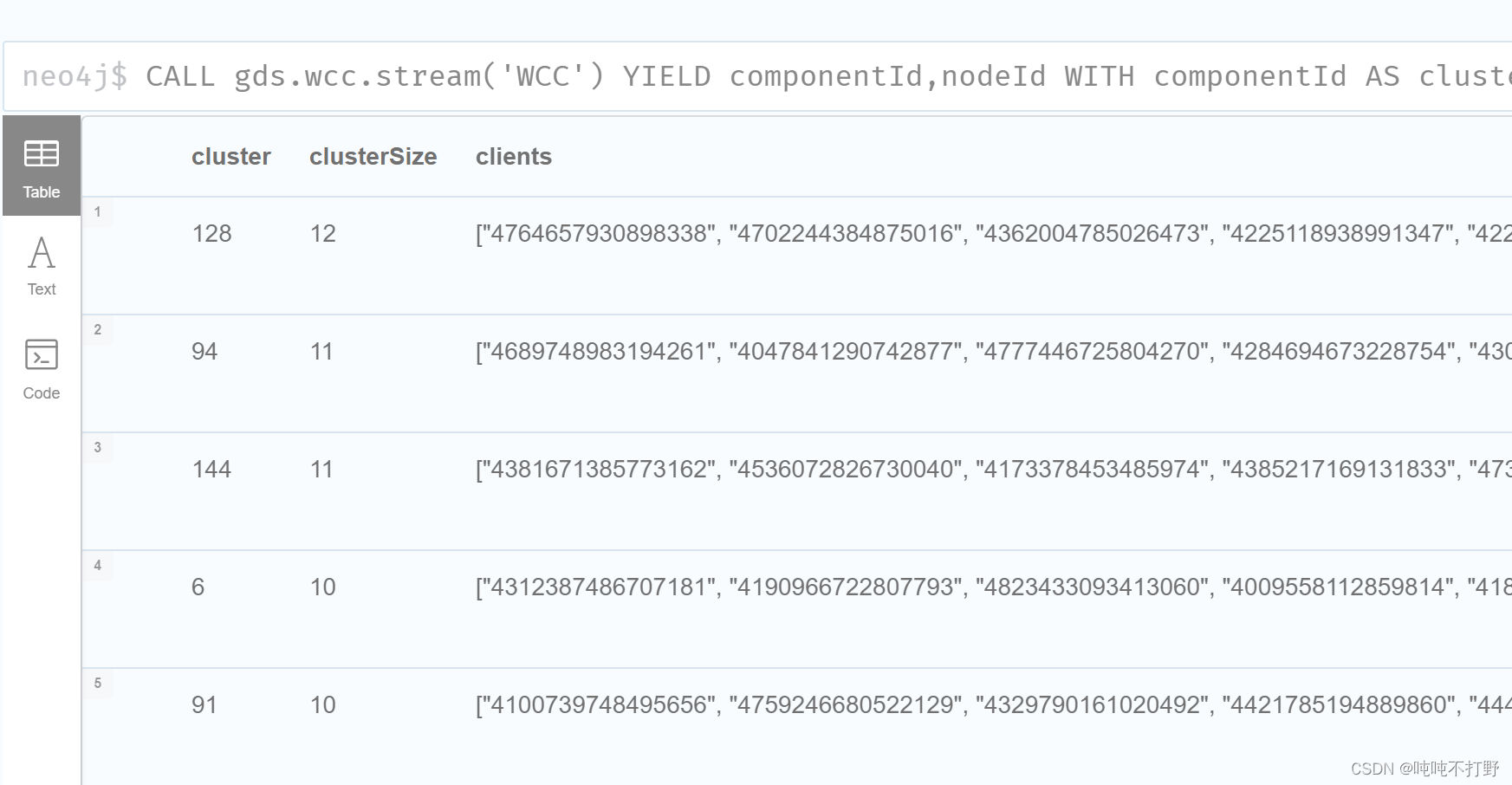
第一行表示:发现的第128个集群,集群规模是12(有12个client),后面的clients是属于这个集群的客户的ID数值。
可视化会在后面进行,继续看,不要着急。
2.2.5. 将结果写入数据库
- 写入模式可以让我们把结果写会到数据库中
- 不过这里不使用写模式,使用Cypher过滤出规模大于1的集群,同时在Clients节点上设置一个合适的属性。
CALL gds.wcc.stream('WCC') YIELD componentId,nodeId WITH componentId AS cluster,gds.util.asNode(nodeId) AS client WITH cluster, collect(client.id) AS clients WITH *,size(clients) AS clusterSize WHERE clusterSize>1 UNWIND clients AS client MATCH(c:Client) WHERE c.id=client SET c.firstPartyFraudGroup=cluster; # 对删选出的属于一个集群的id增加一个属性
2.2.6. 收集并可视化集群
- 可视化共享信息的clients的集群
MATCH (c:Client)
WITH c.firstPartyFraudGroup AS fpGroupID, collect(c.id) AS fGroup
WITH *, size(fGroup) AS groupSize WHERE groupSize >= 9
WITH collect(fpGroupID) AS fraudRings
MATCH p=(c:Client)-[:HAS_SSN|HAS_EMAIL|HAS_PHONE]->()
WHERE c.firstPartyFraudGroup IN fraudRings
RETURN p
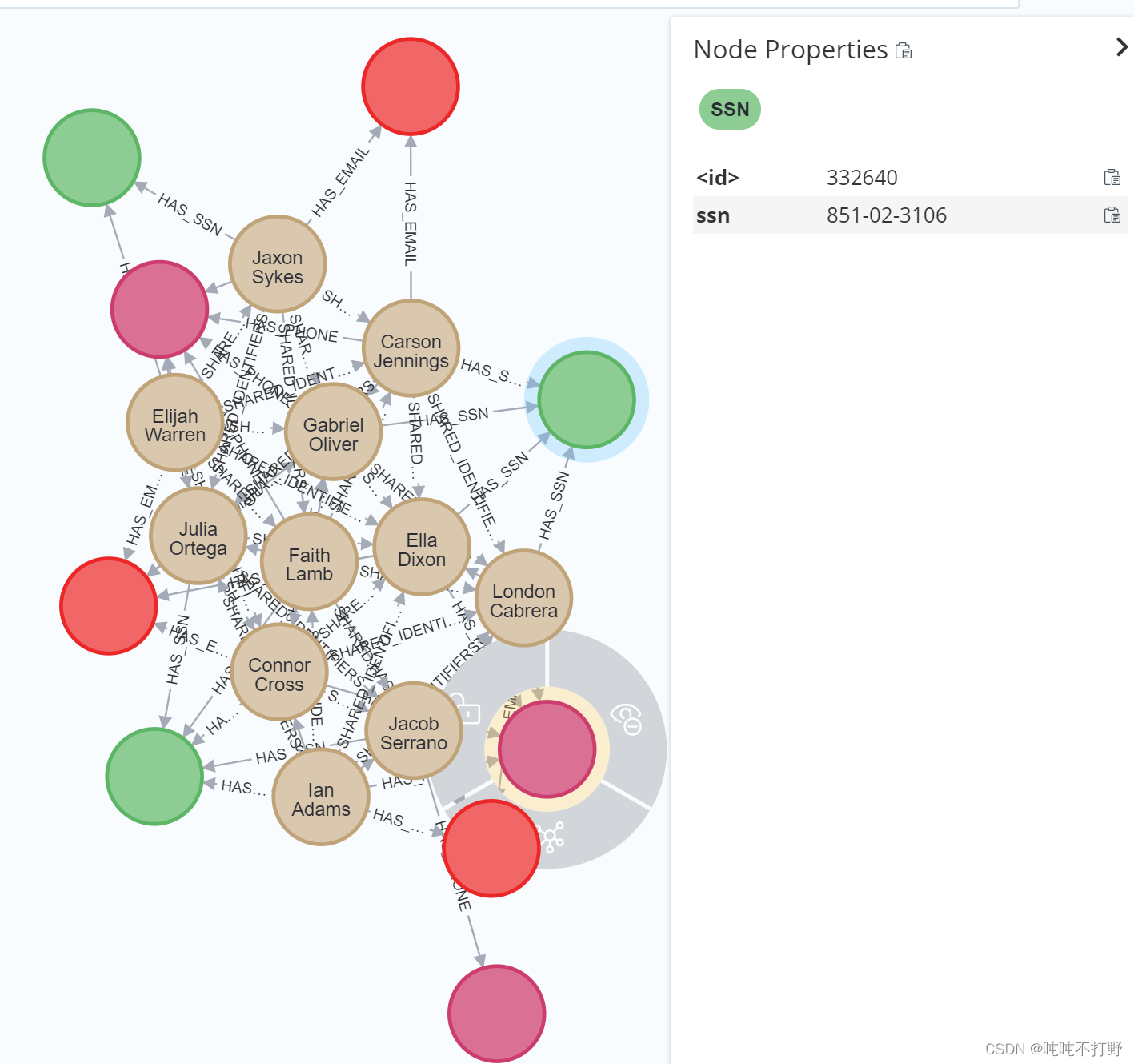
那些没有字的圈圈,表示指向它的用户一样的属性,比如SSN,phone或者mail。
2.3 识别与共享PII客户相似的客户
使用上面得到的簇信息,来发现相似的客户
- 使用GDS库中任意一个 paiwrise similarity 算法,来找到一个集群中相似的用户
- 将节点和其他节点的关系作为节点相似度的评判标准。使用Jaccard指标计算两个节点相似度,Jaccard是通过查看网络中与这两个节点都相关的节点的数量,除以与这两个节点相关的节点数量的总和。(就是:交集/并集)
- 关于节点相似度,可以查看Node Similarity
- 节点相似度算法适用于二分部图/二分图(有两种类型的节点,节点之间的关系也有两种。)所以这里我们将client节点(一种类型)和三种身份节点(ssn,phone,mail,作为第二种类型)映射到内存中。有相同身份信息的用户就是相似的( The clients who have these identifiers in common are similar to each other.)
二分图解释:Bipartite graph/network学习
2.3.1. 创建图(映射图)
使用cypher的映射来创建运行相似度算法需要的放入内存中的图。使用Similarity作为运行相似度算法的图的名称。
关于Cypher映射的语法,参考:Cypher projection。
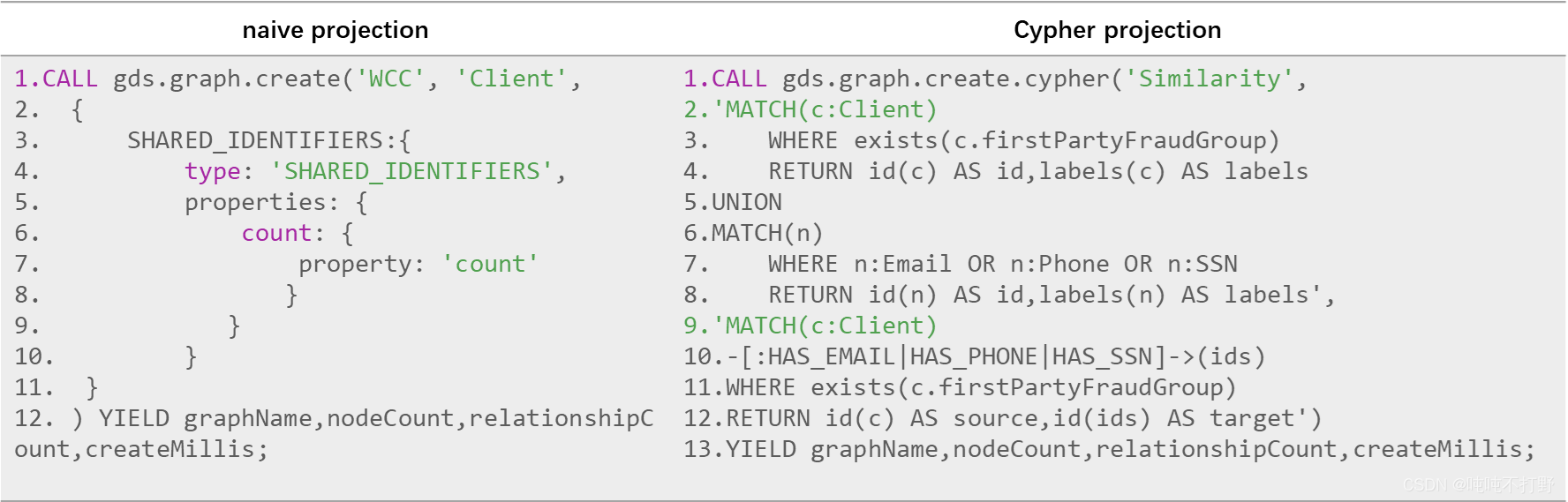
CALL gds.graph.create.cypher('Similarity',
'MATCH(c:Client)
WHERE exists(c.firstPartyFraudGroup)
RETURN id(c) AS id,labels(c) AS labels
UNION
MATCH(n)
WHERE n:Email OR n:Phone OR n:SSN
RETURN id(n) AS id,labels(n) AS labels',
'MATCH(c:Client)
-[:HAS_EMAIL|HAS_PHONE|HAS_SSN]->(ids)
WHERE exists(c.firstPartyFraudGroup)
RETURN id(c) AS source,id(ids) AS target')
YIELD graphName,nodeCount,relationshipCount,createMillis;

- 和
2.2.2 图映射一样,都是从原始的图数据库中抽出一部分,构建一个子图,在子图上进行操作,但是使用的是不同的语法。参考下图,虽然前面都是CALL gds.graph.create,但是很明显,Cypher projection更接近于我们以前使用sql的方式,而那个naive projection看起来有点像取巧的快捷方式/某种语法糖/魔法函数。
2.3.2 使用流模式得到相似度结果
之前在2.2.4中 说过流模式的特征:stream的结果返回到浏览器中;结果不会被写到数据库中。
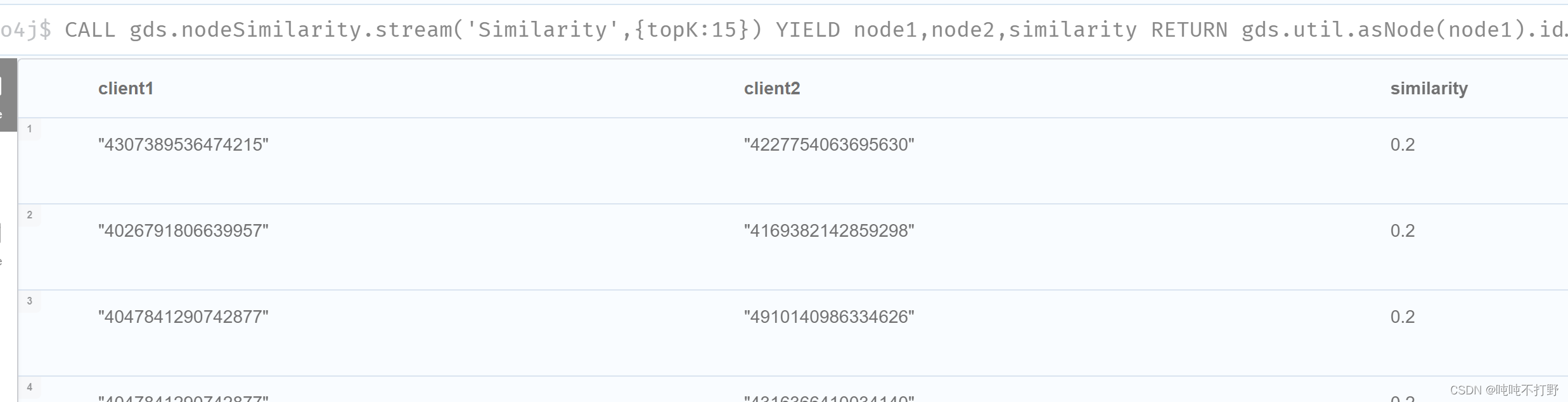
CALL gds.nodeSimilarity.stream('Similarity',{topK:15})
YIELD node1,node2,similarity
RETURN gds.util.asNode(node1).id AS client1,
gds.util.asNode(node2).id AS client2,similarity
ORDER BY similarity;
返回与每个节点最相似的15个节点。
2.3.3 将相似度得分写入映射图中
可以将算法的输出作为节点或边的属性写入内存里的图来改变它
CALL gds.nodeSimilarity.mutate('Similarity',{topK:15,
mutateProperty:'jaccardScore', mutateRelationshipType:'SIMILAR_TO'});
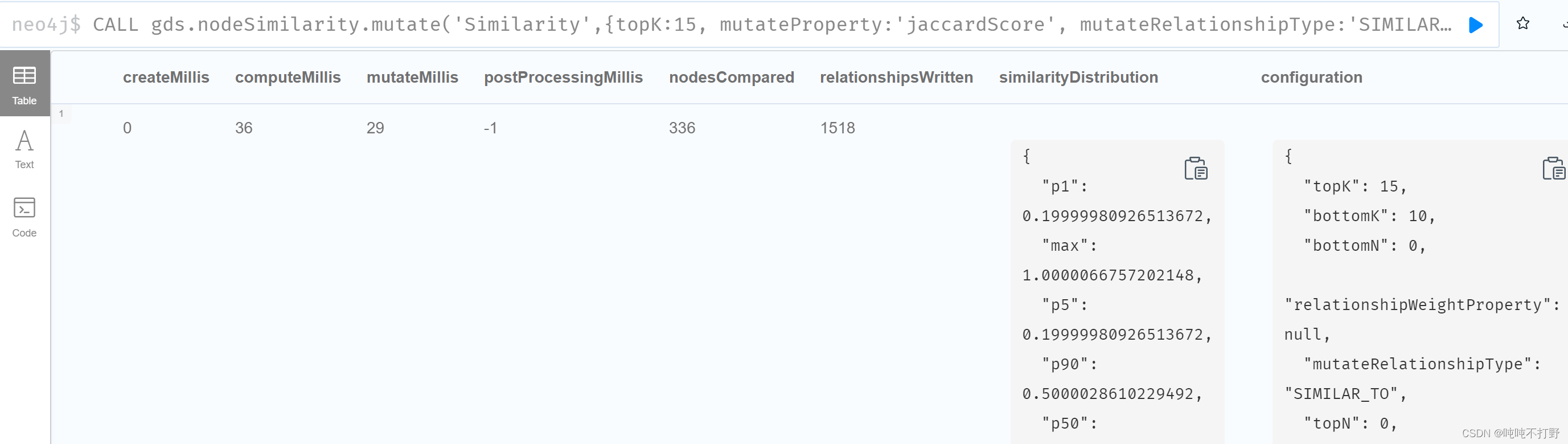
当pipeline中执行不止一个算法的时候,比如pipeline中第一个算法的输出要作为第二个算法的输入时,使用Mutate模式就显得非常有用。Mutate模式相对于write模式很快,同时它会优化算法的执行时间。
2.3.4 把内存里的图写到数据库里
把上一步内存里的图写入到数据库中,基于此再进行分析
CALL gds.graph.writeRelationship('Similarity','SIMILAR_TO','jaccardScore');

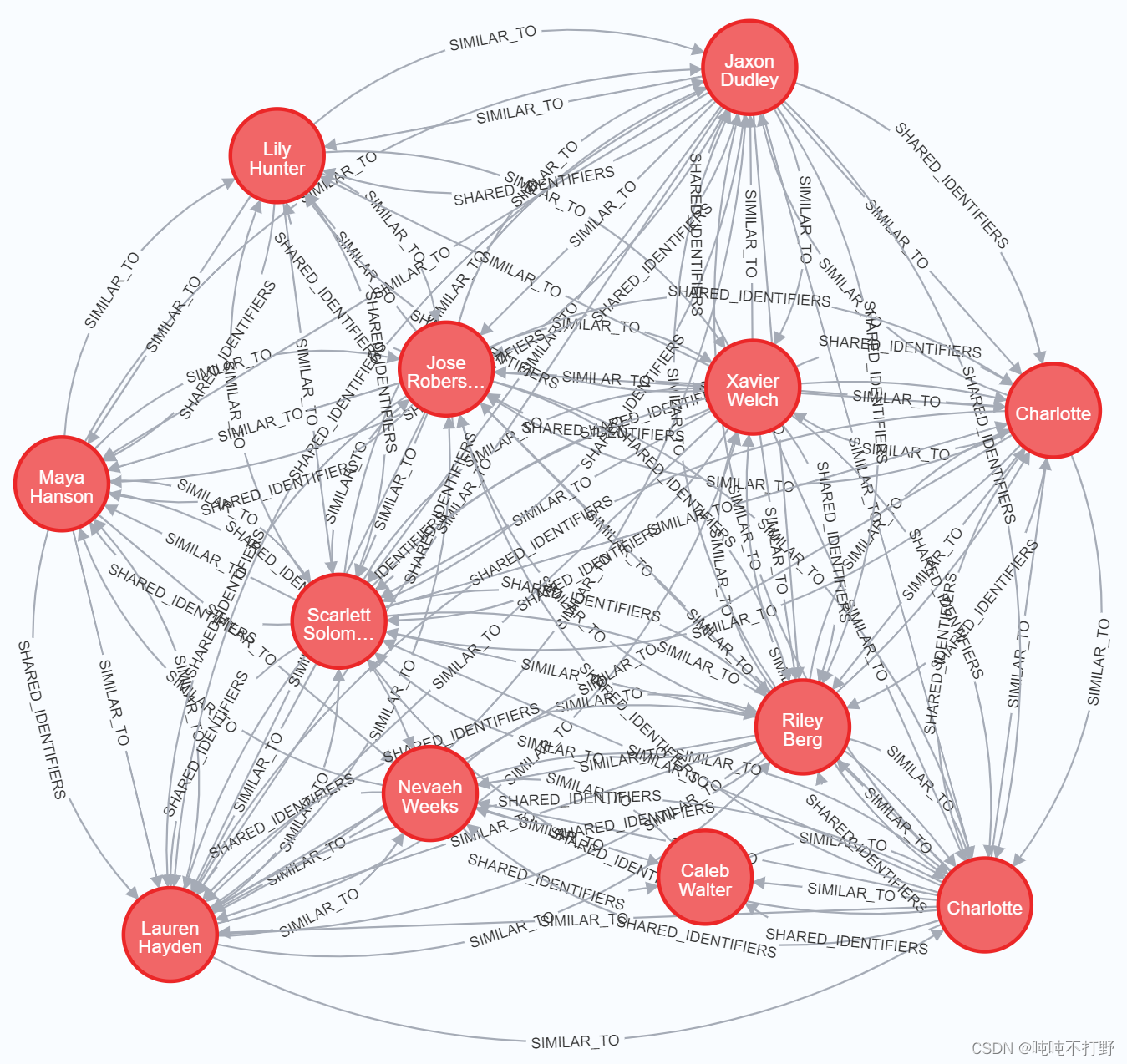
2.3.5 可视化
看一下刚刚创建的SIMILAR_TO关系,还有基于相似度分数的相似clients。
MATCH (c:Client)
WITH c.firstPartyFraudGroup AS fpGroupID, collect(c.id) AS fGroup
WITH *, size(fGroup) AS groupSize WHERE groupSize >= 9
WITH collect(fpGroupID) AS fraudRings
MATCH p=(c:Client)-[:SIMILAR_TO]->()
WHERE c.firstPartyFraudGroup IN fraudRings
RETURN p
2.4 根据度为上面得到的客户分配欺诈分数
使用中心性算法(度中心性)为集群中的客户计算和分配欺诈分数。
- 这里,根据上一步基于由加权过的jaccardScore的
SIMILAR_TO,对上一步确认的集群中的客户计算并分配欺诈得分。 - 使用一种中心算法(度中心性),将集群中一个节点的入度(入关系的节点)和出度(出关系的节点)的jaccardScore相加,将这个和作为对应的
一方欺诈分数。这个分数代表了集群中这个客户和其他客户共享信息的相似程度。 - 这里假设firstPartyFraudScore得分越高,实施欺诈的可能性越高
2.4.1 使用度中心性计算中心分数
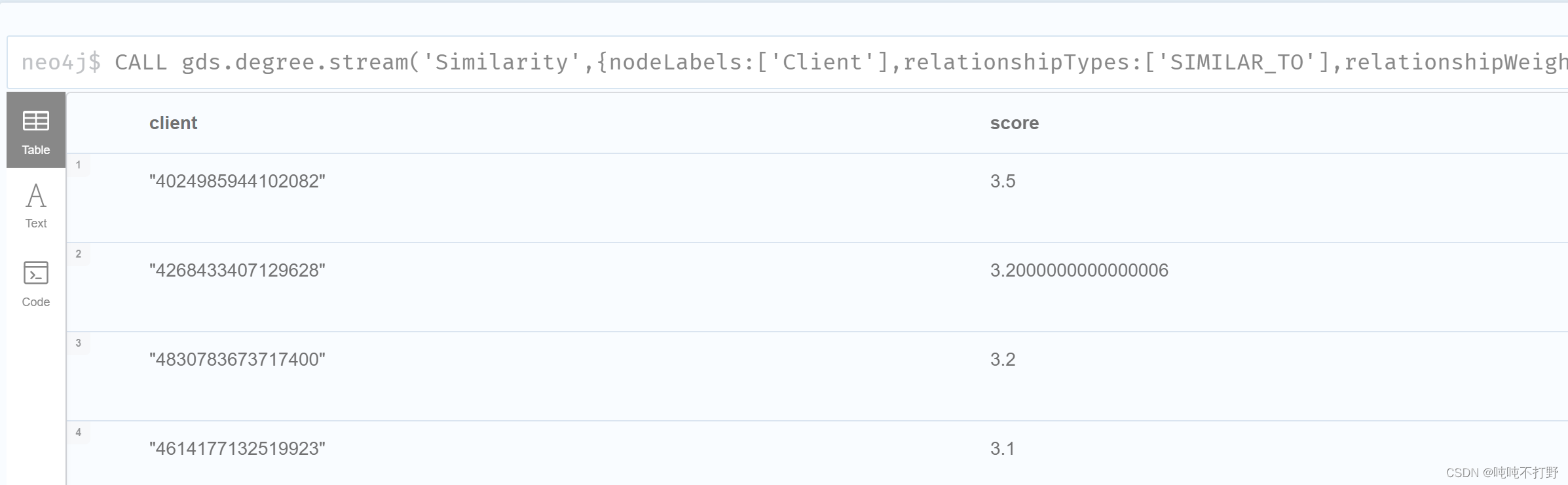
CALL gds.degree.stream('Similarity',{nodeLabels:['Client'],relationshipTypes:['SIMILAR_TO'],relationshipWeightProperty:'jaccardScore'})
YIELD nodeId,score
RETURN gds.util.asNode(nodeId).id AS client,score
ORDER BY score DESC;
关于度中心性,参考Degree Centrality
2.4.2 将计算出的分数写入数据库
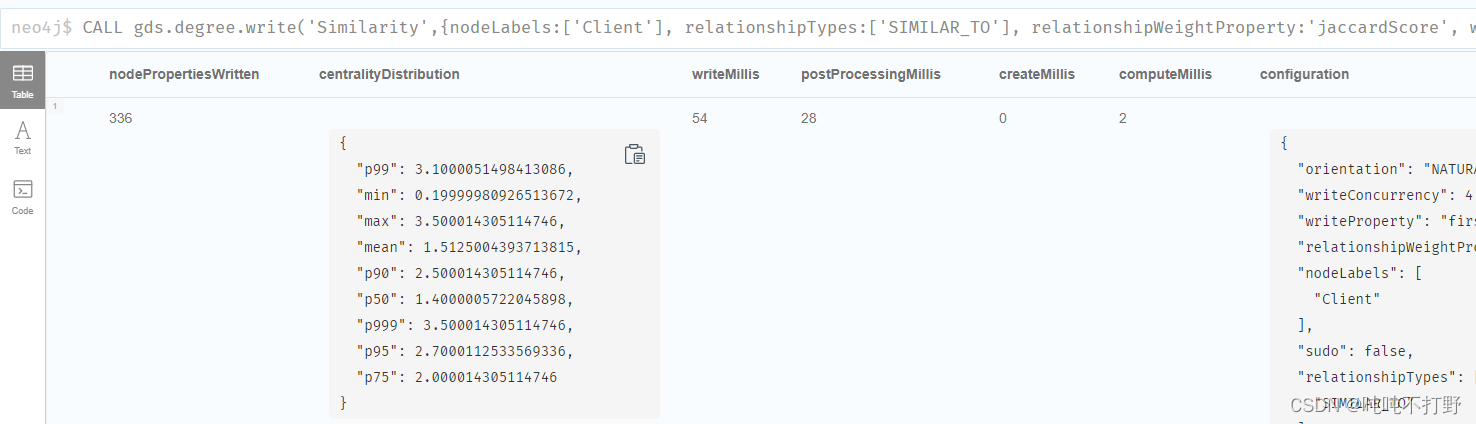
将中心分数作为firstPartyFraudScore,使用write模式写入数据库
CALL gds.degree.write('Similarity',{nodeLabels:['Client'],
relationshipTypes:['SIMILAR_TO'],
relationshipWeightProperty:'jaccardScore',
writeProperty:'firstPartyFraudScore'});
(文档中序号标错了,剩下部分应该属于Exercise 5)
2.5 使用指定的欺诈分数将客户标记为潜在欺诈者
2.5.1 根据得出的欺诈的分对客户添加标签
找出那些比阈值高的first-party诈骗得分对应的用户。这里,使用80%分位数作为阈值,超过的在客户节点上设置FirstPartyFraudster属性。
MATCH(c:Client)
WHERE exists(c.firstPartyFraudScore)
WITH percentileCont(c.firstPartyFraudScore, 0.8)
AS firstPartyFraudThreshold
MATCH(c:Client)
WHERE c.firstPartyFraudScore>firstPartyFraudThreshold
SET c:FirstPartyFraudster;

2.5.2 清理图目录(Graph Catalog)
CALL gds.graph.list()
YIELD graphName AS namedGraph
WITH namedGraph
CALL gds.graph.drop(namedGraph)
YIELD graphName
RETURN graphName;
删除内存里的图(映射之后的子图,在子图上进行操作,操作做完了,内存里的就删了,但是写入数据库的不会删)
3. Second-party fraud(共同欺诈)
这个模块包含两个部分:
- 找出单方欺诈和其他客户的交易
- 找出共同欺诈网络
3.1 确定单方欺诈和其他客户的交易
3.1.1 找出和单防欺诈发生交易的客户
第一步:找出没有被标记为单防欺诈的但是与单防欺诈人员交易的客户
MATCH p=(:Client:FirstPartyFraudster)-[]-(:Transaction)-[]-(c:Client)
WHERE NOT c:FirstPartyFraudster
RETURN p;
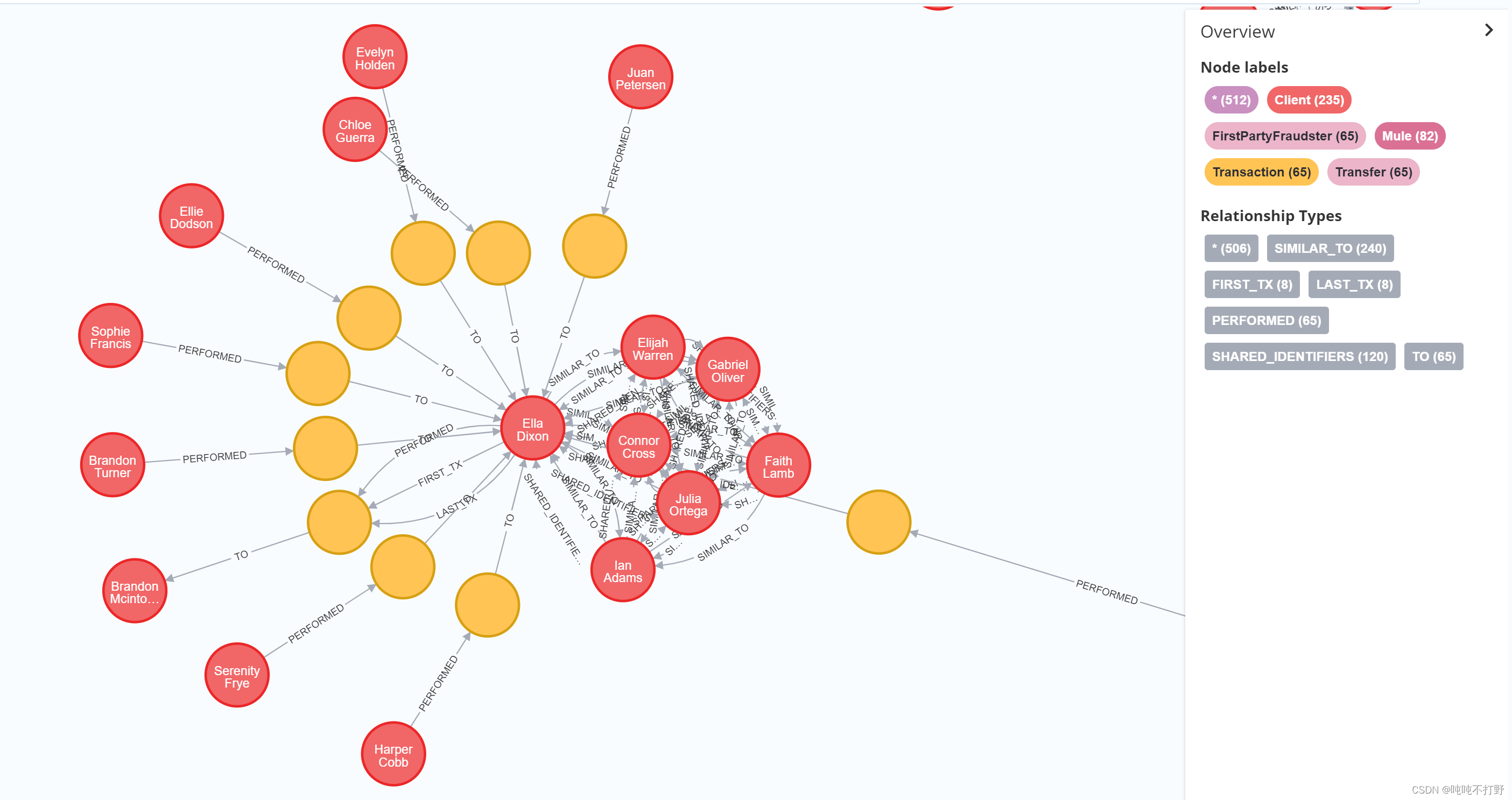
黄色的表示交易关系,to指向的一方表示与有诈骗嫌疑的人发生交易关系的普通客户。
另外,也可以查看一下这些交易的交易类型
MATCH (:Client:FirstPartyFraudster)-[]-(txn:Transaction)-[]-(c:Client)
WHERE NOT c:FirstPartyFraudster
UNWIND labels(txn) AS transactionType
RETURN transactionType, count(*) AS freq;

交易类型主要是 转账交易(上图中每个黄色圆圈都是既有Transaction又有Transfer)
3.1.2 建立新的关系
接下来,对有firstPartyFraudster标记的客户和没有这个标记但是和诈骗者有交易的客户,建立TRANSFER_TO关系。同时,将此类交易的总金额作为TRANSFER_TO关系的一个属性。
由于从诈骗者到客户转账的总金额,与从客户到诈骗者的总金额可能不同,所以分开创建,即在两个查询中分别创建关系。
TRANSFER_TO关系表示从单方诈骗到客户(查看查询中的方向)- 对这些客户添加
SecondPartyFraudSuspect标记(疑似共同诈骗人员)MATCH (c1:Client:FirstPartyFraudster)-[]->(t:Transaction)-[]->(c2:Client) WHERE NOT c2:FirstPartyFraudster WITH c1,c2,sum(t.amount) AS totalAmount SET c2:SecondPartyFraudSuspect CREATE (c1)-[:TRANSFER_TO {amount:totalAmount}]->(c2);
TRANSFER_TO从客户到单方诈骗MATCH (c1:Client:FirstPartyFraudster)<-[]-(t:Transaction)<-[]-(c2:Client) WITH c1,c2,sum(t.amount) AS totalAmount CREATE (c1)<-[:TRANSFER_TO {amount:totalAmount}]-(c2);
3.1.3 可视化关系
可视化新建的TRANSFER_TO关系
MATCH p=(:Client:FirstPartyFraudster)-[:TRANSFER_TO]-(c:Client)
WHERE NOT c:FirstPartyFraudster
RETURN p;
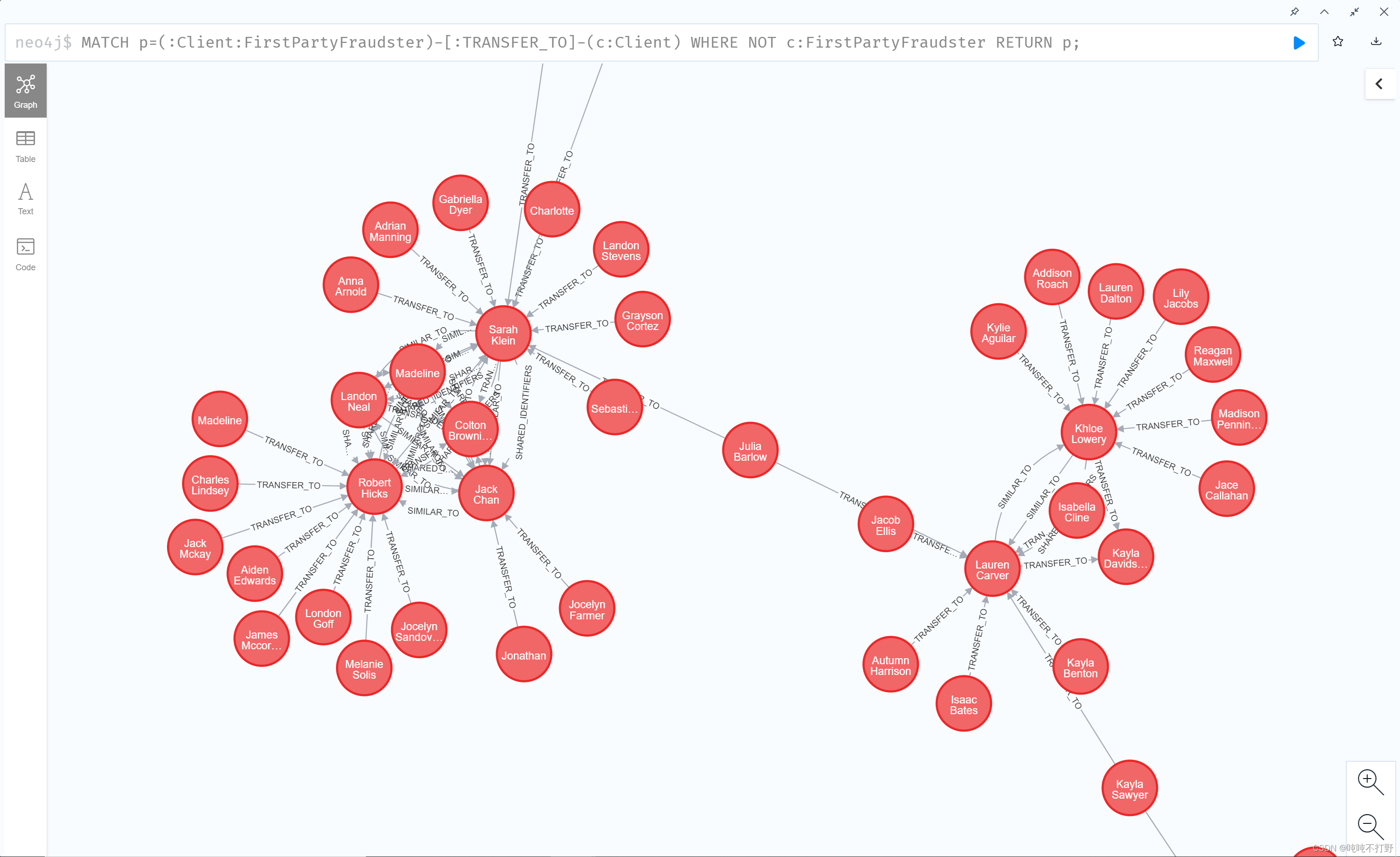
3.2 识别共同欺诈
- 这部分的目标是:找到那些与单方欺诈者勾结的但是还没有被标记为单方欺诈者的客户。
- 假设与单方欺诈者进行转账类的交易的,不管是向单方欺诈者汇款,或者是从单方欺诈者处接收资金的,都被认为是潜在的共同欺诈者。
- 为了找出这种客户,需要根据以下方法充分利用
TRANSFER_TO关系。- 使用社区发现算法(WCC)找到和单方欺诈者有关的用户网络
- 使用一个中心性/中心度算法(Page Rank) 计算一个分数,该分数是基于与诈骗者发生转账交易时,转账的金额大小,金额越大,则这个用户的影响就越大。
- 使用pagerank得分为客户打上secondPartyFraudScore(得分高的)标签
3.2.1 映射子图(创建内存里的图)
Let’s use native projection and create an in-memory graph with Client nodes and TRANSFER_TO relationships. Since we plan to use a community detection algorithm here, we should project a monopartite graph.
使用原生映射(native projection)创建一个有Client节点和TRANSFER_TO关系的映射子图。由于我们要使用社区检测算法,所以需要投影出一个单部图。
CALL gds.graph.create('SecondPartyFraudNetwork','Client','TRANSFER_TO',{relationshipProperties:'amount'});
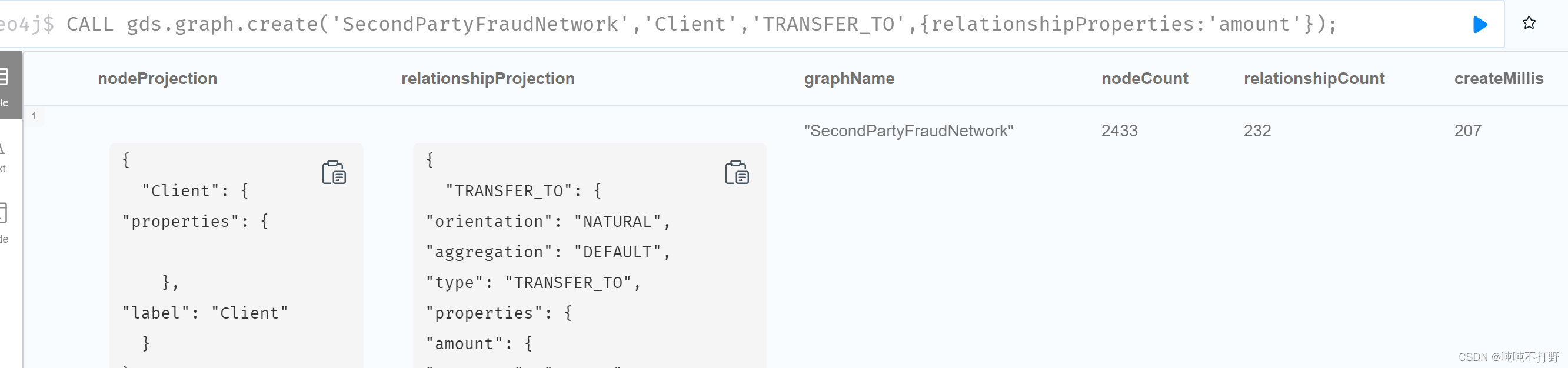
3.2.2 执行WCC找到集群/簇
这里主要是要确认是否有包含超过1人以上的簇,有的话,对这些clients添加secondPartyFraudGroup标签,以便之后使用本地查询也可以找到他们(存到数据图里,随时查询)
Stream结果
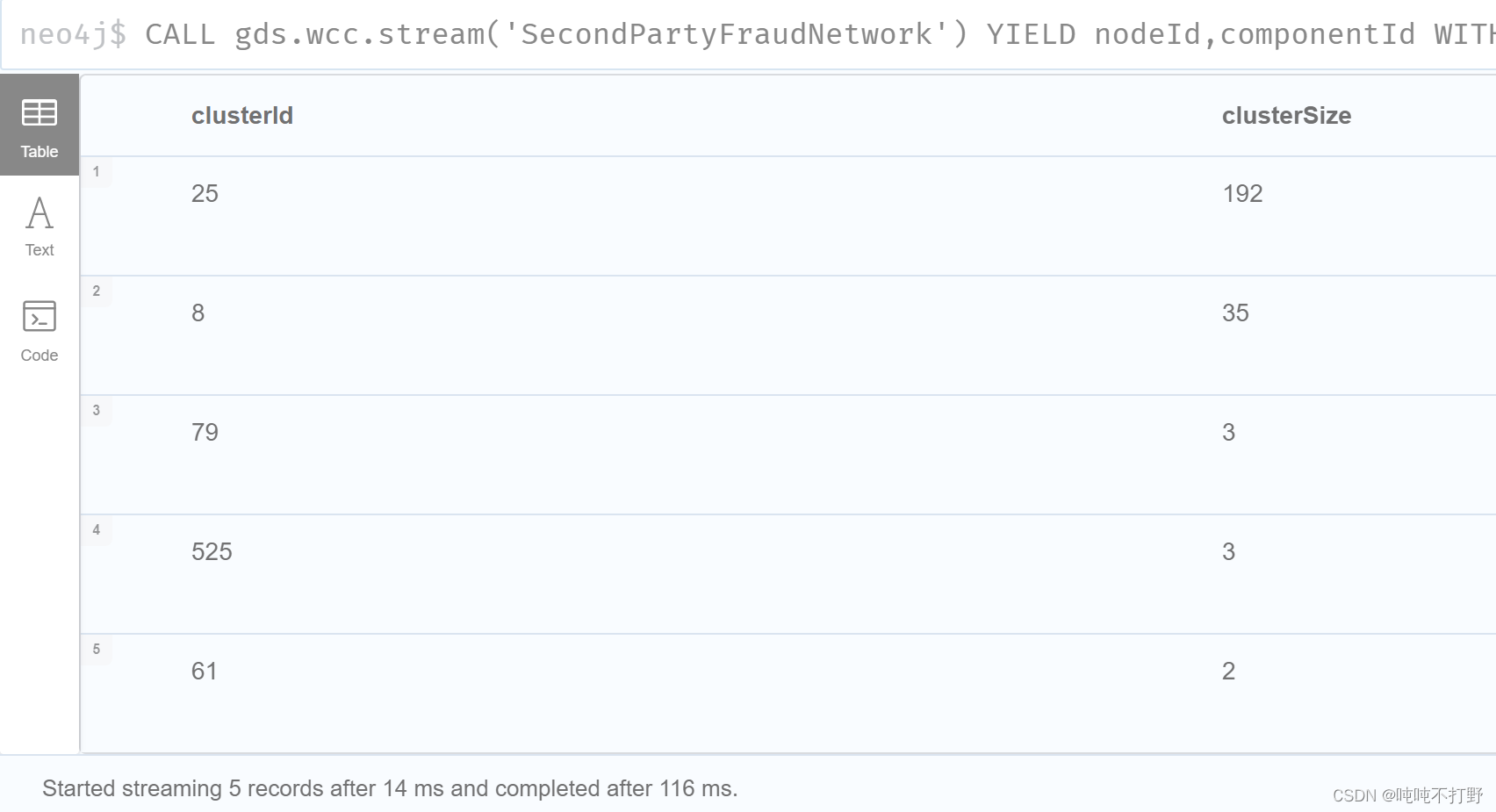
CALL gds.wcc.stream('SecondPartyFraudNetwork')
YIELD nodeId,componentId
WITH gds.util.asNode(nodeId) AS client,componentId AS clusterId
WITH clusterId,collect(client.id) AS cluster
WITH clusterId,size(cluster) AS clusterSize,cluster
WHERE clusterSize>1
RETURN clusterId,clusterSize
ORDER BY clusterSize DESC;
将结果写入数据库
CALL gds.wcc.stream('SecondPartyFraudNetwork')
YIELD nodeId,componentId
WITH gds.util.asNode(nodeId) AS client,componentId AS clusterId
WITH clusterId,collect(client.id) AS cluster
WITH clusterId,size(cluster) AS clusterSize,cluster
WHERE clusterSize>1
UNWIND cluster AS client
MATCH(c:Client {id:client})
SET c.secondPartyFraudGroup=clusterId;

3.3 识别共同欺诈人员
接下来继续使用Page Rank算法,找出嫌疑对象中拥有相对高的pagerank分数的客户。注意,关系按照交易给欺诈者的总金额进行加权。
CALL gds.pageRank.stream('SecondPartyFraudNetwork',{relationshipWeightProperty:'amount'})
YIELD nodeId,score
WITH gds.util.asNode(nodeId) AS client,score AS pageRankScore
WHERE exists(client.secondPartyFraudGroup)
RETURN client.secondPartyFraudGroup,client.name,labels(client),pageRankScore
ORDER BY client.secondPartyFraudGroup,pageRankScore DESC;
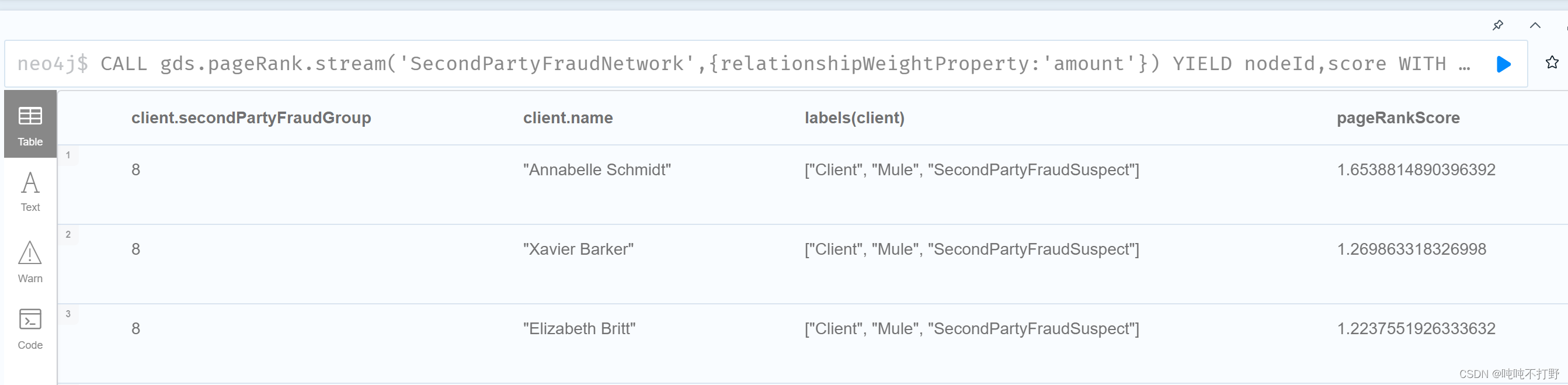
将结果写入数据库
CALL gds.pageRank.stream('SecondPartyFraudNetwork',{relationshipWeightProperty:'amount'})
YIELD nodeId,score
WITH gds.util.asNode(nodeId) AS client,score AS pageRankScore
WHERE exists(client.secondPartyFraudGroup)
AND pageRankScore >1 AND NOT client:FirstPartyFraudster
MATCH(c:Client {id:client.id})
SET c:SecondPartyFraud
SET c.secondPartyFraudScore=pageRankScore;

3.4 可视化共同欺诈网络
MATCH p=(:Client:FirstPartyFraudster)-[:TRANSFER_TO]-(c:Client)
WHERE NOT c:FirstPartyFraudster
RETURN p;
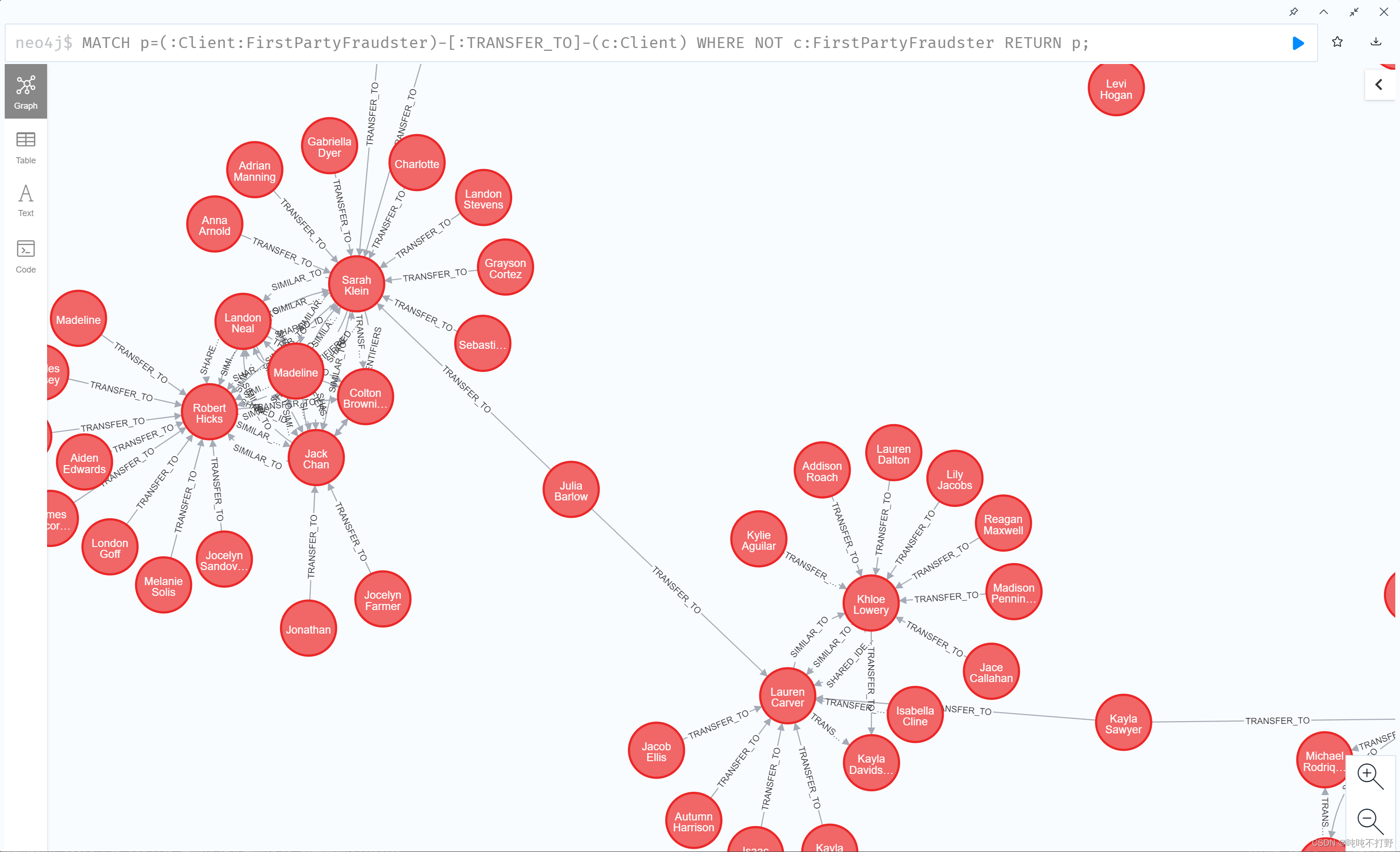
3. 清理内存里的图
使用算法得到结果并写入数据库之后,移除所有在Graph Catalog中的图,是一个很好的习惯
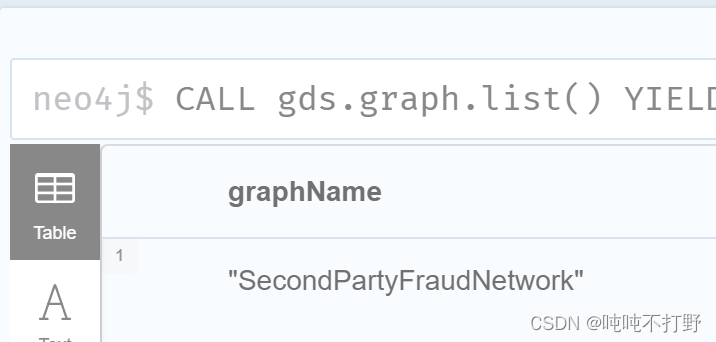
CALL gds.graph.list()
YIELD graphName AS namedGraph
WITH namedGraph
CALL gds.graph.drop(namedGraph)
YIELD graphName
RETURN graphName;
至此这部分结束,主要就是完成了:
- 找出和单方欺诈者有交易的客户
- 计算属于共同欺诈的得分并标记这些人
4.其他
4.1 GDS(graph-data-science)插件
关于GDS,参考:
- neo4j安装算法插件-GDS
- github地址:https://github.com/neo4j/graph-data-science/
- 官方文档说明:https://neo4j.com/developer/graph-data-science/(希望对GDS有更进一步了解的可以看看这个)
是Neo4j的GDS库,也就是图数据科学库,提供了以图算法为中心的广泛的分析能力。包括社区发现、中心度、节点相似度、路径发现和链路预测等算法。所有的操作都是为大规模和并行设计的,同时有可以定制和通用的API,以及高度优化的压缩内存数据结构
安装方式其实和之前APOC差不多,参考图数据库初探——2. neo4j安装和简单使用中2.2.6部分
4.2 WCC算法
- WCC,可以参考官方文档:GDS-WCC
- Strongly Connected Compontents(强连通组件,algo.scc),用于检测网络中存在的强联通组件(关系存在双边结构); 参考知乎文章:知识图谱 | Neo4j算法概述
-
补充一下强连通图和弱连通图的概念,读计算机的同学来说,数据机构中会讲图,离散数学里也有图,前者应该更熟悉。但是其实没有学过WCC算法
-
根据networkx这个库的说明文档:Weakly connected components algorithm (Union find)
弱连通组件(weakly connected component )是从图或子图的节点/顶点出发无法到达的一个子图。这个算法是由 A. Galler和Michael J. 在1964年提出的,一般使用广度优先搜索或深度优先搜索算法来找到图组件。
Weakly Connected Components algorithm (WCC)算法,也被称为Union Find(合并查找), 用于查找图中连接节点的不同的集合。对于这样的集合来说,集合中的任意一点都可以由集合中的某点出发到达。然而强连通组件算法Strongly Connected Components algorithm (SCC)要求节点从两个方向都可以到达。 而WCC只要求从一个方向上到达即可。这两种算法都用于分析网络结构。 -
同时,networkx代码的注释,这里,不考虑边的方向的时候图才是连通的时候,这个有向图就是弱连通图。
def is_weakly_connected(G): """Test directed graph for weak connectivity. A directed graph is weakly connected if and only if the graph is connected when the direction of the edge between nodes is ignored. Note that if a graph is strongly connected (i.e. the graph is connected even when we account for directionality), it is by definition weakly connected as well. -
另外,根据MADlib的库文档:MADlib:Weakly Connected Components
对于给定的一个有向图,WCC(弱连通组件)是原始图中一个子图,在忽略边的方向时,该子图的所有节点都可以通过某些路径互相连接。在无向图中,wcc同时也是scc。
-
根据百度百科定义:连通图
如果图G中每两点间皆连通,则G是连通图。
弱连通图:将有向图的所有的有向边替换为无向边,所得到的图称为原图的基图。如果一个有向图的基图是连通图,则有向图是弱连通图。
所以综合上述定义,可以知道,弱连通图
- 是有向图
- 存在某种路径可以连接起来,但是是单向,而不是双向。
另外,对搜索WCC算法有兴趣的,可以参考:
- CSDN博客:✅并查集(Union-Find)算法介绍
是从coursera上上课得来的 - cnblogs博客:算法与数据结构基础 - 合并查找(Union Find)
其实leetcode的题目只是抽象了一个实际中的问题,其实都是有用的,只是被放在底层调用的地方,别人都帮你写好了,所以才觉得没用。
4.3 相似度算法评估指标
neo4j的文档:Overlap Similarity
Overlap Similarity重叠相似度,主要用来衡量两个集合的重叠程度。定义为:两个集合相交部分的大小,比上两个集合中较小集合的大小。可以表示如下:
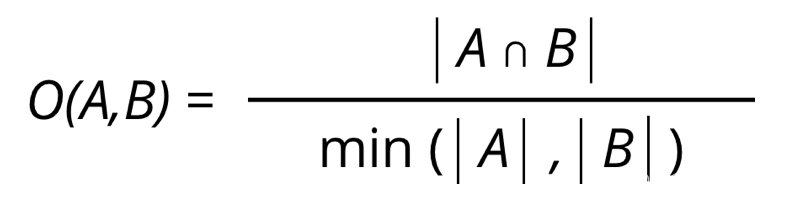
其中,衡量指标的含义如下(挺简单的,就不翻译了):
| Name | Type | Description |
|---|---|---|
| nodes | Integer | The number of nodes passed in. |
| similarityPairs | Integer | The number of pairs of similar nodes computed. |
| writeRelationshipType | String | The relationship type used when storing results. |
| writeProperty | String | The property used when storing results. |
| min | Float | The minimum similarity score computed. |
| max | Float | The maximum similarity score computed. |
| mean | Float | The mean of similarities scores computed. |
| stdDev | Float | The standard deviation of similarities scores computed. |
| p25 | Float | The 25 percentile of similarities scores computed. |
| p50 | Float | The 50 percentile of similarities scores computed. |
| p75 | Float | The 75 percentile of similarities scores computed. |
| p90 | Float | The 90 percentile of similarities scores computed. |
| p95 | Float | The 95 percentile of similarities scores computed. |
| p99 | Float | The 99 percentile of similarities scores computed. |
| p999 | Float | The 99.9 percentile of similarities scores computed. |
| p100 | Float | The 100 percentile of similarities scores computed. |
4.4 neo4j中不同的模式
运行算法的时候,neo4j有以下几种运行模式
- stream
- stats
- mutate
- write
翻译补充
TODO
参考:
4.5 neo4j报错
解决方法1
查看log日志,包括:
- neo4j desktop的log,位于:
C:\Users\yourname\.Neo4jDesktop\log.log - neo4j DBMS的log,位于:
安装时选择的数据目录\relate-data\dbmss\dbms-d85a0952-9ba1-4d1e-9451-cd9eaf5690a0(类似于这样的一串字符串)\logs\neo4j.log
解决方法2
- 参考官方文档:Troubleshooting guide


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











